MX-SAFE: Versatile Inference- and Training-Proof Microscaling Format with On-the-Fly Exponent and Mantissa Bit Allocation
Pith reviewed 2026-06-30 12:40 UTC · model grok-4.3
The pith
MX-SAFE format adaptively allocates bits between mantissa and exponent modes to support both training and inference in one microscaling scheme.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
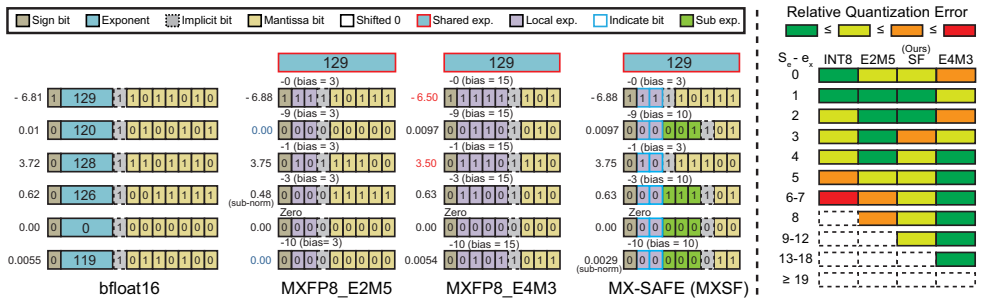
MX-SAFE uses on-the-fly allocation to select either a wider mantissa mode (FP8 E2M5) or a subnormal FP mode (FP5 E3M2) within the MX microscaling framework. The tile-based block design limits re-quantization cost during training. On average the format improves accuracy by 0.05 percent for inference and 11.1 percent for full training versus MXFP8 E2M5, and by 3.55 percent and 3.57 percent versus MXFP8 E4M3. A training-inference accelerator built around MX-SAFE matches BF16 accuracy while consuming 24.9 percent less total energy.
What carries the argument
The MX-SAFE format with adaptive choice between FP8 E2M5 (wider mantissa) and FP5 E3M2 (subnormal FP) modes, supported by a tile-based block design that reduces re-quantization burden during training.
If this is right
- The format delivers average accuracy gains of 0.05 percent inference and 11.1 percent full training versus MXFP8 E2M5.
- It also yields 3.55 percent and 3.57 percent accuracy gains versus MXFP8 E4M3 in the same two regimes.
- A supporting accelerator reaches BF16 accuracy with 24.9 percent lower total energy consumption.
- Direct-cast inference is supported without extra format conversion steps.
Where Pith is reading between the lines
- A single format could replace separate training-only and inference-only microscaling schemes in future accelerator designs.
- The tile-based reduction of re-quantization cost may make dynamic block quantization practical for full training on a wider range of models.
- Energy savings measured on the accelerator suggest potential battery-life gains if the same format is used in edge devices that alternate between training and inference.
Load-bearing premise
The tile-based block design sufficiently reduces the re-quantization burden during training so that the adaptive modes can be used without unacceptable accuracy loss or hardware overhead.
What would settle it
Running full training on a standard model such as ResNet-50 or a transformer with MX-SAFE but without the tile-based blocking would show whether accuracy drops sharply or hardware cost rises beyond the reported levels.
Figures





read the original abstract
As the demand for deep learning grows, cost reduction through quantization has become essential for both training and inference. In 2022, the Open Compute Project (OCP) consortium standardized narrow precision formats for deep learning, called the microscaling (MX) format. The MX format is a hardware-friendly dynamic quantization scheme that effectively reduces the data size by sharing an 8-bit exponent across multiple operands. The MX format can be categorized into two types with their own strengths: (i) MXINT which focuses on a high precision consisting only of mantissa bits and (ii) MXFP which focuses on a wider dynamic range by allowing local exponent bits. In this work, we present a versatile MXFP format, called MX-SAFE (MXSF in short), that adaptively uses two modes, i.e., a wider mantissa mode (FP8 E2M5) and a subnormal FP mode (FP5 E3M2), to support both training and direct-cast inference. Furthermore, we propose a tile-based block design to increase hardware efficiency by reducing the burden of re-quantization process during the training with the MXSF format. Owing to the use of the proposed MXSF format, 0.05%/11.1% and 3.55%/3.57% improvements in accuracy, on average, for inference/full-training compared to MXFP8 E2M5 and MXFP8 E4M3 are observed, respectively. Moreover, we present a training-inference accelerator that supports the MXSF format and it achieves similar accuracy to the BF16 baseline while using 24.9% less total energy consumption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MX-SAFE (MXSF), a microscaling format that adaptively switches between wider-mantissa (E2M5) and subnormal (E3M2) modes, supported by a tile-based block design intended to lower re-quantization cost during training. It reports average accuracy gains of 0.05%/11.1% (inference/full-training) versus MXFP8 E2M5 and 3.55%/3.57% versus MXFP8 E4M3, plus an accelerator that matches BF16 accuracy at 24.9% lower total energy.
Significance. If the empirical results hold after proper validation, the work would supply a single hardware-friendly format usable across both training and inference phases, together with a concrete accelerator design demonstrating energy reduction relative to BF16.
major comments (2)
- [Abstract] Abstract, paragraph on tile-based block design: the claim that this design 'reduc[es] the burden of re-quantization' during full training is load-bearing for the reported 11.1% and 3.57% accuracy gains and the 24.9% energy figure, yet the text supplies no quantitative overhead measurements, tile-size ablation, or comparison against a per-tensor baseline.
- [Abstract] Abstract: the specific accuracy and energy percentages are stated without any accompanying experimental protocol (models, datasets, run counts, statistical tests, or error bars), so the central empirical claims cannot be assessed from the manuscript.
minor comments (1)
- [Abstract] Abstract: the phrasing 'MXFP8 E2M5' and 'MXFP8 E4M3' should be defined on first use or cross-referenced to the OCP MX specification to avoid ambiguity with the authors' own adaptive modes.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript to improve clarity and support for the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph on tile-based block design: the claim that this design 'reduc[es] the burden of re-quantization' during full training is load-bearing for the reported 11.1% and 3.57% accuracy gains and the 24.9% energy figure, yet the text supplies no quantitative overhead measurements, tile-size ablation, or comparison against a per-tensor baseline.
Authors: We agree that the abstract lacks quantitative overhead measurements, tile-size ablations, or explicit per-tensor comparisons to support the re-quantization reduction claim. The tile-based design is motivated in the methods as a means to amortize re-quantization across tiles rather than per-tensor, but we will add concrete overhead numbers, an ablation on tile sizes, and a direct comparison to per-tensor baselines in both the abstract and a new subsection of the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the specific accuracy and energy percentages are stated without any accompanying experimental protocol (models, datasets, run counts, statistical tests, or error bars), so the central empirical claims cannot be assessed from the manuscript.
Authors: We acknowledge that the abstract presents the accuracy and energy figures without protocol details. The full experimental setup (models, datasets, run counts, and any statistical analysis) appears in the experiments section, but to make the abstract self-contained we will revise it to include a concise statement of the evaluation protocol, models, and datasets used. revision: yes
Circularity Check
No circularity; claims rest on empirical comparisons to external baselines
full rationale
The paper proposes the MXSF format and tile-based block design, then reports measured accuracy gains (0.05%/11.1% vs MXFP8 E2M5; 3.55%/3.57% vs MXFP8 E4M3) and energy savings (24.9% vs BF16) from direct experiments. No equations, fitted parameters, or self-citations are shown that reduce these quantities to quantities defined by the authors' own inputs. The derivation chain consists of format definition followed by external-benchmark evaluation and is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The OCP microscaling format with shared 8-bit exponent is a suitable base for dynamic quantization in deep learning.
invented entities (1)
-
MX-SAFE (MXSF) format
no independent evidence
Reference graph
Works this paper leans on
-
[1]
SpinQuant: LLM quantization with learned rotations
Z. Liu et al. , “SpinQuant: LLM Quantization with Learned Rotations,” arXiv:2405.16406, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Temporal Dynami c Quantization for Diffusion Models,
J. So, J. Lee, D. Ahn, H. Kim, and E. Park, “Temporal Dynami c Quantization for Diffusion Models,” in Proceedings of Advances in Neural Information Processing Systems (NeurIPS) , vol. 36, 2024
2024
-
[3]
Microscaling data formats for deep learning
B. D. Rouhani et al. , “Microscaling Data Formats for Deep Learning,” arXiv:2310.10537, 2023
-
[4]
NVIDIA Blackwell Platform: Adv ancing Generative AI and Accelerated Computing,
A. Tirumala and R. Wong, “NVIDIA Blackwell Platform: Adv ancing Generative AI and Accelerated Computing,” in Proceedings of the IEEE Hot Chips Symposium (HCS) . IEEE Computer Society, 2024, pp. 1–33
2024
-
[5]
Inside Maia 100,
S. Xu and C. Ramakrishnan, “Inside Maia 100,” in Proceedings of the IEEE Hot Chips Symposium (HCS) . IEEE Computer Society, 2024, pp. 1–17
2024
-
[6]
Compute substrate for software 2.0,
J. V asiljevic et al. , “Compute substrate for software 2.0,” IEEE Micro, vol. 41, no. 2, pp. 50–55, 2021
2021
-
[7]
OPAL: Outlier-Pres erved Microscaling Quantization Accelerator for Generative Lar ge Language Models,
J. Koo, D. Park, S. Jung, and J. Kung, “OPAL: Outlier-Pres erved Microscaling Quantization Accelerator for Generative Lar ge Language Models,” in Proceedings of the ACM/IEEE Design Automation Confer- ence (DAC), 2024
2024
-
[8]
Block and Subword-Sc aling Floating-Point (BSFP): An Efficient Non-Uniform Quantizat ion for Low Precision Inference,
Y .-C. Lo, T.-K. Lee, and R.-S. Liu, “Block and Subword-Sc aling Floating-Point (BSFP): An Efficient Non-Uniform Quantizat ion for Low Precision Inference,” in Proceedings of the International Conference on Learning Representations (ICLR) , 2023
2023
-
[9]
BOOST: Block Minifloat-Based On-Device CNN Training Accelerator with Transfer Learning,
C. Guo et al. , “BOOST: Block Minifloat-Based On-Device CNN Training Accelerator with Transfer Learning,” in Proceedings of The IEEE/ACM International Conference on Computer Aided Desig n (IC- CAD). IEEE, 2023, pp. 1–9
2023
-
[10]
DBPS: Dynami c Block Size and Precision Scaling for Efficient DNN Training Suppor ted by RISC-V ISA Extensions,
S. Lee, J. Choi, S. Noh, J. Koo, and J. Kung, “DBPS: Dynami c Block Size and Precision Scaling for Efficient DNN Training Suppor ted by RISC-V ISA Extensions,” in Proceedings of the ACM/IEEE Design Automation Conference (DAC) . IEEE, 2023, pp. 1–6
2023
-
[11]
FAST: DNN Training Under V ariable Precision Block Floating Point with Stochastic Ro unding,
S. Q. Zhang, B. McDanel, and H. Kung, “FAST: DNN Training Under V ariable Precision Block Floating Point with Stochastic Ro unding,” in Proceedings of IEEE International Symposium on High-Perfo rmance Computer Architecture (HPCA) . IEEE, 2022, pp. 846–860
2022
-
[12]
Oscillation-Reduce d MXFP4 Training for Vision Transformers,
Y . Chen, H. Xi, J. Zhu, and J. Chen, “Oscillation-Reduce d MXFP4 Training for Vision Transformers,” in Proceeding of the International Conference on Machine Learning (ICML) , 2025. [Online]. Available: https://openreview.net/forum?id=LUFPNGiCUw
2025
-
[13]
Training LLMs with MXFP4,
A. Tseng, T. Y u, and Y . Park, “Training LLMs with MXFP4,” in Proceedings of The International Conference on Artificial Intelligence and Statistics (AISTAT) , 2025. [Online]. Available: https://openreview.net/forum?id=a8z5Q0WSPL
2025
-
[14]
LightRot: A Light- weighted Rotation Scheme and Architecture for Accurate Low -bit Large Language Model Inference,
S. Kim, Y . Choi, J. Oh, B. Kim, and H.-J. Y oo, “LightRot: A Light- weighted Rotation Scheme and Architecture for Accurate Low -bit Large Language Model Inference,” IEEE Journal on Emerging and Selected Topics in Circuits and Systems (JETCAS) , 2025
2025
-
[15]
Deep Residual Learni ng for Image Recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learni ng for Image Recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2016, pp. 770–778
2016
-
[16]
Mo- bileNetV2: Inverted Residuals and Linear Bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Ch en, “Mo- bileNetV2: Inverted Residuals and Linear Bottlenecks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recogn ition (CVPR), 2018, pp. 4510–4520
2018
-
[17]
Systolic te nsor array: An efficient structured-sparse gemm accelerator for mobile cn n inference,
Z.-G. Liu, P . N. Whatmough, and M. Mattina, “Systolic te nsor array: An efficient structured-sparse gemm accelerator for mobile cn n inference,” IEEE Computer Architecture Letters , vol. 19, no. 1, pp. 34–37, 2020
2020
-
[18]
Transformers: State-of-the-art natural language proce ss- ing,
T. Wolf et al. , “Transformers: State-of-the-art natural language proce ss- ing,” in Proceedings of the Conference on Empirical Methods in Natur al Language Processing: System Demonstrations (EMNLP) , 2020
2020
-
[19]
ResNet Strikes B ack: An Improved Training Procedure in Timm,
R. Wightman, H. Touvron, and H. Jegou, “ResNet Strikes B ack: An Improved Training Procedure in Timm,” in NeurIPS 2021 W orkshop on ImageNet: Past, Present, and Future , 2021
2021
-
[20]
Mobilenetv4: Universal models for the mobile ecosys- tem,
D. Qin et al. , “Mobilenetv4: Universal models for the mobile ecosys- tem,” in Proceedings of the European Conference on Computer Vision (ECCV). Springer, 2025, pp. 78–96
2025
-
[21]
Training Data-efficient Image Transformers & Distillation through Attention,
H. Touvron et al. , “Training Data-efficient Image Transformers & Distillation through Attention,” in Proceedings of the International Conference on Machine Learning (ICML) . PMLR, 2021, pp. 10 347– 10 357
2021
-
[22]
Swin Transformer: Hierarchical Vision Transformer usin g Shifted Windows ,
Z. Liu et al., “Swin Transformer: Hierarchical Vision Transformer usin g Shifted Windows ,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2021, pp. 10 012– 10 022
2021
-
[23]
EfficientViT: Lig htweight Multi-scale Attention for High-resolution Dense Predicti on,
H. Cai, J. Li, M. Hu, C. Gan, and S. Han, “EfficientViT: Lig htweight Multi-scale Attention for High-resolution Dense Predicti on,” in Proceed- ings of the IEEE/CVF International Conference on Computer V ision, 2023, pp. 17 302–17 313
2023
-
[24]
FastViT: A Fast Hybrid Vision Transformer using Structural Reparame terization,
P . K. A. V asu, J. Gabriel, J. Zhu, O. Tuzel, and A. Ranjan, “FastViT: A Fast Hybrid Vision Transformer using Structural Reparame terization,” in Proceedings of the IEEE/CVF International Conference on Co mputer Vision (ICCV), 2023, pp. 5785–5795
2023
-
[25]
A Framework for Few-shot Language Model Evaluation,
L. Gao et al., “A Framework for Few-shot Language Model Evaluation,” 07 2024. [Online]. Available: https://zenodo.org/record s/12608602
-
[26]
A. Dubey et al. , “The Llama 3 Herd of Models,” arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
nanovl m,
L. Wiedmann, A. R. Gosthipaty, and A. Marafioti, “nanovl m,” https://github.com/huggingface/nanoVLM, 2025
2025
-
[28]
Are We on the Right Way for Evalua ting Large Vision-Language Models?
L. Chen, J. Li, X. Dong, P . Zhang, Y . Zang, Z. Chen, H. Duan , J. Wang, Y . Qiao, D. Lin, and F. Zhao, “Are We on the Right Way for Evalua ting Large Vision-Language Models?” in Proceedings of The Annual Conference on Neural Information Processing Systems (Neur IPS), 2024. [Online]. Available: https://openreview.net/forum?id=evP9mxNNxJ
2024
-
[29]
Sigmo id Loss for Language Image Pre-Training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmo id Loss for Language Image Pre-Training,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , 2023, pp. 11 975– 11 986
2023
-
[30]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
L. B. Allal, A. Lozhkov, E. Bakouch, G. M. Bl´ azquez, G. P enedo, L. Tunstall, A. Marafioti, H. Kydl´ ıˇ cek, A. P . Lajar´ ın, V . S rivastav, J. Lochner, C. Fahlgren, X.-S. Nguyen, C. Fourrier, B. Burte nshaw, H. Larcher, H. Zhao, C. Zakka, M. Morlon, C. Raffel, L. von Werra, and T. Wolf, “Smollm2: When smol goes big – data-centr ic training of a small ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
BitMoD: Bit-seria l Mixture- of-Datatype LLM Acceleration,
Y . Chen, A. F. AbouElhamayed, X. Dai, Y . Wang, M. Androni c, G. A. Constantinides, and M. S. Abdelfattah, “BitMoD: Bit-seria l Mixture- of-Datatype LLM Acceleration,” in Proceedings of the IEEE Interna- tional Symposium on High Performance Computer Architecture (HPCA). IEEE, 2025, pp. 1082–1097
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.