Vision-Guided Outdoor Flight and Obstacle Evasion via Reinforcement Learning
Pith reviewed 2026-06-30 13:20 UTC · model grok-4.3
The pith
A vision-based reinforcement learning policy trained only in simulation achieves zero-shot transfer to real outdoor drone flights through unseen obstacles and hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
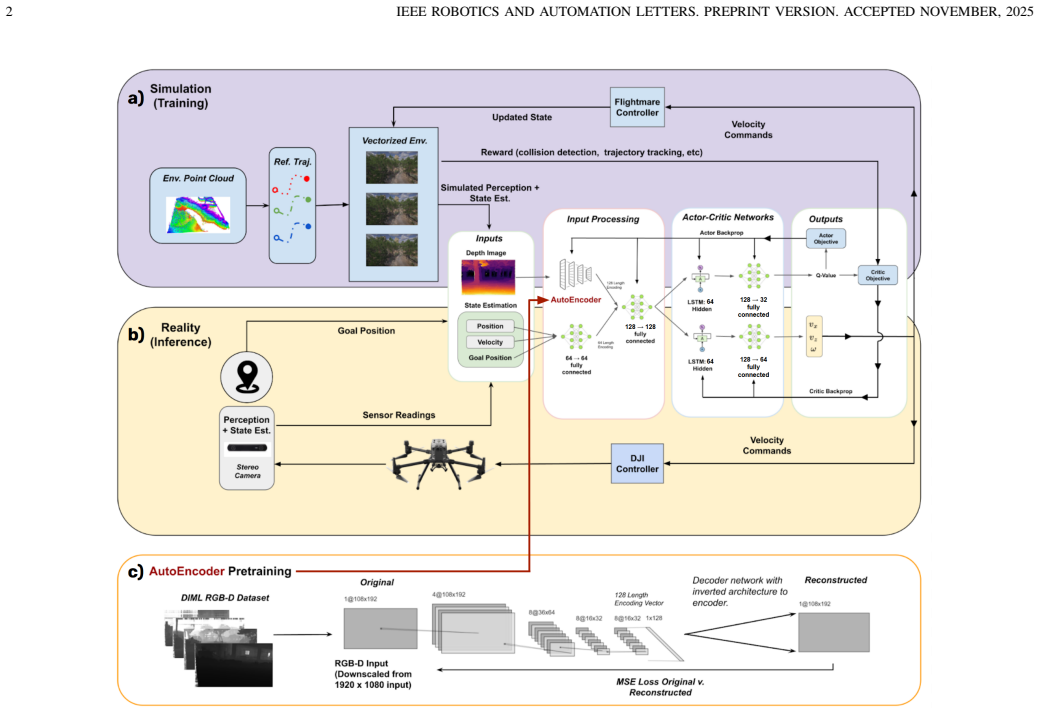
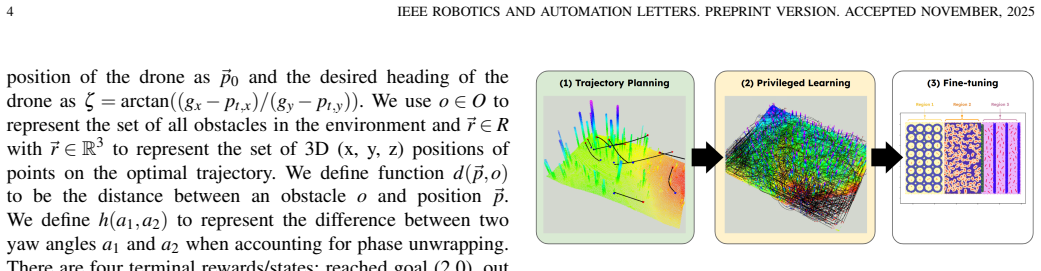
A policy composed of a pre-trained autoencoder perception head and an LSTM planning-control network, trained via privileged learning followed by curriculum fine-tuning with domain randomization, produces velocity commands that enable autonomous goal-directed flight and obstacle evasion when deployed zero-shot on real outdoor environments and previously unseen drone hardware.
What carries the argument
The sensorimotor policy with a pre-trained autoencoder for visual perception followed by an LSTM network that maps depth and VIO inputs to velocity commands.
If this is right
- Autonomous quadcopter navigation becomes feasible in GNSS-denied and telemetry-denied settings.
- Off-the-shelf commercial drones can execute the policy without hardware modifications.
- Real-world data collection for training is unnecessary when simulation curricula and randomization are applied.
- The same policy structure supports navigation in previously unencountered outdoor obstacle fields.
Where Pith is reading between the lines
- The same privileged-plus-curriculum pipeline could be adapted for other mobile robots such as ground vehicles.
- Extending the simulation environments to include indoor layouts might produce policies usable in warehouses.
- Adding explicit uncertainty estimation to the LSTM outputs could further increase safety margins in deployment.
- Long-duration flights could test whether the policy maintains performance over repeated obstacle encounters.
Load-bearing premise
The combination of privileged learning from a global motion planner, curriculum fine-tuning, domain randomization, and reward shaping in simulation is sufficient to produce a policy that transfers zero-shot to real outdoor conditions and unseen hardware.
What would settle it
Repeated failure of the deployed policy to reach goals or avoid collisions during outdoor tests on a new obstacle configuration with a different commercial drone model.
Figures

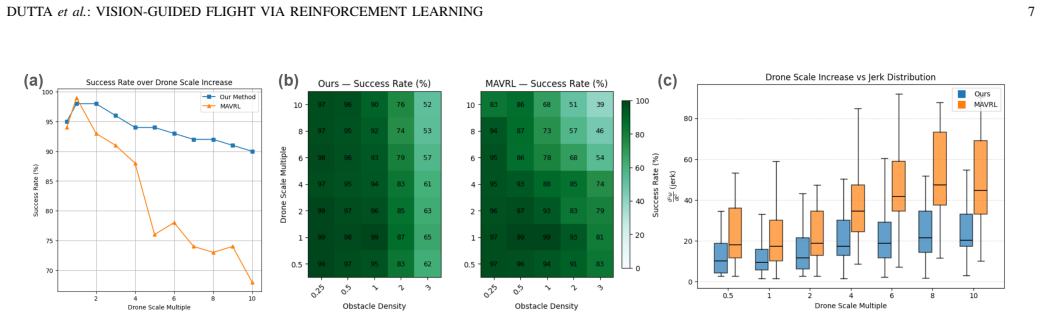

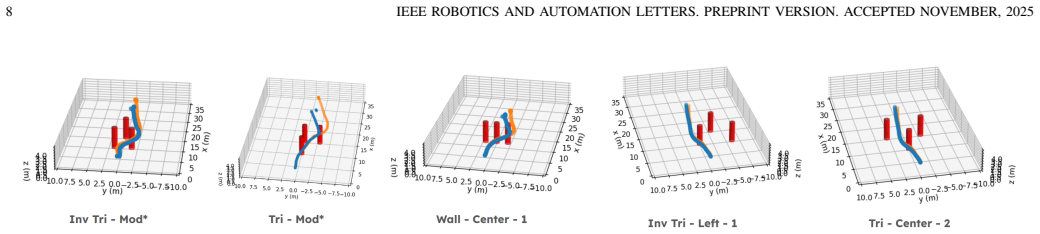
read the original abstract
Although quadcopters boast impressive traversal capabilities enabled by their omnidirectional maneuverability, the need for continuous pilot control in complex environments impedes their application in GNSS and telemetry-denied scenarios. To this end, we propose a novel sensorimotor policy that uses stereo-vision depth and visual-inertial odometry (VIO) to autonomously navigate through obstacles in an unknown environment to reach a goal point. The policy is comprised of a pre-trained autoencoder as the perception head followed by a planning and control LSTM network which outputs velocity commands that can be followed by an off-the-shelf commercial drone. We leverage reinforcement and privileged learning paradigms to train the policy in simulation through a two-stage process: 1) initial training with optimal trajectories generated by a global motion planner acting as a supervisory backbone, 2) further fine-tuning in a curriculum environment. To bridge the sim-to-real gap, we employ domain randomization and reward shaping to create a policy that is both robust to noise and domain shift. In outdoor experiments, our approach achieves successful zero-shot transfer to both obstacle environments and a drone platform that were never encountered during training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a sensorimotor policy for quadcopter obstacle navigation using stereo vision depth and VIO. The policy is trained in simulation via a two-stage RL process: privileged learning supervised by a global motion planner, followed by curriculum fine-tuning. Domain randomization and reward shaping are used to bridge the sim-to-real gap. The central claim is that this policy achieves successful zero-shot transfer to real outdoor obstacle environments and an unseen commercial drone platform.
Significance. If the zero-shot transfer claim is substantiated with rigorous quantitative evaluation, the work would represent a meaningful advance in sim-to-real transfer for vision-based autonomous drone flight in GNSS-denied environments. It combines privileged learning, curriculum training, and domain randomization in a way that could inform practical deployment of RL policies on commercial hardware.
major comments (2)
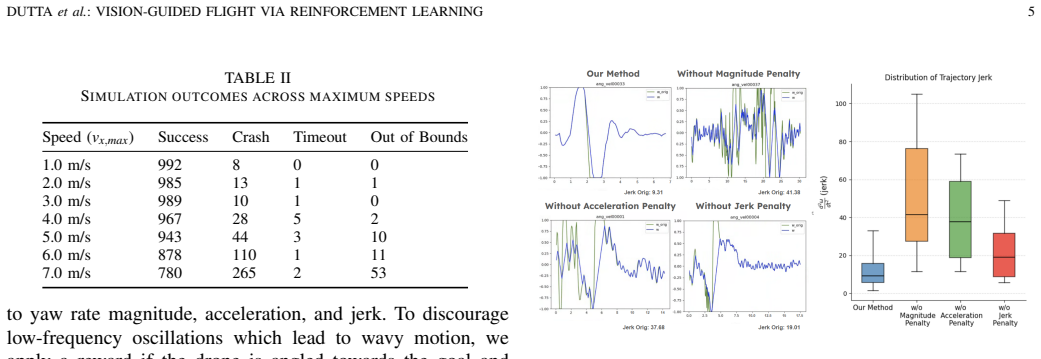
- [Abstract] Abstract: The claim that the approach 'achieves successful zero-shot transfer to both obstacle environments and a drone platform that were never encountered during training' supplies no quantitative metrics, failure rates, number of trials, or baseline comparisons. Without these, it is impossible to assess whether the two-stage pipeline plus domain randomization actually produces the claimed robustness under real sensor noise, lighting, wind, and platform dynamics.
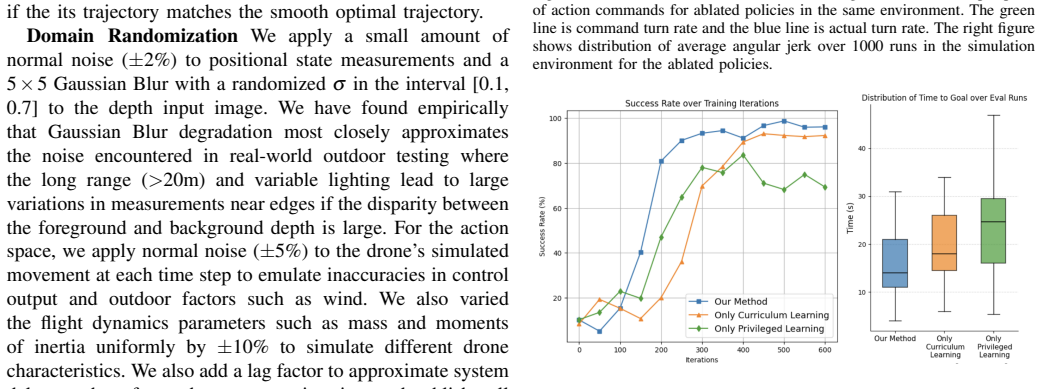
- [Abstract] Abstract: The central claim depends on the assertion that privileged learning from a global planner, curriculum fine-tuning, domain randomization, and reward shaping suffice for zero-shot transfer to unseen hardware and environments, yet the manuscript provides no ablation results or failure-mode analysis to isolate the contribution of each component or to confirm coverage of relevant variation axes.
minor comments (1)
- [Abstract] Abstract: The policy description ('pre-trained autoencoder as the perception head followed by a planning and control LSTM network which outputs velocity commands') would benefit from explicit specification of input feature dimensions, LSTM hidden size, and the exact form of the velocity command output.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We will revise the abstract to include quantitative metrics supporting the zero-shot transfer claim and add ablation studies plus failure-mode analysis to better isolate component contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the approach 'achieves successful zero-shot transfer to both obstacle environments and a drone platform that were never encountered during training' supplies no quantitative metrics, failure rates, number of trials, or baseline comparisons. Without these, it is impossible to assess whether the two-stage pipeline plus domain randomization actually produces the claimed robustness under real sensor noise, lighting, wind, and platform dynamics.
Authors: We agree that the abstract, being a high-level summary, would be strengthened by including key quantitative results. The full manuscript reports real-world experimental outcomes with trial counts and success rates in the evaluation section. We will update the abstract to explicitly state metrics such as success rate over the number of trials performed on the unseen platform and environments. revision: yes
-
Referee: [Abstract] Abstract: The central claim depends on the assertion that privileged learning from a global planner, curriculum fine-tuning, domain randomization, and reward shaping suffice for zero-shot transfer to unseen hardware and environments, yet the manuscript provides no ablation results or failure-mode analysis to isolate the contribution of each component or to confirm coverage of relevant variation axes.
Authors: We acknowledge that explicit ablation studies and failure-mode analysis would help substantiate the role of each element in the two-stage pipeline. The manuscript describes the combined approach and its overall performance but does not isolate individual contributions via ablations. We will add an ablation study and failure-mode discussion in the revised manuscript. revision: yes
Circularity Check
No significant circularity; derivation relies on external planner and simulation
full rationale
The paper's central pipeline trains an LSTM policy in simulation via privileged supervision from an independent global motion planner, followed by curriculum fine-tuning, domain randomization, and reward shaping. This produces a sensorimotor policy for zero-shot real-world transfer. No equations, fitted parameters, or self-citations are shown that reduce the transfer claim to a tautology or to the target real data by construction. The method is self-contained against external benchmarks (the planner and sim environment) rather than deriving its success from the real-world results it claims to achieve.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nathan Bucki, Junseok Lee, and Mark W. Mueller. Rectangular pyramid partitioning using integrated depth sensors (rappids): A fast planner for multicopter navigation.IEEE Robotics and Automation Letters, 5(3):4626–4633, 2020
2020
-
[2]
Jaehoon Cho, Dongbo Min, Youngjung Kim, and Kwanghoon Sohn. Diml/cvl rgb-d dataset: 2m rgb-d images of natural indoor and outdoor scenes.arXiv preprint arXiv:2110.11590, 2021
- [3]
-
[4]
Learning deep sensorimotor policies for vision-based autonomous drone racing
Jiawei Fu, Yunlong Song, Yan Wu, Fisher Yu, and Davide Scaramuzza. Learning deep sensorimotor policies for vision-based autonomous drone racing. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5243–5250. IEEE, 2023
2023
-
[5]
Comparing quadrotor control policies for zero-shot reinforcement learning under uncertainty and partial observability
Sven Gronauer, Daniel St ¨umke, and Klaus Diepold. Comparing quadrotor control policies for zero-shot reinforcement learning under uncertainty and partial observability. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023
2023
-
[6]
Autonomous drone racing: A survey.IEEE Transactions on Robotics, 2024
Drew Hanover, Antonio Loquercio, Leonard Bauersfeld, Angel Romero, Robert Penicka, and et al. Autonomous drone racing: A survey.IEEE Transactions on Robotics, 2024
2024
-
[7]
Generalization through simulation: Integrating simulated and real data into deep reinforcement learning for vision-based autonomous flight
Katie Kang, Suneel Belkhale, Gregory Kahn, Pieter Abbeel, and Sergey Levine. Generalization through simulation: Integrating simulated and real data into deep reinforcement learning for vision-based autonomous flight. In2019 international conference on robotics and automation (ICRA), pages 6008–6014. IEEE, 2019
2019
-
[8]
Mihir Kulkarni and Kostas Alexis. Reinforcement learning for collision-free flight exploiting deep collision encoding.arXiv preprint arXiv:2402.03947, 2024
-
[9]
Mihir Kulkarni, Theodor J. L. Forgaard, and Kostas Alexis. Aerial gym – isaac gym simulator for aerial robots, 2023
2023
-
[10]
Search- based motion planning for aggressive flight in se (3).IEEE Robotics and Automation Letters, 3(3):2439–2446, 2018
Sikang Liu, Kartik Mohta, Nikolay Atanasov, and Vijay Kumar. Search- based motion planning for aggressive flight in se (3).IEEE Robotics and Automation Letters, 3(3):2439–2446, 2018
2018
-
[11]
Learning high-speed flight in the wild.Science Robotics, 6(59):eabg5810, 2021
Antonio Loquercio, Elia Kaufmann, Ren ´e Ranftl, Matthias M ¨uller, Vladlen Koltun, and Davide Scaramuzza. Learning high-speed flight in the wild.Science Robotics, 6(59):eabg5810, 2021
2021
-
[12]
Maqueda, Carlos R
Antonio Loquercio, Ana I. Maqueda, Carlos R. Del Blanco, and Davide Scaramuzza. Dronet: Learning to fly by driving.IEEE Robotics and Automation Letters, 3:1088–1095, 2018
2018
-
[13]
Efficient optical flow and stereo vision for velocity estimation and obstacle avoidance on an autonomous pocket drone.IEEE Robotics and Automation Letters, 2(2):1070–1076, 2017
Kimberly McGuire, Guido de Croon, Christophe De Wagter, Karl Tuyls, and Hilbert Kappen. Efficient optical flow and stereo vision for velocity estimation and obstacle avoidance on an autonomous pocket drone.IEEE Robotics and Automation Letters, 2(2):1070–1076, 2017
2017
-
[14]
Polynomial trajectory planning for aggressive quadrotor flight in dense indoor environments
Charles Richter, Adam Bry, and Nicholas Roy. Polynomial trajectory planning for aggressive quadrotor flight in dense indoor environments. InRobotics Research: The 16th International Symposium ISRR, pages 649–666. Springer, 2016
2016
-
[15]
A reduction of imitation learning and structured prediction to no-regret online learning
St ´ephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
2011
-
[16]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Abhik Singla, Sindhu Padakandla, and Shalabh Bhatnagar. Memory- based deep reinforcement learning for obstacle avoidance in uav with limited environment knowledge.IEEE transactions on intelligent trans- portation systems, 22(1):107–118, 2019
2019
-
[18]
Icra 2022 dodgedrone challenge: Vision-based agile drone flight
Yunlong Song, Elia Kaufmann, Leonard Bauersfeld, Antonio Loquercio, and Davide Scaramuzza. Icra 2022 dodgedrone challenge: Vision-based agile drone flight. Presented at the IEEE ICRA 2022, 2022
2022
-
[19]
Learning perception-aware agile flight in cluttered environments
Yunlong Song, Kexin Shi, Robert Penicka, and Davide Scaramuzza. Learning perception-aware agile flight in cluttered environments. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 1989–1995. IEEE, 2023
2023
-
[20]
Efficient trajectory library filtering for quadrotor flight in unknown environments
Vaibhav Viswanathan, Eric Dexheimer, Guanrui Li, and et al. Efficient trajectory library filtering for quadrotor flight in unknown environments. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2510–2517, 2020
2020
-
[21]
Hang Yu, Guido CH de Croon, and Christophe De Wagter. Avoidbench: A high-fidelity vision-based obstacle avoidance benchmarking suite for multi-rotors.arXiv preprint arXiv:2301.07430, 2023
-
[22]
Mavrl: Learn to fly in cluttered environments with varying speed.IEEE Robotics and Automation Letters, 2024
Hang Yu, Christophe De Wagter, and Guido CH E de Croon. Mavrl: Learn to fly in cluttered environments with varying speed.IEEE Robotics and Automation Letters, 2024
2024
-
[23]
Computational benefits of intermediate rewards for goal-reaching policy learning.Journal of Artificial Intelligence Research, 73:847–896, 2022
Yuexiang Zhai, Christina Baek, Zhengyuan Zhou, Jiantao Jiao, and Yi Ma. Computational benefits of intermediate rewards for goal-reaching policy learning.Journal of Artificial Intelligence Research, 73:847–896, 2022
2022
-
[24]
Dingqi Zhang, Antonio Loquercio, Jerry Tang, Ting-Hao Wang, Jitendra Malik, and Mark W. Mueller. A learning-based quadcopter controller with extreme adaptation, 2024
2024
-
[25]
Monocular depth estimation for drone obstacle avoidance in indoor environments
Haokun Zheng, Sidhant Rajadnya, and Avideh Zakhor. Monocular depth estimation for drone obstacle avoidance in indoor environments. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10027–10034. IEEE, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.