Boosted Stochastic Frank-Wolfe for Constrained Nonconvex Optimization
Pith reviewed 2026-06-29 23:20 UTC · model grok-4.3
The pith
A step size strategy independent of the gradient Lipschitz constant extends boosted Frank-Wolfe to stochastic nonconvex constrained problems while preserving standard convergence rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing a step size strategy independent of the gradient's Lipschitz constant, the boosted Frank-Wolfe algorithm can be applied in the stochastic regime to nonconvex and quasar-convex constrained optimization problems. The boosted updates, which better align with the negative gradient, maintain the worst-case convergence guarantees of standard stochastic Frank-Wolfe when used with modern estimators like SAGA and zeroth-order methods. This yields the first such rates for boosted Frank-Wolfe beyond convex deterministic settings.
What carries the argument
The novel step size strategy that avoids dependence on the Lipschitz constant of the gradient while ensuring valid updates with stochastic estimators.
If this is right
- Retains convergence rates of stochastic Frank-Wolfe when combined with SAGA, L-SVRG, SAG, Heavy Ball momentum, and zeroth-order estimators.
- Provides first convergence rates for boosted Frank-Wolfe on nonconvex objectives.
- Provides first convergence rates for boosted Frank-Wolfe on quasar-convex objectives.
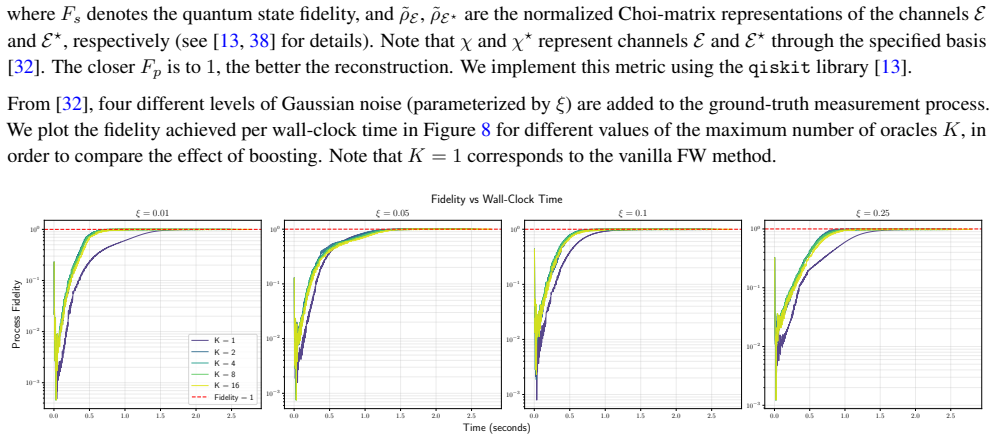
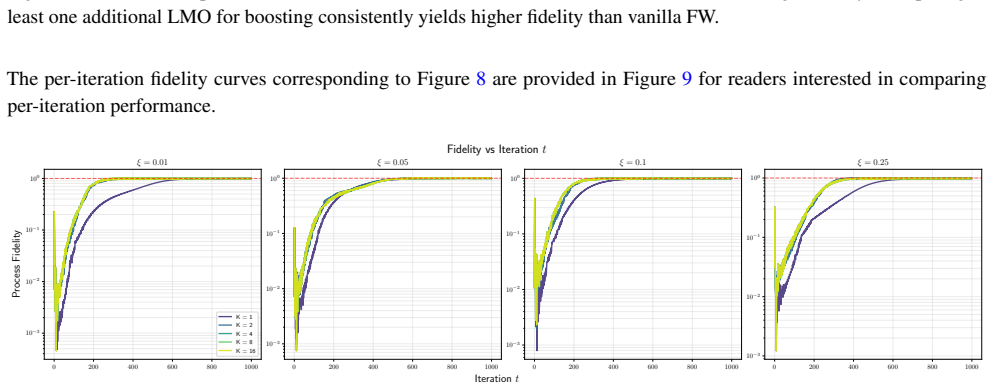
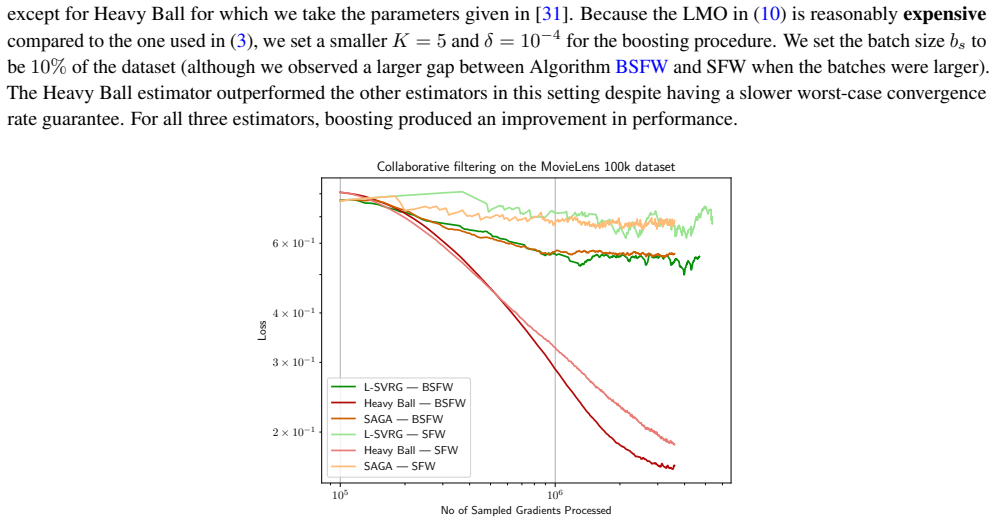
- Achieves faster convergence per gradient oracle call in experiments on sparse logistic regression and quantum process tomography.
Where Pith is reading between the lines
- This step size rule could be adapted to other accelerated first-order methods in constrained settings.
- The method may offer practical advantages in high-dimensional problems where computing Lipschitz constants is infeasible.
- Further analysis might explore the method's behavior under different noise models in stochastic gradients.
Load-bearing premise
The new step size strategy can be defined and produces valid updates without knowledge of the gradient Lipschitz constant even when using stochastic estimators.
What would settle it
Observing that the boosted stochastic Frank-Wolfe fails to achieve the claimed convergence rates on a nonconvex constrained problem when using the proposed step size with a stochastic estimator such as SAGA would falsify the claim.
Figures

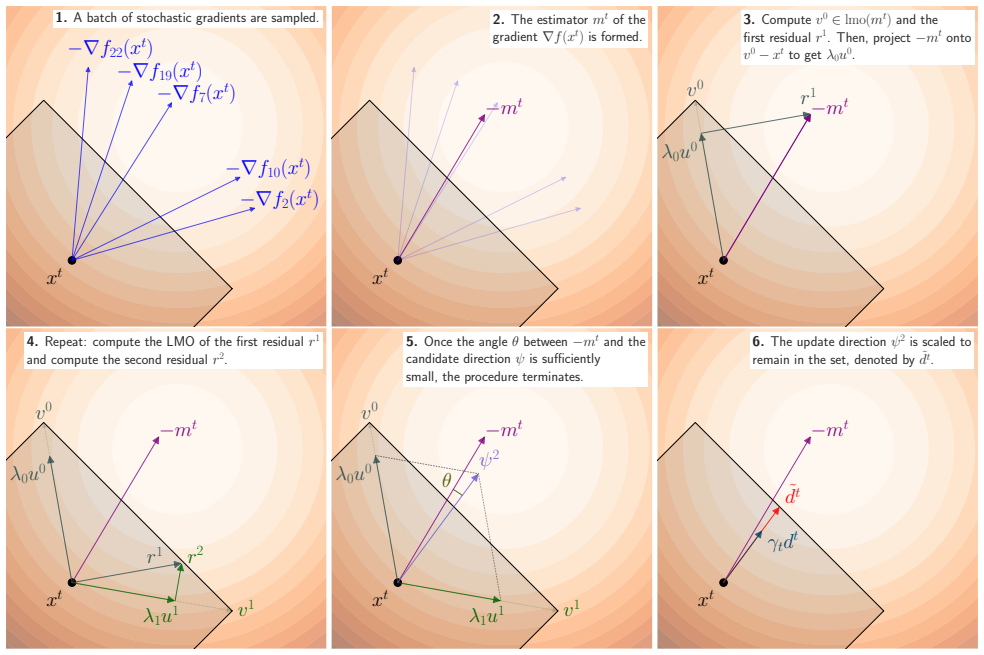
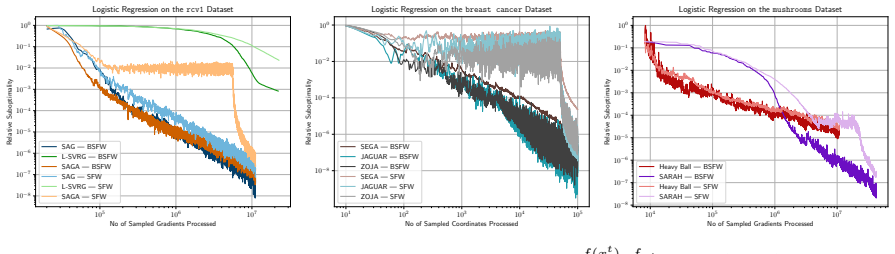


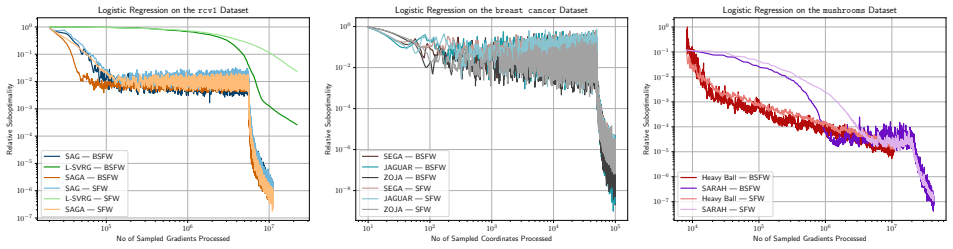
read the original abstract
The boosted Frank-Wolfe algorithm accelerates the classical Frank-Wolfe algorithm by better aligning the update direction with the negative gradient. Its analysis, however, has been limited to deterministic convex problems, with step sizes that require either line search or knowledge of the Lipschitz constant of the gradient. We develop a novel step size strategy that does not depend on the Lipschitz constant of the gradient, which allows us to extend the boosted Frank-Wolfe algorithm to the stochastic setting. We prove that boosting with this step size strategy can be combined with many modern gradient estimators, including SAGA, L-SVRG, SAG, Heavy Ball momentum, and zeroth-order estimators, among others, while retaining the worst-case convergence rates of ordinary stochastic Frank-Wolfe. Our analysis also yields the first convergence rates for boosted Frank-Wolfe on nonconvex and quasar-convex objectives, results which are new even for deterministic problems. Experiments on sparse logistic regression and quantum process tomography show that stochastic boosted Frank-Wolfe achieves faster convergence per gradient oracle call (and on wall-clock) compared to the non-boosted baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a boosted stochastic Frank-Wolfe algorithm for constrained optimization, including nonconvex and quasar-convex cases. It introduces a novel step-size rule independent of the gradient Lipschitz constant that permits the boosted direction to be combined with stochastic estimators (SAGA, L-SVRG, SAG, Heavy-Ball momentum, zeroth-order) while retaining the worst-case rates of ordinary stochastic Frank-Wolfe. The analysis supplies the first convergence guarantees for boosted Frank-Wolfe on nonconvex and quasar-convex objectives (new even in the deterministic setting). Experiments on sparse logistic regression and quantum process tomography report faster convergence per gradient oracle call and in wall-clock time relative to the non-boosted baseline.
Significance. If the central claims hold, the work meaningfully extends the practical reach of Frank-Wolfe methods by removing the need for the Lipschitz constant and by demonstrating compatibility with a broad family of modern gradient estimators. The new nonconvex and quasar-convex rates constitute a clear theoretical advance. The parameter-free step-size rule and the preservation of existing rates are concrete strengths that would be useful to practitioners working with constrained stochastic problems.
minor comments (3)
- The abstract states that the step-size strategy is analyzed without access to the Lipschitz constant; the main text should explicitly locate the definition of this rule (e.g., the precise formula and the section containing its proof) so that readers can verify independence from L.
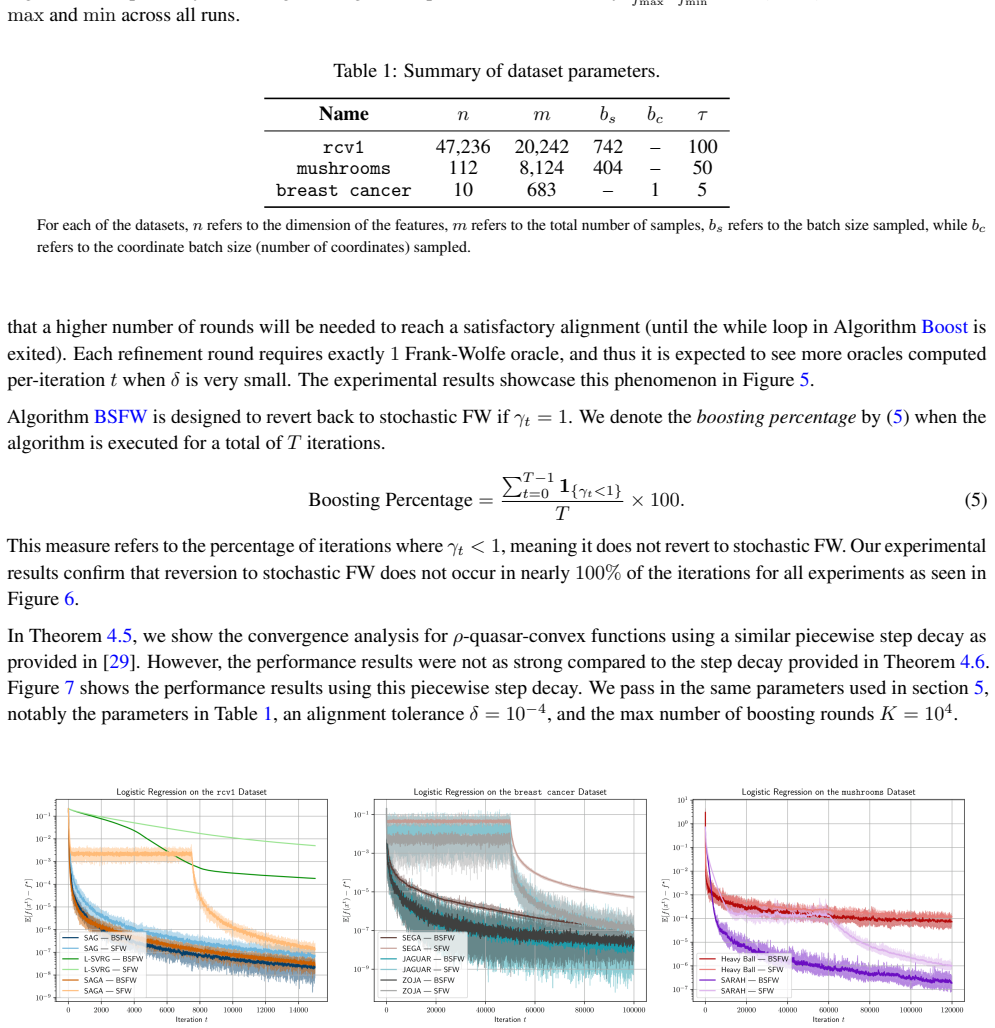
- Table or figure captions for the experimental results should report the precise problem dimensions, number of runs, and whether error bars represent standard deviation or standard error.
- A short remark clarifying whether the quasar-convex rate requires any additional structural assumptions beyond those stated for the nonconvex case would improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the parameter-free step-size rule, compatibility with multiple gradient estimators, and the new nonconvex/quasar-convex rates (even in the deterministic case). We appreciate the recommendation for minor revision.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a novel step-size rule independent of the gradient Lipschitz constant, then proves that boosted Frank-Wolfe combined with this rule retains the worst-case rates of ordinary stochastic Frank-Wolfe when paired with SAGA, L-SVRG, SAG, Heavy-Ball, and zeroth-order estimators. The same analysis supplies the first rates for nonconvex and quasar-convex objectives. These claims rest on explicit rate statements that are not obtained by fitting parameters to the target quantities or by renaming prior results; the step-size construction is presented as an independent derivation rather than a self-definition. Experiments on sparse logistic regression and quantum process tomography supply separate empirical checks. No load-bearing equation reduces to its own inputs by construction, and no self-citation chain is invoked to justify uniqueness or the central rates.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions on objective smoothness, constraint set, and gradient estimator properties typical for Frank-Wolfe analyses
Reference graph
Works this paper leans on
-
[1]
A. Beznosikov, D. Dobre, and G. Gidel. Sarah Frank-Wolfe: Methods for constrained optimization with best rates and practical features.Available from: arXiv:2304.11737, 2024
-
[2]
Chang and C.-J
C.-C. Chang and C.-J. Lin. LIBSVM: A library for support vector machines.ACM Transactions on Intelligent Systems and Technology (TIST), 2(3):1–27, 2011
2011
-
[3]
Combettes and S
C. Combettes and S. Pokutta. Boosting Frank-Wolfe by chasing gradients. InInternational Conference on Machine Learning, pages 2111–2121. PMLR, 2020
2020
-
[4]
C. W. Combettes and S. Pokutta. Complexity of linear minimization and projection on some sets.Operations Research Letters, 49(4):565–571, 2021
2021
-
[5]
S. Ding, L. Yang, L. Luo, and C. Fang. Optimizing over multiple distributions under generalized quasar-convexity condition.Advances in Neural Information Processing Systems, 37:4718–4764, 2024. 53
2024
-
[6]
D. J. Foster, A. Sekhari, and K. Sridharan. Uniform convergence of gradients for non-convex learning and optimization. Advances in Neural Information Processing Systems, 31, 2018
2018
-
[7]
Frank and P
M. Frank and P. Wolfe. An algorithm for quadratic programming.Naval Research Logistics Quarterly, 3(1-2):95–110, 1956
1956
-
[8]
Q. Fu, D. Xu, and A. C. Wilson. Accelerated stochastic optimization methods under quasar-convexity. InInternational Conference on Machine Learning, pages 10431–10460. PMLR, 2023
2023
-
[9]
Guélat and P
J. Guélat and P. Marcotte. Some comments on Wolfe’s ‘away step’.Mathematical Programming, 35(1):110–119, 1986
1986
-
[10]
Hanzely, K
F. Hanzely, K. Mishchenko, and P. Richtárik. SEGA: Variance reduction via gradient sketching.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[11]
Hardt, T
M. Hardt, T. Ma, and B. Recht. Gradient descent learns linear dynamical systems.Journal of Machine Learning Research, 19(29):1–44, 2018
2018
-
[12]
F. M. Harper and J. A. Konstan. The movielens datasets: History and context.ACM Transactions on Interactive Intelligent Systems (TIIS), 5(4):1–19, 2015
2015
-
[13]
A. Javadi-Abhari, M. Treinish, K. Krsulich, C. J. Wood, J. Lishman, J. Gacon, S. Martiel, P. D. Nation, L. S. Bishop, A. W. Cross, et al. Quantum computing with qiskit.Available from: arXiv:2405.08810, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
A. Khademi. The convexity zoo: a taxonomy of function classes in optimization.Optimization, pages 1–52, 2026
2026
-
[15]
A. Khademi and A. Silveti-Falls. Adaptive conditional gradient descent.Available from: arXiv:2510.11440, 2025
-
[16]
Kovalev, S
D. Kovalev, S. Horváth, and P. Richtárik. Don’t jump through hoops and remove those loops: SVRG and Katyusha are better without the outer loop. InAlgorithmic Learning Theory, pages 451–467. PMLR, 2020
2020
-
[17]
Lacoste-Julien and M
S. Lacoste-Julien and M. Jaggi. On the global linear convergence of Frank-Wolfe optimization variants.Advances in Neural Information Processing Systems, 28, 2015
2015
-
[18]
Lara and C
F. Lara and C. Vega. Delayed feedback in online non-convex optimization: a non-stationary approach with applications. Numerical Algorithms, pages 1–42, 2025
2025
-
[19]
E. S. Levitin and B. T. Polyak. Constrained minimization methods.USSR Computational Mathematics and Mathematical Physics, 6(5):1–50, 1966
1966
-
[20]
D. D. Lewis, Y . Yang, T. G. Rose, and F. Li. Rcv1: A new benchmark collection for text categorization research. Journal of Machine Learning Research, 5:361–397, 2004
2004
-
[21]
Z. Li, H. Bao, X. Zhang, and P. Richtárik. PAGE: A simple and optimal probabilistic gradient estimator for nonconvex optimization. InInternational Conference on Machine Learning, pages 6286–6295. PMLR, 2021
2021
- [22]
-
[23]
Locatello, M
F. Locatello, M. Tschannen, G. Rätsch, and M. Jaggi. Greedy algorithms for cone constrained optimization with convergence guarantees.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[24]
T. Ma. Why do local methods solve.Beyond the Worst-Case Analysis of Algorithms, page 465, 2021
2021
-
[25]
D. Martínez-Rubio. Smooth quasar-convex optimization with constraints.Available from: arXiv:2510.01943, 2025
- [26]
-
[27]
Mokhtari, H
A. Mokhtari, H. Hassani, and A. Karbasi. Stochastic conditional gradient methods: From convex minimization to submodular maximization.Journal of Machine Learning Research, 21(105):1–49, 2020. 54
2020
-
[28]
UCI Machine Learning Repository.Dataset, 1981
Mushroom Dataset. UCI Machine Learning Repository.Dataset, 1981
1981
-
[29]
Nazykov, A
R. Nazykov, A. Shestakov, V . Solodkin, A. Beznosikov, G. Gidel, and A. Gasnikov. Stochastic Frank-Wolfe: Unified analysis and zoo of special cases. InInternational Conference on Artificial Intelligence and Statistics, pages 4870–4878. PMLR, 2024
2024
-
[30]
Négiar, G
G. Négiar, G. Dresdner, A. Tsai, L. El Ghaoui, F. Locatello, R. Freund, and F. Pedregosa. Stochastic Frank-Wolfe for constrained finite-sum minimization. InInternational Conference on Machine Learning, pages 7253–7262. PMLR, 2020
2020
-
[31]
Training Deep Learning Models with Norm-Constrained LMOs
T. Pethick, W. Xie, K. Antonakopoulos, Z. Zhu, A. Silveti-Falls, and V . Cevher. Training deep learning models with norm-constrained LMOs.Available from: arXiv:2502.07529, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [32]
-
[33]
S. J. Reddi, S. Sra, B. Póczos, and A. Smola. Stochastic Frank-Wolfe methods for nonconvex optimization. In2016 54th Annual Allerton Conference on Communication, Control, and Computing (Allerton), pages 1244–1251. IEEE, 2016
2016
-
[34]
K. K. Tsuji, K. Tanaka, and S. Pokutta. Pairwise conditional gradients without swap steps and sparser kernel herding. InInternational Conference on Machine Learning, pages 21864–21883. PMLR, 2022
2022
-
[35]
J.-K. Wang and A. Wibisono. Continuized acceleration for quasar convex functions in non-convex optimization. Available from: arXiv:2302.07851, 2023
-
[36]
W. Wolberg. Breast Cancer Wisconsin (Original).UCI Machine Learning Repository, 1990. Dataset
1990
-
[37]
P. Wolfe. Convergence theory in nonlinear programming.Integer and Nonlinear Programming, pages 1–36, 1970
1970
-
[38]
C. J. Wood, J. D. Biamonte, and D. G. Cory. Tensor networks and graphical calculus for open quantum systems. Available from: arXiv:1111.6950, 2015. 55
work page internal anchor Pith review Pith/arXiv arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.