Simulating Human Memory with Language Models
Pith reviewed 2026-06-29 21:58 UTC · model grok-4.3
The pith
Language models remember information more reliably than humans across classic psychology tasks, even when prompted to imitate human behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
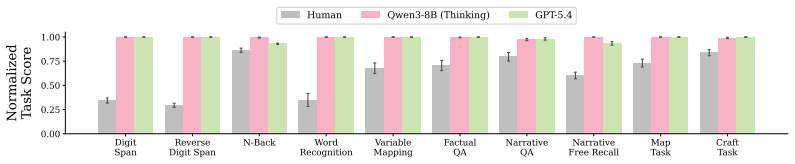
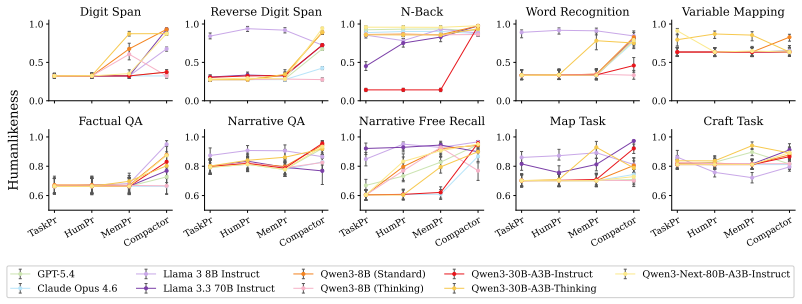
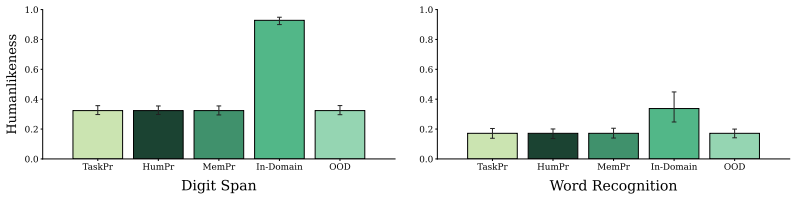
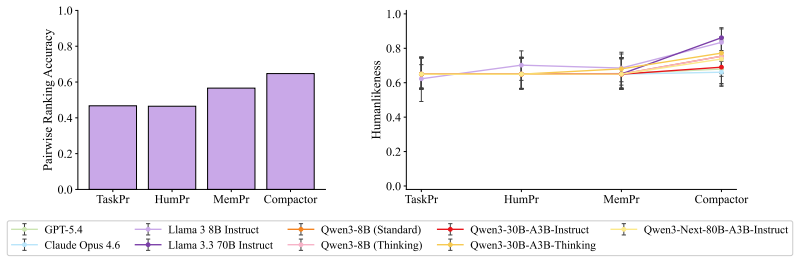
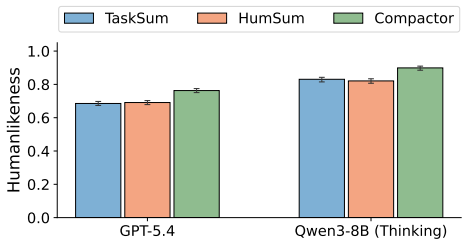
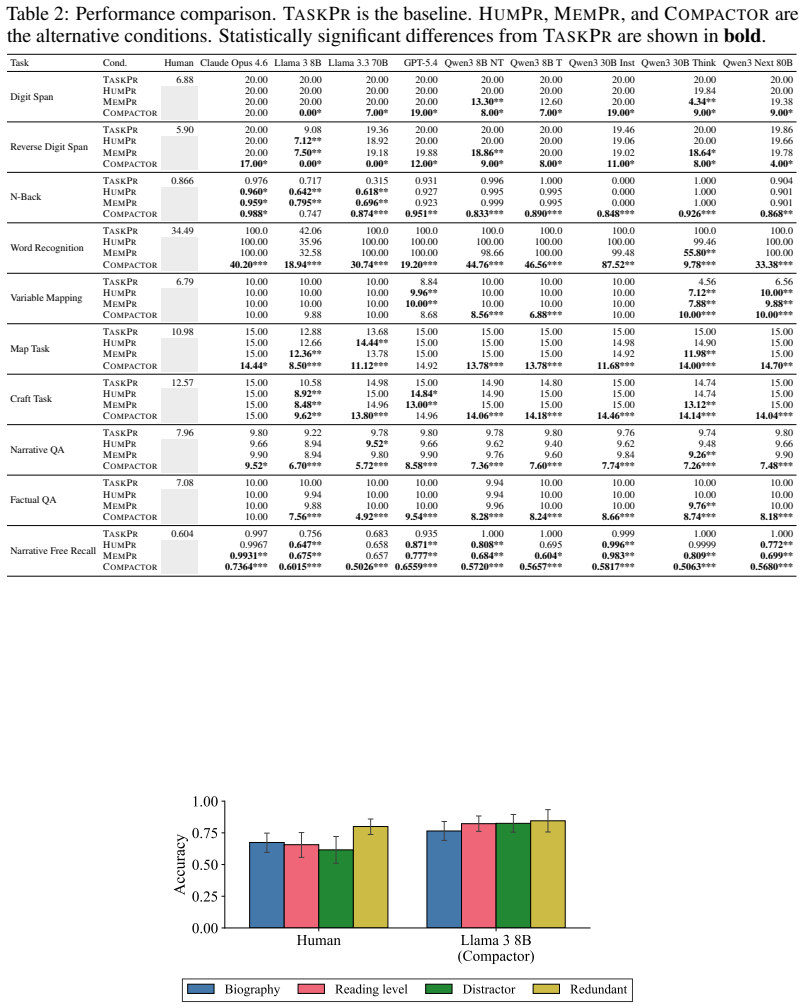
Out-of-the-box language models exhibit better memory than humans across a series of classic psychology experiments, even when prompted to imitate human behavior. Better prompting strategies and the use of a compactor can cause language models to forget content in a more human-like way. Language models with these human-like memory constraints function as more effective user simulators in a downstream education task.
What carries the argument
A compactor together with prompting strategies that induce human-like forgetting in language models.
If this is right
- Out-of-the-box language models retain more information than humans in memory tasks.
- Prompting strategies plus a compactor produce forgetting patterns that match human data more closely.
- Language models with human-like memory constraints improve performance as user simulators in education tasks.
- New human reference data and benchmarks are now available for testing memory simulation methods.
Where Pith is reading between the lines
- The same adjustment methods could be tested in other interactive domains such as customer support or collaborative problem solving.
- If the memory constraints scale, they might allow simulators to replace some human-subject studies in interface design.
- The gap in raw memory reliability may explain why current simulators sometimes produce unrealistically consistent user responses.
- Future work could measure whether the compactor affects other cognitive aspects beyond memory alone.
Load-bearing premise
The classic memory experiments from psychology serve as valid proxies for the memory demands that arise when language models act as user simulators in interactive tasks such as education.
What would settle it
A direct comparison in which language models with induced forgetting perform no better than unmodified models when simulating users in actual educational dialogues would falsify the claim that human-like memory constraints improve simulator effectiveness.
Figures

read the original abstract
Language models are increasingly being deployed as user simulators, but their memory is far more reliable than that of real users. To measure this gap, we run a series of classic memory experiments from psychology on both humans and language models. Across tasks, we find that out-of-the-box language models exhibit better memory than humans, even when prompted to imitate human behavior. We then show that better prompting strategies and the use of a compactor can cause language models to forget content in a more human-like way. Using these methods, we show preliminary evidence that language models with human-like memory constraints can function as more effective user simulators in a downstream education task. Finally, we release human reference data and benchmarks to support future work on simulating human memory with language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that out-of-the-box language models exhibit superior memory performance compared to humans across classic psychology memory experiments, even when prompted to imitate human behavior. It further claims that improved prompting and a 'compactor' mechanism can induce more human-like forgetting patterns in LMs, and provides preliminary evidence that LMs constrained in this way serve as more effective user simulators in a downstream education task. Human reference data and benchmarks are released to support future work.
Significance. If the empirical comparisons and downstream results hold after proper statistical validation and proxy testing, the work could support development of more realistic LM-based user simulators for interactive applications such as education by addressing the reliability gap in memory. The release of human data and benchmarks is a constructive contribution for reproducibility in this area.
major comments (3)
- [Abstract] Abstract: the abstract states clear empirical findings but provides no sample sizes, statistical tests, error bars, or details on how the compactor is implemented or evaluated; the central claim cannot be assessed from the given text alone.
- [Downstream education task] Downstream education task: the claim that language models with human-like memory constraints function as more effective user simulators rests on the untested assumption that forgetting patterns from classic one-shot recall or list-learning experiments transfer to memory failures in multi-turn interactive tutoring (context tracking, personalization, error recovery); no evidence is provided that the specific human-like forgetting (vs. any capacity reduction) drives the reported gain.
- [Methods] Methods/implementation: details on the compactor's architecture, training or prompting procedure, and quantitative evaluation against human forgetting curves are absent, which are load-bearing for reproducing the human-like forgetting result and the education-task improvement.
minor comments (1)
- [Abstract] Abstract: the term 'compactor' is introduced without a brief definition or citation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract states clear empirical findings but provides no sample sizes, statistical tests, error bars, or details on how the compactor is implemented or evaluated; the central claim cannot be assessed from the given text alone.
Authors: We agree that the abstract would benefit from these specifics. In revision we will expand the abstract to report sample sizes for the human and LM experiments, reference the statistical tests performed, note error bars in the relevant figures, and include a concise description of the compactor and its evaluation. revision: yes
-
Referee: [Downstream education task] Downstream education task: the claim that language models with human-like memory constraints function as more effective user simulators rests on the untested assumption that forgetting patterns from classic one-shot recall or list-learning experiments transfer to memory failures in multi-turn interactive tutoring (context tracking, personalization, error recovery); no evidence is provided that the specific human-like forgetting (vs. any capacity reduction) drives the reported gain.
Authors: We acknowledge the point. The manuscript presents preliminary evidence that the constrained models improve simulator performance on the education task, yet it does not contain controls isolating the contribution of the specific human-like forgetting curve versus general capacity reduction. We will revise the discussion to explicitly state this limitation and its implications for causal interpretation. revision: partial
-
Referee: [Methods] Methods/implementation: details on the compactor's architecture, training or prompting procedure, and quantitative evaluation against human forgetting curves are absent, which are load-bearing for reproducing the human-like forgetting result and the education-task improvement.
Authors: We agree these details are necessary. The revised manuscript will expand the Methods section to describe the compactor architecture, the prompting and compaction procedures, and the quantitative metrics used to compare induced forgetting curves against the released human benchmarks. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential fits
full rationale
The paper reports direct experimental results from running classic psychology memory tasks on humans and LMs, followed by empirical tests of prompting/compactor methods and a downstream education task. No equations, parameter fits, uniqueness theorems, or self-citations are invoked as load-bearing steps in any derivation chain. All reported outcomes (better LM memory, human-like forgetting via interventions, improved simulator performance) are measured quantities, not quantities defined by the authors' own modeling choices. This is the standard case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Classic psychology memory experiments measure the memory properties relevant to language-model user simulation in downstream tasks.
invented entities (1)
-
compactor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A systematic comparison of syllogistic reasoning in humans and language models
Tiwalayo Eisape, Michael Tessler, Ishita Dasgupta, Fei Sha, Sjoerd Steenkiste, and Tal Linzen. A systematic comparison of syllogistic reasoning in humans and language models. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Langu...
2024
-
[2]
User simulators bridge RL with real-world interaction
Jessy Lin and Nicholas Tomlin. User simulators bridge RL with real-world interaction. https: //jessylin.com/2025/07/10/user-simulators-1/
2025
-
[3]
TutorUp: What if your students were simulated? Training tutors to address engagement challenges in online learning
Sitong Pan, Robin Schmucker, Bernardo Garcia Bulle Bueno, Salome Aguilar Llanes, Fernanda Albo Alarcón, Hangxiao Zhu, Adam Teo, and Meng Xia. TutorUp: What if your students were simulated? Training tutors to address engagement challenges in online learning. InProceedings of the 2025 CHI conference on human factors in computing systems, pages 1–18, 2025
2025
-
[4]
Can LLM-simulated practice and feedback upskill human counselors? A randomized study with 90+ novice counselors
Ryan Louie, Raj Sanjay Shah, Ifdita Hasan Orney, Juan Pablo Pacheco, Emma Brunskill, and Diyi Yang. Can LLM-simulated practice and feedback upskill human counselors? A randomized study with 90+ novice counselors. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems, pages 1–31, 2026
2026
-
[5]
LLM Agents Grounded in Self-Reports Enable General-Purpose Simulation of Individuals
Joon Sung Park, Carolyn Q Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, and Michael S Bernstein. Generative agent simulations of 1,000 people.arXiv preprint arXiv:2411.10109, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Building machines that learn and think like people.Behavioral and brain sciences, 40:e253, 2017
Brenden M Lake, Tomer D Ullman, Joshua B Tenenbaum, and Samuel J Gershman. Building machines that learn and think like people.Behavioral and brain sciences, 40:e253, 2017
2017
-
[7]
To model human linguistic prediction, make LLMs less superhuman
Byung-Doh Oh and Tal Linzen. To model human linguistic prediction, make LLMs less superhuman.arXiv preprint arXiv:2510.05141, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Characterizing verbatim short-term memory in neural language models
Kristijan Armeni, Christopher Honey, and Tal Linzen. Characterizing verbatim short-term memory in neural language models. InProceedings of the 26th Conference on Computational Natural Language Learning (CoNLL), pages 405–424, 2022
2022
-
[9]
Benchmarks for models of short-term and working memory.Psychological Bulletin, 144(9):885, 2018
Klaus Oberauer, Stephan Lewandowsky, Edward Awh, Gordon DA Brown, Andrew Conway, Nelson Cowan, Christopher Donkin, Simon Farrell, Graham J Hitch, Mark J Hurlstone, et al. Benchmarks for models of short-term and working memory.Psychological Bulletin, 144(9):885, 2018
2018
-
[10]
The magical number 4 in short-term memory: A reconsideration of mental storage capacity.Behavioral and Brain Sciences, 24(1):87–114, 2001
Nelson Cowan. The magical number 4 in short-term memory: A reconsideration of mental storage capacity.Behavioral and Brain Sciences, 24(1):87–114, 2001. 10
2001
-
[11]
Zhaoyang Cao, Lael Schooler, and Reza Zafarani. Analyzing memory effects in large language models through the lens of cognitive psychology.arXiv preprint arXiv:2509.17138, 2025
-
[12]
Are frequent phrases directly retrieved like idioms? An investigation with self-paced reading and language models
Giulia Rambelli, Emmanuele Chersoni, Marco SG Senaldi, Philippe Blache, and Alessandro Lenci. Are frequent phrases directly retrieved like idioms? An investigation with self-paced reading and language models. InProceedings of the 19th Workshop on Multiword Expressions (MWE 2023), pages 87–98, 2023
2023
-
[13]
R Thomas McCoy, Paul Smolensky, Tal Linzen, Jianfeng Gao, and Asli Celikyilmaz. How much do language models copy from their training data? evaluating linguistic novelty in text generation using raven.Transactions of the Association for Computational Linguistics, 11:652–670, 2023
2023
-
[14]
Humans and language models diverge when predicting repeating text
Aditya Vaidya, Javier Turek, and Alexander Huth. Humans and language models diverge when predicting repeating text. InProceedings of the 27th Conference on Computational Natural Language Learning (CoNLL), pages 58–69, 2023
2023
-
[15]
Bigger is not always better: The importance of human-scale language modeling for psycholinguistics.Journal of Memory and Language, 144:104650, 2025
Ethan Gotlieb Wilcox, Michael Y Hu, Aaron Mueller, Alex Warstadt, Leshem Choshen, Chengxu Zhuang, Adina Williams, Ryan Cotterell, and Tal Linzen. Bigger is not always better: The importance of human-scale language modeling for psycholinguistics.Journal of Memory and Language, 144:104650, 2025
2025
-
[16]
Abishek Thamma and Micha Heilbron. Human-like fleeting memory improves language learning but impairs reading time prediction in transformer language models.arXiv preprint arXiv:2508.05803, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Locally biased transformers better align with human reading times
Andrea De Varda and Marco Marelli. Locally biased transformers better align with human reading times. InProceedings of the workshop on cognitive modeling and computational linguistics, pages 30–36, 2024
2024
-
[18]
Linear recency bias during training improves transformers’ fit to reading times
Christian Clark, Byung-Doh Oh, and William Schuler. Linear recency bias during training improves transformers’ fit to reading times. InProceedings of the 31st International Conference on Computational Linguistics, pages 7735–7747, 2025
2025
-
[19]
A foundation model to predict and capture human cognition.Nature, 644(8078):1002–1009, 2025
Marcel Binz, Elif Akata, Matthias Bethge, Franziska Brändle, Fred Callaway, Julian Coda- Forno, Peter Dayan, Can Demircan, Maria K Eckstein, Noémi Éltet˝o, et al. A foundation model to predict and capture human cognition.Nature, 644(8078):1002–1009, 2025
2025
-
[20]
HippoRAG: Neurobio- logically inspired long-term memory for large language models.Advances in neural information processing systems, 37:59532–59569, 2024
Bernal J Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. HippoRAG: Neurobio- logically inspired long-term memory for large language models.Advances in neural information processing systems, 37:59532–59569, 2024
2024
-
[21]
arXiv preprint arXiv:2407.09450 (2024)
Zafeirios Fountas, Martin A Benfeghoul, Adnan Oomerjee, Fenia Christopoulou, Gerasimos Lampouras, Haitham Bou-Ammar, and Jun Wang. Human-inspired episodic memory for infinite context LLMs.arXiv preprint arXiv:2407.09450, 2024
-
[22]
Towards large language models with human-like episodic memory.Trends in Cognitive Sciences, 2025
Cody V Dong, Qihong Lu, Kenneth A Norman, and Sebastian Michelmann. Towards large language models with human-like episodic memory.Trends in Cognitive Sciences, 2025
2025
-
[23]
Sangyeop Kim, Yohan Lee, Sanghwa Kim, Hyunjong Kim, and Sungzoon Cho
Kuang-Huei Lee, Xinyun Chen, Hiroki Furuta, John Canny, and Ian Fischer. A human-inspired reading agent with gist memory of very long contexts.arXiv preprint arXiv:2402.09727, 2024
-
[24]
Hailong Li, Feifei Li, Wenhui Que, and Xingyu Fan. Himes: Hippocampus-inspired memory system for personalized AI assistants.arXiv preprint arXiv:2601.06152, 2026
-
[25]
Transformer-XL: Attentive language models beyond a fixed-length context
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G Carbonell, Quoc Le, and Ruslan Salakhutdinov. Transformer-XL: Attentive language models beyond a fixed-length context. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 2978–2988, 2019
2019
-
[26]
Recurrent memory transformer.Advances in Neural Information Processing Systems, 35:11079–11091, 2022
Aydar Bulatov, Yury Kuratov, and Mikhail Burtsev. Recurrent memory transformer.Advances in Neural Information Processing Systems, 35:11079–11091, 2022. 11
2022
-
[27]
MemoryLLM: Towards self-updatable large language models.arXiv preprint arXiv:2402.04624, 2024
Yu Wang, Yifan Gao, Xiusi Chen, Haoming Jiang, Shiyang Li, Jingfeng Yang, Qingyu Yin, Zheng Li, Xian Li, Bing Yin, et al. MemoryLLM: Towards self-updatable large language models.arXiv preprint arXiv:2402.04624, 2024
-
[28]
M+: Extending MemoryLLM with scalable long-term memory.arXiv preprint arXiv:2502.00592, 2025
Yu Wang, Dmitry Krotov, Yuanzhe Hu, Yifan Gao, Wangchunshu Zhou, Julian McAuley, Dan Gutfreund, Rogerio Feris, and Zexue He. M+: Extending MemoryLLM with scalable long-term memory.arXiv preprint arXiv:2502.00592, 2025
-
[29]
Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
2024
-
[30]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. YaRN: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
A controlled study on long context extension and generalization in LLMs, 2025
Yi Lu, Jing Nathan Yan, Songlin Yang, Justin T Chiu, Siyu Ren, Fei Yuan, Wenting Zhao, Zhiyong Wu, and Alexander M Rush. A controlled study on long context extension and generalization in LLMs, 2025
2025
-
[32]
Extending Context Window of Large Language Models via Positional Interpolation
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation.arXiv preprint arXiv:2306.15595, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[34]
Yu Wang, Xinshuang Liu, Xiusi Chen, Sean O’Brien, Junda Wu, and Julian McAuley. Self- updatable large language models by integrating context into model parameters.arXiv preprint arXiv:2410.00487, 2024
-
[35]
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, et al. Conditional memory via scalable lookup: A new axis of sparsity for large language models.arXiv preprint arXiv:2601.07372, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Continual learning via sparse memory finetuning, 2025
Jessy Lin, Luke Zettlemoyer, Gargi Ghosh, Wen-Tau Yih, Aram Markosyan, Vincent-Pierre Berges, and Barlas O˘guz. Continual learning via sparse memory finetuning, 2025
2025
-
[37]
Haoran Sun and Shaoning Zeng. Hierarchical memory for high-efficiency long-term reasoning in LLM agents.arXiv preprint arXiv:2507.22925, 2025
-
[38]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Mensink, Andrew Elfenbein, and Dongyeop Kang
Karin de Langis, Jong Inn Park, Bin Hu, Khanh Chi Le, Andreas Schramm, Michael C. Mensink, Andrew Elfenbein, and Dongyeop Kang. Strong memory, weak control: An empirical study of executive functioning in LLMs. In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors,Proceedings of the 19th Conference of the European Chapter of the Association for Computa...
-
[41]
Association for Computational Linguistics
-
[42]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
2024
-
[43]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- MemEval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in LLM agents via incremental multi-turn interactions.arXiv preprint arXiv:2507.05257, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Darshan Deshpande, Varun Gangal, Hersh Mehta, Anand Kannappan, Rebecca Qian, and Peng Wang. MEMTRACK: Evaluating long-term memory and state tracking in multi-platform dynamic agent environments.arXiv preprint arXiv:2510.01353, 2025
-
[46]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
2023
-
[47]
Scaling Synthetic Data Creation with 1,000,000,000 Personas
Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. Scaling synthetic data creation with 1,000,000,000 personas.arXiv preprint arXiv:2406.20094, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Pranav Narayanan Venkit, Yu Li, Yada Pruksachatkun, and Chien-Sheng Wu. The need for a socially-grounded persona framework for user simulation.arXiv preprint arXiv:2601.07110, 2026
-
[49]
Enoch Hyunwook Kang. LLM personas as a substitute for field experiments in method benchmarking.arXiv preprint arXiv:2512.21080, 2025
-
[50]
User behavior simulation with large language model-based agents.ACM Transactions on Information Systems, 43(2):1–37, 2025
Lei Wang, Jingsen Zhang, Hao Yang, Zhi-Yuan Chen, Jiakai Tang, Zeyu Zhang, Xu Chen, Yankai Lin, Hao Sun, Ruihua Song, et al. User behavior simulation with large language model-based agents.ACM Transactions on Information Systems, 43(2):1–37, 2025
2025
-
[51]
S$^3$: Social-network Simulation System with Large Language Model-Empowered Agents
Chen Gao, Xiaochong Lan, Zhihong Lu, Jinzhu Mao, Jinghua Piao, Huandong Wang, Depeng Jin, and Yong Li. S3: Social-network simulation system with large language model-empowered agents.arXiv preprint arXiv:2307.14984, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
AgentSociety: Large-scale simulation of LLM-driven generative agents advances understanding of human behaviors and society
Jinghua Piao, Yuwei Yan, Jun Zhang, Nian Li, Junbo Yan, Xiaochong Lan, Zhihong Lu, Zhiheng Zheng, Jing Yi Wang, Di Zhou, et al. AgentSociety: Large-scale simulation of LLM-driven generative agents advances understanding of human behaviors and society. 2025
2025
-
[53]
Ziyi Yang, Zaibin Zhang, Zirui Zheng, Yuxian Jiang, Ziyue Gan, Zhiyu Wang, Zijian Ling, Jinsong Chen, Martz Ma, Bowen Dong, et al. OASIS: Open agent social interaction simulations with one million agents.arXiv preprint arXiv:2411.11581, 2024
-
[54]
Mosaic: Modeling social AI for content dissemination and regulation in multi-agent simulations
Genglin Liu, Vivian T Le, Salman Rahman, Elisa Kreiss, Marzyeh Ghassemi, and Saadia Gabriel. Mosaic: Modeling social AI for content dissemination and regulation in multi-agent simulations. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6401–6428, 2025
2025
-
[55]
Shenzhe Zhu, Jiao Sun, Yi Nian, Tobin South, Alex Pentland, and Jiaxin Pei. The automated but risky game: Modeling and benchmarking agent-to-agent negotiations and transactions in consumer markets.arXiv preprint arXiv:2506.00073, 2025
-
[56]
Decision-oriented dialogue for human-AI collaboration.Transactions of the Association for Computational Linguistics, 12:892–911, 08 2024
Jessy Lin, Nicholas Tomlin, Jacob Andreas, and Jason Eisner. Decision-oriented dialogue for human-AI collaboration.Transactions of the Association for Computational Linguistics, 12:892–911, 08 2024
2024
-
[57]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-Bench: Eval- uating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Training proactive and personalized LLM agents.arXiv preprint arXiv:2511.02208, 2025
Weiwei Sun, Xuhui Zhou, Weihua Du, Xingyao Wang, Sean Welleck, Graham Neubig, Maarten Sap, and Yiming Yang. Training proactive and personalized LLM agents.arXiv preprint arXiv:2511.02208, 2025
-
[59]
Mind the sim2real gap in user simulation for agentic tasks.arXiv preprint arXiv:2603.11245, 2026
Xuhui Zhou, Weiwei Sun, Qianou Ma, Yiqing Xie, Jiarui Liu, Weihua Du, Sean Welleck, Yiming Yang, Graham Neubig, Sherry Tongshuang Wu, et al. Mind the sim2real gap in user simulation for agentic tasks.arXiv preprint arXiv:2603.11245, 2026. 13
-
[60]
SimBench: Benchmarking the Ability of Large Language Models to Simulate Human Behaviors
Tiancheng Hu, Joachim Baumann, Lorenzo Lupo, Nigel Collier, Dirk Hovy, and Paul Röttger. SimBench: Benchmarking the ability of large language models to simulate human behaviors. arXiv preprint arXiv:2510.17516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Do LLMs exhibit human-like response biases? a case study in survey design.Transactions of the Association for Computational Linguistics, 12:1011–1026, 2024
Lindia Tjuatja, Valerie Chen, Tongshuang Wu, Ameet Talwalkwar, and Graham Neubig. Do LLMs exhibit human-like response biases? a case study in survey design.Transactions of the Association for Computational Linguistics, 12:1011–1026, 2024
2024
-
[62]
Can LLM Agents Simulate Multi-Turn Human Behavior? Evidence from Real Online Customer Behavior Data
Yuxuan Lu, Jing Huang, Yan Han, Bingsheng Yao, Sisong Bei, Jiri Gesi, Yaochen Xie, Qi He, Dakuo Wang, et al. Can LLM agents simulate multi-turn human behavior? Evidence from real online customer behavior data.arXiv preprint arXiv:2503.20749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
LLM-based human simulations have not yet been reliable.arXiv preprint arXiv:2501.08579, 2025
Qian Wang, Jiaying Wu, Zichen Jiang, Zhenheng Tang, Bingqiao Luo, Nuo Chen, Wei Chen, and Bingsheng He. LLM-based human simulations have not yet been reliable.arXiv preprint arXiv:2501.08579, 2025
-
[64]
The magical number seven, plus or minus two: Some limits on our capacity for processing information.Psychological review, 63(2):81, 1956
George A Miller. The magical number seven, plus or minus two: Some limits on our capacity for processing information.Psychological review, 63(2):81, 1956
1956
-
[65]
Effect of age on forward and backward digit spans.Aging, neuropsychology, and cognition, 4(2):140–149, 1997
Jacques Grégoire and Martial Van Der Linden. Effect of age on forward and backward digit spans.Aging, neuropsychology, and cognition, 4(2):140–149, 1997
1997
-
[66]
Digit span is (mostly) related linearly to general intelligence: Every extra bit of span counts.Psychological Assessment, 27(4):1312, 2015
Gilles E Gignac and Lawrence G Weiss. Digit span is (mostly) related linearly to general intelligence: Every extra bit of span counts.Psychological Assessment, 27(4):1312, 2015
2015
-
[67]
Development of the WAIS-III: A brief overview, history, and description
Marc A Silva. Development of the WAIS-III: A brief overview, history, and description. Graduate Journal of Counseling Psychology, 1(1):11, 2008
2008
-
[68]
The digit span backwards task.European Journal of Psychological Assessment, 2014
Sven Hilbert, Tristan T Nakagawa, Patricia Puci, Alexandra Zech, and Markus Bühner. The digit span backwards task.European Journal of Psychological Assessment, 2014
2014
-
[69]
Reporting and interpreting working memory performance in n-back tasks
Adrian Meule. Reporting and interpreting working memory performance in n-back tasks. Frontiers in psychology, 8:352, 2017
2017
-
[70]
N-back working memory paradigm: A meta-analysis of normative functional neuroimaging studies.Human brain mapping, 25(1):46–59, 2005
Adrian M Owen, Kathryn M McMillan, Angela R Laird, and Ed Bullmore. N-back working memory paradigm: A meta-analysis of normative functional neuroimaging studies.Human brain mapping, 25(1):46–59, 2005
2005
-
[71]
Complex span versus updating tasks of working memory: The gap is not that deep
Florian Schmiedek, Andrea Hildebrandt, Martin Lövdén, Oliver Wilhelm, and Ulman Linden- berger. Complex span versus updating tasks of working memory: The gap is not that deep. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35(4):1089, 2009
2009
-
[72]
The components of working memory updating: An experimental decomposition and individual differences
Ullrich KH Ecker, Stephan Lewandowsky, Klaus Oberauer, and Abby EH Chee. The components of working memory updating: An experimental decomposition and individual differences. Journal of Experimental Psychology: Learning, Memory, and Cognition, 36(1):170, 2010
2010
-
[73]
Retrieval processes in continuous recognition.Journal of Experimental Psychology: Learning, Memory, and Cognition, 8(6):497, 1982
William E Hockley. Retrieval processes in continuous recognition.Journal of Experimental Psychology: Learning, Memory, and Cognition, 8(6):497, 1982
1982
-
[74]
Naturalistic Free Recall
Omri Raccah, Phoebe Chen, Todd M Gureckis, David Poeppel, and Vy A V o. The “Naturalistic Free Recall” dataset: four stories, hundreds of participants, and high-fidelity transcriptions. Scientific Data, 11(1):1317, 2024
2024
-
[75]
Cognitive maps: What are they and why study them?Journal of environ- mental psychology, 14(1):1–19, 1994
Robert M Kitchin. Cognitive maps: What are they and why study them?Journal of environ- mental psychology, 14(1):1–19, 1994
1994
-
[76]
Human relational memory requires time and sleep.Proceedings of the National Academy of Sciences, 104(18):7723–7728, 2007
Jeffrey M Ellenbogen, Peter T Hu, Jessica D Payne, Debra Titone, and Matthew P Walker. Human relational memory requires time and sleep.Proceedings of the National Academy of Sciences, 104(18):7723–7728, 2007
2007
-
[77]
OpenAI. GPT-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
System card: Claude Opus 4.6
Anthropic. System card: Claude Opus 4.6. 2026
2026
-
[79]
Llama Team. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[80]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.