Can LLMs Time Travel? Enhancing Temporal Consistency in Legal Agentic Search through Reinforcement Learning
Pith reviewed 2026-06-29 22:01 UTC · model grok-4.3
The pith
Reinforcement learning on temporally indexed legal data enables agents to match statutes to case time periods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
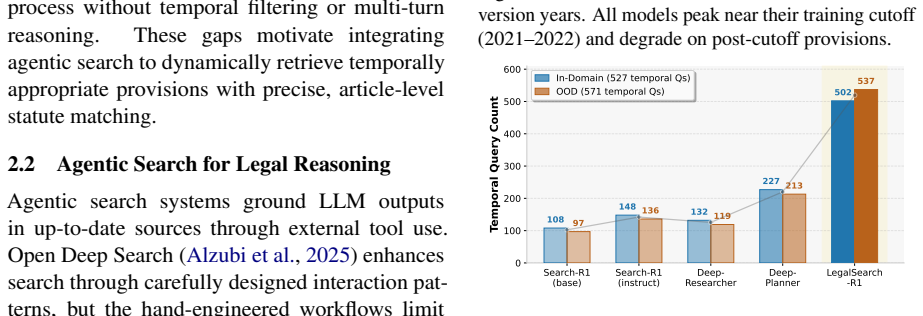
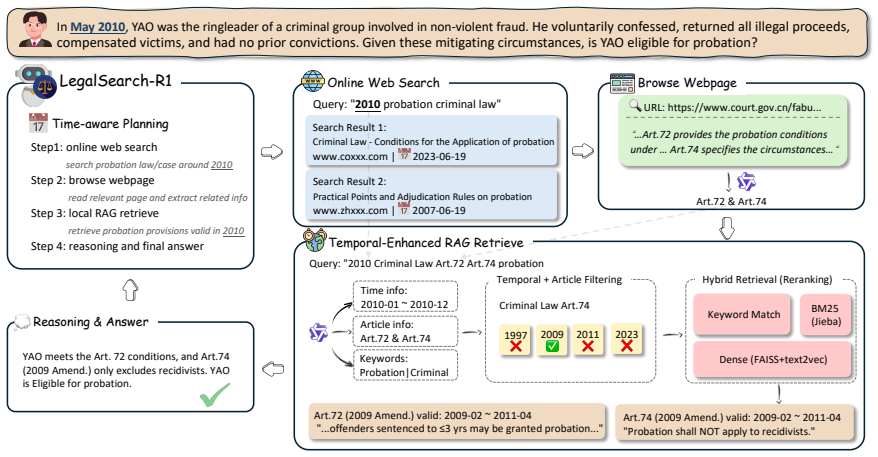
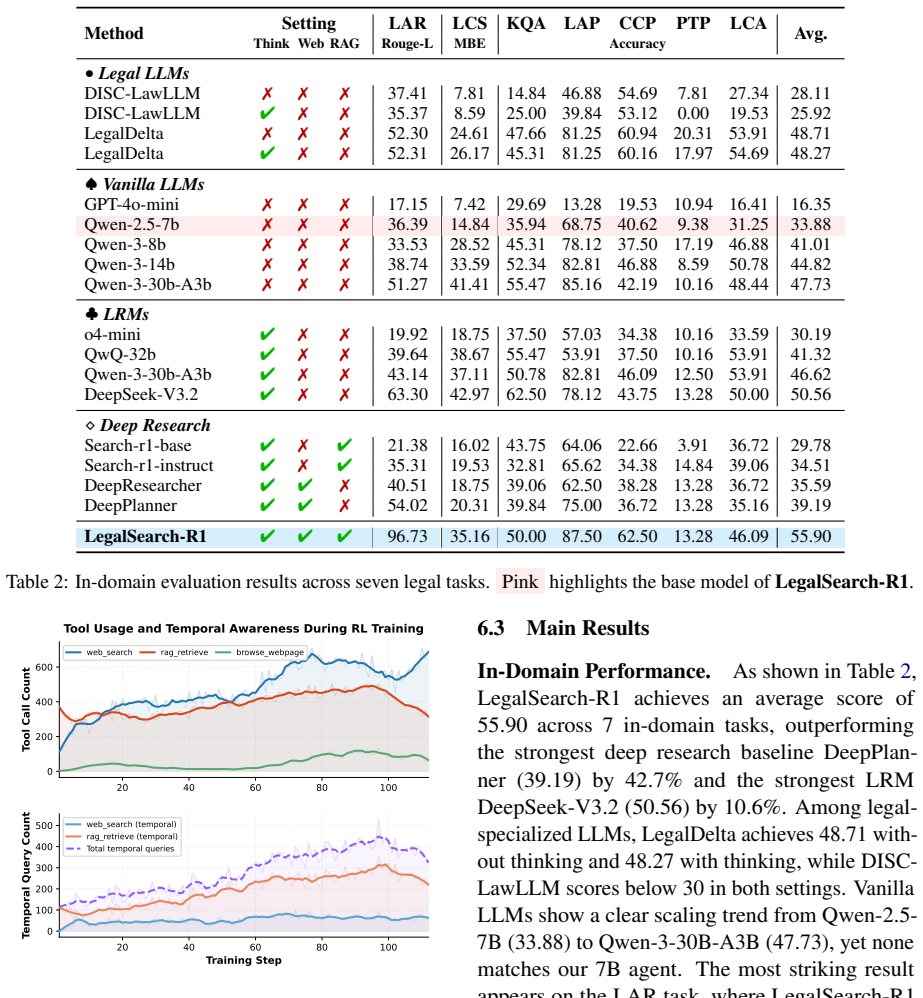
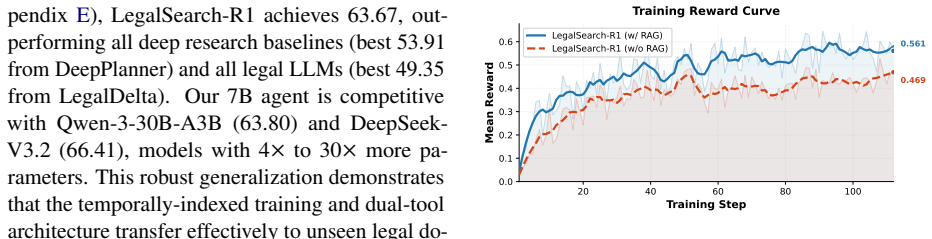
By training a 7B-parameter agent end-to-end with reinforcement learning on temporally-indexed data spanning multiple amendment periods using a hybrid local RAG and online search setup, the system achieves superior results on 13 legal tasks and enforces temporal consistency in statute and precedent selection.
What carries the argument
The hybrid search mechanism that pairs precise local statute RAG with broader online web search, optimized through RL to incorporate temporal constraints from training data across amendment periods.
If this is right
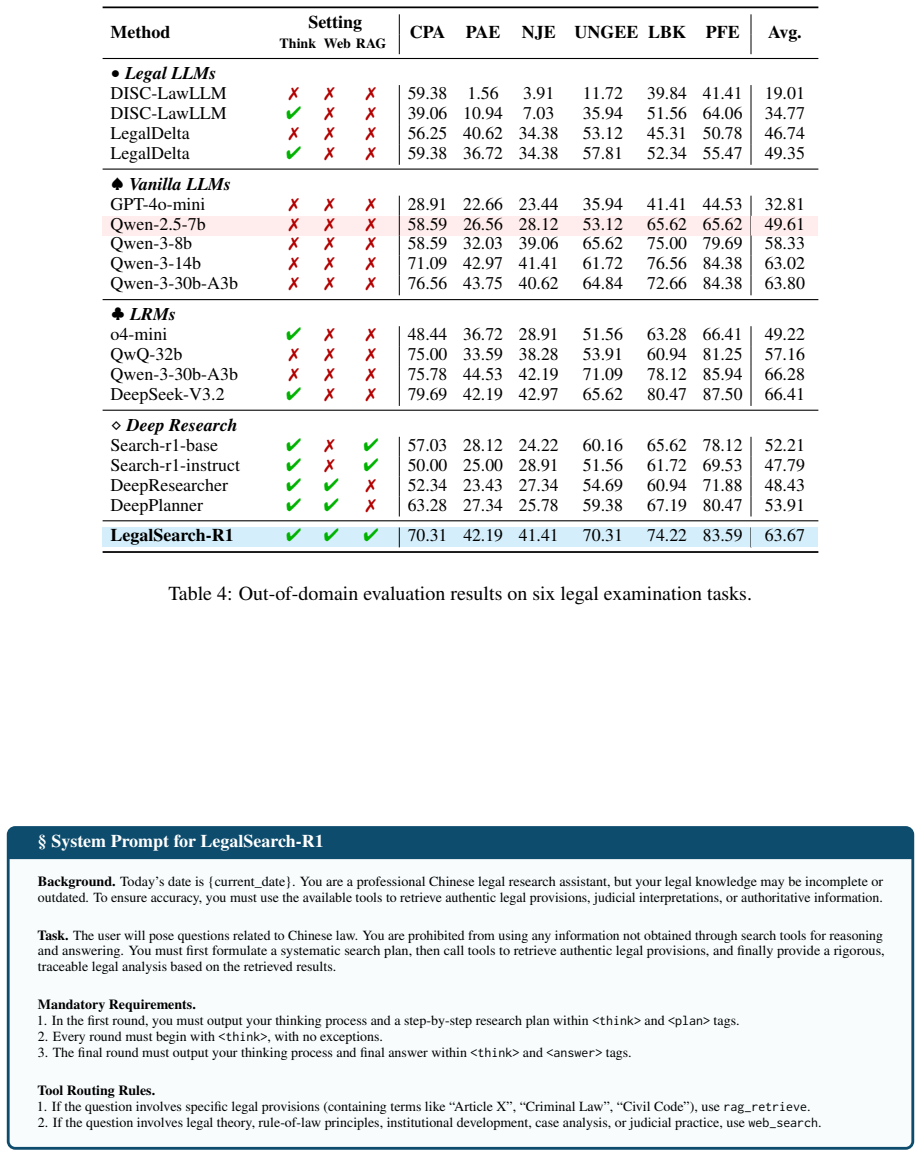
- Outperforms state-of-the-art frameworks and legal LLMs by 12.9% to 29.8% on legal tasks.
- Surpasses baselines by 57.7% to 80.3% on measures of temporal consistency.
- Shows robust generalization to out-of-domain cases.
- The training method produces agents that avoid retroactive application of laws.
Where Pith is reading between the lines
- Similar temporal training could help in other time-sensitive domains such as medical guidelines that change over time.
- Explicitly indexing training data by time periods may be a general strategy for reducing cutoff biases in LLMs.
- Deploying such agents could lower the risk of erroneous legal advice based on outdated or future laws.
Load-bearing premise
Training on data from multiple amendment periods will teach the model to select only laws applicable to the case's time rather than relying on superficial patterns or training cutoff biases.
What would settle it
A test where the model is given cases from time periods after the latest training data or with newly amended laws not present in training, checking if it still selects the correct current statutes without using later ones.
Figures









read the original abstract
While large language models (LLMs) augmented with agentic search capabilities show promise for legal reasoning, they overlook a fundamental constraint that applicable law must match the temporal context of each case, as retroactive application of statutes violates core legal principles and leads to erroneous conclusions. Our observations reveal that current legal LLMs suffer from temporal bias anchored to their training cutoff, while search agents rarely incorporate temporal constraints into queries, and that web search alone cannot provide the precise statute and precedent citations that legal reasoning demands. To address these challenges, we propose LegalSearch-R1, an end-to-end reinforcement learning framework that pairs local statute RAG for precise article matching with online web search for broader legal knowledge, trained on temporally-indexed data spanning multiple amendment periods to enforce temporal consistency. Extensive experiments on our benchmark covering 13 legal tasks demonstrate that our 7B-parameter agent outperforms state-of-the-art deep research frameworks and specialized legal LLMs by 12.9% to 29.8%, surpasses baselines by 57.7% to 80.3% on temporal consistency, and exhibits robust out-of-domain generalization. The code and data are available at https://github.com/AlexFanw/LegalSearch-R1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that legal LLMs exhibit temporal bias tied to training cutoffs and that search agents fail to enforce temporal constraints on applicable law. It introduces LegalSearch-R1, an end-to-end RL framework combining local statute RAG with web search, trained on temporally-indexed data across amendment periods to enforce temporal consistency. On a benchmark of 13 legal tasks, the 7B model is reported to outperform SOTA deep research frameworks and legal LLMs by 12.9–29.8% overall and baselines by 57.7–80.3% on temporal consistency, with robust OOD generalization. Code and data are released.
Significance. If the results hold after proper validation, the work targets a practically important constraint in legal AI: ensuring that retrieved statutes and precedents match the temporal context of a case rather than applying later amendments retroactively. The hybrid RAG-plus-web-search design and multi-period RL training could generalize to other time-sensitive agentic domains. Releasing code and data is a clear strength for reproducibility.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The manuscript reports concrete performance numbers (12.9–29.8% overall, 57.7–80.3% on temporal consistency) on a 13-task benchmark but supplies no description of benchmark construction, the precise definition or scoring of the temporal consistency metric, whether test amendment periods are strictly post-training-cutoff, baseline implementations, or error bars. These omissions are load-bearing because the central claim—that RL on temporally-indexed data produces genuine temporal consistency rather than retrieval artifacts—cannot be assessed without them.
- [Method] Method section: No equations, reward function, or training objective is provided for how temporal consistency is enforced during RL (e.g., explicit penalties for date mismatches or period-aware rewards). Without this formalization or ablations separating the temporal-indexing component from the hybrid search setup, it remains unclear whether reported gains stem from the claimed mechanism or from improved retrieval patterns on indexed data.
minor comments (1)
- [Abstract] The abstract states 'robust out-of-domain generalization' without specifying the OOD periods or tasks used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater methodological transparency. We will revise the manuscript to incorporate the requested details on benchmark construction, metrics, and the RL objective.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The manuscript reports concrete performance numbers (12.9–29.8% overall, 57.7–80.3% on temporal consistency) on a 13-task benchmark but supplies no description of benchmark construction, the precise definition or scoring of the temporal consistency metric, whether test amendment periods are strictly post-training-cutoff, baseline implementations, or error bars. These omissions are load-bearing because the central claim—that RL on temporally-indexed data produces genuine temporal consistency rather than retrieval artifacts—cannot be assessed without them.
Authors: We agree that these details are essential for evaluating the central claims. In the revised manuscript we will add a new subsection in Experiments that (i) describes the construction of the 13-task benchmark including data sources and temporal indexing, (ii) provides the exact definition and scoring procedure for the temporal consistency metric, (iii) confirms that all test amendment periods lie strictly after the training cutoff with supporting statistics, (iv) lists implementation details and hyperparameters for every baseline, and (v) reports error bars computed over multiple random seeds. These additions will allow readers to distinguish genuine temporal consistency gains from retrieval artifacts. revision: yes
-
Referee: [Method] Method section: No equations, reward function, or training objective is provided for how temporal consistency is enforced during RL (e.g., explicit penalties for date mismatches or period-aware rewards). Without this formalization or ablations separating the temporal-indexing component from the hybrid search setup, it remains unclear whether reported gains stem from the claimed mechanism or from improved retrieval patterns on indexed data.
Authors: We accept that the current manuscript lacks the formal RL specification. The revised Method section will include the full reward function and training objective in equation form, explicitly showing the period-aware reward terms and penalties applied for date mismatches. We will also add ablation experiments that isolate the temporal-indexing component from the hybrid RAG-plus-web-search architecture, thereby clarifying the contribution of each design choice to the observed gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical RL-based agent trained on temporally-indexed legal data with hybrid RAG and web search. No equations, fitted parameters, or self-referential definitions appear in the provided text. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are described. The temporal consistency claim rests on training data and external benchmarks rather than reducing to a definitional or fitted-input construction. The derivation chain is self-contained against standard RL and retrieval methods.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, and 1 others
Legalδ: Enhancing legal reasoning in llms via reinforcement learning with chain-of-thought guided information gain.Preprint, arXiv:2508.12281. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, and 1 others. 2025a. Deepseek-r1: Incentivizing reasoning capability in llms via rein- forcement learning.Preprint, arXiv:2501.12948. DeepSeek-AI, Aix...
-
[2]
Deepplanner: Scaling planning capability for deep research agents via advantage shaping.Preprint, arXiv:2510.12979. Zhiwei Fei, Xiaoyu Shen, Dawei Zhu, Fengzhe Zhou, Zhuo Han, Songyang Zhang, Kai Chen, Zongwen Shen, and Jidong Ge. 2023. Lawbench: Bench- marking legal knowledge of large language models. Preprint, arXiv:2309.16289. Zhiwei Fei, Songyang Zhan...
-
[3]
InProceedings of the 38th AAAI Conference on Arti- ficial Intelligence, pages 18642–18650
Interpretable long-form legal question answer- ing with retrieval-augmented large language models. InProceedings of the 38th AAAI Conference on Arti- ficial Intelligence, pages 18642–18650. AAAI Press. Phung Lai Thi Kim Louis, Dohyun Kim, Minseok Seo, Amber Yijin Cho, Kiyoung Lee, Sungho Noh, and KwangHee Park. 2025. Lrage: Legal retrieval augmented gener...
-
[4]
Fuzi.mingcha. https://github.com/irlab-sdu/ fuzi.mingcha. An Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, and 22 others. 2025. Qwen3 technical report.Preprint, arXiv:2505.093...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Lawgpt: A chinese legal knowledge-enhanced large language model.CoRR, abs/2406.04614. A Implementation Details We implement LegalSearch-R1 using Qwen2.5-7B- Instruct as the backbone model. For the auxil- iary LLM used internally by the browse_webpage and rag_retrieve tools (for webpage content ex- traction and query analysis, respectively), we use Qwen3-3...
-
[6]
In the first round, you must output your thinking process and a step-by-step research plan within<think>and<plan>tags
-
[7]
Every round must begin with<think>, with no exceptions
-
[8]
Tool Routing Rules
The final round must output your thinking process and final answer within<think>and<answer>tags. Tool Routing Rules
-
[9]
Article X
If the question involves specific legal provisions (containing terms like “Article X”, “Criminal Law”, “Civil Code”), userag_retrieve
-
[10]
Figure 7: System prompt used during training and evaluation
If the question involves legal theory, rule-of-law principles, institutional development, case analysis, or judicial practice, useweb_search. Figure 7: System prompt used during training and evaluation. § Reading Agent Extraction Prompt (Browse Webpage) You are a professional and reliable Chinese legal research assistant. You will be given the user’s main...
-
[11]
When the page containsoriginal Chinese legal provisions(from the Civil Code, Criminal Law, administrative regulations, judicial interpretations, etc.), preserve the textverbatimwithout paraphrasing
-
[12]
When the page containsjudicial documents, penalty decisions, case details, or legal reasoning for applying specific articles, extract them as completely as possible
-
[13]
When the page containseffective dates, version identifiers, or revision history, these must be retained
-
[14]
5.Scholarly interpretations, academic viewpoints, controversies, and expert opinionsshould all be extracted
Content unrelated to the Chinese legal system may be skipped, but anything with potential relevance should be recorded. 5.Scholarly interpretations, academic viewpoints, controversies, and expert opinionsshould all be extracted. Output<extracted_info>,<page_down>(yes/no), and<short_summary>. Figure 8: Domain-specific extraction prompt used by the reading ...
-
[15]
2024” → [
Temporal Information(time_info) Format: YYYY-MM-DD. Expand partial dates to start/end ranges (e.g., “2024” → ["2024-01-01", "2024-12-31"]). Extract all time periods mentioned. Return empty list if none
2024
-
[16]
Article X
Chapter/Article References(chapter_info) Extract references such as “Article X” or “Chapter X” in full Chinese numeral form. Convert Arabic numerals to Chinese numerals (e.g., “Criminal Law Art. 3”→“Article Three”). Return empty list if none
-
[17]
intentional homicide
Keywords(keywords) Extract primary legal concepts and terms. Must be semantically complete words that appear in the query. Include sub-terms of compound words (e.g., “intentional homicide” should also include “intentional”). Output Format:{"time_info": [], "chapter_info": [], "keywords": []} Figure 9: Structured query analysis prompt used by the RAG retri...
2014
-
[18]
The revised text differs from the original bymore than 20% in character count
-
[19]
name": "web_search
The revision introduces aclear semantic changethat alters the legal meaning or applicability of the provision (e.g., addition or removal of qualifying conditions, changes in sentencing ranges, reversal of legal presumptions). Data Format: Pre-revision entry: Post-revision entry: •Article number•Revised article number (if renumbered) •Amendment date (effec...
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.