PauLIB: A High-Performance Library for Processing Pauli Strings
Pith reviewed 2026-06-29 22:03 UTC · model grok-4.3
The pith
PauLIB multiplies Pauli strings in 25 nanoseconds and shrinks Hamiltonian memory sevenfold through a two-bit-per-qubit encoding and sorted arrays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
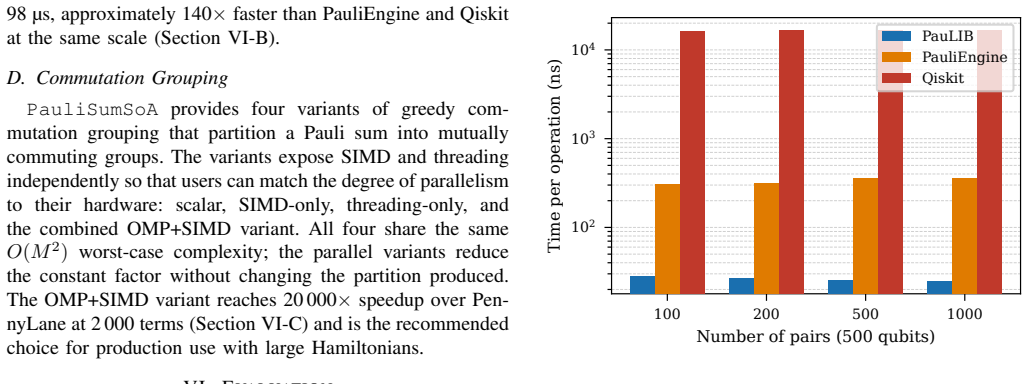
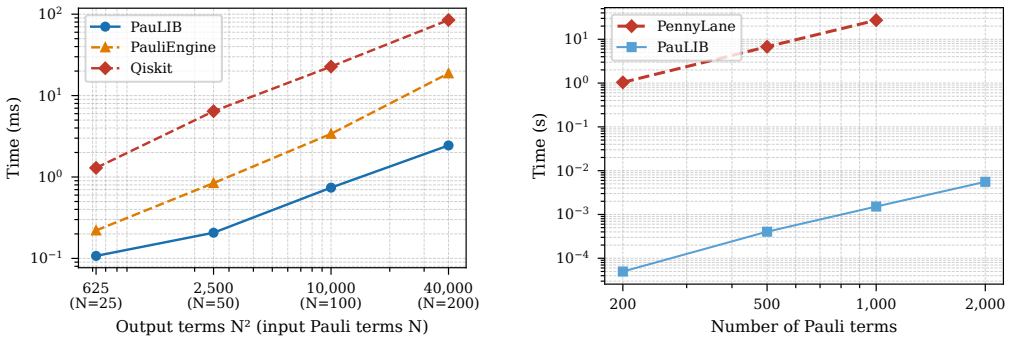
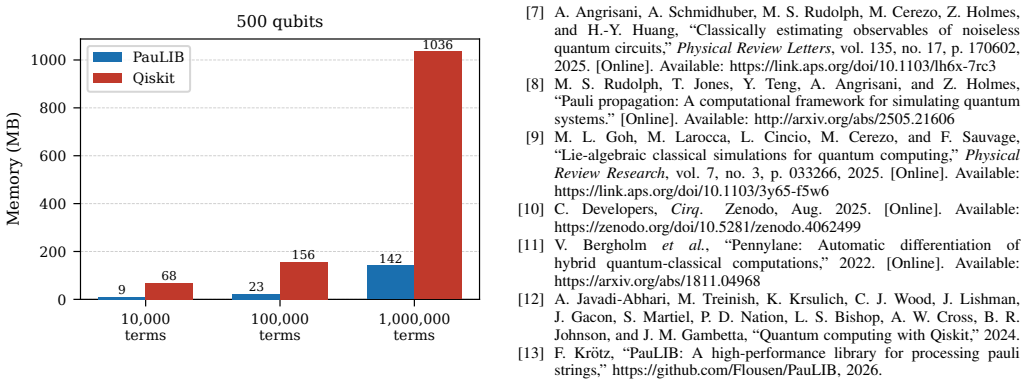
PauLIB encodes each Pauli string in a binary symplectic form with two bits per qubit so that multiplication reduces to a bitwise XOR followed by a population count. Strings are kept in sorted arrays rather than hash maps to support contiguous SIMD bulk operations and use a struct-of-arrays layout to expose word arrays for explicit vectorization. On representative 500-qubit workloads the design yields single-string multiplication at 25 nanoseconds (14 times faster than PauliEngine, 660 times faster than Qiskit-flat), outer-product Hamiltonian multiplication approximately 10 times faster than PauliEngine and 45 times faster than Qiskit, greedy commutation grouping up to 21,000 times faster tha
What carries the argument
The bit-packed binary symplectic representation that encodes each qubit in two bits, reducing Pauli multiplication to a bitwise XOR and a population count.
If this is right
- Single Pauli string multiplication completes in 25 nanoseconds, delivering a 14-fold speedup over PauliEngine and a 660-fold speedup over Qiskit-flat across tested pair counts.
- Hamiltonian outer-product multiplication runs approximately 10 times faster than PauliEngine and 45 times faster than Qiskit at all tested sizes.
- Greedy commutation grouping, the dominant preprocessing step in variational algorithms, achieves up to a 21,000-fold speedup over PennyLane.
- A one-million-term Hamiltonian at 500 qubits occupies 142 MB instead of 1,036 MB, a 7.3-fold reduction that directly enables larger problem sizes within a fixed memory budget.
Where Pith is reading between the lines
- The same compact representation could be reused to accelerate Pauli propagation or stabilizer simulation workloads that currently rely on the same operator algebra.
- Embedding PauLIB inside higher-level quantum frameworks would allow existing variational quantum eigensolver pipelines to scale to larger qubit counts without source changes.
- The sorted-array layout for sparse operator sums may transfer to other algebraic structures that appear in quantum error correction or tensor-network contractions.
Load-bearing premise
The reported speedups and memory reductions are measured on representative workloads and hardware configurations that match typical user environments, and the library's C++ and Python interfaces incur no hidden overhead that would negate the gains in real applications.
What would settle it
A direct timing run of one million random 500-qubit Pauli-string multiplications on a standard x86-64 CPU that yields an average time per multiplication clearly above 25 nanoseconds would falsify the central performance claim.
Figures


read the original abstract
Processing large Pauli sums is a significant bottleneck in quantum chemistry, Pauli propagation, and Pauli-based compilation. Existing frameworks often suffer from Python interpreter overhead or utilize hash-map data structures that hinder SIMD vectorization and complicate multi-threaded merging. We present PauLIB, a header-only C++20 library designed to eliminate these bottlenecks through three key architectural choices. A bit-packed binary symplectic representation that encodes each qubit in two bits, reducing Pauli multiplication to a bitwise XOR and a population count; a sorted array layout that replaces hash maps to enable branch-predictable SIMD bulk operations; and a struct-of-arrays (SoA) memory layout that exposes contiguous word arrays for explicit SIMD vectorization. Benchmarks at 500 qubits show that single Pauli string multiplication runs at 25ns per operation-14 times faster than PauliEngine and 660 times faster than Qiskit-flat across all pair counts tested. Hamiltonian outer-product multiplication is approximately 10 times faster than PauliEngine and 45 times faster than Qiskit at all tested sizes. Greedy commutation grouping, the dominant preprocessing cost in variational algorithms, achieves up to 21,000 times speedup over PennyLane, driven by the compact bit-packed representation. The compact layout reduces the memory footprint of a one-million-term Hamiltonian at 500 qubits from 1,036MB (Qiskit) to 142MB, a 7.3 times reduction that directly enables larger problem sizes within a fixed memory budget. PauLIB is open source and provides C++ and Python interfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PauLIB, a header-only C++20 library for processing Pauli strings that employs a bit-packed binary symplectic representation (two bits per qubit), a sorted array layout instead of hash maps, and a struct-of-arrays memory layout to enable SIMD operations. It reports concrete performance claims at 500 qubits: single Pauli multiplication at 25 ns/op (14× faster than PauliEngine, 660× faster than Qiskit-flat), Hamiltonian outer-product multiplication (10× faster than PauliEngine, 45× faster than Qiskit), greedy commutation grouping (up to 21,000× faster than PennyLane), and a 7.3× memory reduction for a 1M-term Hamiltonian (142 MB vs. 1,036 MB in Qiskit). The library provides both C++ and Python interfaces and is open source.
Significance. If the reported speedups and memory reductions hold under representative conditions, PauLIB could meaningfully accelerate Pauli propagation, variational algorithms, and quantum chemistry workloads by enabling larger Hamiltonians within fixed memory budgets. The open-source release and explicit support for both C++ and Python interfaces are positive attributes that facilitate adoption.
major comments (2)
- [Abstract] Abstract: the headline performance numbers (25 ns/op single multiplication, 14–660× speedups, 10–45× for outer products, 21,000× for grouping, 7.3× memory reduction) are presented without any description of hardware platform, compiler flags, measurement methodology, statistical error bars, or whether timings isolate the C++ core versus the Python bindings. Because the central claims rest entirely on these benchmarks and the library explicitly advertises Python interfaces, the absence of this information is load-bearing for assessing whether the reported factors translate to end-user workloads.
- [Abstract] Abstract / claimed results: no isolation or quantification of Python binding overhead (data marshalling, GIL, per-call cost) is provided, even though the skeptic note correctly identifies this as the weakest link between micro-benchmark numbers and practical Python usage. This directly affects the applicability of the 14–660× and 10–45× factors for the dominant user path.
minor comments (1)
- [Abstract] Abstract contains a typographic issue: "operation-14 times" lacks a space or em-dash.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. The points raised correctly identify areas where the abstract and benchmark presentation can be strengthened to better support the performance claims. We address each comment below and have revised the manuscript to incorporate the requested information.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline performance numbers (25 ns/op single multiplication, 14–660× speedups, 10–45× for outer products, 21,000× for grouping, 7.3× memory reduction) are presented without any description of hardware platform, compiler flags, measurement methodology, statistical error bars, or whether timings isolate the C++ core versus the Python bindings. Because the central claims rest entirely on these benchmarks and the library explicitly advertises Python interfaces, the absence of this information is load-bearing for assessing whether the reported factors translate to end-user workloads.
Authors: We agree that the abstract lacks essential methodological context for the reported numbers. In the revised manuscript we will expand the abstract to state the hardware platform, compiler and optimization flags used, and explicitly note that the timings isolate the C++ core. The existing benchmarks section will be augmented with a concise description of the timing methodology (high-resolution timers, repetition counts), inclusion of statistical error bars, and a clear statement confirming isolation from Python bindings. revision: yes
-
Referee: [Abstract] Abstract / claimed results: no isolation or quantification of Python binding overhead (data marshalling, GIL, per-call cost) is provided, even though the skeptic note correctly identifies this as the weakest link between micro-benchmark numbers and practical Python usage. This directly affects the applicability of the 14–660× and 10–45× factors for the dominant user path.
Authors: We concur that the absence of quantified Python-binding overhead limits the interpretability of the speedup factors for the primary Python user path. In the revised manuscript we will add dedicated measurements in the performance section that isolate the overhead of the pybind11 bindings (marshalling, GIL acquisition/release, and per-call cost) relative to the C++ core, allowing readers to assess effective speedups under typical Python usage. revision: yes
Circularity Check
No derivation chain present; claims are benchmark-driven engineering results
full rationale
The manuscript describes a C++ library implementation using bit-packed representations, sorted arrays, and SoA layouts, with all performance claims (25 ns/op, speedups of 14–660×, 10–45×, 21 000×, 7.3× memory reduction) resting on reported benchmarks against other libraries. No equations, first-principles derivations, fitted parameters, or predictions appear. No self-citations are invoked to justify uniqueness theorems or ansatzes. The work is self-contained against external benchmarks and contains no load-bearing steps that reduce to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. A. Nielsen and I. L. Chuang,Quantum Computation and Quantum Information, 10th ed. Cambridge: Cambridge University Press, 2010
2010
-
[2]
Stabilizer Codes and Quantum Error Correction
D. Gottesman, “Stabilizer codes and quantum error correction,” 1997. [Online]. Available: https://arxiv.org/abs/quant-ph/9705052
work page internal anchor Pith review Pith/arXiv arXiv 1997
-
[3]
McCleanet al., “Openfermion: the electronic structure package for quantum computers,”Quantum Science and Technology, vol. 5, no. 3, p. 034014, jun 2020. [Online]. Available: https://doi.org/10.1088/2058- 9565/ab8ebc
-
[4]
Stim: a fast stabilizer circuit simulator,
C. Gidney, “Stim: a fast stabilizer circuit simulator,” vol. 5, p. 497. [Online]. Available: http://arxiv.org/abs/2103.02202
-
[5]
Improved Simulation of Stabilizer Circuits
S. Aaronson and D. Gottesman, “Improved simulation of stabilizer circuits,”Physical Review A, vol. 70, no. 5, p. 052328, 2004. [Online]. Available: http://arxiv.org/abs/quant-ph/0406196
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[6]
Trading classical and quantum computational resources,
S. Bravyi, G. Smith, and J. Smolin, “Trading classical and quantum computational resources,”Physical Review X, vol. 6, no. 2, p. 021043,
-
[7]
Trading classical and quantum computational resources
[Online]. Available: http://arxiv.org/abs/1506.01396
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Classically estimating observables of noiseless quantum circuits,
A. Angrisani, A. Schmidhuber, M. S. Rudolph, M. Cerezo, Z. Holmes, and H.-Y . Huang, “Classically estimating observables of noiseless quantum circuits,”Physical Review Letters, vol. 135, no. 17, p. 170602,
-
[9]
Available: https://link.aps.org/doi/10.1103/lh6x-7rc3
[Online]. Available: https://link.aps.org/doi/10.1103/lh6x-7rc3
-
[10]
Pauli Propagation: A Computational Framework for Simulating Quantum Systems
M. S. Rudolph, T. Jones, Y . Teng, A. Angrisani, and Z. Holmes, “Pauli propagation: A computational framework for simulating quantum systems.” [Online]. Available: http://arxiv.org/abs/2505.21606
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Lie-algebraic classical simulations for quantum computing,
M. L. Goh, M. Larocca, L. Cincio, M. Cerezo, and F. Sauvage, “Lie-algebraic classical simulations for quantum computing,”Physical Review Research, vol. 7, no. 3, p. 033266, 2025. [Online]. Available: https://link.aps.org/doi/10.1103/3y65-f5w6
-
[12]
C. Developers,Cirq. Zenodo, Aug. 2025. [Online]. Available: https://zenodo.org/doi/10.5281/zenodo.4062499
-
[13]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
V . Bergholmet al., “Pennylane: Automatic differentiation of hybrid quantum-classical computations,” 2022. [Online]. Available: https://arxiv.org/abs/1811.04968
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Quantum computing with Qiskit,
A. Javadi-Abhari, M. Treinish, K. Krsulich, C. J. Wood, J. Lishman, J. Gacon, S. Martiel, P. D. Nation, L. S. Bishop, A. W. Cross, B. R. Johnson, and J. M. Gambetta, “Quantum computing with Qiskit,” 2024
2024
-
[15]
PauLIB: A high-performance library for processing pauli strings,
F. Kr ¨otz, “PauLIB: A high-performance library for processing pauli strings,” https://github.com/Flousen/PauLIB, 2026
2026
-
[16]
PauliEngine: High-Performant Symbolic Arithmetic for Quantum Operations
L. M ¨uller, A. B ¨arligea, A. Knapp, and J. S. Kottmann, “PauliEngine: High-performant symbolic arithmetic for quantum operations.” [Online]. Available: http://arxiv.org/abs/2601.02233
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
STABSim: A parallelized clifford simulator with features beyond direct simulation
S. Garner, C. Liu, M. Wang, S. Stein, and A. Li, “STABSim: A parallelized clifford simulator with features beyond direct simulation.” [Online]. Available: http://arxiv.org/abs/2507.03092
-
[18]
The clifford hierarchy for one qubit or qudit
N. d. Silva and O. Lautsch, “The clifford hierarchy for one qubit or qudit.” [Online]. Available: http://arxiv.org/abs/2501.07939
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.