MobileGym: A Verifiable and Highly Parallel Simulation Platform for Mobile GUI Agent Research
Pith reviewed 2026-06-29 21:24 UTC · model grok-4.3
The pith
MobileGym uses structured JSON state and deterministic judging to enable scalable RL training for mobile GUI agents that transfers to real devices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
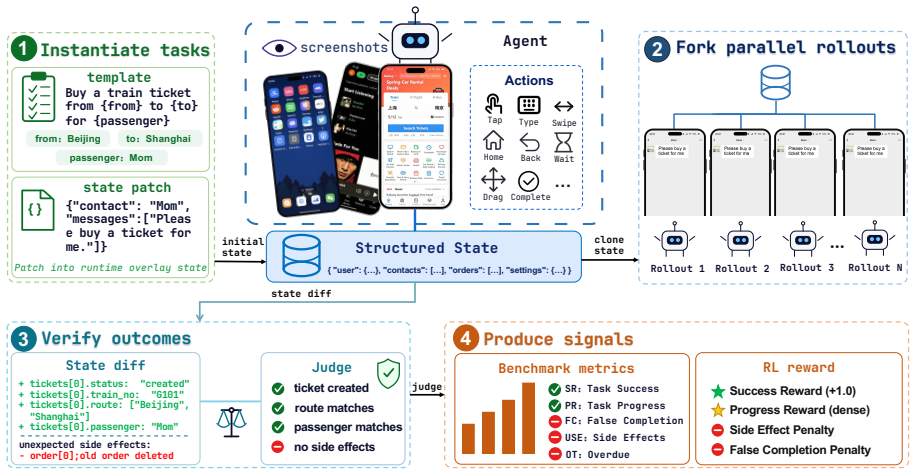
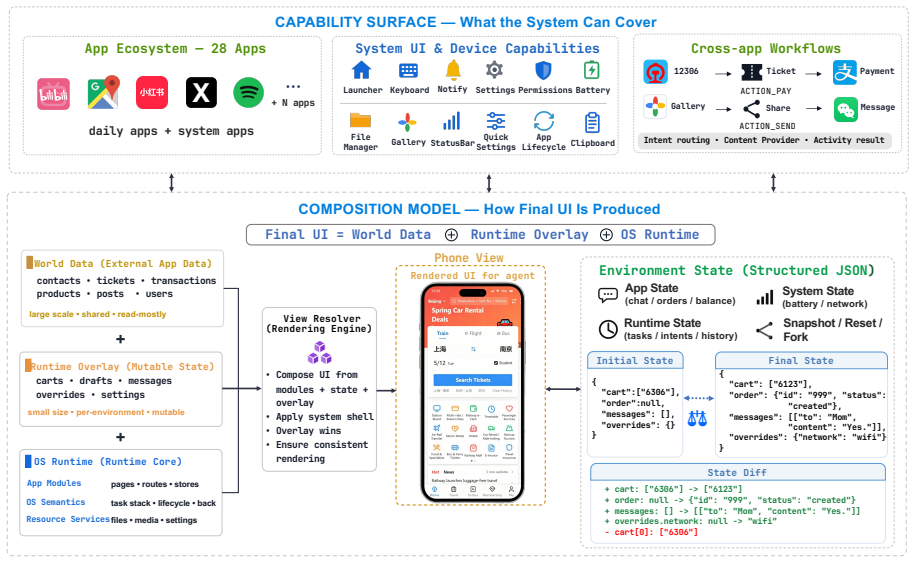
MobileGym captures the full environment state as structured JSON that can be configured, forked, and compared, paired with a layered state model and declarative task framework that enables a single programmatic judging mechanism to deliver both deterministic verdicts and dense RL rewards. A single server can host hundreds of instances with roughly 400 MB memory per instance and three-second cold starts. In the reported Sim-to-Real case study, GRPO training on Qwen3-VL-4B-Instruct yields a +12.8 percentage point gain on the 256-task test set, while real-device execution on the 59-task subset retains 95.1 percent of the simulation-side training gain.
What carries the argument
Structured JSON state representation together with deterministic state-based judging that supplies both evaluation verdicts and dense RL rewards.
If this is right
- Online RL for mobile GUI agents becomes feasible at scale using modest server hardware for hundreds of parallel rollouts.
- Task evaluation becomes reliable through structured AnswerSheet protocols that eliminate free-text matching failures.
- State forking and direct comparison support efficient exploration and debugging during agent training.
- Agents trained entirely in simulation produce performance gains that largely persist when deployed on physical mobile devices.
Where Pith is reading between the lines
- The JSON state model could be adapted to create similar verifiable environments for desktop or web GUI agents.
- Parameterized task templates with deterministic judges could support automated curriculum learning by tracking measurable state progress.
- The low cold-start time and memory footprint suggest the platform could dynamically scale instance counts during large training runs.
Load-bearing premise
The structured JSON state representation and deterministic judging mechanism accurately capture task outcomes for everyday mobile apps without access to proprietary backends or full device emulation fidelity.
What would settle it
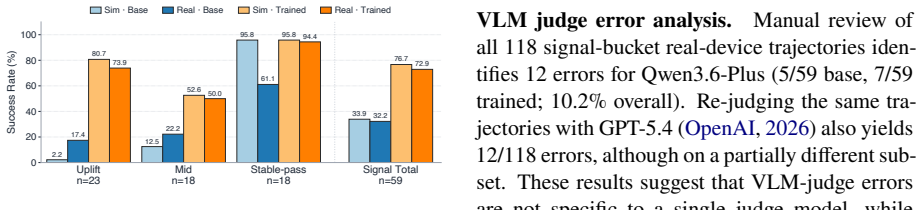
If real-device execution on the 59-task subset shows retention of the simulation training gain substantially below 95.1 percent, for example below 70 percent, the transfer result would be falsified.
Figures


read the original abstract
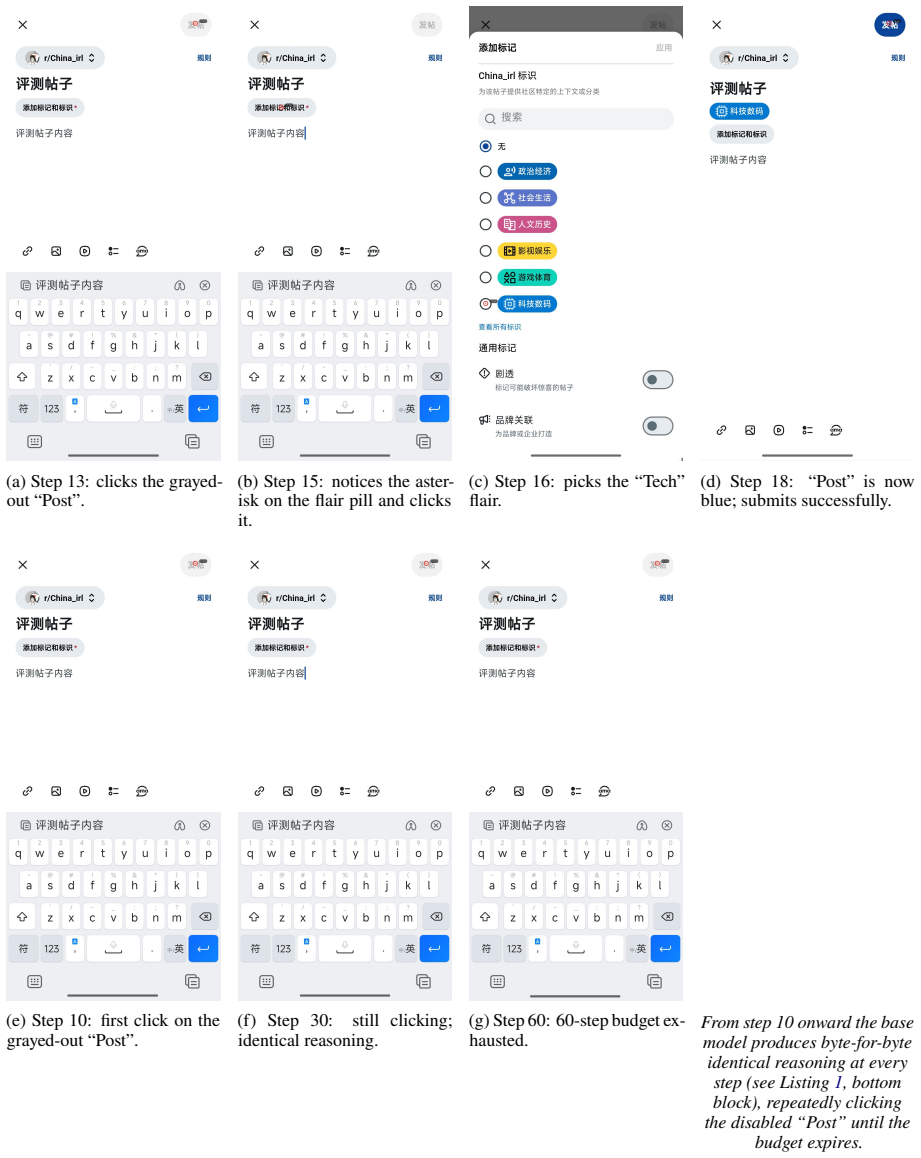
We present MobileGym, a browser-hosted, lightweight, fully controllable environment for everyday mobile use, targeting interaction fidelity without replicating proprietary backends. It enables two capabilities previously out of reach for everyday apps: verifiable outcome signals through deterministic state-based judging over structured JSON state, and scalable online RL through low-cost parallel rollouts. The full environment state is captured, configured, forked, and compared as structured JSON, and a single server can host hundreds of parallel instances, with about 400 MB memory per instance and about 3 s cold start. A layered state model and a declarative task-definition framework keep state programmability and task creation practical at scale, and a single programmatic judging mechanism delivers both deterministic evaluation verdicts and dense RL rewards. The accompanying MobileGym-Bench provides 416 parameterized task templates, including 256 test and 160 train templates, over 28 apps, with deterministic judges and a structured AnswerSheet protocol that avoids free-text matching failures. In a Sim-to-Real case study, GRPO on Qwen3-VL-4B-Instruct gains +12.8 percentage points on the 256-task test set, and on a 59-task real-device signal subset, real-device execution retains 95.1% of the simulation-side training gain. Project page: https://mobilegym.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MobileGym, a browser-hosted lightweight simulation platform for mobile GUI agent research. It claims to enable verifiable task outcomes via a layered structured-JSON state model and deterministic programmatic judging, while supporting highly parallel RL rollouts (hundreds of instances per server at ~400 MB memory and ~3 s cold start). The accompanying MobileGym-Bench supplies 416 parameterized task templates (256 test, 160 train) across 28 apps with an AnswerSheet protocol. A Sim-to-Real case study reports that GRPO on Qwen3-VL-4B-Instruct yields a +12.8 percentage point gain on the 256-task test set, with real-device execution on a 59-task subset retaining 95.1% of the simulation-side training gain.
Significance. If the fidelity and scalability claims hold, MobileGym would provide a practical, low-cost alternative to full device emulation for everyday mobile apps, enabling reproducible online RL with dense rewards and deterministic evaluation. The structured state representation, declarative task framework, and parallel rollout efficiency are concrete engineering contributions that could accelerate GUI agent research. The benchmark size and reported resource numbers add practical value; the sim-to-real retention figure, if shown to be robust, would strengthen the case for simulation-based training.
major comments (1)
- [Sim-to-Real case study] Sim-to-Real case study (abstract and associated results): the selection criteria and composition of the 59-task real-device signal subset are not specified. This detail is load-bearing for the 95.1% retention claim, because any systematic exclusion of tasks whose outcomes depend on unmodeled server responses, timing, or proprietary backends would make the retention percentage non-generalizable to the full 256-task set.
minor comments (1)
- [Abstract] Abstract: the memory and cold-start figures (~400 MB, ~3 s) would be more informative with a brief statement of the measurement conditions or hardware baseline used.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the sim-to-real case study. We address the concern point by point below.
read point-by-point responses
-
Referee: [Sim-to-Real case study] Sim-to-Real case study (abstract and associated results): the selection criteria and composition of the 59-task real-device signal subset are not specified. This detail is load-bearing for the 95.1% retention claim, because any systematic exclusion of tasks whose outcomes depend on unmodeled server responses, timing, or proprietary backends would make the retention percentage non-generalizable to the full 256-task set.
Authors: We agree that the selection criteria and composition of the 59-task subset must be specified for the retention claim to be interpretable. The current manuscript does not provide these details. In the revised version we will add an explicit subsection describing the subset construction process, including the sampling strategy across the 28 apps and 256 test tasks, the criteria applied to ensure feasibility on physical devices (e.g., exclusion of tasks requiring live external services or precise timing not captured in the JSON state model), and a breakdown of the subset by app category and task type. We will also report any observed differences between the subset and the full test set. revision: yes
Circularity Check
No circularity: empirical platform and benchmark results with no derivations or self-referential predictions
full rationale
The paper introduces MobileGym as a simulation platform using structured JSON state and deterministic judging, then reports direct empirical outcomes from GRPO training (+12.8 pp on 256-task test set) and sim-to-real retention (95.1% on 59-task subset). No equations, derivations, fitted parameters, or first-principles claims exist that could reduce to inputs by construction. The central results are measurements on the described environment and real devices rather than predictions derived from the platform's own definitions. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing support. The skeptic concern about JSON fidelity matching real outcomes is a question of assumption validity and generalizability, not circularity per the specified criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , pages 16022–16076
Appworld: A controllable world of apps and people for benchmarking interactive coding agents . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , pages 16022–16076. Karen Ullrich, Jingtong Su, Claudia Shi, Arjun Subra- monian, Amir Bar, Ivan Evtimov, Nikolaos Tsilivis, Randall Balestriero, Julia Kempe, and M...
-
[2]
browser refresh = device reboot
Openapps: Simulating environment varia- tions to measure ui-agent reliability . arXiv preprint arXiv:2511.20766. Venus-Team, Changlong Gao, Zhangxuan Gu, Yulin Liu, Xinyu Qiu, Shuheng Shen, Yue Wen, Tianyu Xia, Zhenyu Xu, Zhengwen Zeng, Beitong Zhou, Xingran Zhou, Weizhi Chen, Sunhao Dai, Jingya Dou, Yichen Gong, Yuan Guo, Zhenlin Guo, Feng Li, and 8 othe...
-
[3]
The primary 8-model cali- 19 bration yields +21.3/+25.4/+11.1/+0.9 pt, while the 4-model calibration yields +23.0/+ 22.5/ + 7.3/ + 0.7 pt
Sim-to-Real lift concentrates on L1–L2 and diminishes sharply at L3–L4 under both calibrations. The primary 8-model cali- 19 bration yields +21.3/+25.4/+11.1/+0.9 pt, while the 4-model calibration yields +23.0/+ 22.5/ + 7.3/ + 0.7 pt. In both cases, most of the training lift lies in L1–L2 and nearly van- ishes on L4
-
[4]
declarative-statement
L4 isolates the frontier under both calibra- tions. Under the 8-model calibration, only Gemini 3.1 Pro stays meaningfully above the floor on L4 (21.9%), while every other model is ≤ 6.2%. Under the 4-model calibration, Gemini remains the only model above 10% on L4 (12.2%), while all other models are ≤ 8.1%. The trained 4B model also exceeds AutoGLM-Phone-...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.