Learning to Balance Motor Thermal Safety and Quadrupedal Locomotion Performance with Residual Policy
Pith reviewed 2026-06-30 11:04 UTC · model grok-4.3
The pith
A residual policy conditioned on motor temperatures extends safe quadruped locomotion under payload from 5 to over 13 minutes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
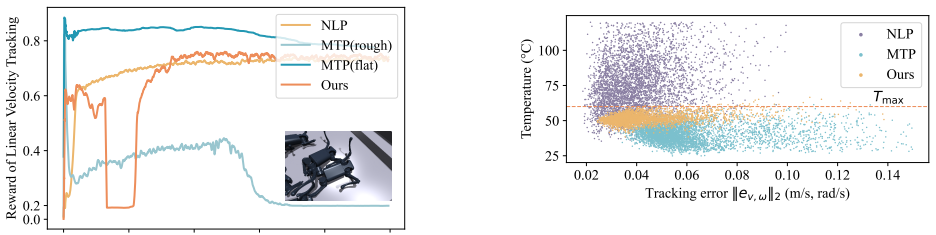
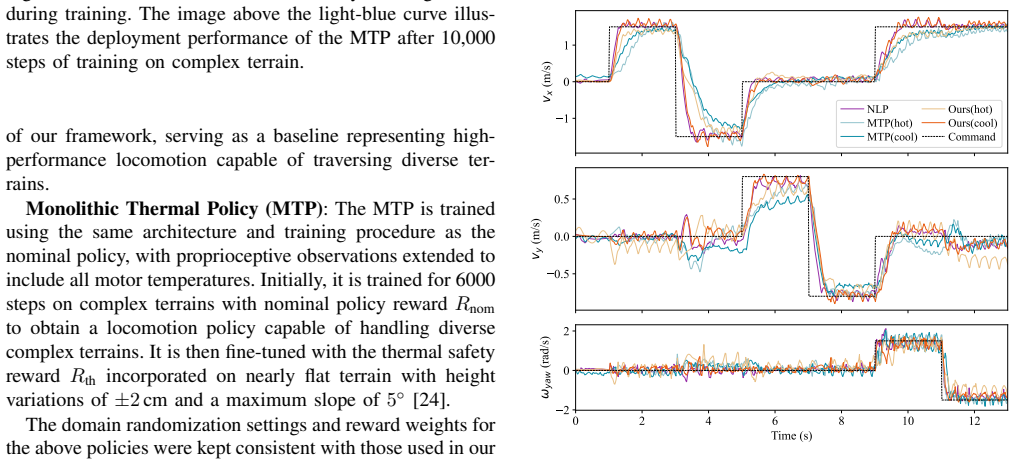
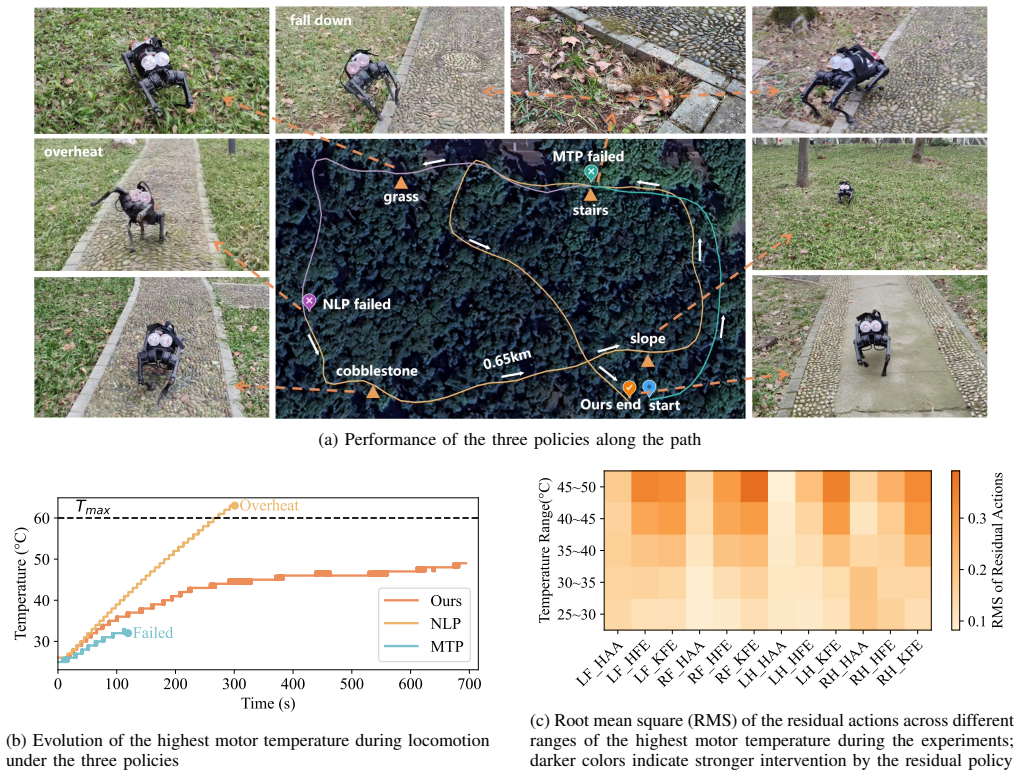
The authors establish that a nominal locomotion policy pre-trained on diverse terrains can be augmented with a residual policy conditioned on the robot's thermal state. This combination, trained in a two-stage process using a whole-body thermal model to update temperatures in the reinforcement learning environment, enables the robot to achieve high performance at low temperatures and avoid overheating at high temperatures. Validation comes from simulation showing balanced safety and performance, and real-world tests where the policy sustains over 13 minutes of stable locomotion with a 3 kg payload across terrains, compared to 5 minutes before overheating with the nominal policy alone.
What carries the argument
The residual policy, which outputs corrective actions based on the current thermal state of the motors to modify the nominal policy's outputs.
If this is right
- The robot maintains high locomotion performance when motor temperatures remain low.
- Corrective actions from the residual policy prevent overheating during extended runs under load.
- The two-stage training produces policies that transfer from simulation to real hardware on the Unitree A1.
- Stable traversal across multiple terrains becomes possible for durations exceeding 13 minutes with added payload.
Where Pith is reading between the lines
- The same residual-correction structure could be applied to other hard constraints such as battery state or joint torque limits.
- Hardware cooling systems might be reduced or eliminated on some platforms if the learned policy manages heat through gait adjustments.
- Testing the same framework on robots with different actuator counts or heavier payloads would test how far the thermal model remains accurate.
Load-bearing premise
The whole-body thermal model must predict motor temperatures accurately enough in both simulation and on the physical robot under payload so that the residual policy trained in simulation transfers without large mismatch.
What would settle it
Deploying the residual policy on the Unitree A1 with a 3 kg payload and measuring motor temperatures that exceed safe limits or cause locomotion failure before 13 minutes of terrain traversal would show the central claim is incorrect.
Figures



read the original abstract
Motor thermal management is often overlooked in the context of electrically-actuated robots, particularly legged robots, but motor overheating is a key factor that limits long-duration locomotion especially under payload conditions. This paper integrates a whole-body thermal model of a quadruped robot into the reinforcement learning pipeline to update motor temperatures, and proposes a two-stage training framework for motor thermal management. In this framework, a nominal policy is first pre-trained as a locomotion baseline capable of traversing diverse terrains. A residual policy is then trained on top of the nominal policy to provide corrective actions based on the robot's thermal state, ensuring high performance under low-temperature conditions and preventing motor overheating under high-temperature conditions. Simulation results demonstrate that the proposed policy achieves an effective balance between motor thermal safety and locomotion performance. Real-world experiments on a Unitree A1 quadruped robot further validate the approach: under a 3 kg payload, the robot achieves stable locomotion across multiple terrains for over 13 minutes, while the nominal policy alone leads to motor overheating in about 5 minutes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that integrating a whole-body thermal model into the RL pipeline, combined with a two-stage training process (nominal locomotion policy followed by a thermal-state-conditioned residual policy), enables quadrupedal robots to balance motor thermal safety and locomotion performance. Simulation results are said to demonstrate this balance, while hardware experiments on a Unitree A1 with 3 kg payload report stable multi-terrain locomotion for over 13 minutes versus motor overheating in ~5 minutes under the nominal policy alone.
Significance. If the thermal model proves accurate and the sim-to-real transfer holds, the residual-policy approach could meaningfully extend safe operating time for payload-carrying legged robots by addressing an often-overlooked thermal constraint without sacrificing baseline locomotion capability. The two-stage framework and the concrete hardware duration comparison are positive elements that could influence future safety-aware RL designs in robotics.
major comments (2)
- [Abstract / thermal model integration] Abstract and thermal-model description: no quantitative validation, error metrics, parameter-identification procedure, or direct hardware-model comparison is reported for the whole-body thermal model's temperature predictions versus measured motor temperatures on the Unitree A1 (under payload or otherwise). This is load-bearing for the central claim, because the residual policy is trained on temperature updates supplied by this model; without evidence that the model matches hardware dynamics, the 13 min vs. 5 min hardware result cannot be attributed to thermal awareness rather than generic conservatism.
- [Real-world experiments] Real-world experiments section: the manuscript supplies neither the method used to measure motor temperatures on the physical robot, nor ablation studies isolating the residual policy's contribution, nor error bars or statistical characterization of the reported run durations. These omissions prevent assessment of whether the observed extension is reproducible and attributable to the proposed method.
minor comments (1)
- [Abstract] The abstract states 'simulation and hardware results' but provides no numerical performance metrics (e.g., velocity, energy, or success rate) beyond the single duration comparison; adding a table of quantitative locomotion metrics would strengthen the balance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of the thermal model and more complete experimental reporting. We agree these elements are important for substantiating the central claims and will revise the manuscript to incorporate the requested details and analyses.
read point-by-point responses
-
Referee: [Abstract / thermal model integration] Abstract and thermal-model description: no quantitative validation, error metrics, parameter-identification procedure, or direct hardware-model comparison is reported for the whole-body thermal model's temperature predictions versus measured motor temperatures on the Unitree A1 (under payload or otherwise). This is load-bearing for the central claim, because the residual policy is trained on temperature updates supplied by this model; without evidence that the model matches hardware dynamics, the 13 min vs. 5 min hardware result cannot be attributed to thermal awareness rather than generic conservatism.
Authors: We agree that direct quantitative validation of the thermal model against hardware is necessary to support attribution of the results. In the revised manuscript we will add a new subsection detailing the parameter-identification procedure, error metrics (RMSE and max error) between model predictions and measured motor temperatures, and side-by-side comparison plots for both no-payload and 3 kg payload conditions on the Unitree A1. These additions will allow readers to assess model fidelity independently of the RL performance claims. revision: yes
-
Referee: [Real-world experiments] Real-world experiments section: the manuscript supplies neither the method used to measure motor temperatures on the physical robot, nor ablation studies isolating the residual policy's contribution, nor error bars or statistical characterization of the reported run durations. These omissions prevent assessment of whether the observed extension is reproducible and attributable to the proposed method.
Authors: We acknowledge the lack of these experimental details in the current version. The revision will explicitly state that motor temperatures were read from the Unitree A1's onboard sensors, include ablation comparisons (nominal policy alone, residual policy with thermal conditioning disabled, and full proposed method), and report run-duration statistics across multiple trials with means, standard deviations, and error bars. This will strengthen the evidence that the observed extension is reproducible and due to the residual policy. revision: yes
Circularity Check
No circularity; performance claims rest on direct hardware measurements after RL training
full rationale
The paper describes a two-stage RL procedure (nominal policy pre-training followed by residual policy training conditioned on a whole-body thermal model) and reports empirical outcomes: simulation balance metrics plus real-world Unitree A1 runs showing >13 min stable locomotion under 3 kg payload versus ~5 min overheating for the nominal policy. No equations, fitted parameters, or self-citations are presented that would render the reported durations or safety claims equivalent to their inputs by construction. The central results are measured quantities on physical hardware, not predictions derived from the thermal model itself or from any self-referential loop. This satisfies the default expectation of a non-circular empirical ML robotics paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The integrated whole-body thermal model correctly updates motor temperatures from joint torques and velocities in both simulation and reality.
Forward citations
Cited by 1 Pith paper
-
Long-Distance Real-World Navigation of the Legged-Wheeled Robot Go2-W Using Deep Reinforcement Learning
A DRL locomotion controller extended from prior quadruped work enabled the Go2-W robot to complete 2.8 km of autonomous real-world navigation including mixed terrain and stairs.
Reference graph
Works this paper leans on
-
[1]
Beyond robustness: Learning unknown dynamic load adaptation for quadruped locomotion on rough terrain,
L. Chang, Y . Nai, H. Chen, and L. Yang, “Beyond robustness: Learning unknown dynamic load adaptation for quadruped locomotion on rough terrain,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 10 282–10 288
2025
-
[2]
Chance- constrained convex mpc for robust quadruped locomotion under para- metric and additive uncertainties,
A. Trivedi, S. Prajapati, M. Zolotas, M. Everett, and T. Padır, “Chance- constrained convex mpc for robust quadruped locomotion under para- metric and additive uncertainties,”IEEE Robotics and Automation Letters, 2025
2025
-
[3]
Learning agile locomotion and adaptive behaviors via rl-augmented mpc,
Y . Chen and Q. Nguyen, “Learning agile locomotion and adaptive behaviors via rl-augmented mpc,” in2024 IEEE International Confer- ence on Robotics and Automation (ICRA). IEEE, 2024, pp. 11 436– 11 442
2024
-
[4]
Leeps: Learning end-to-end legged perceptive parkour skills on challenging terrains,
T. Qian, H. Zhang, Z. Zhou, H. Wang, M. Cai, and Z. Kan, “Leeps: Learning end-to-end legged perceptive parkour skills on challenging terrains,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 12 904–12 909
2024
-
[5]
Toward Reliable Sim-to-Real Predictability for MoE-based Robust Quadrupedal Locomotion
T. Wu, H. Guo, Y . Wang, J. Yang, X. Sui, J. Xie, X. Chen, Z. Liu, and X. Lan, “Toward reliable sim-to-real predictability for moe-based robust quadrupedal locomotion,”arXiv preprint arXiv:2602.00678, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Olaf: Bringing an animated character to life in the physical world,
D. Müller, E. Knoop, D. Mylonopoulos, A. Serifi, M. A. Hopkins, R. Grandia, and M. Bächer, “Olaf: Bringing an animated character to life in the physical world,”arXiv preprint arXiv:2512.16705, 2025
-
[7]
Learning thermal-aware locomotion policies for an electrically-actuated quadruped robot,
L. Qian, Y . Wan, S. Wang, and X. Luo, “Learning thermal-aware locomotion policies for an electrically-actuated quadruped robot,” arXiv preprint arXiv:2603.01631, 2026
-
[8]
Improving generalization in visual reinforce- ment learning via conflict-aware gradient agreement augmentation,
S. Liu, Z. Chen, Y . Liu, Y . Wang, D. Yang, Z. Zhao, Z. Zhou, X. Yi, W. Li, W. Zhanget al., “Improving generalization in visual reinforce- ment learning via conflict-aware gradient agreement augmentation,” in Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 23 436–23 446
2023
-
[9]
Moe-loco: Mixture of experts for multitask locomotion,
R. Huang, S. Zhu, Y . Du, and H. Zhao, “Moe-loco: Mixture of experts for multitask locomotion,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 14 218– 14 225
2025
-
[10]
How to train your robots? the impact of demonstration modality on imitation learning,
H. Li, Y . Cui, and D. Sadigh, “How to train your robots? the impact of demonstration modality on imitation learning,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 1113–1120
2025
-
[11]
Motion priors reimagined: Adapting flat-terrain skills for complex quadruped mobility,
Z. Zhang, C. Li, T. Miki, and M. Hutter, “Motion priors reimagined: Adapting flat-terrain skills for complex quadruped mobility,”arXiv preprint arXiv:2505.16084, 2025
-
[12]
Design and experimental study of bldc motor immersion cooling for legged robots,
T. Zhu, M. S. Ahn, and D. Hong, “Design and experimental study of bldc motor immersion cooling for legged robots,” in2021 20th International Conference on Advanced Robotics (ICAR). IEEE, 2021, pp. 1137–1143
2021
-
[13]
Design and evaluation of airflow cooling system for high-power-density motor for robotic applications,
A. F. Akawung and Y . Fujimoto, “Design and evaluation of airflow cooling system for high-power-density motor for robotic applications,” in2020 IEEE Energy Conversion Congress and Exposition (ECCE). IEEE, 2020, pp. 1715–1721
2020
-
[14]
Estimation and control of motor core temperature with online learning of thermal model param- eters: Application to musculoskeletal humanoids,
K. Kawaharazuka, N. Hiraoka, K. Tsuzuki, M. Onitsuka, Y . Asano, K. Okada, K. Kawasaki, and M. Inaba, “Estimation and control of motor core temperature with online learning of thermal model param- eters: Application to musculoskeletal humanoids,”IEEE Robotics and Automation Letters, vol. 5, no. 3, pp. 4273–4280, 2020
2020
-
[15]
A modular residual learning framework to enhance model-based approach for robust locomotion,
M.-G. Kim, D. Kang, H. Kim, and H.-W. Park, “A modular residual learning framework to enhance model-based approach for robust locomotion,”IEEE Robotics and Automation Letters, vol. 10, no. 9, pp. 9072–9079, 2025
2025
-
[16]
Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills,
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbab, C. Panet al., “Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills,”arXiv preprint arXiv:2502.01143, 2025
-
[17]
Learning quadrupedal locomotion over challenging terrain,
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning quadrupedal locomotion over challenging terrain,”Science robotics, vol. 5, no. 47, p. eabc5986, 2020
2020
-
[18]
Learning accurate whole- body throwing with high-frequency residual policy and pullback tube acceleration,
Y . Ma, Y . Liu, K. Qu, and M. Hutter, “Learning accurate whole- body throwing with high-frequency residual policy and pullback tube acceleration,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 1771–1778
2025
-
[19]
General humanoid whole-body control via pretraining and fast adaptation,
Z. Wang, J. Wang, S. Yao, Y . Zhang, Z. Ding, M. Yang, Y . Wang, H. Jiang, C. Ma, X. Shiet al., “General humanoid whole-body control via pretraining and fast adaptation,”arXiv preprint arXiv:2602.11929, 2026
-
[20]
Asymmetric Actor Critic for Image-Based Robot Learning
L. Pinto, M. Andrychowicz, P. Welinder, W. Zaremba, and P. Abbeel, “Asymmetric actor critic for image-based robot learning,”arXiv preprint arXiv:1710.06542, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Hybrid internal model: Learning agile legged locomotion with simulated robot response,
J. Long, Z. Wang, Q. Li, J. Gao, L. Cao, and J. Pang, “Hybrid internal model: Learning agile legged locomotion with simulated robot response,”arXiv preprint arXiv:2312.11460, 2023
-
[22]
Temperature distribution prediction of the quadruped robot based on the lumped-parameter thermal networks,
W. Lin, L. Qian, X. Luo, and C. Liang, “Temperature distribution prediction of the quadruped robot based on the lumped-parameter thermal networks,”Robot, vol. 47, no. 2, pp. 188–199, 3 2025 (in Chinese)
2025
-
[23]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on robot learning. PMLR, 2022, pp. 91–100
2022
-
[24]
Accurate power consumption estimation method makes walking robots energy efficient and quiet,
G. Valsecchi, A. Vicari, F. Tischhauser, M. Garabini, and M. Hut- ter, “Accurate power consumption estimation method makes walking robots energy efficient and quiet,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 13 282–13 288
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.