Qiskit QuantumKatas: Adapting Microsoft's Quantum Computing exercises for LLM evaluation
Pith reviewed 2026-06-29 16:33 UTC · model grok-4.3
The pith
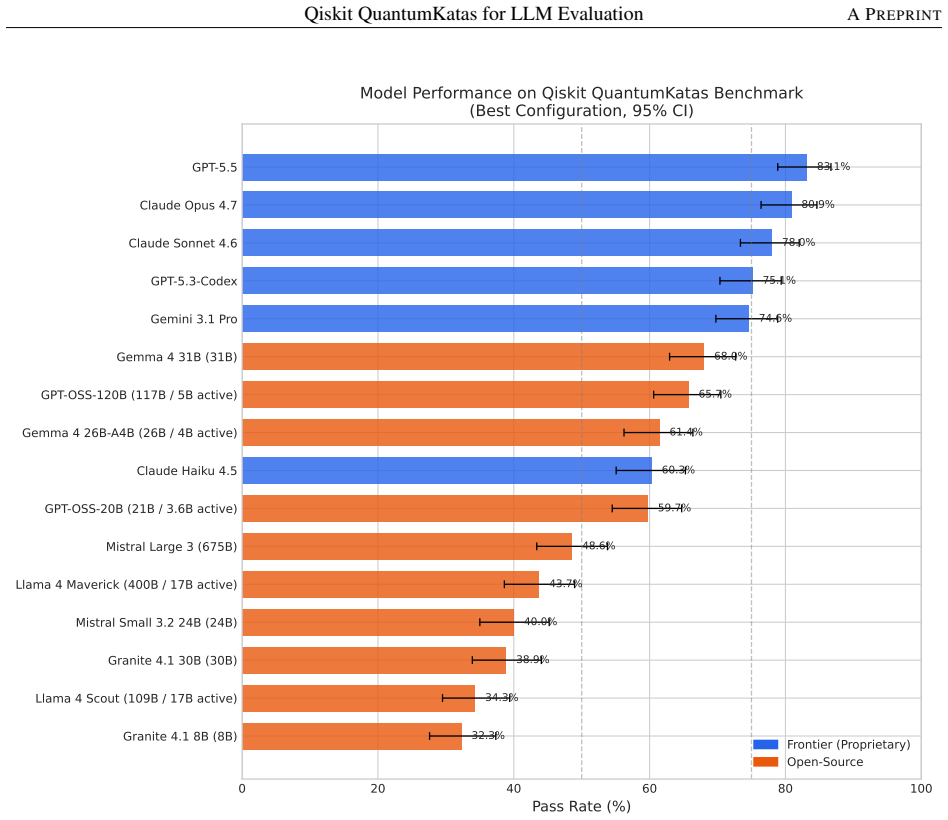
Adapting QuantumKatas to Qiskit produces a benchmark that distinguishes LLM quantum capabilities with pass rates from 32.3% to 83.1%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By adapting the QuantumKatas curriculum to Qiskit, the paper establishes a benchmark consisting of 350 tasks that can be used to assess LLMs' ability to generate correct quantum code, demonstrating differentiation in capabilities through empirical runs on multiple models and prompting strategies.
What carries the argument
The Qiskit-adapted QuantumKatas benchmark comprising 350 tasks with natural language prompts, canonical solutions, and deterministic test verification via classical circuit simulation.
If this is right
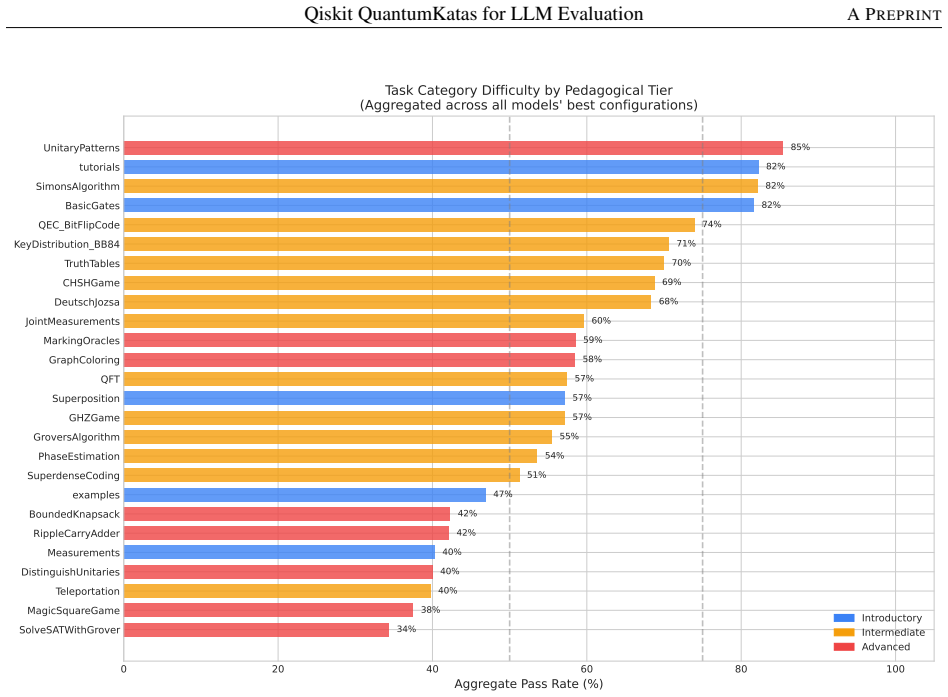
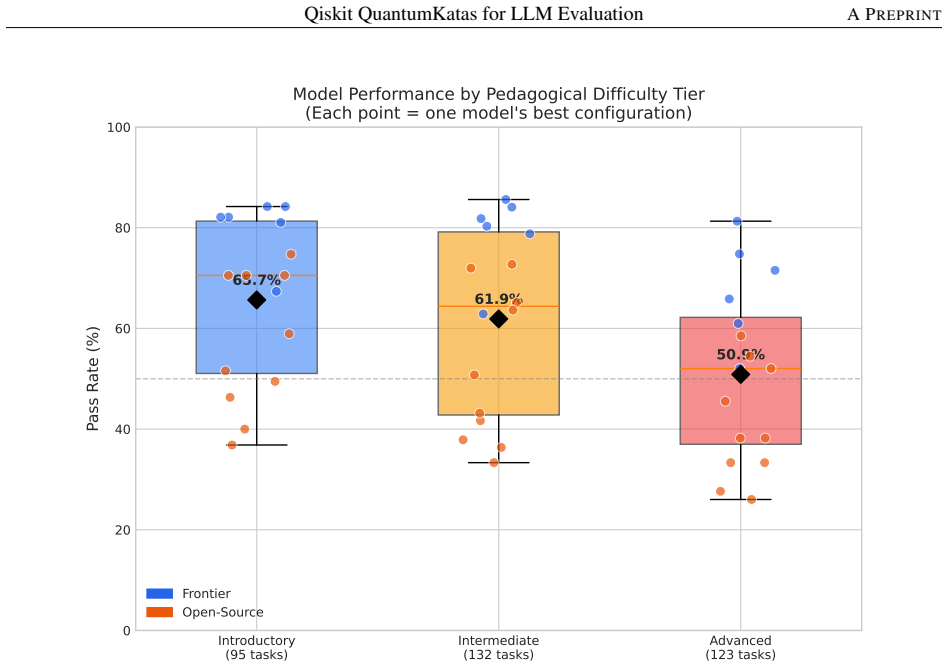
- Models achieve higher success rates on implementing known algorithms like SimonsAlgorithm (82.1%) and BasicGates (81.6%) compared to problem encoding tasks like SolveSATWithGrover (34.4%).
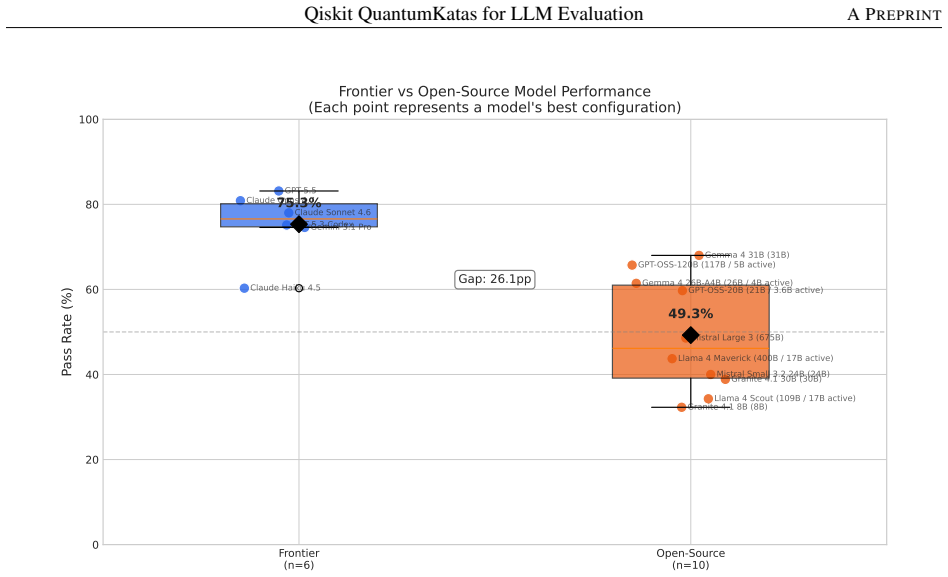
- Frontier models show an average 26.1 percentage point advantage over open-source models in best-configuration pass rates.
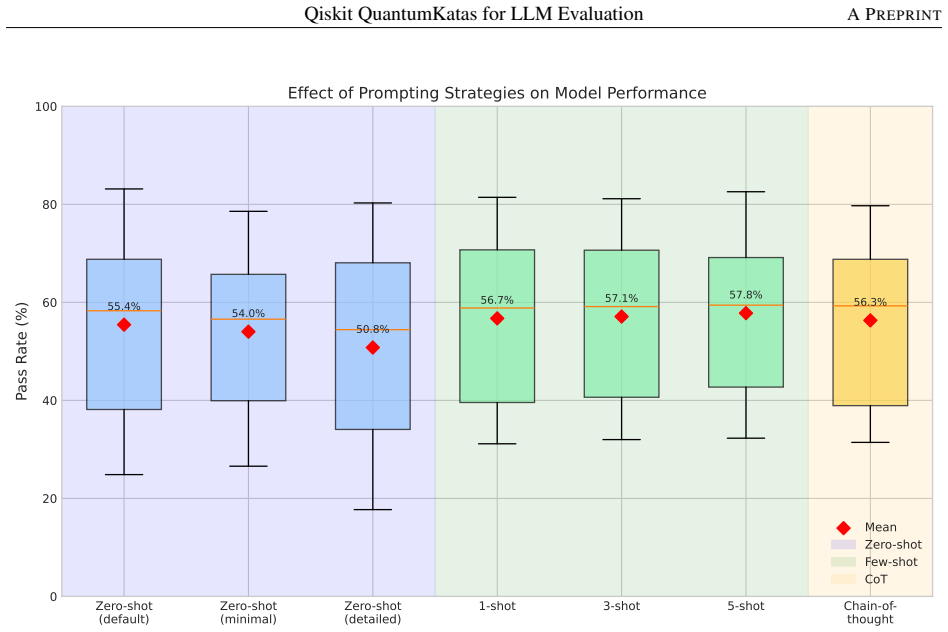
- Chain-of-thought prompting improves results for some models but reduces them for others, ranking mid-pack overall at 56.3% mean pass rate.
- Best configurations yield pass rates between 32.3% and 83.1% across the tested LLMs.
Where Pith is reading between the lines
- Researchers could use this benchmark to identify training data gaps in LLMs regarding quantum problem-solving approaches.
- Extending the benchmark with noisy simulations might reveal how well models handle realistic quantum hardware constraints.
- High-performing models on this test may be better suited for assisting in the development of new quantum algorithms beyond the curriculum.
Load-bearing premise
That the 350 tasks adapted from the original QuantumKatas curriculum, together with deterministic classical simulation checks, provide a faithful and unbiased measure of an LLM's actual quantum-computing capability rather than merely its ability to produce syntactically plausible code.
What would settle it
Observation that LLMs scoring high on the benchmark produce incorrect outputs when asked to solve quantum problems outside the 26 categories or when verification includes hardware noise models.
Figures
read the original abstract
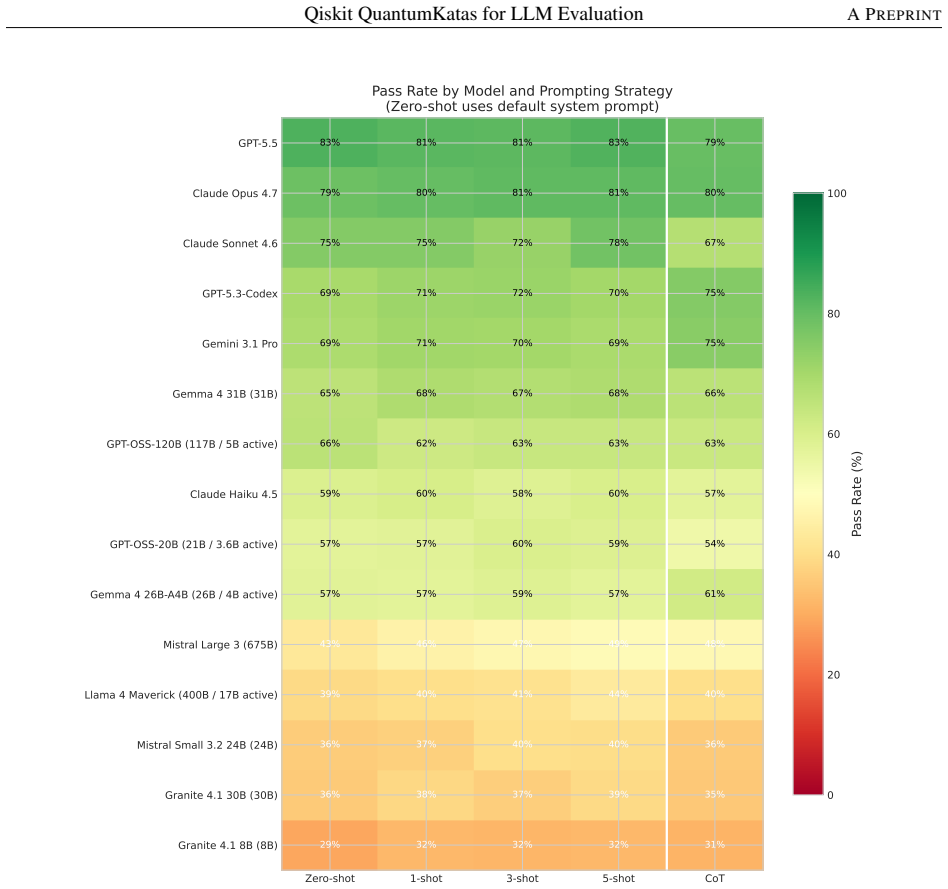
We adapt Microsoft's QuantumKatas -- a well-established quantum computing curriculum -- from Q# to Qiskit, the most widely-adopted quantum computing framework, and package it with an evaluation framework for systematic LLM assessment. The resulting benchmark comprises 350 tasks across 26 categories, spanning fundamental gates through advanced algorithms (Grover's, Simon's, Deutsch-Jozsa), error correction, key distribution, and quantum games. Each task includes a natural language prompt, canonical solution, and deterministic test verification via classical circuit simulation. By building on the QuantumKatas' proven pedagogical design rather than creating tasks from scratch, we inherit a principled difficulty progression and comprehensive concept coverage while contributing the framework adaptation, evaluation infrastructure, and empirical analysis. We evaluate 16 LLMs across 7 prompting configurations -- a total of 39,200 model runs -- to demonstrate the benchmark's utility. Three key findings emerge: (1) the benchmark effectively differentiates model capabilities, with best-configuration pass rates ranging from 32.3% to 83.1% and a 26.1 pp average gap between frontier and open-source models; (2) models perform well at implementing known algorithms (SimonsAlgorithm 82.1%, BasicGates 81.6%) but struggle with problem encoding (SolveSATWithGrover 34.4%, DistinguishUnitaries 40.0%); and (3) chain-of-thought prompting shows a modestly bimodal effect -- it is the best strategy for three models (two of them explicitly reasoning-tuned per vendor documentation) but degrades performance for the rest, leaving it mid-pack in aggregate (56.3% mean) behind few-shot-5 (57.8%). We release the benchmark, evaluation framework, and baseline results to support research on LLM capabilities in quantum computing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
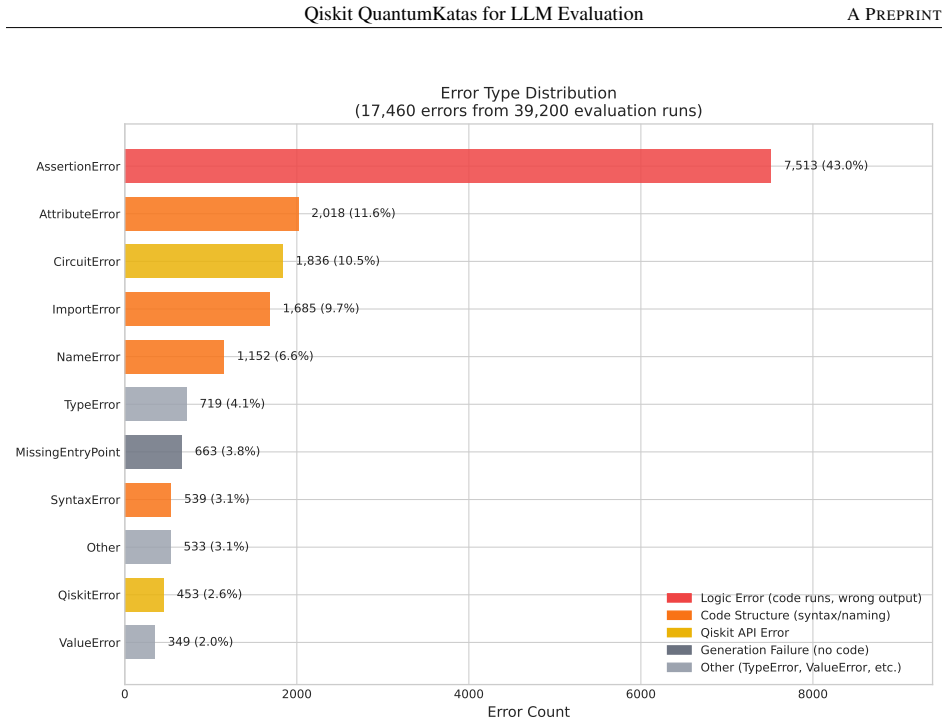
Summary. The manuscript adapts Microsoft's QuantumKatas curriculum from Q# to Qiskit, producing a benchmark of 350 tasks across 26 categories that span basic gates to advanced algorithms, error correction, and quantum games. Each task supplies a natural-language prompt, canonical solution, and deterministic verification via classical circuit simulation. The authors evaluate 16 LLMs under 7 prompting regimes (39,200 total runs), reporting clear model differentiation (best-configuration pass rates 32.3–83.1 %), category-specific patterns (strong on known algorithms such as SimonsAlgorithm at 82.1 %, weak on problem encoding such as SolveSATWithGrover at 34.4 %), and a modestly bimodal effect of chain-of-thought prompting. The benchmark, evaluation framework, and baseline results are released.
Significance. If the results hold, the work supplies a pedagogically grounded, non-synthetic benchmark that inherits a proven difficulty progression and uses deterministic verification, enabling reproducible assessment of LLM quantum-computing capabilities. The scale of the evaluation and the observed separation between frontier and open-source models, together with the public release of code and tasks, constitute a concrete resource for the community.
minor comments (3)
- [Abstract] Abstract: the reported 26.1 pp average gap between frontier and open-source models is stated without an accompanying definition of the two groups or the exact models assigned to each; this should be clarified in the main text or a table.
- The description of the 350 tasks would benefit from an explicit table listing the 26 categories together with task counts per category, to allow readers to assess coverage balance.
- The claim that chain-of-thought is 'mid-pack in aggregate (56.3 % mean)' should be accompanied by the exact ranking and scores of all seven prompting regimes for transparency.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the benchmark's significance, and recommendation of minor revision. The evaluation of 16 LLMs across 39,200 runs on the adapted 350-task QuantumKatas benchmark is intended to provide a reproducible, pedagogically grounded resource, and we are glad this is acknowledged.
Circularity Check
No significant circularity identified
full rationale
The paper reports empirical results from running 16 LLMs on 350 tasks (39,200 total invocations) adapted from Microsoft's external QuantumKatas curriculum, with correctness verified by deterministic classical circuit simulation. Pass rates, category gaps, and prompting effects are direct measurements against released tasks and simulators; no equations, fitted parameters, or self-referential definitions appear. The adaptation inherits an established pedagogical progression rather than deriving tasks or metrics from the present evaluation itself. No load-bearing self-citation chains, uniqueness theorems, or reductions of claimed quantities to inputs by construction are present. This is a standard benchmark release paper whose differentiation claims are internally consistent with the stated methodology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The original QuantumKatas tasks supply a principled difficulty progression and comprehensive concept coverage that remains valid after translation to Qiskit.
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Program Synthesis with Large Language Models
23 Qiskit QuantumKatas for LLM EvaluationA PREPRINT Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Scott Wen-tau Yih, Daniel Fried, Sida Wang, and Tao Yu. Ds-1000: A natural and reliable benchmark for data science code generation.arXiv preprint arXiv:2211.11501,
-
[4]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Sanjay Vishwakarma, Francis Harkins, Siddharth Golecha, Vishal Sharathchandra Bajpe, Nicolas Dupuis, Luca Buratti, David Kremer, Ismael Faro, Ruchir Puri, and Juan Cruz-Benito. Qiskit humaneval: An evaluation benchmark for quantum code generative models.arXiv preprint arXiv:2406.14712,
-
[6]
Quantumbench: A benchmark for quantum problem solving.arXiv preprint arXiv:2511.00092,
Shunya Minami, Tatsuya Ishigaki, Ikko Hamamura, Taku Mikuriya, Youmi Ma, Naoaki Okazaki, Hiroya Takamura, Yohichi Suzuki, and Tadashi Kadowaki. Quantumbench: A benchmark for quantum problem solving.arXiv preprint arXiv:2511.00092,
-
[7]
Accessed: 2025-01-14. Ali Javadi-Abhari, Matthew Treinish, Kevin Krsulich, Christopher J Wood, Jake Lishman, Julien Gacon, Simon Martiel, Paul D Nation, Lev S Bishop, Andrew W Cross, et al. Quantum computing with Qiskit.arXiv preprint arXiv:2405.08810,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
URLhttps://doi.org/10.5281/zenodo.2562111. Unitary Foundation. Quantum open source software survey 2024 results. https://unitary.foundation/posts/ 2025_survey_results/,
-
[9]
Accessed: 2025-01-22. Minyang Tian, Luyu Gao, et al. Scicode: A research coding benchmark curated by scientists.arXiv preprint arXiv:2407.13168,
-
[10]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Yinqi Zeng and Renjie Li. QuantumChem-200K: A large-scale open organic molecular dataset for quantum-chemistry property screening and language model benchmarking.arXiv preprint arXiv:2511.21747,
-
[13]
Nicolas Dupuis, Luca Buratti, Sanjay Vishwakarma, Aitana Viudes Forrat, David Kremer, Ismael Faro, Ruchir Puri, and Juan Cruz-Benito
Accessed: 2025-01-14. Nicolas Dupuis, Luca Buratti, Sanjay Vishwakarma, Aitana Viudes Forrat, David Kremer, Ismael Faro, Ruchir Puri, and Juan Cruz-Benito. Qiskit code assistant: Training LLMs for generating quantum computing code. In2024 IEEE LLM Aided Design Workshop (LAD), pages 1–4,
2025
-
[14]
Nicolas Dupuis, Adarsh Tiwari, Youssef Mroueh, David Kremer, Ismael Faro, and Juan Cruz-Benito
doi:10.1109/LAD62341.2024.10691762. Nicolas Dupuis, Adarsh Tiwari, Youssef Mroueh, David Kremer, Ismael Faro, and Juan Cruz-Benito. Quantum verifiable rewards for post-training qiskit code assistant.arXiv preprint arXiv:2508.20907,
-
[15]
24 Qiskit QuantumKatas for LLM EvaluationA PREPRINT Taku Mikuriya, Tatsuya Ishigaki, Masayuki Kawarada, Shunya Minami, Tadashi Kadowaki, Yohichi Suzuki, Soshun Naito, Shunya Takata, Takumi Kato, Tamotsu Basseda, Reo Yamada, and Hiroya Takamura. Qcoder bench- mark: Bridging language generation and quantum hardware through simulator-based feedback.arXiv pre...
-
[16]
Xiaoyu Guo, Minggu Wang, and Jianjun Zhao. Quanbench: Benchmarking quantum code generation with large language models.arXiv preprint arXiv:2510.16779, 2025a. Accepted at ASE
-
[17]
QuanBench+: A Unified Multi-Framework Benchmark for LLM-Based Quantum Code Generation
Slim et al. QuanBench+: A unified multi-framework benchmark for LLM-based quantum code generation.arXiv preprint arXiv:2604.08570,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
A PennyLane-Centric Dataset to Enhance LLM-based Quantum Code Generation using RAG
Abdul Basit et al. PennyLang: Pioneering LLM-based quantum code generation with a novel PennyLane-centric dataset. arXiv preprint arXiv:2503.02497, 2025a. Rui Yang, Ziruo Wang, Yuntian Gu, Tianyi Chen, Yitao Liang, and Tongyang Li. Qcircuitbench: A large-scale dataset for benchmarking quantum algorithm design.arXiv preprint arXiv:2410.07961,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Abdul Basit, Minghao Shao, Muhammad Haider Asif, Nouhaila Innan, Muhammad Kashif, Alberto Marchisio, and Muhammad Shafique. Qhackbench: Benchmarking large language models for quantum code generation using pennylane hackathon challenges.arXiv preprint arXiv:2506.20008, 2025b. Paz et al. StabilizerBench: A benchmark for AI-assisted quantum error correction ...
-
[20]
Mohamed Afane, Kayla Laufer, Wenqi Wei, Ying Mao, Junaid Farooq, Ying Wang, and Juntao Chen. QC-Bench: What do language models know about quantum computing? https://openreview.net/forum?id=hrDlJGrPqc, 2026a. Afane et al. Quantum-Audit: Evaluating the reasoning limits of LLMs on quantum computing.arXiv preprint arXiv:2602.10092, 2026b. Cao et al. QCalEval:...
-
[21]
Qu et al. QuantumQA: Enhancing scientific reasoning via physics-consistent dataset and verification-aware reinforce- ment learning.arXiv preprint arXiv:2604.18176,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Cong Yu, Valter Uotila, Shilong Deng, Qingyuan Wu, Tuo Shi, Songlin Jiang, Lei You, and Bo Zhao. QUASAR – quantum assembly code generation using tool-augmented LLMs via agentic RL.arXiv preprint arXiv:2510.00967,
-
[23]
Xiaoyu Guo, Shinobu Saito, and Jianjun Zhao. M2qcode: A model-driven framework for generating multi-platform quantum programs.arXiv preprint arXiv:2510.17110, 2025b. Accepted at ASE
-
[24]
PennyCoder: Efficient domain-specific LLMs for PennyLane-based quantum code generation
Abdul Basit et al. PennyCoder: Efficient domain-specific LLMs for PennyLane-based quantum code generation. In 2025 IEEE International Conference on Quantum Computing and Engineering (QCE), 2025c. Shlomo Kashani. QuantumLLMInstruct: A 500k LLM instruction-tuning dataset with problem-solution pairs for quantum computing.arXiv preprint arXiv:2412.20956,
-
[25]
David Deutsch and Richard Jozsa
Accessed: 2025-01-14. David Deutsch and Richard Jozsa. Rapid solution of problems by quantum computation.Proceedings of the Royal Society of London. Series A: Mathematical and Physical Sciences, 439(1907):553–558,
2025
-
[26]
OpenAI. Gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025a. Google DeepMind. Gemini 3 pro model card. https://storage.googleapis.com/deepmind-media/ Model-Cards/Gemini-3-Pro-Model-Card.pdf,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Mistral AI
Accessed: 2025-01-22. Mistral AI. Mistral-large-3-675b-instruct. https://huggingface.co/mistralai/ Mistral-Large-3-675B-Instruct-2512, 2025a. Accessed: 2025-01-22. Meta AI. Llama 4: Multimodal intelligence. https://ai.meta.com/blog/ llama-4-multimodal-intelligence/,
2025
-
[28]
Accessed: 2025-01-22. OpenAI. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025b. Google DeepMind. Gemma 4 language models. https://huggingface.co/google/gemma-4-31b-it ,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
IBM Research
Accessed: 2026-04-30. IBM Research. Granite 4.1 language models. https://huggingface.co/collections/ibm-granite/ granite-41-language-models,
2026
-
[30]
Mistral AI
Accessed: 2026-04-30. Mistral AI. Mistral-small-3.2-24b-instruct. https://huggingface.co/mistralai/Mistral-Small-3. 2-24B-Instruct-2506, 2025b. Accessed: 2025-01-22. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.Advances ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.