Recognition: no theorem link
QuanBench+: A Unified Multi-Framework Benchmark for LLM-Based Quantum Code Generation
Pith reviewed 2026-05-14 23:55 UTC · model grok-4.3
The pith
A new benchmark finds LLMs generate quantum code with up to 59.5% success in Qiskit but lower in other frameworks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
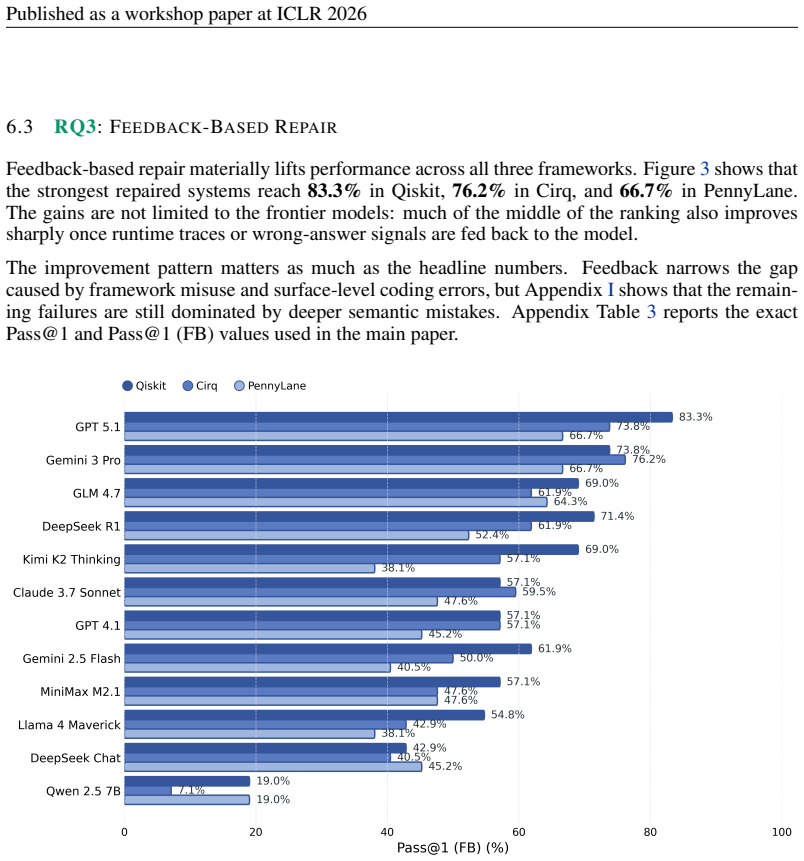
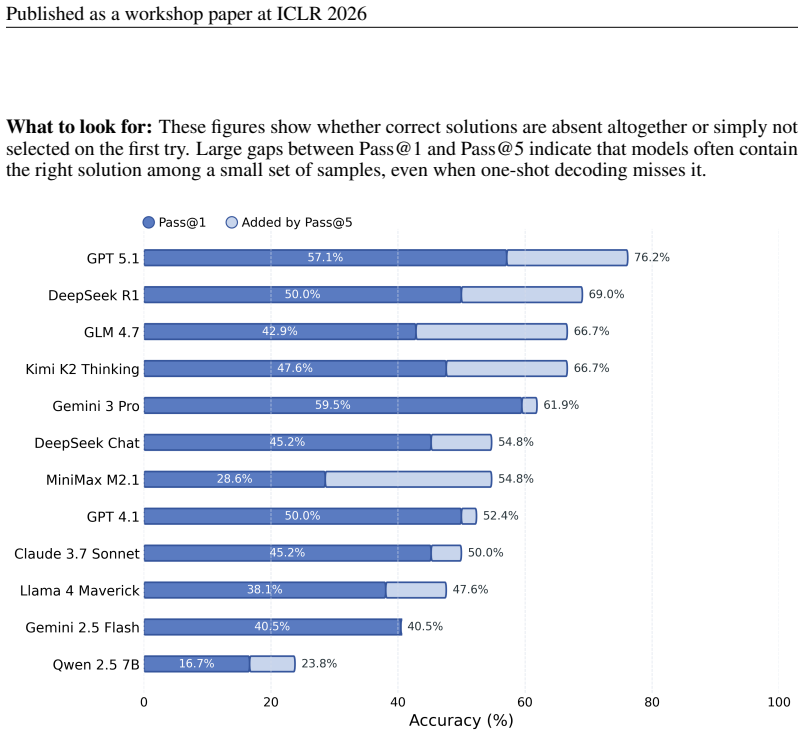
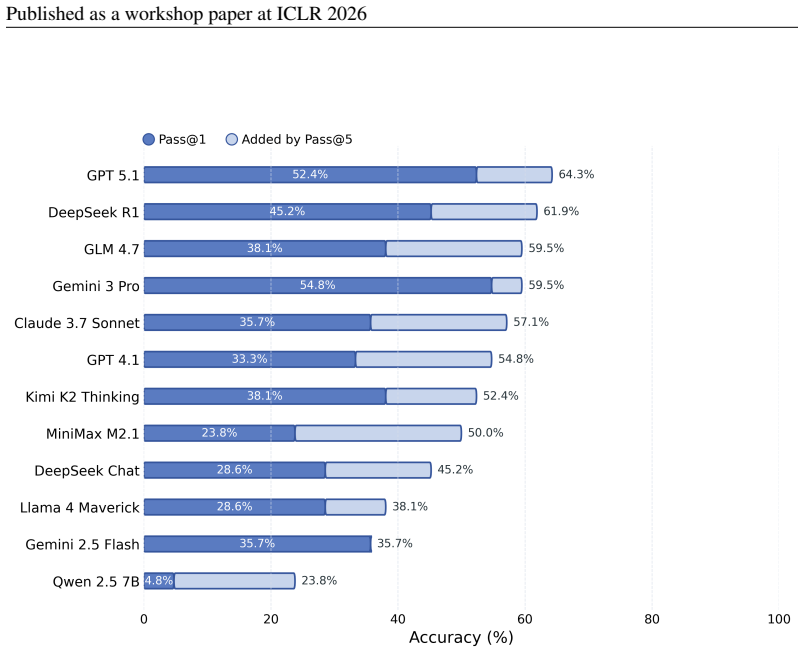
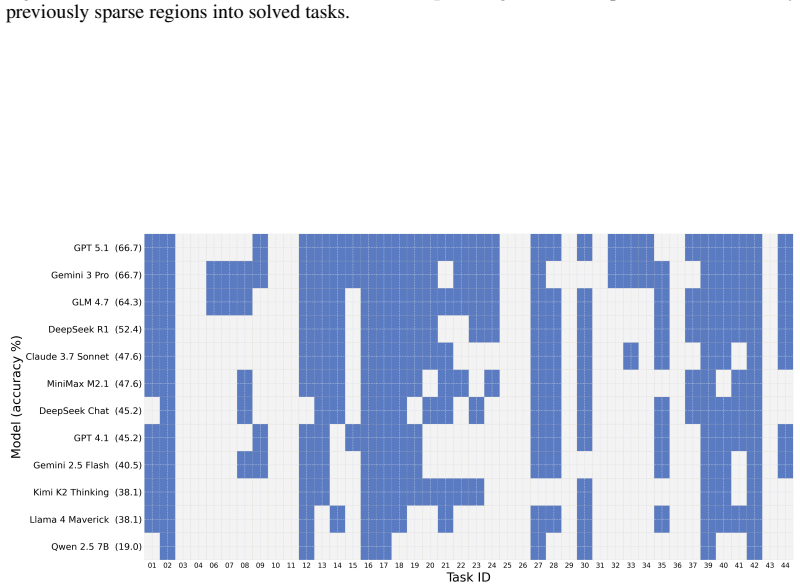
The paper establishes QuanBench+ as a benchmark that aligns 42 tasks across three major quantum frameworks to measure LLM performance in generating executable quantum code, reporting that top one-shot accuracies range from 42.9% to 59.5% and improve markedly with repair feedback, thereby showing that multi-framework reliability remains an open challenge.
What carries the argument
The QuanBench+ benchmark, which provides 42 aligned tasks covering quantum algorithms, gate decomposition, and state preparation, evaluated via functional tests and KL-divergence across Qiskit, PennyLane, and Cirq.
If this is right
- Models exhibit different strengths depending on the quantum framework used.
- Feedback repair is an effective way to boost performance on quantum coding tasks.
- Current LLMs still require framework-specific knowledge for high accuracy in quantum code generation.
- Pass rates can be measured consistently using executable tests to allow fair comparison.
- The benchmark highlights the need for better generalization in quantum-aware LLMs.
Where Pith is reading between the lines
- Developers of LLMs for quantum computing should prioritize training on multiple frameworks to improve cross-compatibility.
- Future work could test whether larger models close the performance gaps between frameworks.
- Integrating the benchmark with automated verification tools might further improve repair success.
- The dependency on framework knowledge suggests that abstract quantum circuit representations could help LLMs.
Load-bearing premise
The 42 aligned tasks successfully isolate quantum reasoning ability from framework familiarity, and executable tests plus KL-divergence fully capture correctness for quantum code.
What would settle it
Observing that performance scores become similar across frameworks when models are tested without prior exposure to framework documentation or examples.
Figures




















read the original abstract
Large Language Models (LLMs) are increasingly used for code generation, yet quantum code generation is still evaluated mostly within single frameworks, making it difficult to separate quantum reasoning from framework familiarity. We introduce QuanBench+, a unified benchmark spanning Qiskit, PennyLane, and Cirq, with 42 aligned tasks covering quantum algorithms, gate decomposition, and state preparation. We evaluate models with executable functional tests, report Pass@1 and Pass@5, and use KL-divergence-based acceptance for probabilistic outputs. We additionally study Pass@1 after feedback-based repair, where a model may revise code after a runtime error or wrong answer. Across frameworks, the strongest one-shot scores reach 59.5% in Qiskit, 54.8% in Cirq, and 42.9% in PennyLane; with feedback-based repair, the best scores rise to 83.3%, 76.2%, and 66.7%, respectively. These results show clear progress, but also that reliable multi-framework quantum code generation remains unsolved and still depends strongly on framework-specific knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces QuanBench+, a unified benchmark for LLM-based quantum code generation spanning Qiskit, PennyLane, and Cirq with 42 aligned tasks covering quantum algorithms, gate decomposition, and state preparation. It evaluates models using executable functional tests, reports Pass@1 and Pass@5 scores, applies KL-divergence-based acceptance for probabilistic outputs, and studies Pass@1 after feedback-based repair. The strongest one-shot scores are 59.5% (Qiskit), 54.8% (Cirq), and 42.9% (PennyLane), rising to 83.3%, 76.2%, and 66.7% after repair. The authors conclude that reliable multi-framework quantum code generation remains unsolved and depends strongly on framework-specific knowledge.
Significance. If the 42 aligned tasks successfully isolate quantum reasoning from framework familiarity, this work supplies a valuable standardized tool for evaluating LLMs in quantum programming. The multi-framework design, executable functional tests, and inclusion of a feedback-based repair loop are concrete strengths that could inform future model development. The reported performance gaps and repair gains highlight persistent challenges in cross-framework generalization.
major comments (3)
- [Abstract] Abstract and benchmark description: The central claim that performance gaps demonstrate dependence on framework-specific knowledge assumes the 42 aligned tasks hold quantum content fixed while varying only syntax. No evidence is provided that task difficulty was matched for API verbosity, gate-set expressiveness, or frequency of each framework's idioms in pre-training corpora. Without such controls, the observed ordering (Qiskit 59.5% > Cirq 54.8% > PennyLane 42.9%) could track corpus imbalance rather than isolated quantum reasoning.
- [Abstract] Abstract and evaluation section: Concrete Pass@1 and repair scores are stated, yet no details are supplied on task construction, model selection, statistical tests, or data exclusion rules. This absence makes the central performance claims difficult to verify or reproduce from the available text.
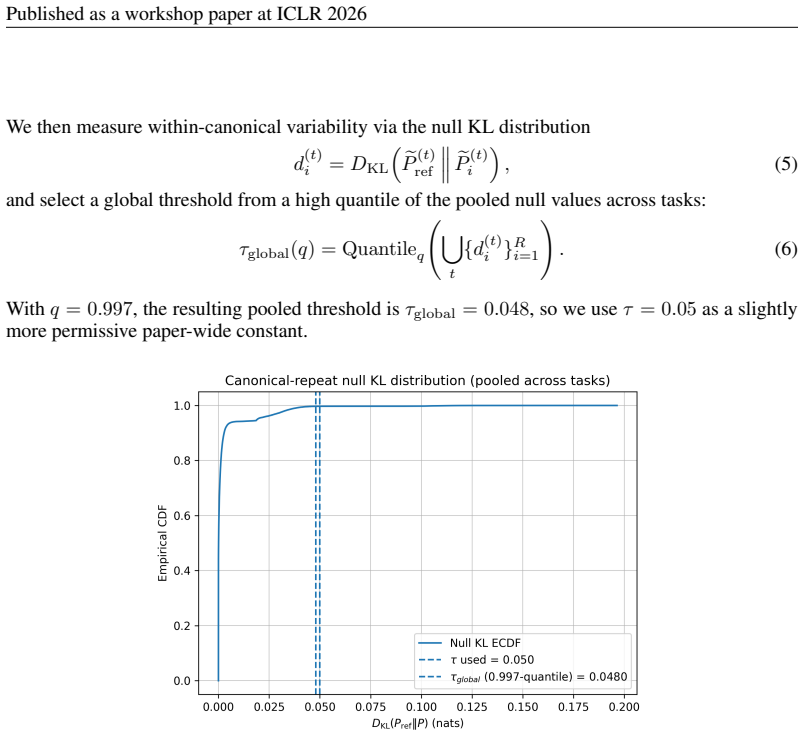
- [Evaluation Methodology] KL-divergence and repair loop: The KL-divergence acceptance criterion together with framework-specific runtime feedback in the repair loop couples the correctness metric to framework details, which risks confounding the intended isolation of quantum reasoning ability from framework familiarity.
minor comments (1)
- [Results] Results tables or figures would benefit from explicit confidence intervals or p-values when comparing Pass@1 scores across frameworks to support the reported ordering.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to improve methodological transparency, discuss potential confounds, and clarify the scope of our claims.
read point-by-point responses
-
Referee: [Abstract] The central claim that performance gaps demonstrate dependence on framework-specific knowledge assumes the 42 aligned tasks hold quantum content fixed while varying only syntax. No evidence is provided that task difficulty was matched for API verbosity, gate-set expressiveness, or frequency of each framework's idioms in pre-training corpora. The observed ordering could track corpus imbalance rather than isolated quantum reasoning.
Authors: We agree that explicit controls for verbosity, expressiveness, and corpus frequency would strengthen the isolation claim. Tasks were constructed by mapping equivalent quantum functionality (e.g., the same algorithm or state preparation expressed via each framework's native APIs and gate sets), but we did not quantify pre-training frequency or verbosity metrics. In the revision we added a dedicated limitations subsection with examples of alignment, corpus-bias discussion, and an acknowledgment that the Qiskit > Cirq > PennyLane ordering may partly reflect training-data imbalance. We retain the claim that framework-specific knowledge contributes because the gap persists across multiple models and task categories. revision: partial
-
Referee: [Abstract] Concrete Pass@1 and repair scores are stated, yet no details are supplied on task construction, model selection, statistical tests, or data exclusion rules. This absence makes the central performance claims difficult to verify or reproduce from the available text.
Authors: The full manuscript already contains these details in Section 3 (task construction via aligned quantum primitives) and Section 4 (model selection, Pass@k definition, and execution environment). To address the referee's concern we have expanded the abstract with a one-sentence methodological summary, added explicit statistical significance tests (paired t-tests on Pass@1 across models), and inserted a data-exclusion protocol (e.g., discarding tasks with non-deterministic outputs beyond KL tolerance) into the evaluation section. revision: yes
-
Referee: [Evaluation Methodology] KL-divergence and repair loop: The KL-divergence acceptance criterion together with framework-specific runtime feedback in the repair loop couples the correctness metric to framework details, which risks confounding the intended isolation of quantum reasoning ability from framework familiarity.
Authors: We acknowledge the coupling. KL-divergence is used only for probabilistic outputs to provide a syntax-agnostic acceptance threshold; the repair loop necessarily uses framework-specific runtime errors because the benchmark evaluates executable code generation. The manuscript's goal is practical multi-framework performance rather than pure reasoning isolation. In revision we clarified this scope, added an ablation that reports one-shot Pass@1 without the repair loop, and noted that any future benchmark seeking stricter isolation would need synthetic framework-agnostic interfaces. revision: partial
Circularity Check
No circularity: benchmark applies new tasks and standard metrics to existing models
full rationale
The paper introduces 42 aligned tasks across Qiskit, PennyLane, and Cirq, then directly measures Pass@1, Pass@5, and KL-divergence on off-the-shelf LLMs using executable functional tests. No equations, fitted parameters, or predictions are defined in terms of the reported outcomes. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming reduces the evaluation results to inputs by construction. The central claims are empirical measurements, not derivations that collapse to the benchmark definition itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Executable functional tests and Pass@k metrics measure quantum code correctness
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.