Lost in Sampling: Assessing Lexical Reachability in LLMs via the Word Coverage Score (WCS)
Pith reviewed 2026-06-29 18:04 UTC · model grok-4.3
The pith
Sampling methods in LLMs prune many contextually appropriate low-frequency words from outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Word Coverage Score measures the lexical survival rate of low-frequency, high-information human words as a function of sampling parameters. By auditing models on human-authored corpus fragments, it identifies logical lexical choices that are rendered unreachable by the decoder even when they reside within the probability space. This provides evidence that standard sampling defaults act as unintended censorship mechanisms.
What carries the argument
The Word Coverage Score (WCS), which quantifies the pruning of contextually appropriate human vocabulary by sampling filters.
If this is right
- Optimizing sampling parameters can trade off coherence against lexical richness.
- The metric serves as a diagnostic for preserving language diversity in models.
- Standard defaults homogenize discourse by excluding unique human expressions.
- Audits reveal which words are unreachable despite being in the probability space.
Where Pith is reading between the lines
- This suggests that alternative decoding strategies could recover more human-like lexical choices.
- Applications requiring creative writing might benefit from WCS-guided sampling adjustments.
- The approach could extend to evaluating other aspects of output diversity beyond single words.
Load-bearing premise
That the words from human fragments are contextually appropriate and that the model assigns them non-zero probability independently of the sampling filters being tested.
What would settle it
Finding a set of human text fragments where the low-frequency words identified by WCS are frequently generated by the model under standard sampling parameters would contradict the pruning claim.
Figures

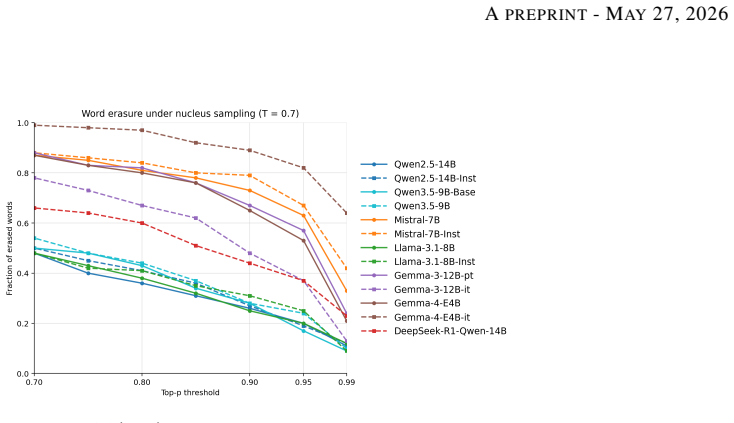
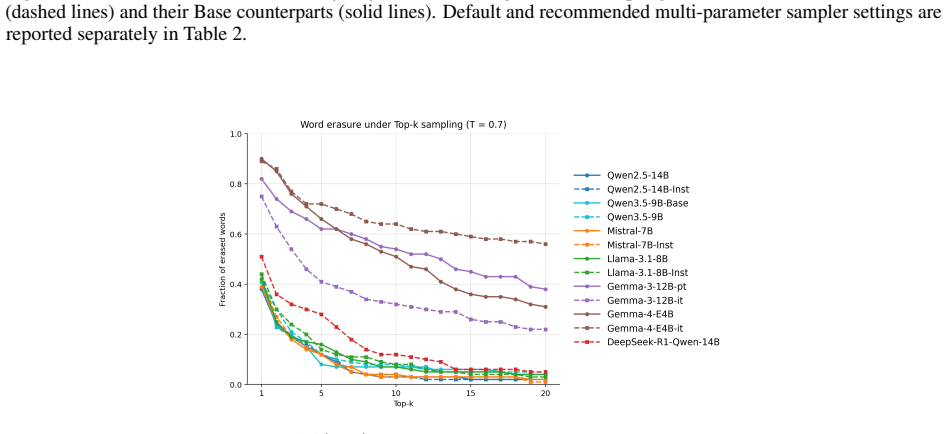

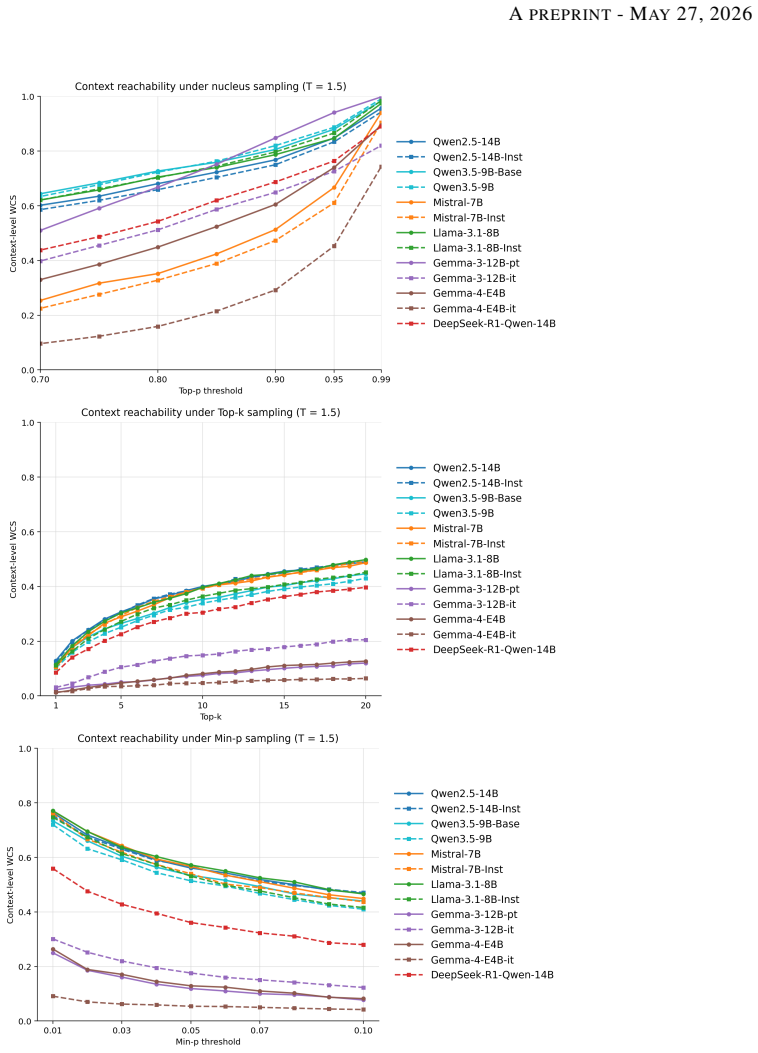

read the original abstract
Modern Large Language Models (LLMs) are often criticized for producing repetitive and homogeneous text, despite possessing vast latent vocabularies. While previous research has focused on model knowledge and training data, we investigate the role of decoding mechanics in suppressing linguistic diversity. We introduce the Word Coverage Score (WCS), a metric that quantifies the extent to which contextually appropriate human vocabulary is mathematically pruned by standard sampling filters (e.g., Top-$p$, Top-$k$, and Min-$p$). Rather than assessing static knowledge, the WCS measures the lexical survival rate of low-frequency, high-information human words as a function of sampling parameters. By auditing open-weight models on human-authored corpus fragments, we identify which logical lexical choices are rendered unreachable by the decoder, even when they reside within the probability space. Our results provide quantitative evidence that industry-standard sampling defaults act as unintended censorship mechanisms, smoothing the unique textures of human expression into a homogenized discourse. The WCS offers a rigorous framework for optimizing the trade-off between text coherence and lexical richness, providing a diagnostic tool for preserving the diversity of human language in generative models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Word Coverage Score (WCS), a metric that quantifies the survival rate of low-frequency, high-information human words under standard sampling filters (Top-p, Top-k, Min-p) in LLMs. It audits open-weight models on human-authored corpus fragments and claims that default sampling parameters act as unintended censorship by pruning contextually appropriate lexical choices even when they lie within the probability space, leading to homogenized output; WCS is positioned as a diagnostic for balancing coherence and lexical richness.
Significance. If WCS can be shown to rely on an independent appropriateness oracle (distinct from model logits or sampling thresholds), the work would provide a useful framework for diagnosing decoding-induced loss of diversity, complementing existing studies on training data and model knowledge. The emphasis on dynamic reachability during generation rather than static vocabulary size is a potentially valuable angle.
major comments (2)
- [Abstract and WCS definition] Abstract and WCS definition: The central claim requires that 'contextually appropriate' low-frequency words are identified independently of the audited model's probability distribution. If appropriateness judgments or low-frequency selection rely on the same model's logits (a common practice), then the finding that sampling prunes them is tautological by construction, since sampling filters low-probability tokens by design. This directly undermines the assertion that such words 'reside within the probability space' yet are censored. The abstract provides no clarification of an independent oracle; the methods section must explicitly detail the procedure.
- [Empirical evaluation / Results] Empirical evaluation: The abstract asserts 'quantitative evidence' from auditing open-weight models and reports survival rates as a function of sampling parameters, yet no concrete WCS values, tables, figures, survival-rate statistics, or error analysis appear in the visible sections. Without these, the claim that industry-standard defaults act as censorship mechanisms cannot be evaluated or reproduced.
minor comments (1)
- [Notation and definitions] Clarify all variables and the exact formula for WCS, including how human corpus fragments are selected and how 'high-information' is operationalized.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below with clarifications on our methodology and results.
read point-by-point responses
-
Referee: [Abstract and WCS definition] Abstract and WCS definition: The central claim requires that 'contextually appropriate' low-frequency words are identified independently of the audited model's probability distribution. If appropriateness judgments or low-frequency selection rely on the same model's logits (a common practice), then the finding that sampling prunes them is tautological by construction, since sampling filters low-probability tokens by design. This directly undermines the assertion that such words 'reside within the probability space' yet are censored. The abstract provides no clarification of an independent oracle; the methods section must explicitly detail the procedure.
Authors: The contextually appropriate words are drawn from human-authored corpus fragments, which function as an independent oracle separate from any audited model's logits. Low-frequency words are first identified in human text based on contextual fit within those fragments; only afterward do we compute the model's assigned probabilities and test survival under sampling filters. This ordering avoids tautology. We will revise the methods section to state this independence explicitly and describe the extraction procedure in detail. revision: yes
-
Referee: [Empirical evaluation / Results] Empirical evaluation: The abstract asserts 'quantitative evidence' from auditing open-weight models and reports survival rates as a function of sampling parameters, yet no concrete WCS values, tables, figures, survival-rate statistics, or error analysis appear in the visible sections. Without these, the claim that industry-standard defaults act as censorship mechanisms cannot be evaluated or reproduced.
Authors: The complete manuscript contains a results section with tabulated WCS values, survival-rate statistics across models and parameter settings, figures, and error analysis. These elements appear to have been omitted from the review copy. We will ensure all quantitative results and reproducibility details are prominently included in the revised submission. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract defines WCS as a new metric that measures lexical survival rate of low-frequency human words (drawn from human-authored corpus fragments) under sampling filters. No equations, definitions, or self-citations are shown that reduce the metric or its 'contextually appropriate' judgments to model probabilities or sampling parameters by construction. The derivation chain as described remains independent of the audited outputs, with human corpus serving as the external reference. This is the expected honest non-finding given the absence of load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Artificial hivemind: The open-ended homogeneity of language models (and beyond)
Liwei Jiang, Yuanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Yulia Tsvetkov, Maarten Sap, and Yejin Choi. Artificial hivemind: The open-ended homogeneity of language models (and beyond). InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
-
[2]
Large language models are homogeneously creative.PNAS Nexus, 5(3):pgag042, 03 2026
Emily Wenger and Yoed N Kenett. Large language models are homogeneously creative.PNAS Nexus, 5(3):pgag042, 03 2026
2026
-
[3]
Doshi and Oliver P
Anil R. Doshi and Oliver P. Hauser. Generative ai enhances individual creativity but reduces the collective diversity of novel content.Science Advances, 10(28):eadn5290, 2024
2024
-
[4]
Instruction tuning for large language models: A survey.ACM Computing Surveys, 58(7):1–36, 2026
Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Guoyin Wang, et al. Instruction tuning for large language models: A survey.ACM Computing Surveys, 58(7):1–36, 2026
2026
-
[5]
Evaluating the diversity and quality of llm generated content
Alexander Shypula, Shuo Li, Botong Zhang, Vishakh Padmakumar, Kayo Yin, and Osbert Bastani. Evaluating the diversity and quality of llm generated content. InICLR 2025 Third Workshop on Deep Learning for Code
2025
-
[6]
The price of format: Diversity collapse in llms.arXiv preprint arXiv:2505.18949, 2025
Longfei Yun, Chenyang An, Zilong Wang, Letian Peng, and Jingbo Shang. The price of format: Diversity collapse in llms.arXiv preprint arXiv:2505.18949, 2025
-
[7]
Mingyi Liu. The alignment tax: Response homogenization in aligned llms and its implications for uncertainty estimation.arXiv preprint arXiv:2603.24124, 2026
-
[8]
Lexical diversity, syntactic complexity, and readability: A corpus-based analysis of chatgpt and l2 student essays
Daniel R Fredrick and Laurence Craven. Lexical diversity, syntactic complexity, and readability: A corpus-based analysis of chatgpt and l2 student essays. InFrontiers in Education, volume 10, page 1616935. Frontiers Media SA, 2025
2025
-
[9]
Beware of words: Evaluating the lexical diversity of conversational llms using chatgpt as case study.ACM Transactions on Intelligent Systems and Technology, 16(6):1–15, 2025
Gonzalo Martínez, José Alberto Hernández, Javier Conde, Pedro Reviriego, and Elena Merino-Gómez. Beware of words: Evaluating the lexical diversity of conversational llms using chatgpt as case study.ACM Transactions on Intelligent Systems and Technology, 16(6):1–15, 2025
2025
-
[10]
Ravenio books, 2016
George Kingsley Zipf.Human behavior and the principle of least effort: An introduction to human ecology. Ravenio books, 2016
2016
-
[11]
The Surprising Universality of LLM Outputs: A Real-Time Verification Primitive
Alex Bogdan and Adrian de Valois-Franklin. The surprising universality of llm outputs: A real-time verification primitive.arXiv preprint arXiv:2604.25634, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
The garden of forking paths
Jorge Luis Borges. The garden of forking paths. InCollected Fictions, pages 119–128. Penguin Books, New York,
-
[13]
Original work published 1941
1941
-
[14]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[15]
Turning up the heat: Min-p sampling for creative and coherent llm outputs
Nguyen Nhat Minh, Andrew Baker, Clement Neo, Allen G Roush, Andreas Kirsch, and Ravid Shwartz-Ziv. Turning up the heat: Min-p sampling for creative and coherent llm outputs. InThe Thirteenth International Conference on Learning Representations
-
[16]
Min-$k$ Sampling: Decoupling Truncation from Temperature Scaling via Relative Logit Dynamics
Yuanhao Ding, Meimingwei Li, Esteban Garces Arias, Matthias Aßenmacher, Christian Heumann, and Chong- sheng Zhang. Min-k sampling: Decoupling truncation from temperature scaling via relative logit dynamics.arXiv preprint arXiv:2604.11012, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Top-n−σ : Not all logits are you need.arXiv preprint arXiv:2411.07641, 2024
Chenxia Tang, Jianchun Liu, Hongli Xu, and Liusheng Huang. Top-n−σ : Not all logits are you need.arXiv preprint arXiv:2411.07641, 2024
-
[18]
Natural language corpus data
Peter Norvig. Natural language corpus data. In Toby Segaran and Jeff Hammerbacher, editors,Beautiful Data: The Stories Behind Elegant Data Solutions, chapter 14, pages 219–242. O’Reilly Media, Inc., 2009
2009
-
[19]
Moby word lists
Grady Ward. Moby word lists. Project Gutenberg eBook No. 3201, 2002
2002
-
[20]
Compressive Transformers for Long-Range Sequence Modelling
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, and Timothy P. Lillicrap. Compressive transformers for long-range sequence modelling.arXiv preprint arXiv:1911.05507, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[21]
Gemini 2.5 flash large language model, 2025
Google DeepMind. Gemini 2.5 flash large language model, 2025. Accessed via the Google Generative Language API
2025
-
[22]
Llama-3.1-8B
Meta AI. Llama-3.1-8B. https://huggingface.co/meta-llama/Llama-3.1-8B , 2024. Hugging Face model checkpoint
2024
-
[23]
Llama-3.1-8B-Instruct
Meta AI. Llama-3.1-8B-Instruct. https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct , 2024. Hugging Face model checkpoint. 12 APREPRINT- MAY27, 2026
2024
-
[24]
Mistral-7B-v0.3
Mistral AI. Mistral-7B-v0.3. https://huggingface.co/mistralai/Mistral-7B-v0.3, 2024. Hugging Face model checkpoint
2024
-
[25]
Mistral-7B-Instruct-v0.3
Mistral AI. Mistral-7B-Instruct-v0.3. https://huggingface.co/mistralai/Mistral-7B-Instruct-v0. 3, 2024. Hugging Face model checkpoint
2024
-
[26]
Qwen3.5-9B-Base
Qwen Team. Qwen3.5-9B-Base. https://huggingface.co/Qwen/Qwen3.5-9B-Base, 2025. Hugging Face model checkpoint
2025
-
[27]
Qwen3.5-9B
Qwen Team. Qwen3.5-9B. https://huggingface.co/Qwen/Qwen3.5-9B, 2025. Hugging Face model checkpoint
2025
-
[28]
Qwen2.5-14B
Qwen Team. Qwen2.5-14B. https://huggingface.co/Qwen/Qwen2.5-14B, 2024. Hugging Face model checkpoint
2024
-
[29]
Qwen2.5-14B-Instruct
Qwen Team. Qwen2.5-14B-Instruct. https://huggingface.co/Qwen/Qwen2.5-14B-Instruct, 2024. Hug- ging Face model checkpoint
2024
-
[30]
Gemma-3-12B-pt
Google DeepMind. Gemma-3-12B-pt. https://huggingface.co/google/gemma-3-12b-pt , 2025. Hugging Face model checkpoint
2025
-
[31]
Gemma-3-12B-it
Google DeepMind. Gemma-3-12B-it. https://huggingface.co/google/gemma-3-12b-it , 2025. Hugging Face model checkpoint
2025
-
[32]
Gemma-4-E4B
Google DeepMind. Gemma-4-E4B. https://huggingface.co/google/gemma-4-E4B, 2026. Hugging Face model checkpoint
2026
-
[33]
Gemma-4-E4B-it
Google DeepMind. Gemma-4-E4B-it. https://huggingface.co/google/gemma-4-E4B-it , 2026. Hugging Face model checkpoint
2026
-
[34]
DeepSeek-R1-Distill-Qwen-14B
DeepSeek-AI. DeepSeek-R1-Distill-Qwen-14B. https://huggingface.co/deepseek-ai/ DeepSeek-R1-Distill-Qwen-14B, 2025. Hugging Face model checkpoint
2025
-
[35]
Is temperature the creativity parameter of large language models?, 2024
Max Peeperkorn, Tom Kouwenhoven, Dan Brown, and Anna Jordanous. Is temperature the creativity parameter of large language models?, 2024. To be published in the Proceedings of the 15th International Conference on Computational Creativity (ICCC 2024). 13 APREPRINT- MAY27, 2026 A Appendix: Selected Word List and Aggregate Reachability Table 3 lists the 100 t...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.