Guiding LLM Post-training Data Engineering with Model Internals from Sparse Autoencoders
Pith reviewed 2026-06-29 18:49 UTC · model grok-4.3
The pith
SAERL uses sparse autoencoders on model internals to model data diversity, difficulty, and quality for LLM reinforcement learning post-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
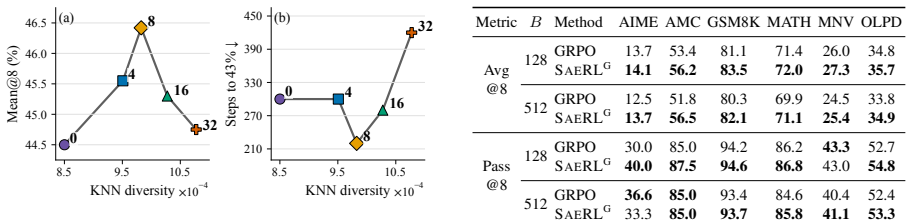
SAERL shows that modeling diversity, difficulty, and quality directly from SAE-extracted model internals produces concrete data engineering operations that improve RL post-training outcomes, including higher final accuracy and faster convergence to target performance.
What carries the argument
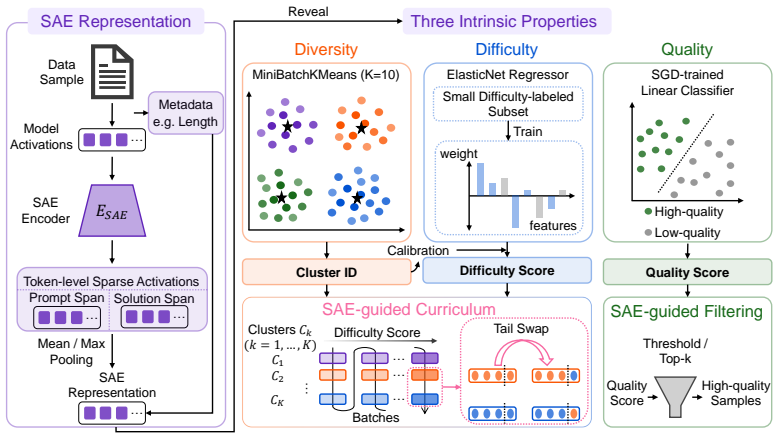
Sparse autoencoder features that define batch diversity via clustering and mixing, a difficulty proxy for curriculum ordering, and a quality probe for filtering.
If this is right
- Data engineering for RL can rely on internal model signals instead of external heuristics alone.
- Curriculum ordering and filtering based on SAE proxies reduce the total training steps needed.
- The same SAE features can be reused across different model families, scales, and RL algorithms.
- Batch diversity control via SAE clustering leads to more effective training data mixtures.
Where Pith is reading between the lines
- This method may extend to supervised fine-tuning stages where similar data properties matter.
- SAE-based signals could help identify which subsets of a fixed dataset are most valuable without new collection.
- If the three properties prove incomplete, adding other SAE-derived properties might yield further gains.
Load-bearing premise
SAE features from model internals reliably capture and causally affect the data properties of diversity, difficulty, and quality in ways that improve downstream RL performance.
What would settle it
Run SAERL with SAE signals replaced by random or purely external signals and check whether the accuracy gains and step reductions disappear.
Figures

read the original abstract
Model internals encode rich information about how a large language model (LLM) processes its training data; however, post-training data engineering largely relies on external signals and ignores rich intrinsic signals lying in model internals. We propose SAERL, a data engineering framework for LLM reinforcement learning (RL). It models three intrinsic data properties: diversity, difficulty, and quality, using model internals extracted with Sparse Autoencoder (SAE), an advanced mechanistic interpretability tool. Each property grounds a concrete data engineering operation: SAE-space clustering with moderate batch mixing for batch diversity control, a difficulty proxy for easy-to-hard curriculum ordering, and a quality probe for data filtering. SAERL improves average accuracy by 3.00% over vanilla GRPO and reaches target accuracy with 20% fewer training steps on Qwen2.5-Math-1.5B, with consistent gains across model scales and RL algorithms. Experiments show that SAE transfers effectively across model families and scales, serving as a lightweight and reusable data engineering tool. These results demonstrate that model internals are a powerful and practical source of signals for post-training data engineering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SAERL, a data engineering framework for LLM RL post-training that extracts features from model internals using Sparse Autoencoders (SAEs) to model three properties: diversity (via SAE-space clustering with moderate batch mixing), difficulty (via a proxy for easy-to-hard curriculum), and quality (via a probe for filtering). It reports that SAERL achieves a 3.00% average accuracy improvement over vanilla GRPO, reaches target accuracy with 20% fewer training steps on Qwen2.5-Math-1.5B, shows consistent gains across model scales and RL algorithms, and transfers effectively across model families and scales.
Significance. If the results hold under proper controls isolating the SAE contribution, the work would be significant as it demonstrates a practical, lightweight use of mechanistic interpretability tools (SAEs) to provide intrinsic signals for data operations in RL training, potentially improving efficiency over external-signal methods with reported cross-scale consistency.
major comments (2)
- [Experimental evaluation] The experimental results (including the 3.00% accuracy gain and 20% step reduction on Qwen2.5-Math-1.5B) do not include ablations that apply the same data operations (clustering, curriculum ordering, filtering) but replace SAE-derived signals with random or non-SAE baselines. Without this, it is impossible to establish that the SAE internals are causally responsible for the gains rather than the operations themselves.
- [Method and framework description] The central modeling assumption—that SAE features reliably and causally capture diversity, difficulty, and quality in ways that drive downstream RL improvements—is load-bearing for the claim that model internals are a 'powerful and practical source of signals,' yet the paper provides no direct tests (e.g., intervention on SAE features or correlation vs. causation analysis) to support this over mere correlation with external metrics.
minor comments (2)
- [Abstract] The abstract states concrete numerical gains but omits details on number of runs, statistical tests, variance, or exact baseline implementations, which should be added for clarity even if present in the main text.
- Notation and pseudocode for the SAE clustering, difficulty proxy, and quality probe would improve reproducibility; currently the operations are described at a high level without explicit equations.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which highlight important areas for strengthening the evidence in our work. We address each major comment below and commit to revisions that will improve the manuscript.
read point-by-point responses
-
Referee: [Experimental evaluation] The experimental results (including the 3.00% accuracy gain and 20% step reduction on Qwen2.5-Math-1.5B) do not include ablations that apply the same data operations (clustering, curriculum ordering, filtering) but replace SAE-derived signals with random or non-SAE baselines. Without this, it is impossible to establish that the SAE internals are causally responsible for the gains rather than the operations themselves.
Authors: We agree that such ablations are necessary to isolate the contribution of the SAE-derived signals. The current evaluation demonstrates improvements over vanilla GRPO but does not control for the data operations themselves. In the revised manuscript, we will add experiments applying the same clustering, curriculum, and filtering operations but using random signals or non-SAE baselines (e.g., random feature assignments or external heuristic-based signals). This will allow us to quantify the specific benefit of using model internals via SAEs. revision: yes
-
Referee: [Method and framework description] The central modeling assumption—that SAE features reliably and causally capture diversity, difficulty, and quality in ways that drive downstream RL improvements—is load-bearing for the claim that model internals are a 'powerful and practical source of signals,' yet the paper provides no direct tests (e.g., intervention on SAE features or correlation vs. causation analysis) to support this over mere correlation with external metrics.
Authors: We acknowledge that the paper relies on the established properties of SAEs for feature extraction without providing new direct causal interventions in this work. The empirical results, including consistent gains across scales and transfer across model families, provide indirect support. However, to address this, we will include in the revision: (1) additional correlation analysis between SAE-derived difficulty/quality proxies and established external metrics, and (2) a more explicit discussion of the assumptions and limitations regarding causality. Direct interventions on SAE features during training would require significant additional compute and are beyond the current scope, but we will note this as a direction for future work. revision: partial
Circularity Check
No significant circularity; derivation self-contained against external benchmarks
full rationale
The paper defines SAERL operations (SAE-space clustering for diversity, difficulty proxy for curriculum, quality probe for filtering) from model internals and evaluates them via downstream RL accuracy gains (3.00% over GRPO, 20% fewer steps) on held-out benchmarks across scales and families. No equation or claim reduces a prediction to a fitted parameter by construction, nor does any load-bearing step rely on self-citation chains or self-definitional renaming; the central claims remain falsifiable against independent accuracy metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- SAE clustering and mixing hyperparameters
axioms (1)
- domain assumption Sparse autoencoders extract features that meaningfully represent data diversity, difficulty, and quality
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. DeepSeek-AI. 2026. Deepseek-v4: Towards highly efficient million-token context intelli- gence. https://huggingface.co/deepseek-ai/ DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf. Technical report. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, R...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
LightGBM: A highly efficient gradient boost- ing decision tree. InAdvances in Neural Information Processing Systems, volume 30, pages 3146–3154. Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V . Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Improving data efficiency for LLM rein- forcement fine-tuning through difficulty-targeted on- line data selection and rollout replay.Preprint, arXiv:2506.05316. Adly Templeton et al. 2024. Scaling monosemantic- ity: Extracting interpretable features from claude 3 sonnet. Transformer Circuits Thread. Georgios Tzannetos, Parameswaran Kamalaruban, and Adish ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.