Agents that Matter: Optimizing Multi-Agent LLMs via Removal-Based Attribution
Pith reviewed 2026-06-29 14:33 UTC · model grok-4.3
The pith
Substituting low-contribution agent models in multi-agent LLM systems improves performance up to 17% and cuts costs up to 35%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
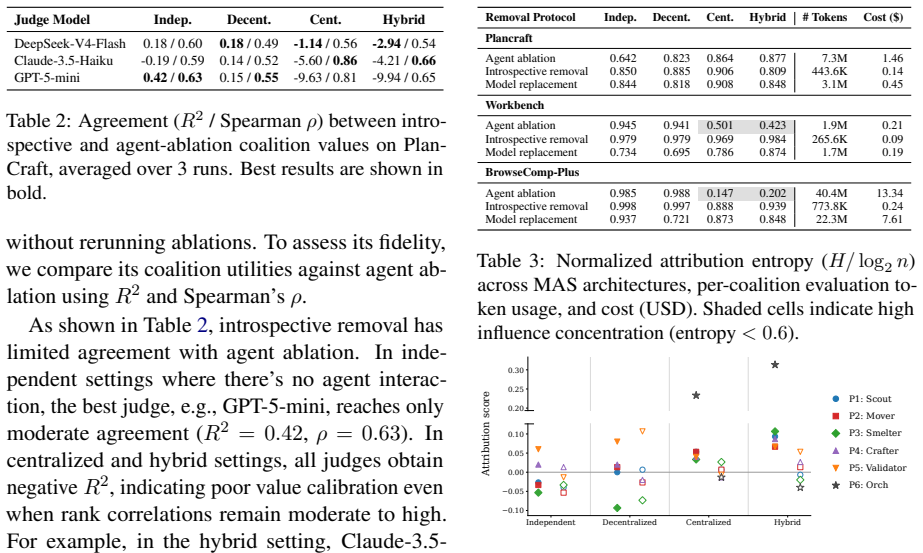
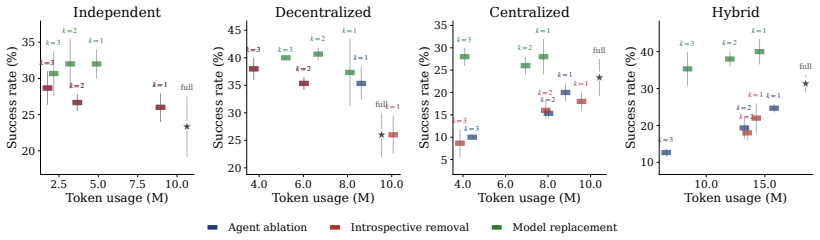
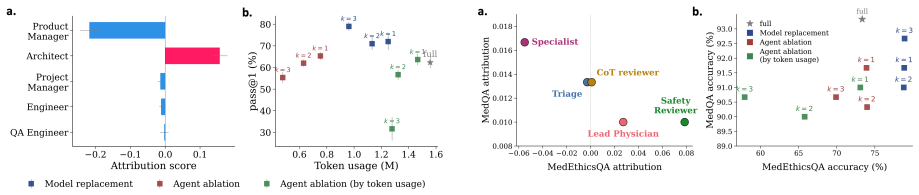
The authors show that removal-based attribution, formalized as a cooperative game, allows identification of agents whose underlying models can be substituted to improve overall system performance by up to 17% and reduce cost by up to 35% on three benchmarks, while also demonstrating that different removal protocols induce distinct attribution games and that in a medical MAS, agent contributions to accuracy and ethics can be decoupled.
What carries the argument
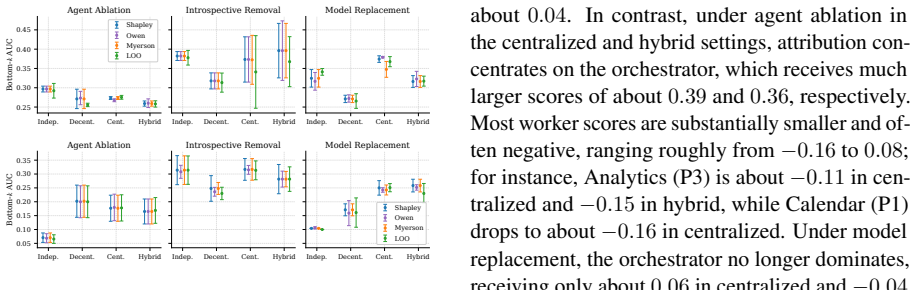
Removal-based attribution as a cooperative game, with Leave-One-Out (LOO) and combinatorial variants, and model replacement on low-attribution agents.
Load-bearing premise
The removal-based attribution scores identify agents for whom model replacement will actually deliver the performance and cost improvements.
What would settle it
Replacing the models of agents scored as low-contribution by the attribution method results in no improvement or even a decrease in task performance or an increase in cost on the benchmarks.
Figures



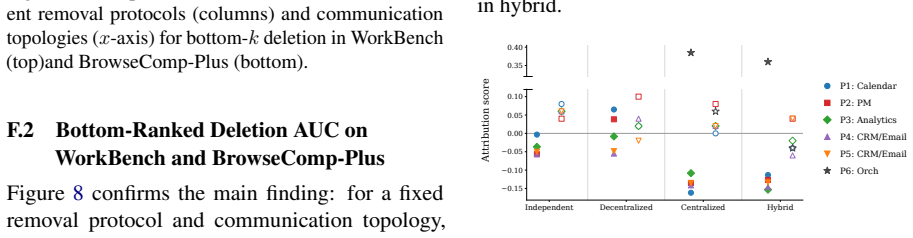
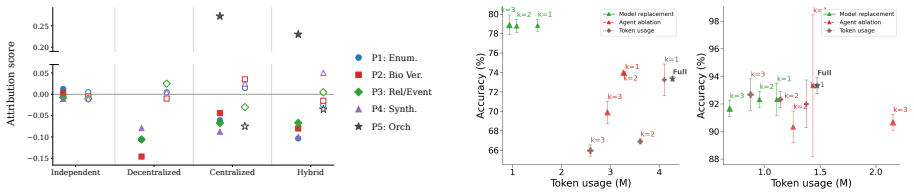

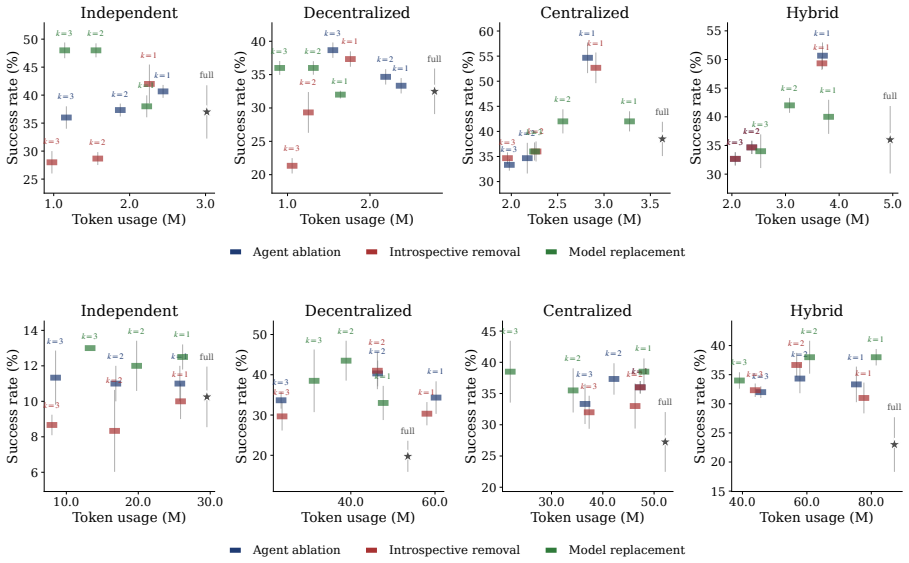
read the original abstract
As multi-agent systems (MAS) become increasingly complex, identifying the contributions of individual agents is critical for system optimization. However, existing approaches lack a rigorous, unified framework for credit assignment. In this work, we formalize agent attribution as a cooperative game, parameterized by the coalition distribution, removal protocol, and target metric. Using this framework, we show that Leave-One-Out (LOO) identifies bottleneck agents as effectively as combinatorial methods, but at a fraction of the computational cost. We also demonstrate that removal protocols induce distinct games: Agent ablation isolates structural bottlenecks, whereas introspective LLM judges fail to faithfully approximate this behavior. Furthermore, to evaluate the utility of specific agent backbones, we introduce attribution via model replacement. By substituting underlying models of low-contribution agents, we improve task performance by up to 17% while reducing cost by up to 35% across three benchmarks. Finally, we apply our framework to audit a medical MAS, revealing that agent contributions to diagnostic accuracy and ethical behavior are often decoupled. By intervening on counterproductive roles, we observe an increase in ethics alignment while maintaining diagnostic accuracy. Overall, this work provides a principled approach for cost-effective MAS attribution and intervention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes agent attribution in multi-agent LLM systems as a cooperative game parameterized by coalition distribution, removal protocol, and target metric. It shows that Leave-One-Out (LOO) attribution matches combinatorial methods in identifying bottleneck agents at lower cost, that ablation vs. introspective LLM-judge removal protocols induce distinct games, introduces model-replacement attribution to evaluate agent backbones, reports up to 17% task-performance gains and 35% cost reductions by substituting low-contribution agents across three benchmarks, and applies the framework to a medical MAS to reveal decoupled contributions to diagnostic accuracy and ethics, enabling interventions that improve ethical alignment without harming accuracy.
Significance. If the central empirical claims hold, the work would be significant for multi-agent systems research by supplying a unified game-theoretic credit-assignment framework that directly supports cost-effective optimization and auditing. The demonstration that LOO suffices for bottleneck detection and the practical medical-MAS case study illustrate utility beyond theory. The model-replacement intervention technique offers a concrete mechanism for translating attribution scores into system improvements.
major comments (3)
- [Abstract / experimental results] Abstract and experimental results sections: the headline claim that substituting low-contribution agents yields up to 17% performance and 35% cost gains is load-bearing for the utility of the attribution framework, yet no controls (replacement of high-attribution agents, random agents, or matched non-attribution baselines) are described. Without these, it remains possible that any model substitution, independent of the LOO/combinatorial scores, produces the deltas.
- [Framework definition / experimental protocol] Framework and methods sections: the three benchmarks, exact coalition distributions, removal protocols, target metrics, and statistical procedures (error bars, significance tests, number of runs) are not specified. These omissions prevent verification that the reported gains are attributable to the attribution method rather than to unspecified experimental choices.
- [Attribution via model replacement] Model-replacement attribution section: the claim that attribution scores correctly identify agents whose replacement improves performance rests on the untested assumption that low-attribution agents are the ones whose backbone change produces the observed deltas; a direct comparison of replacement effects conditioned on attribution rank is required to establish this.
minor comments (2)
- [Framework formalization] Notation for the cooperative-game parameters (coalition distribution, removal protocol) would benefit from a small concrete example immediately after the formal definition.
- [Medical MAS case study] The medical-MAS audit would be clearer if the specific agent roles, the ethics metric, and the intervention procedure were tabulated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The major comments identify gaps in experimental controls and protocol details that we will address through revisions to strengthen the manuscript. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract / experimental results] Abstract and experimental results sections: the headline claim that substituting low-contribution agents yields up to 17% performance and 35% cost gains is load-bearing for the utility of the attribution framework, yet no controls (replacement of high-attribution agents, random agents, or matched non-attribution baselines) are described. Without these, it remains possible that any model substitution, independent of the LOO/combinatorial scores, produces the deltas.
Authors: We agree that controls are required to establish that gains are attributable to the attribution method rather than generic substitution. In the revision we will add experiments replacing high-attribution agents, random agents, and matched non-attribution baselines, reporting performance and cost deltas for each condition across the benchmarks. revision: yes
-
Referee: [Framework definition / experimental protocol] Framework and methods sections: the three benchmarks, exact coalition distributions, removal protocols, target metrics, and statistical procedures (error bars, significance tests, number of runs) are not specified. These omissions prevent verification that the reported gains are attributable to the attribution method rather than to unspecified experimental choices.
Authors: We acknowledge these details were insufficiently specified. The revised manuscript will expand the methods section with a dedicated experimental protocol subsection that explicitly lists the three benchmarks, coalition distributions, removal protocols, target metrics, number of runs, error bar computation, and significance tests. revision: yes
-
Referee: [Attribution via model replacement] Model-replacement attribution section: the claim that attribution scores correctly identify agents whose replacement improves performance rests on the untested assumption that low-attribution agents are the ones whose backbone change produces the observed deltas; a direct comparison of replacement effects conditioned on attribution rank is required to establish this.
Authors: We agree that conditioning replacement effects on attribution rank is needed to validate the assumption. The revision will include a new analysis (table or plot) comparing performance and cost changes when replacing agents grouped by low, medium, and high attribution scores. revision: yes
Circularity Check
No significant circularity; empirical gains measured on external benchmarks
full rationale
The paper defines a cooperative-game attribution framework via coalition distribution, removal protocol, and target metric, then applies LOO/combinatorial variants and model-replacement intervention to three benchmarks. The reported 17%/35% deltas are observed task outcomes after substitution, not quantities forced by the definitions themselves or by any fitted parameter renamed as prediction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The derivation therefore remains self-contained against the external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Workbench: a benchmark dataset for agents in a realistic workplace setting.arXiv preprint arXiv:2405.00823. Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, and Mark Gerstein. 2024. Medagents: Large language models as collaborators for zero-shot medical rea- soning. InFindings of the Association for Computa- tion...
-
[2]
Medethicsqa: A comprehensive question an- swering benchmark for medical ethics evaluation of llms.arXiv preprint arXiv:2506.22808. Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, and 1 others. 2024. Au- togen: Enabling next-gen llm applications via multi- agent conversations. InFir...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.