Knowing When to Ask: Segment-Level Credit Assignment for LLM Tool Use
Pith reviewed 2026-06-29 13:47 UTC · model grok-4.3
The pith
CARL assigns credit to segments at tool-use boundaries so LLMs learn when their parametric knowledge suffices versus when to call tools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
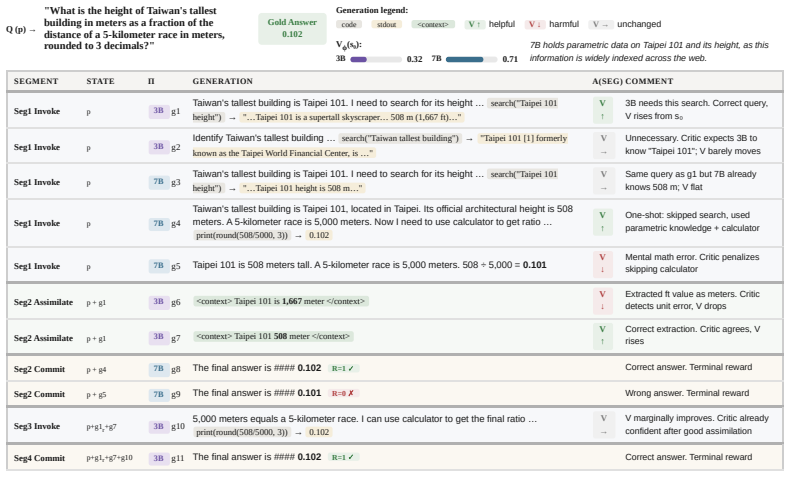
CARL decomposes each rollout at natural tool-use boundaries and trains a critic that assigns independent advantages to segments from a single binary outcome reward, allowing the policy to learn both when to invoke tools and when to rely on internal parameters without step-level supervision.
What carries the argument
A competence-aware critic that produces segment-level advantages by evaluating each delimited portion of a rollout against the final binary outcome.
If this is right
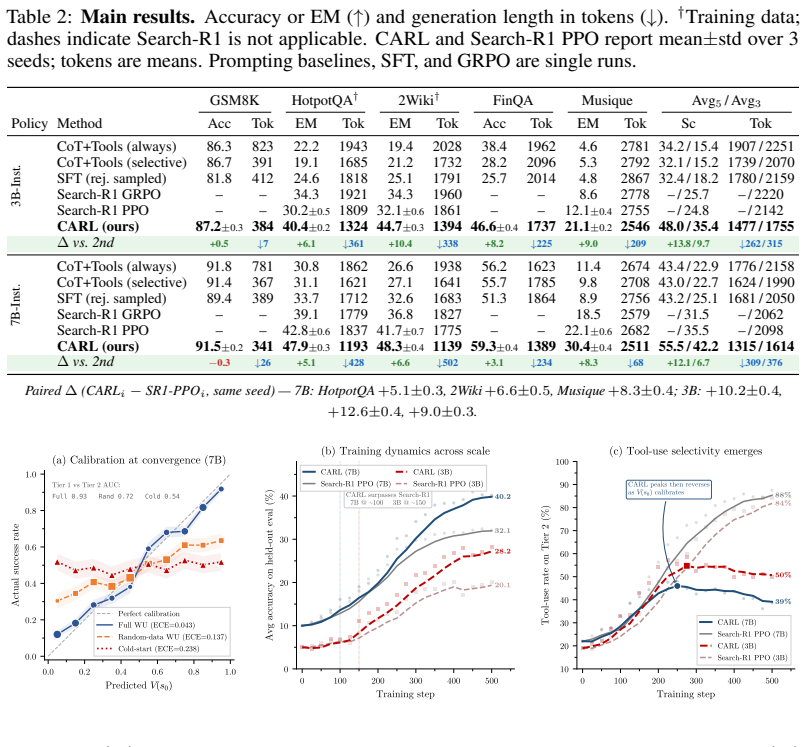
- The model issues 53 percent fewer tool calls on questions it can answer from parameters alone while remaining about 10 exact-match points more accurate.
- Exact-match gains reach +8.3 points at 7B and +9.0 points at 3B on the Musique multi-hop QA benchmark.
- The learned critic separates parametrically solvable from tool-dependent questions with AUC 0.93 at the 7B scale.
- Relative improvement is 1.4 times larger at 3B than at 7B, indicating the method compensates for smaller parametric capacity.
Where Pith is reading between the lines
- The same boundary-based decomposition could be tested on other structured generation tasks that contain clear delimiters, such as function calling or code generation.
- Reducing unnecessary tool invocations may lower inference latency and external API costs in deployed systems.
- The critic's competence signal might be reused at inference time as an explicit uncertainty estimate to decide tool use without further training.
Load-bearing premise
Splitting rollouts at natural tool-use boundaries supplies independent segments whose credit can be estimated from one overall success signal.
What would settle it
An ablation that replaces the natural tool-use boundaries with random cuts and obtains the same accuracy and tool-use reductions would falsify the necessity of those boundaries.
Figures


read the original abstract
Humans know when to reach for help e.g. $347 \times 28$ warrants a calculator while $2+2$ does not. Language models do not. Prompt-based approaches can instruct a model when to invoke tools, but this scaffolding does not teach it to recognize the boundary of its own knowledge. RL approaches that assign a single outcome reward to the whole trajectory fare no better: trajectory-level credit cannot isolate which tool call in a successful episode actually helped, nor penalize unnecessary calls. We propose \textbf{CARL} (\textbf{C}ompetence-\textbf{A}ware \textbf{R}einforcement \textbf{L}earning), which trains a critic on the model's own rollouts to learn where parametric knowledge suffices and where it needs external help. By decomposing each rollout at natural tool-use boundaries (e.g., code fence delimiters and context block transitions), CARL assigns independent credit to each segment from a single binary outcome, without external judges or step-level annotations. As a result, erroneous tool calls, incorrect extractions, and unnecessary calls each receive appropriately signed advantages. The trained critic captures the model's domain competence: it separates parametrically solvable from tool-dependent questions with AUC 0.93 at 7B. On five benchmarks spanning arithmetic, multi-hop factual QA, and numerical reasoning over financial tables, CARL improves exact-match accuracy by 6.7 points at 7B and 9.7 points at 3B over the best RL baseline, with the largest gain (+8.3 EM at 7B, +9.0 EM at 3B) on Musique. The model issues 53\% fewer tool calls on parametrically answerable questions while remaining ${\sim}10$ EM points more accurate on them. Gains are largest at small scale: the 3B improvement is $1.4\times$ the 7B improvement, suggesting that knowing when to ask disproportionately benefits models with smaller parametric memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CARL (Competence-Aware Reinforcement Learning), which trains a critic on an LLM's own rollouts to perform segment-level credit assignment for tool use. By decomposing trajectories at natural boundaries such as code fences and context transitions, the method assigns independent signed advantages to each segment from a single binary trajectory outcome, without step-level labels or external judges. This is claimed to penalize unnecessary or erroneous tool calls while rewarding necessary ones. Experiments across five benchmarks (arithmetic, multi-hop QA, financial tables) report exact-match gains of 6.7 points at 7B and 9.7 points at 3B over the best RL baseline, a 53% reduction in tool calls on parametrically solvable questions, and a critic AUC of 0.93 for distinguishing competence.
Significance. If the central claim holds, CARL offers a practical way to improve both accuracy and efficiency in tool-augmented LLMs by learning the boundary of parametric knowledge, with larger relative benefits at smaller scales. The use of the model's own rollouts for critic training and the reported scale-dependent gains are notable strengths. The approach could influence credit-assignment techniques in agentic RL more broadly if the segment independence assumption is validated.
major comments (2)
- [method / abstract] The core assumption that natural-boundary decomposition yields independent segment credits from one binary reward (abstract and method description) is load-bearing for both the accuracy gains and the 53% tool-call reduction. Sequential dependencies (e.g., an early erroneous call changing context for later segments) could entangle advantages; the manuscript should supply either a formal separability argument or controlled ablations demonstrating that the critic recovers per-segment competence without confounding from policy-induced segment distributions.
- [experiments / results] Table or results section reporting the 6.7 / 9.7 EM gains and 53% reduction: the abstract states concrete improvements over RL baselines but provides no error bars, data-split details, or ablation isolating the segment-level critic from standard RL components. This makes it impossible to confirm the gains are attributable to the proposed credit assignment rather than unstated implementation choices.
minor comments (1)
- [method] Notation for the critic (e.g., how segment advantages are computed from the binary outcome) should be made fully explicit with an equation, as the current description leaves the exact form of the advantage estimator ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential broader impact of segment-level credit assignment. We address each major comment below and outline revisions that will strengthen the manuscript.
read point-by-point responses
-
Referee: [method / abstract] The core assumption that natural-boundary decomposition yields independent segment credits from one binary reward (abstract and method description) is load-bearing for both the accuracy gains and the 53% tool-call reduction. Sequential dependencies (e.g., an early erroneous call changing context for later segments) could entangle advantages; the manuscript should supply either a formal separability argument or controlled ablations demonstrating that the critic recovers per-segment competence without confounding from policy-induced segment distributions.
Authors: We agree that the independence assumption is central and that sequential dependencies could in principle entangle advantages. The manuscript motivates natural boundaries (code fences, context transitions) precisely because they align with points where the policy's information state changes, but we lack a formal separability proof. In revision we will add (1) a short discussion of the assumption and its potential violations, and (2) a controlled ablation that fixes the policy and resamples segment distributions to isolate whether the critic recovers per-segment competence independent of policy-induced correlations. These additions will directly address the concern about confounding. revision: yes
-
Referee: [experiments / results] Table or results section reporting the 6.7 / 9.7 EM gains and 53% reduction: the abstract states concrete improvements over RL baselines but provides no error bars, data-split details, or ablation isolating the segment-level critic from standard RL components. This makes it impossible to confirm the gains are attributable to the proposed credit assignment rather than unstated implementation choices.
Authors: We acknowledge that the reported point estimates lack error bars, explicit split details, and a dedicated ablation isolating the critic. The current numbers come from single runs on fixed splits; we will revise the results section to report means and standard deviations over three random seeds, document the exact train/validation/test partitions, and add an ablation that compares CARL against a trajectory-level RL baseline sharing all other implementation choices (optimizer, reward scaling, rollout length) except the segment-level critic. This will make attribution clearer. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's derivation relies on standard RL credit assignment applied to segments defined at natural boundaries (code fences, context transitions) within the model's own generated rollouts, with a critic trained to produce per-segment advantages from a single binary trajectory reward. No equations or claims reduce a reported prediction or result to a fitted parameter by construction, nor does any load-bearing premise rest on a self-citation chain whose validity is internal to the present work. The empirical gains (EM improvements, tool-call reduction) are presented as outcomes of this procedure on external benchmarks rather than tautological re-expressions of inputs, making the chain self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural tool-use boundaries exist in rollouts and can be used to segment trajectories for credit assignment.
invented entities (1)
-
Competence-aware critic
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Arjona-Medina, J.A., et al. (2019). RUDDER: Return Decomposition for Delayed Rewards. NeurIPS
2019
- [2]
-
[3]
Taparia, A., et al. (2026). ARC: Learning to Configure Agentic AI Systems. arXiv:2602.11574
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [4]
- [5]
-
[6]
Jin, B., et al. (2025). Search-R1: Training LLMs to Reason and Leverage Search Engines with RL. COLM 2025
2025
- [7]
-
[8]
Ng, A.Y ., Harada, D., & Russell, S. (1999). Policy Invariance Under Reward Transformations. ICML
1999
-
[9]
Qian, C., et al. (2025). ToolRL: Reward is All Tool Learning Needs. NeurIPS 2025
2025
-
[10]
Schulman, J., Moritz, P., Levine, S., Jordan, M., & Abbeel, P. (2016). High-Dimensional Continuous Control Using Generalized Advantage Estimation. ICLR
2016
-
[11]
Schulman, J., et al. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Sutton, R.S., Precup, D., & Singh, S. (1999). Between MDPs and Semi-MDPs: A Framework for Temporal Abstraction in RL. Artificial Intelligence 112, 181-211
1999
-
[13]
Setlur, A., et al. (2025). Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning. ICLR 2025
2025
-
[14]
Guo, Y ., Xu, L., Liu, J., Ye, D., & Qiu, S. (2025). Segment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models. NeurIPS 2025
2025
- [15]
-
[16]
Cobbe, K., et al. (2021). Training Verifiers to Solve Math Word Problems. arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
Yang, Z., et al. (2018). HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. EMNLP
2018
-
[18]
Ho, X.N., Duong Nguyen, A.K., Sugawara, S., & Aizawa, A. (2020). Constructing A Multi-Hop QA Dataset for Comprehensive Evaluation of Reasoning Steps. COLING
2020
-
[19]
Chen, Z., et al. (2021). FinQA: A Dataset of Numerical Reasoning over Financial Data. EMNLP
2021
-
[20]
Trivedi, H., Balasubramanian, N., Khot, T., & Sabharwal, A. (2022). MuSiQue: Multihop Questions via Single Hop Question Composition. TACL
2022
-
[21]
Chen, J., et al. (2025). ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning. arXiv:2503.19470
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [22]
-
[23]
Zheng, R., Dou, S., Gao, S., Hua, Y ., Shen, W., et al. (2023). Secrets of RLHF in Large Language Models Part I: PPO. arXiv:2307.04964
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Hu, J., et al. (2024). OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework. arXiv:2405.11143. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Yu, Q., et al. (2025). DAPO: An Open-Source LLM Reinforcement Learning System. arXiv:2503.14476
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Yao, S., et al. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023
2023
-
[27]
Yu, Y ., et al. (2024). StepTool: A Step-Level Reinforcement Learning Method for Tool Learning. arXiv:2410.07745. 11 A SMDP Derivation Details From the SMDP Bellman equation.By Theorem 1 of Sutton et al. (12), our setting is an SMDP over segment-level decision points, with per-segment TD error δSMDP k =r k +γ τk V(s k+1)−V(s k),(4) where rk is the cumulat...
-
[28]
Tier 1 / Tier 2 labeling via multi-rollout consistency.A question is Tier 2 (within parametric competence) if the base model answers it correctly in at least one of five no-tool rollouts, and Tier 1 (beyond parametric competence) if all five rollouts produce incorrect answers. This labeling directly measures the model’s competence boundary: Tier 2 questio...
-
[29]
Controlled tool-use rollouts.Each question is also rolled out under two system prompts: (a) forced tool use, (b) no tools allowed. Combined with the Tier labels, this produces four outcome buckets per question, each teaching a different signal: Tier 2 no-tool (anchors V(s 0)≈1 ), Tier 2 forced-tool (teaches that unnecessary tools add risk), Tier 1 no-tool...
-
[30]
Mixed retrieval quality.Roughly 70% BM25 (matching PPO training) and 30% rollouts from a high-quality internal search API give Vϕ contrast between helpful and less-helpful tool outputs without changing the inference-time retriever
-
[31]
Topic diversity via embedding clustering.Questions are embedded with a sentence-transformer (all-MiniLM-L6-v2) and clustered with k-means; warm-up samples are drawn uniformly across clusters to preventV ϕ from learning surface topical cues
-
[32]
Verification gate.Before starting PPO, three checks must pass on a held-out subset
Multi-hop exposure.Multi-hop rollouts from 2WikiMQA and Musique are included so that Vϕ has seen compound-state boundaries before PPO. Verification gate.Before starting PPO, three checks must pass on a held-out subset. Minimum thresholds (gate):(i) V(s 0) separates Tier 1 from Tier 2 questions (AUC ≥0.70 ), (ii) Vϕ shows correct sign behavior after retrie...
-
[33]
Answer the following question directly. Do not use any tools or code. Provide your answer inside \boxed{}
No-tool direct answer:“Answer the following question directly. Do not use any tools or code. Provide your answer inside \boxed{}.”
-
[34]
Use search(query) for retrieval or write arithmetic code
Forced tool use:“You must use a Python code block to help answer this question. Use search(query) for retrieval or write arithmetic code. After seeing tool output, write a <context> block extracting the relevant information, then provide your answer inside \boxed{}.”
-
[35]
You may optionally use
Optional tool use (Tier 2):Same as forced tool use but with “You may optionally use” replacing “You must use.”
-
[36]
This question may require multiple search steps. You may call tools more than once
Multi-hop forced tool use:Same as (2) but with an additional instruction: “This question may require multiple search steps. You may call tools more than once.” Embedding clustering.Questions are embedded with all-MiniLM-L6-v2 (384-dimensional embeddings). We apply k-means with k= 50 clusters for HotpotQA and 2WikiMQA, k= 30 for GSM8K (smaller and more hom...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.