Semantic Flow Regularization: Teaching LLMs to Generate Diverse Yet Coherent Responses
Pith reviewed 2026-06-29 12:30 UTC · model grok-4.3
The pith
Semantic Flow Regularization counters cross-style collapse in conditioned LLMs by adding an auxiliary flow-matching loss on future sentence embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cross-style collapse arises because cross-entropy training under shared representations suppresses diverse continuations; Semantic Flow Regularization counters this by supervising the backbone with continuous sentence-encoder embeddings of future segments via conditional flow matching, whose stochastic source preserves multi-modality by construction.
What carries the argument
Conditional flow matching on sentence-encoder embeddings of future segments, used as an auxiliary objective discarded after training.
If this is right
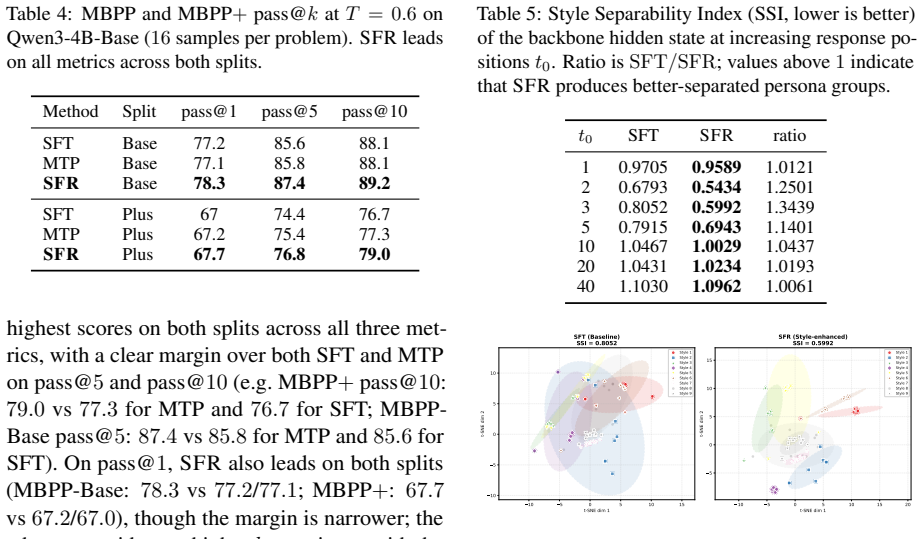
- On an industrial dialogue dataset with Qwen3-32B and nine personas, SFR raises output diversity, style fidelity, and response quality relative to ordinary supervised fine-tuning.
- On LiveCodeBench-v5 with Qwen2.5-Coder-7B-Instruct, SFR produces consistent gains in pass@k.
- A controlled comparison on MBPP shows that multi-token prediction is a degenerate special case of Semantic Flow Regularization.
Where Pith is reading between the lines
- The auxiliary flow head could be combined with other training signals that already use auxiliary heads, such as preference optimization, without changing inference latency.
- Varying the noise schedule inside the flow-matching objective might give practitioners a direct dial for trading diversity against coherence.
- Because the method operates on continuous embeddings rather than discrete tokens, it may extend to conditioning signals other than persona or tone, such as task difficulty or length constraints.
Load-bearing premise
Supervising the model with continuous future embeddings through conditional flow matching will keep multiple output modes open without creating new collapse modes or harming coherence on unseen styles.
What would settle it
Train with SFR on nine personas, then measure diversity and coherence metrics on a tenth held-out persona; if both metrics fall below the standard fine-tuning baseline the central claim is falsified.
Figures

read the original abstract
When large language models are fine-tuned to generate persona- or tone-conditioned responses, their output diversity is severely limited--a failure we term Cross-Style Collapse. We trace this collapse to the cross-entropy objective, which under shared representations tends to suppress diverse continuations. We propose Semantic Flow Regularization (SFR), a lightweight auxiliary objective that supervises the backbone with continuous sentence-encoder embeddings of future segments via conditional flow matching. The stochastic flow source preserves multi-modality by construction; the flow-matching head is discarded at inference, adding zero deployment cost. On a large-scale industrial dialogue dataset (Qwen3-32B, 9 personas), SFR improves output diversity, style fidelity, and response quality over SFT. We further validate on the public LiveCodeBench-v5 (Qwen2.5-Coder-7B-Instruct), where SFR consistently improves pass@k, confirming generality beyond stylized dialogue. A controlled comparison on MBPP reveals Multi-Token Prediction to be a degenerate special case of SFR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Semantic Flow Regularization (SFR), a lightweight auxiliary objective that uses conditional flow matching to supervise an LLM backbone with continuous sentence-encoder embeddings of future segments. The goal is to mitigate Cross-Style Collapse (reduced output diversity) that arises under standard cross-entropy fine-tuning for persona- or tone-conditioned generation. The flow-matching head is discarded at inference. On an industrial dialogue dataset with Qwen3-32B across 9 personas, SFR is reported to improve diversity, style fidelity, and response quality relative to SFT. The method is further evaluated on LiveCodeBench-v5 with Qwen2.5-Coder-7B-Instruct, where it improves pass@k, and a controlled comparison on MBPP is used to argue that Multi-Token Prediction is a degenerate special case of SFR.
Significance. If the reported gains prove robust and the auxiliary objective does not introduce new collapse modes, SFR would supply a zero-cost-at-inference mechanism for increasing diversity in conditioned generation while preserving coherence. The public-benchmark validation on code generation adds a measure of generality. No machine-checked proofs or parameter-free derivations are present; the contribution is empirical.
major comments (2)
- [Abstract] Abstract: the central claim that SFR improves diversity, fidelity, and quality over SFT on the 9-persona industrial dataset (and pass@k on LiveCodeBench) rests on the auxiliary objective preserving multi-modality without new collapse modes on held-out styles. No ablation, statistical test, or held-out-style isolation is described that would verify this assumption; aggregate improvements alone do not rule out dataset-specific artifacts.
- [Abstract] Abstract: the statement that conditional flow matching 'preserves multi-modality by construction' is presented without derivation or reference to an equation showing that the stochastic source remains independent of the main loss and does not induce coherence degradation on unseen personas.
minor comments (1)
- [Abstract] Abstract: the claim that MTP is a 'degenerate special case of SFR' would be clearer if the relevant section or equation establishing the reduction were cited.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address each major comment below and will revise the manuscript accordingly to provide stronger empirical support and clarification.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that SFR improves diversity, fidelity, and quality over SFT on the 9-persona industrial dataset (and pass@k on LiveCodeBench) rests on the auxiliary objective preserving multi-modality without new collapse modes on held-out styles. No ablation, statistical test, or held-out-style isolation is described that would verify this assumption; aggregate improvements alone do not rule out dataset-specific artifacts.
Authors: We agree that aggregate improvements across datasets do not fully isolate the effect on held-out styles. The current experiments compare SFR against SFT on the full 9-persona set and on code benchmarks, but lack explicit held-out persona isolation and statistical testing. In the revision we will add a held-out-style ablation (training on 8 personas, evaluating diversity on the ninth) together with paired statistical tests on the key metrics. revision: yes
-
Referee: [Abstract] Abstract: the statement that conditional flow matching 'preserves multi-modality by construction' is presented without derivation or reference to an equation showing that the stochastic source remains independent of the main loss and does not induce coherence degradation on unseen personas.
Authors: The claim rests on the fact that conditional flow matching supervises a continuous embedding trajectory whose noise source is sampled independently of the discrete cross-entropy loss. We acknowledge that the manuscript provides no explicit derivation or equation. We will insert a short derivation in Section 3 (with reference to the conditional flow-matching literature) showing independence of the stochastic source and will note that empirical results on the held-out personas already indicate no coherence degradation. revision: yes
Circularity Check
No circularity: auxiliary objective and empirical gains are independent of main loss
full rationale
The paper presents SFR as a separate auxiliary objective (conditional flow matching on sentence-encoder embeddings) whose head is discarded at inference. The central claims rest on experimental comparisons (industrial dialogue dataset with 9 personas, LiveCodeBench-v5, MBPP) showing gains over SFT, without any equations, fitted parameters, or self-citations that reduce the reported diversity/quality/pass@k improvements to quantities defined by the method itself. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh
One agent to serve all: a lite-adaptive styl- ized AI assistant for millions of multi-style official accounts.CoRR, abs/2509.17788. Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2022. GPTQ: accurate post-training quantization for generative pre-trained transformers. CoRR, abs/2210.17323. Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Ro...
-
[2]
Qwen2.5-Coder Technical Report
Efficient diffusion training via min-snr weight- ing strategy. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, Oc- tober 1-6, 2023, pages 7407–7417. IEEE. Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text degeneration. In8th International Conference on Learning Representa...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
The Chameleon's Limit: Investigating Persona Collapse and Homogenization in Large Language Models
OpenReview.net. Yixuan Su, Tian Lan, Yan Wang, Dani Yogatama, Ling- peng Kong, and Nigel Collier. 2022. A contrastive framework for neural text generation. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Sys- tems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022. Jack Urban...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Ruixiang Zhang, Richard He Bai, Huangjie Zheng, Navdeep Jaitly, Ronan Collobert, and Yizhe Zhang
Association for Computational Linguistics. Ruixiang Zhang, Richard He Bai, Huangjie Zheng, Navdeep Jaitly, Ronan Collobert, and Yizhe Zhang
-
[5]
Embarrassingly Simple Self-Distillation Improves Code Generation
Embarrassingly simple self-distillation im- proves code generation.CoRR, abs/2604.01193. Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. 2018. Per- sonalizing dialogue agents: I have a dog, do you have pets too? Shiyue Zhang, Shijie Wu, Ozan Irsoy, Steven Lu, Mo- hit Bansal, Mark Dredze, and David S. Rosenberg
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Mixce: Training autoregressive language mod- els by mixing forward and reverse cross-entropies. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 9027–9050. Association for Com- putational Linguistics. Lianmin Zheng, Liangsheng Yin, Zhiqiang ...
-
[7]
taking the state space to be∆ K
-
[8]
, e(yt+K)]∈∆ K
taking the per-position target to be the one-hot stackz (t) 1 = [e(yt+1), . . . , e(yt+K)]∈∆ K
-
[9]
taking the source to be the constant p0 = δ[π,...,π]
-
[10]
using the straight-line path z(t) τ,k = (1−τ)π+ τ e(yt+k)
-
[11]
Lemma A.5(Velocity-matching ≡ endpoint– matching).Under Definition A.4, the tangent space of the simplex ∆ is T∆ ={u∈R |V| |P i ui = 0}
restricting the head to a constant-velocity field vϕ,k(zτ , τ;h t) :=q ϕ,k(· |h t)−π that is in- dependent of (zτ , τ), where qϕ,k(· |h t) = softmax(Wkht +b k)∈∆. Lemma A.5(Velocity-matching ≡ endpoint– matching).Under Definition A.4, the tangent space of the simplex ∆ is T∆ ={u∈R |V| |P i ui = 0}. For any divergence D on T∆ induced by a divergence D∆ on ...
2007
-
[12]
FSFR with z0 ∼ N(0, I) preserves all modes (Proposition A.2)
Source randomness: F∆-FM fixes p0 = δ[π,...,π], so its velocity field is deterministic given ht; it models token-level uncertainty in the discrete simplex but lacks stochastic con- tinuous source modeling and segment-level semantic targets. FSFR with z0 ∼ N(0, I) preserves all modes (Proposition A.2)
-
[13]
The contin- uous target z1 ∈R dz of FSFR has no such restriction
Target dimensionality: ∆K is a K(|V|−1) - dimensional bounded polytope that encodes only the identity of the next K tokens; it can- not represent continuous semantic attributes (style intensity, syntactic structure, or dis- course coherence) that live in directions or- thogonal to the one-hot vertices. The contin- uous target z1 ∈R dz of FSFR has no such ...
2023
-
[14]
Retain only samples marked bothverified and is_passed
-
[15]
Remove samples whose chain-of-thought ex- ceeds16k tokens
-
[16]
After filtering, approximately 380k training exam- ples remain
Deduplicate problems by adjacent-hash match- ing on the problem statement. After filtering, approximately 380k training exam- ples remain. B.3 MBPP (Experiment 3) We use the open-source OpenCodeInstruct dataset (Ahmad et al., 2025) (solutions without a reasoning trace). The filtering criteria are:
2025
-
[17]
LLM-judged requirement_conformance= 5 andlogical_correctness= 5
-
[18]
LLM-judgededge_case_consideration≥4
-
[19]
All unit tests pass (tests_execution_status)
-
[20]
Exact-match deduplication on the problem in- put (retaining the highest-scoring, most concise solution per problem). After filtering, approximately 500k training exam- ples remain. C Implementation notes C.1 Why we avoid runtimerequires_grad toggling Under DeepSpeed ZeRO-3 (Rajbhandari et al., 2020), the optimizer’s parameter groups are bound once at acce...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.