Every9D-21M: Large-Scale Real-World 9D Canonicalization of Everyday Objects
Pith reviewed 2026-06-29 13:45 UTC · model grok-4.3
The pith
Every9D-21M supplies 21.8 million real-world images with 9D pose annotations across 700 everyday object categories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
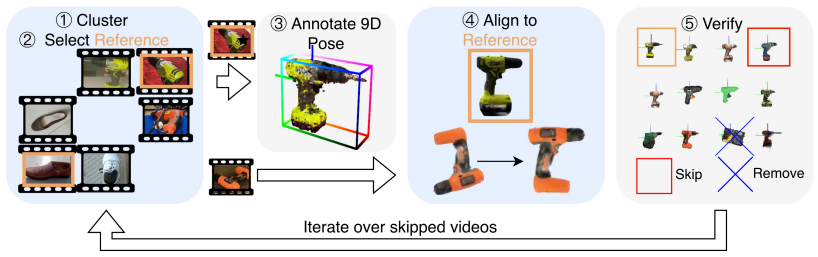
By reconstructing object-level point clouds from multi-view geometry on object-centric videos, aligning similar instances into a shared canonical frame, manually annotating reference objects for fewer than 0.01 percent of images, propagating the remaining canonical poses via cross-instance alignment, and verifying all propagated poses from multiple viewpoints, the work produces 21.8M real-world 9D annotations across 700 categories—two orders of magnitude larger than previous real-world benchmarks—while also introducing cross-category orientation rules that induce category-level symmetries for evaluation.
What carries the argument
Cross-instance alignment of reconstructed point clouds from multiview videos, combined with manual reference annotation on a tiny fraction of images and subsequent multiview verification, to propagate canonical 9D poses at scale.
If this is right
- Training on Every9D-21M improves performance on the ImageNet3D and PASCAL3D+ benchmarks.
- Models trained on Every9D-21M generalize substantially better to the HANDAL dataset than models trained on ImageNet3D.
- The dataset supplies dedicated training and evaluation splits for developing 9D pose foundation models.
- Cross-category orientation rules enable symmetry-aware evaluation protocols.
Where Pith is reading between the lines
- The scale of real data may reduce the need to rely primarily on synthetic renderings for 9D pose training.
- The alignment-and-propagation pipeline could be applied to additional video sources to grow the set of categories further.
- Improved canonical 9D supervision may benefit downstream tasks such as robotic grasping or scene reconstruction that require consistent object coordinate frames.
Load-bearing premise
Cross-instance point-cloud alignment plus multiview verification produces canonical poses whose residual error remains small enough for downstream training and evaluation to stay valid.
What would settle it
Manual inspection of a random sample of several hundred propagated poses reveals systematic alignment errors above a few degrees or centimeters, or models trained on Every9D-21M show no improvement over smaller real-world datasets on independent held-out 9D pose benchmarks.
Figures



read the original abstract
Estimating the 9D pose of everyday objects from a single real-world image remains challenging. This is largely due to the lack of large-scale supervision. Most existing datasets either rely heavily on synthetic renderings or provide limited coverage of real-world objects: the largest real-world 9D pose dataset to date contains only 17K annotated objects across 9 categories. We address this gap with Every9D-21M, a dataset of 9D pose annotations for 21.8M real-world images from 109K object- centric videos spanning 700 everyday object categories - two orders of magnitude larger than prior real-world 9D pose benchmarks in both image and category count. To achieve this scale, we leverage object-centric videos by reconstructing object- level point clouds via multi-view geometry and aligning similar instances into a shared canonical coordinate frame. Canonical poses are manually annotated for only a small set of reference objects (fewer than 0.01% of all images) and propagated to the remaining instances via cross-instance alignment. All propagated canonical poses are then verified from multiple viewpoints. We further introduce cross-category orientation rules that induce category-level symmetries, enabling symmetry-aware evaluation. Beyond establishing dedicated training and evaluation splits as a benchmark for 9D pose foundation models, we show that training on Every9D-21M improves performance on ImageNet3D and PASCAL3D+, and generalizes to HANDAL substantially better than training on ImageNet3D. Data and code are available at https://github.com/GenIntel/Every9D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Every9D-21M, a dataset comprising 21.8M real-world images with 9D pose annotations across 700 everyday object categories, constructed from 109K object-centric videos. The pipeline reconstructs object-level point clouds via multi-view geometry, manually annotates canonical poses for a tiny reference set (<0.01% of images), propagates them through cross-instance alignment of similar instances into a shared frame, and verifies all propagated poses from multiple viewpoints. Cross-category orientation rules are introduced to handle symmetries. The authors provide training/evaluation splits and report that models trained on Every9D-21M improve on ImageNet3D and PASCAL3D+ while generalizing better to HANDAL than models trained on ImageNet3D alone. Data and code are released.
Significance. If the 9D annotations prove sufficiently accurate, Every9D-21M would constitute a substantial advance: two orders of magnitude larger than prior real-world 9D benchmarks in both images and categories, enabling training of 9D pose foundation models on genuine real-world data rather than synthetic renderings. The demonstrated transfer gains and the public release of data/code are concrete strengths.
major comments (2)
- [§4] §4 (Dataset Construction), paragraph on cross-instance alignment and multiview verification: the manuscript states that alignment error is controlled via point-cloud propagation and multiview checks but supplies no quantitative statistics (rotation/translation error distributions, failure rates, or inter-annotator agreement on a held-out sample). This directly affects the validity of the headline claim of 21.8M usable 9D annotations.
- [§5] §5 (Experiments), results on ImageNet3D and HANDAL: the reported performance gains are presented without explicit controls or ablation for category overlap between Every9D-21M training data and the target evaluation sets; without such controls it is unclear whether the improvements reflect genuine generalization or partial data leakage.
minor comments (1)
- [Figure 3] Figure 3 caption and §3.2: the description of the symmetry-aware evaluation protocol would benefit from an explicit statement of how the induced category-level symmetries interact with the 9D pose metric.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of Every9D-21M's scale and the constructive feedback. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Dataset Construction), paragraph on cross-instance alignment and multiview verification: the manuscript states that alignment error is controlled via point-cloud propagation and multiview checks but supplies no quantitative statistics (rotation/translation error distributions, failure rates, or inter-annotator agreement on a held-out sample). This directly affects the validity of the headline claim of 21.8M usable 9D annotations.
Authors: We agree that providing quantitative validation metrics is important for establishing the reliability of the 21.8M annotations. In the revised manuscript, we will add a new subsection or appendix detailing error distributions (mean and std of rotation and translation errors) on a held-out sample of 1,000 instances where we performed additional manual verification. We will also report the failure rate of the multiview verification step (instances discarded due to inconsistency) and inter-annotator agreement (e.g., average angular difference) for the manual canonical pose annotations on a subset of 200 objects. revision: yes
-
Referee: [§5] §5 (Experiments), results on ImageNet3D and HANDAL: the reported performance gains are presented without explicit controls or ablation for category overlap between Every9D-21M training data and the target evaluation sets; without such controls it is unclear whether the improvements reflect genuine generalization or partial data leakage.
Authors: We appreciate this point on potential data leakage. Upon inspection, Every9D-21M covers 700 categories while ImageNet3D and PASCAL3D+ have fewer, and HANDAL focuses on hand-held objects. To rigorously address this, we will include in the revision: (1) a table listing overlapping categories, (2) an ablation where we retrain excluding all overlapping categories from Every9D-21M, and (3) confirm that performance gains on non-overlapping subsets remain significant. This will demonstrate that improvements are due to better generalization from large-scale real data rather than leakage. revision: yes
Circularity Check
No circularity: dataset construction pipeline is self-contained with external validation
full rationale
The paper describes an empirical pipeline for dataset creation (multi-view point cloud reconstruction, cross-instance alignment, manual annotation on <0.01% reference objects, propagation, and multi-view verification) without any equations, fitted parameters renamed as predictions, or load-bearing self-citations. Claims of annotation validity rest on the described process and are supported by reported improvements on independent external benchmarks (ImageNet3D, PASCAL3D+, HANDAL). No step reduces a reported result to an input by construction; the contribution is scale of real-world data rather than a closed derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multi-view geometry from object-centric videos yields sufficiently accurate object-level point clouds for subsequent alignment
- domain assumption Cross-instance alignment of similar objects into a shared canonical frame transfers pose labels without introducing systematic bias
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ahmadyan, A., Zhang, L., Ablavatski, A., Wei, J., Grundmann, M.: Objectron: A large scale dataset of object-centric videos in the wild with pose annotations. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7822–7831 (2021)
2021
-
[2]
In: Proceedings of the IEEE/CVF international conference on computer vision
Chen, K., Dou, Q.: Sgpa: Structure-guided prior adaptation for category-level 6d object pose estimation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2773–2782 (2021)
2021
-
[3]
In: European conference on computer vision
Cheng, H.K., Schwing, A.G.: Xmem: Long-term video object segmentation with an atkinson- shiffrin memory model. In: European conference on computer vision. pp. 640–658. Springer (2022)
2022
-
[4]
In: Thirteenth International Conference on 3D Vision (2026)
Chi, Y ., Sommer, L., Dünkel, O., Muhle, D., Cremers, D., Theobalt, C., Kortylewski, A.: C3PO: Canonicalization of 3d pose from partial views with generalizable correspondence features. In: Thirteenth International Conference on 3D Vision (2026)
2026
-
[5]
In: European conference on computer vision
Choy, C.B., Xu, D., Gwak, J., Chen, K., Savarese, S.: 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction. In: European conference on computer vision. pp. 628–644. Springer (2016)
2016
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Collins, J., Goel, S., Deng, K., Luthra, A., Xu, L., Gundogdu, E., Zhang, X., Vicente, T.F.Y ., Dideriksen, T., Arora, H., et al.: Abo: Dataset and benchmarks for real-world 3d object understanding. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21126–21136 (2022)
2022
-
[7]
Advances in Neural Information Processing Systems36, 35799–35813 (2023)
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., V oleti, V ., Gadre, S.Y ., et al.: Objaverse-xl: A universe of 10m+ 3d objects. Advances in Neural Information Processing Systems36, 35799–35813 (2023)
2023
-
[8]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13142–13153 (2023)
2023
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Deng, Y ., Yang, J., Tong, X.: Deformed implicit field: Modeling 3d shapes with learned dense correspondence. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10286–10296 (2021) 10
2021
-
[10]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Dünkel, O., Wimmer, T., Theobalt, C., Rupprecht, C., Kortylewski, A.: Do it yourself: Learning semantic correspondence from pseudo-labels. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 5834–5844 (2025)
2025
-
[11]
ACM Transactions On Graph- ics (TOG)13(1), 43–72 (1994)
Edelsbrunner, H., Mücke, E.P.: Three-dimensional alpha shapes. ACM Transactions On Graph- ics (TOG)13(1), 43–72 (1994)
1994
-
[12]
International Journal of Computer Vision129(12), 3313–3337 (2021)
Fu, H., Jia, R., Gao, L., Gong, M., Zhao, B., Maybank, S., Tao, D.: 3d-future: 3d furniture shape with texture. International Journal of Computer Vision129(12), 3313–3337 (2021)
2021
-
[13]
Advances in Neural Information Processing Systems35, 27469–27483 (2022)
Fu, Y ., Wang, X.: Category-level 6d object pose estimation in the wild: A semi-supervised learning approach and a new dataset. Advances in Neural Information Processing Systems35, 27469–27483 (2022)
2022
-
[14]
In: European Conference on Computer Vision
Goodwin, W., Vaze, S., Havoutis, I., Posner, I.: Zero-shot category-level object pose estimation. In: European Conference on Computer Vision. pp. 516–532. Springer (2022)
2022
-
[15]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Graham, B., Engelcke, M., Van Der Maaten, L.: 3d semantic segmentation with submanifold sparse convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 9224–9232 (2018)
2018
-
[16]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Groueix, T., Fisher, M., Kim, V .G., Russell, B.C., Aubry, M.: A papier-mâché approach to learning 3d surface generation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 216–224 (2018)
2018
-
[17]
In: 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Guo, A., Wen, B., Yuan, J., Tremblay, J., Tyree, S., Smith, J., Birchfield, S.: Handal: A dataset of real-world manipulable object categories with pose annotations, affordances, and reconstructions. In: 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 11428–11435. IEEE (2023)
2023
-
[18]
WildDet3D: Scaling Promptable 3D Detection in the Wild
Huang, W., Zhang, J., Li, S., Jia, T., Duan, J., Cheng, Y ., Cho, J., Wallingford, M., Soraki, R., Kim, C.D., et al.: Wilddet3d: Scaling promptable 3d detection in the wild. arXiv preprint arXiv:2604.08626 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
In: European Conference on Computer Vision
Jesslen, A., Zhang, G., Wang, A., Ma, W., Yuille, A., Kortylewski, A.: Novum: Neural object volumes for robust object classification. In: European Conference on Computer Vision. pp. 264–281. Springer (2024)
2024
-
[20]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Jin, L., Wang, Y ., Chen, W., Dai, Q., Gao, Q., Qin, X., Chen, B.: One-shot 3d object canonical- ization based on geometric and semantic consistency. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16850–16859 (2025)
2025
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jung, H., Wu, S.C., Ruhkamp, P., Zhai, G., Schieber, H., Rizzoli, G., Wang, P., Zhao, H., Garattoni, L., Meier, S., et al.: Housecat6d-a large-scale multi-modal category level 6d ob- ject perception dataset with household objects in realistic scenarios. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22498–22508 (2024)
2024
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Khanna, M., Mao, Y ., Jiang, H., Haresh, S., Shacklett, B., Batra, D., Clegg, A., Undersander, E., Chang, A.X., Savva, M.: Habitat synthetic scenes dataset (hssd-200): An analysis of 3d scene scale and realism tradeoffs for objectgoal navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16384–16393 (2024)
2024
-
[23]
In: Proceedings of the IEEE/CVF international conference on computer vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y ., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4015–4026 (2023)
2023
-
[24]
Advances in neural information processing systems34, 15370–15381 (2021)
Li, X., Weng, Y ., Yi, L., Guibas, L.J., Abbott, A., Song, S., Wang, H.: Leveraging se (3) equiv- ariance for self-supervised category-level object pose estimation from point clouds. Advances in neural information processing systems34, 15370–15381 (2021)
2021
-
[25]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y ., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025) 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
In: 2022 International Conference on Robotics and Automation (ICRA)
Lin, Y ., Tremblay, J., Tyree, S., Vela, P.A., Birchfield, S.: Single-stage keypoint-based category- level object pose estimation from an rgb image. In: 2022 International Conference on Robotics and Automation (ICRA). pp. 1547–1553. IEEE (2022)
2022
-
[27]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, J., Chen, Y ., Ye, X., Qi, X.: Ist-net: Prior-free category-level pose estimation with implicit space transformation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13978–13988 (2023)
2023
-
[28]
Advances in neural information processing systems36, 44860–44879 (2023)
Liu, M., Shi, R., Kuang, K., Zhu, Y ., Li, X., Han, S., Cai, H., Porikli, F., Su, H.: Openshape: Scaling up 3d shape representation towards open-world understanding. Advances in neural information processing systems36, 44860–44879 (2023)
2023
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Q., Zhang, Y ., Bai, S., Kortylewski, A., Yuille, A.: Direct-3d: Learning direct text-to-3d generation on massive noisy 3d data. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6881–6891 (2024)
2024
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, X., Tayal, P., Wang, J., Zarzar, J., Monnier, T., Tertikas, K., Duan, J., Toisoul, A., Zhang, J.Y ., Neverova, N., et al.: Uncommon objects in 3d. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14102–14113 (2025)
2025
-
[31]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Orientation matters: Making 3d generative models orientation-aligned,
Lu, Y ., Tian, Y ., Jiang, Z., Zhao, Y ., Yang, Y ., Ouyang, H., Hu, H., Yu, H., Shen, Y ., Liao, Y .: Orientation matters: Making 3d generative models orientation-aligned. arXiv preprint arXiv:2506.08640 (2025)
-
[33]
Advances in Neural Information Processing Systems37, 96127–96149 (2024)
Ma, W., Zhang, G., Liu, Q., Zeng, G., Kortylewski, A., Liu, Y ., Yuille, A.: Imagenet3d: Towards general-purpose object-level 3d understanding. Advances in Neural Information Processing Systems37, 96127–96149 (2024)
2024
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Mariotti, O., Mac Aodha, O., Bilen, H.: Improving semantic correspondence with viewpoint- guided spherical maps. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19521–19530 (2024)
2024
-
[35]
https://github.com/luca-medeiros/ lang-segment-anything(2023), gitHub repository
Medeiros, L.: lang-segment-anything. https://github.com/luca-medeiros/ lang-segment-anything(2023), gitHub repository
2023
-
[36]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., V o, H., Szafraniec, M., Khalidov, V ., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Park, J.J., Florence, P., Straub, J., Newcombe, R., Lovegrove, S.: Deepsdf: Learning continuous signed distance functions for shape representation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 165–174 (2019)
2019
-
[38]
Neural Networks108, 533–543 (2018)
Phan, A.V ., Le Nguyen, M., Nguyen, Y .L.H., Bui, L.T.: Dgcnn: A convolutional neural network over large-scale labeled graphs. Neural Networks108, 533–543 (2018)
2018
-
[39]
Advances in neural information processing systems30(2017)
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in neural information processing systems30(2017)
2017
-
[40]
In: Proceedings of the IEEE/CVF international conference on computer vision
Reizenstein, J., Shapovalov, R., Henzler, P., Sbordone, L., Labatut, P., Novotny, D.: Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 10901–10911 (2021)
2021
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sajnani, R., Poulenard, A., Jain, J., Dua, R., Guibas, L.J., Sridhar, S.: Condor: Self-supervised canonicalization of 3d pose for partial shapes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16969–16979 (2022)
2022
-
[42]
Siméoni, O., V o, H.V ., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V ., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025) 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Sommer, L., Dünkel, O., Theobalt, C., Kortylewski, A.: Common3d: Self-supervised learning of 3d morphable models for common objects in neural feature space. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6468–6479 (2025)
2025
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sommer, L., Jesslen, A., Ilg, E., Kortylewski, A.: Unsupervised learning of category-level 3d pose from object-centric videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22787–22796 (2024)
2024
-
[45]
In: Bmvc
Stark, M., Goesele, M., Schiele, B.: Back to the future: Learning shape models from 3d cad data. In: Bmvc. vol. 2, p. 5 (2010)
2010
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sun, S., Han, K., Kong, D., Tang, H., Yan, X., Xie, X.: Topology-preserving shape recon- struction and registration via neural diffeomorphic flow. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20845–20855 (2022)
2022
-
[47]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, C., Xu, D., Zhu, Y ., Martín-Martín, R., Lu, C., Fei-Fei, L., Savarese, S.: Densefusion: 6d object pose estimation by iterative dense fusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3343–3352 (2019)
2019
-
[48]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, H., Sridhar, S., Huang, J., Valentin, J., Song, S., Guibas, L.J.: Normalized object coordinate space for category-level 6d object pose and size estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2642–2651 (2019)
2019
-
[49]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, J., Karaev, N., Rupprecht, C., Novotny, D.: Vggsfm: Visual geometry grounded deep structure from motion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21686–21697 (2024)
2024
-
[50]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, P., Jung, H., Li, Y ., Shen, S., Srikanth, R.P., Garattoni, L., Meier, S., Navab, N., Busam, B.: Phocal: A multi-modal dataset for category-level object pose estimation with photometrically challenging objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21222–21231 (2022)
2022
-
[51]
Orient anything: Learning robust object orientation estimation from rendering 3d models,
Wang, Z., Zhang, Z., Pang, T., Du, C., Zhao, H., Zhao, Z.: Orient anything: Learning robust object orientation estimation from rendering 3d models. arXiv preprint arXiv:2412.18605 (2024)
-
[52]
Orient anything v2: Unifying orientation and rotation understanding,
Wang, Z., Zhang, Z., Xu, J., Wang, J., Pang, T., Du, C., Zhao, H., Zhao, Z.: Orient anything v2: Unifying orientation and rotation understanding. arXiv preprint arXiv:2601.05573 (2026)
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, S., Li, R., Jakab, T., Rupprecht, C., Vedaldi, A.: Magicpony: Learning articulated 3d animals in the wild. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8792–8802 (2023)
2023
-
[54]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wu, X., Jiang, L., Wang, P.S., Liu, Z., Liu, X., Qiao, Y ., Ouyang, W., He, T., Zhao, H.: Point transformer v3: Simpler faster stronger. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4840–4851 (2024)
2024
-
[55]
In: European conference on computer vision
Xiang, Y ., Kim, W., Chen, W., Ji, J., Choy, C., Su, H., Mottaghi, R., Guibas, L., Savarese, S.: Objectnet3d: A large scale database for 3d object recognition. In: European conference on computer vision. pp. 160–176. Springer (2016)
2016
-
[56]
In: IEEE winter conference on applications of computer vision
Xiang, Y ., Mottaghi, R., Savarese, S.: Beyond pascal: A benchmark for 3d object detection in the wild. In: IEEE winter conference on applications of computer vision. pp. 75–82. IEEE (2014)
2014
-
[57]
In: 2021 International Conference on 3D Vision (3DV)
Xiao, Y ., Du, Y ., Marlet, R.: Posecontrast: Class-agnostic object viewpoint estimation in the wild with pose-aware contrastive learning. In: 2021 International Conference on 3D Vision (3DV). pp. 74–84. IEEE (2021)
2021
-
[58]
Advances in Neural Information Processing Systems37, 21875–21911 (2024)
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. Advances in Neural Information Processing Systems37, 21875–21911 (2024)
2024
-
[59]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yu, X., Rao, Y ., Wang, Z., Liu, Z., Lu, J., Zhou, J.: Pointr: Diverse point cloud completion with geometry-aware transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 12498–12507 (2021) 13
2021
-
[60]
arXiv preprint arXiv:2512.13689 (2025)
Yue, Y ., Robert, D., Wang, J., Hong, S., Wegner, J.D., Rupprecht, C., Schindler, K.: Litept: Lighter yet stronger point transformer. arXiv preprint arXiv:2512.13689 (2025)
-
[61]
arXiv preprint arXiv:2510.11687 (2025)
Zhang, J., Lin, H., Hou, J., Xue, X., Fu, Y .: Beyond’templates’: Category-agnostic object pose, size, and shape estimation from a single view. arXiv preprint arXiv:2510.11687 (2025)
-
[62]
In: European Conference on Computer Vision
Zhang, J., Huang, W., Peng, B., Wu, M., Hu, F., Chen, Z., Zhao, B., Dong, H.: Omni6dpose: A benchmark and model for universal 6d object pose estimation and tracking. In: European Conference on Computer Vision. pp. 199–216. Springer (2024)
2024
-
[63]
ACM Transactions on Graphics (TOG)43(4), 1–20 (2024)
Zhang, L., Wang, Z., Zhang, Q., Qiu, Q., Pang, A., Jiang, H., Yang, W., Xu, L., Yu, J.: Clay: A controllable large-scale generative model for creating high-quality 3d assets. ACM Transactions on Graphics (TOG)43(4), 1–20 (2024)
2024
-
[64]
Zhang, Y ., Zhang, L., Ma, R., Cao, N.: Texverse: A universe of 3d objects with high-resolution textures. arXiv preprint arXiv:2508.10868 (2025)
-
[65]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zheng, L., Wang, C., Sun, Y ., Dasgupta, E., Chen, H., Leonardis, A., Zhang, W., Chang, H.J.: Hs-pose: Hybrid scope feature extraction for category-level object pose estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17163–17173 (2023)
2023
-
[66]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zheng, Z., Yu, T., Dai, Q., Liu, Y .: Deep implicit templates for 3d shape representation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1429–1439 (2021)
2021
-
[67]
In: Proceedings of the European Conference on Computer Vision (ECCV)
Zhou, X., Karpur, A., Luo, L., Huang, Q.: Starmap for category-agnostic keypoint and viewpoint estimation. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 318– 334 (2018)
2018
-
[68]
move backward
Zhou, Y ., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation representations in neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5745–5753 (2019) 14 Supplementary Material Every9D-21M: Large-Scale Canonicalized Real-World 9D Pose Estimation This supplementary material provides ad...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.