Multi-Agent LLM-based Metamorphic Testing for REST APIs
Pith reviewed 2026-06-29 10:50 UTC · model grok-4.3
The pith
ARMeta uses a multi-agent LLM workflow to generate metamorphic tests that complement scenario-based testing for REST APIs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
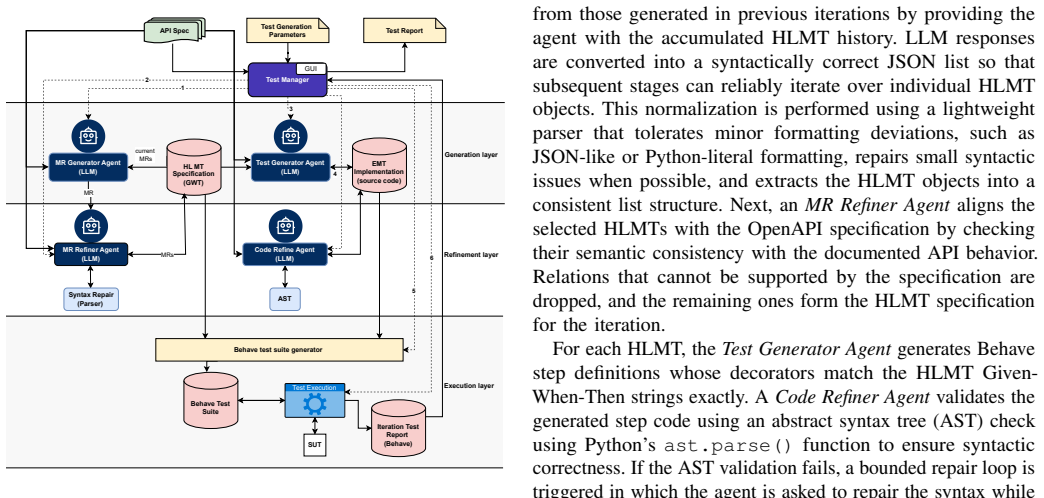
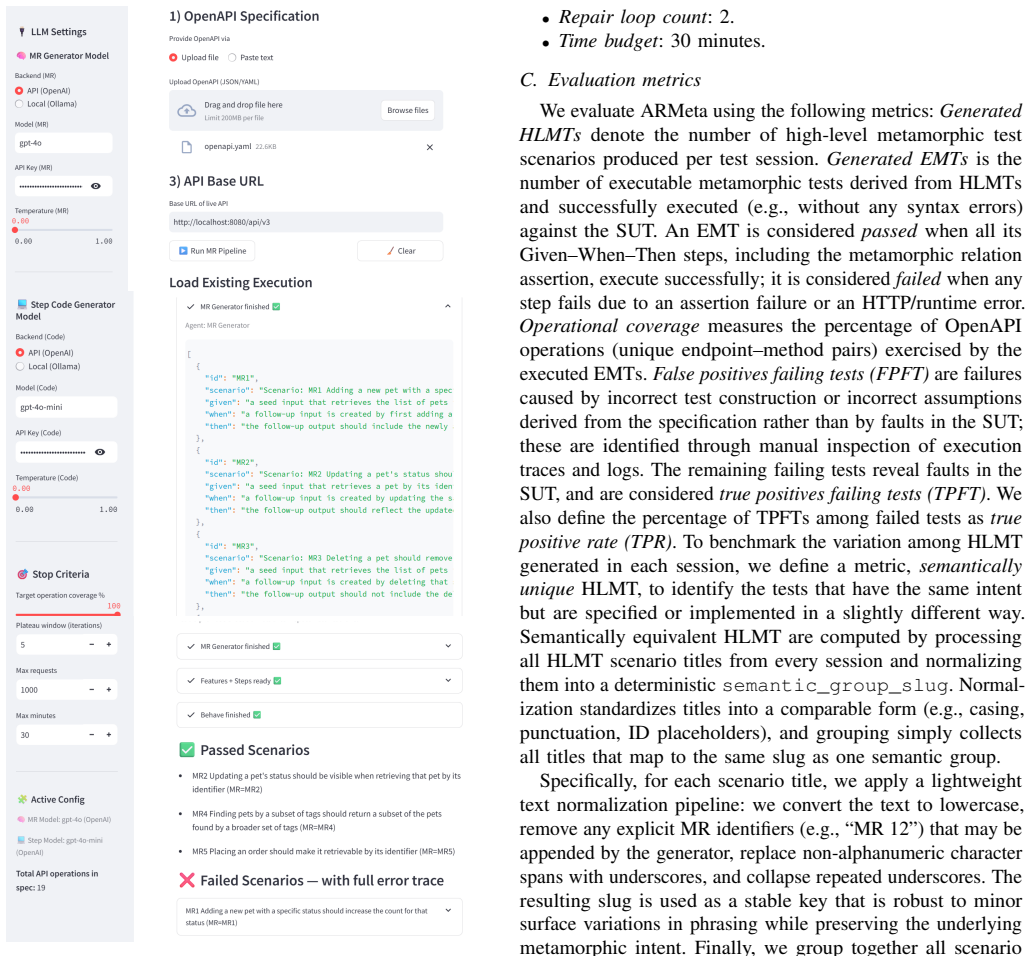
ARMeta is a tool-supported approach that uses an LLM-based multi-agent workflow to support metamorphic testing of REST APIs documented with OpenAPI. The agentic workflow is used to identify metamorphic test scenarios and specify them in the Given-When-Then format. These scenarios are automatically implemented as executable tests and executed against the system under test. We evaluate ARMeta on two publicly available web applications that expose REST interfaces and compare its performance with a scenario-based testing baseline. The results show that ARMeta explores behaviors that serve as a complement to existing scenario-based testing approaches.
What carries the argument
LLM-based multi-agent workflow that identifies metamorphic relations and encodes them as executable Given-When-Then tests for OpenAPI-described REST APIs.
If this is right
- Metamorphic testing can be applied to REST APIs even when no explicit oracle exists for individual responses.
- The generated tests run automatically once the scenarios are turned into code.
- The method can be compared directly against scenario-based testing on any OpenAPI-documented service.
- Additional behaviors become reachable without manual definition of every test case.
Where Pith is reading between the lines
- If the agent workflow scales without extra human review, manual effort for writing metamorphic relations could drop for teams that already use OpenAPI specs.
- The same multi-agent pattern might transfer to property-based testing or consistency checks in other API styles such as GraphQL.
- Integration into CI pipelines would allow repeated runs to catch behavioral drift after code changes.
Load-bearing premise
The LLM agents reliably produce valid metamorphic relations that do not introduce false positives or miss critical behaviors when applied to real REST APIs.
What would settle it
An execution of ARMeta on one of the two evaluated applications in which a generated metamorphic relation produces a false positive or fails to flag a known fault in the API would show the approach does not reliably complement the baseline.
Figures

read the original abstract
As REST APIs become an increasingly significant part of software systems, their validation is becoming more critical. Hence, testing and uncovering underlying issues are of utmost importance for improving software quality. However, testing REST APIs is challenging mainly due to the difficulty of assessing whether the output of an API call is correct, i.e., the test oracle problem. Metamorphic testing is a specification-based testing approach for situations where correct outputs are unknown or not specified explicitly. To check the correctness of a system, relations between the different outputs are specified. We present ARMeta, a tool-supported approach that uses an LLM-based multi-agent workflow to support metamorphic testing of REST APIs documented with OpenAPI. The agentic workflow is used to identify metamorphic test scenarios and specify them in the Given-When-Then format. These scenarios are automatically implemented as executable tests and executed against the system under test. We evaluate ARMeta on two publicly available web applications that expose REST interfaces and compare its performance with a scenario-based testing baseline. The results show that ARMeta explores behaviors that serve as a complement to existing scenario-based testing approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ARMeta, a multi-agent LLM workflow that generates metamorphic test scenarios in Given-When-Then format from OpenAPI specifications for REST APIs, automatically implements them as executable tests, and evaluates the approach on two public web applications against a scenario-based testing baseline, claiming that the generated behaviors serve as a complement to existing methods.
Significance. If the empirical results hold after proper validation of the metamorphic relations and fair baseline comparison, the work could advance automated testing for systems with difficult oracles by reducing the manual burden of specifying relations and demonstrating practical complementarity in REST API testing.
major comments (2)
- [Abstract] Abstract: the central claim of complementarity rests on an empirical comparison, but the abstract (and by extension the evaluation) provides no details on how the generated metamorphic relations were validated for correctness, what metrics quantified the explored behaviors, or how the scenario-based baseline was matched in scope and effort.
- [Evaluation] Evaluation (implied by abstract): without reported checks for false positives introduced by LLM-generated relations or coverage of critical behaviors missed by the baseline, the complementarity result cannot be assessed for reliability on real REST APIs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in our empirical claims. We address each major comment below and commit to revisions that strengthen the presentation of our validation and comparison methods without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of complementarity rests on an empirical comparison, but the abstract (and by extension the evaluation) provides no details on how the generated metamorphic relations were validated for correctness, what metrics quantified the explored behaviors, or how the scenario-based baseline was matched in scope and effort.
Authors: We agree that the abstract, as a concise summary, should better support the complementarity claim with high-level indicators of the underlying methods. The current evaluation describes the workflow and results on the two applications but does not explicitly detail validation steps, specific metrics, or baseline matching criteria in one place. In the revision we will update the abstract with a brief clause noting expert review for relation correctness, use of coverage and relation-count metrics, and scope matching via identical OpenAPI inputs and comparable scenario volumes; the evaluation section will be expanded with a dedicated paragraph consolidating these elements. revision: yes
-
Referee: [Evaluation] Evaluation (implied by abstract): without reported checks for false positives introduced by LLM-generated relations or coverage of critical behaviors missed by the baseline, the complementarity result cannot be assessed for reliability on real REST APIs.
Authors: We acknowledge that explicit reporting of false-positive mitigation and differential coverage analysis would improve assessability of the complementarity result. The manuscript currently reports aggregate outcomes and qualitative complementarity but does not include a systematic false-positive audit or enumeration of behaviors uniquely missed by the baseline. We will add these in revision by describing the manual filtering process used to discard invalid relations and by including a table or subsection contrasting unique state transitions and endpoint behaviors covered by ARMeta versus the baseline. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical tool (ARMeta) and its evaluation on two public REST applications against a scenario-based baseline. The central claim of complementarity rests on observed behaviors in that external comparison, with no equations, fitted parameters, self-defined quantities, or load-bearing self-citations that reduce the result to its own inputs by construction. The derivation chain is self-contained as a standard empirical study rather than a mathematical or definitional reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can be orchestrated to produce valid Given-When-Then metamorphic scenarios for REST APIs
Reference graph
Works this paper leans on
-
[1]
Uses and applications of the openapi/swagger specification: a systematic mapping of the literature,
S. Casas, D. Cruz, G. Vidal, and M. Constanzo, “Uses and applications of the openapi/swagger specification: a systematic mapping of the literature,” in2021 40th International Conference of the Chilean Computer Science Society (SCCC). IEEE, 2021, pp. 1–8
2021
-
[2]
Metamorphic testing: a new approach for generating next test cases,
T. Y . Chenet al., “Metamorphic testing: a new approach for generating next test cases,”arXiv preprint arXiv:2002.12543, 2020
-
[3]
A new method for constructing metamorphic relations,
H. Liuet al., “A new method for constructing metamorphic relations,” in12th International Conference on Quality Software. IEEE, 2012, pp. 59–68
2012
-
[4]
Metamorphic testing for web services: Framework and a case study,
C.-A. Sun, G. Wang, B. Mu, H. Liu, Z. Wang, and T. Y . Chen, “Metamorphic testing for web services: Framework and a case study,” in 2011 IEEE international Conference on Web Services. IEEE, 2011, pp. 283–290
2011
-
[5]
Metamorphic testing of restful web apis,
S. Segura, J. Parejo, J. Troya, and A. Ruiz-Cort ´es, “Metamorphic testing of restful web apis,”IEEE Transactions on Software Engineering, vol. PP, pp. 1–1, 10 2017
2017
-
[6]
Metamorphic testing: A review of challenges and opportunities,
T. Y . Chen, F. C. Kuo, H. Liu, P. L. Poon, D. Towey, T. H. Tse, and Z. Q. Zhou, “Metamorphic testing: A review of challenges and opportunities,” ACM Computing Surveys (CSUR), vol. 51, no. 1, pp. 1–27, 2018
2018
-
[7]
A survey on metamorphic testing,
S. Segura, G. Fraser, A. B. Sanchez, and A. Ruiz-Cort ´es, “A survey on metamorphic testing,”IEEE Transactions on Software Engineering, vol. 42, no. 9, pp. 805–824, 2016
2016
-
[8]
Can chatgpt advance software testing intelligence? an experience report on metamorphic testing,
Q. H. Luu, H. Liu, and T. Y . Chen, “Can chatgpt advance software testing intelligence? an experience report on metamorphic testing,”arXiv preprint arXiv:2310.19204, 2023
-
[9]
Automated metamorphic-relation generation with chatgpt,
Y . Zhang, D. Towey, and M. Pike, “Automated metamorphic-relation generation with chatgpt,” inProceedings of the 47th IEEE Annual Computers, Software, and Applications Conference (COMPSAC). IEEE, 2023, pp. 1–6
2023
-
[10]
Towards generating executable metamorphic relations using large language models,
S. Y . Shin, F. Pastore, D. Bianculli, and A. Baicoianu, “Towards generating executable metamorphic relations using large language models,” inInternational Conference on the Quality of Information and Communications Technology. Springer, 2024, pp. 126–141
2024
-
[11]
Behave: Behavior-driven development (bdd) framework for python,
B. Rice and R. Jones, “Behave: Behavior-driven development (bdd) framework for python,” https://pypi.org/project/behave/, Python Package Index (PyPI), 2025, version 1.3.3
2025
-
[12]
Streamlit documentation,
“Streamlit documentation,” https://docs.streamlit.io/, Accessed: December 2025
2025
-
[13]
Testing restful apis: A survey,
A. Golmohammadi, M. Zhang, and A. Arcuri, “Testing restful apis: A survey,”ACM Transactions on Software Engineering and Methodology, vol. 33, no. 1, pp. 1–41, 2023
2023
-
[14]
Logiagent: Automated logical testing for rest systems with llm-based multi-agents,
K. Zhanget al., “Logiagent: Automated logical testing for rest systems with llm-based multi-agents,”arXiv preprint arXiv:2503.15079, 2025
-
[15]
Restifai: Llm-based workflow for reusable rest api testing,
L. Kogler, M. Ehrhart, B. Dornauer, and E. P. Enoiu, “Restifai: Llm-based workflow for reusable rest api testing,”arXiv preprint arXiv:2512.08706, 2025
-
[16]
L. Liang, C. Tan, Y . Deng, Y . Cai, T. Y . Chen, and X. Zheng, “Automt: A multi-agent llm framework for automated metamorphic testing of autonomous driving systems,”arXiv preprint arXiv:2510.19438v1, 2025
-
[17]
B. Atil, S. Aykent, A. Chittams, L. Fu, R. J. Passonneau, E. Radcliffe, G. R. Rajagopal, A. Sloan, T. Tudrej, F. Tureet al., “Non-determinism of ”deterministic” llm settings,”arXiv preprint arXiv:2408.04667, 2024
-
[18]
Wynne and A
M. Wynne and A. Hellesoy,”The cucumber book: behaviour-driven development for testers and developers”. Pragmatic Bookshelf, 2012
2012
-
[19]
[Online]
Behave Development Team,Behave Documentation, Read the Docs, 2026, accessed: 2026-01-29. [Online]. Available: https: //behave.readthedocs.io/en/latest/
2026
-
[20]
CrewAI documentation,
CrewAI, “CrewAI documentation,” https://docs.crewai.com/, 2024, ac- cessed: 2025-02-15
2024
-
[21]
Streamlit: A faster way to build and share data apps,
Streamlit Inc., “Streamlit: A faster way to build and share data apps,” https://streamlit.io, 2023, accessed: 2026-02-06
2023
-
[22]
Swagger petstore,
Swagger API Team, “Swagger petstore,” https://github.com/swagger-api/ swagger-petstore, accessed: December 2025
2025
-
[23]
Microservice-rbac-user-management: Role-Based Access Control User Management Microservice,
Andrea Giassi, “Microservice-rbac-user-management: Role-Based Access Control User Management Microservice,” https://github.com/andreagiassi/ microservice-rbac-user-management, Accessed: December 2025
2025
-
[24]
Automated test generation for rest apis: No time to rest yet,
M. Kim, Q. Xin, S. Sinha, and A. Orso, “Automated test generation for rest apis: No time to rest yet,” inProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, 2022, pp. 289–301
2022
-
[25]
Armeta - replication package,
“Armeta - replication package,” https://gitlab.abo.fi/virtualseatrial-public/ ARMETA, accessed: 2026-05-26
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.