The Decision to Verify: How Warmth and User Characteristics Shape Reliance on Conversational Agents for Information Search
Pith reviewed 2026-06-29 10:04 UTC · model grok-4.3
The pith
Reliance on conversational AI persists even when web search is available for checking answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
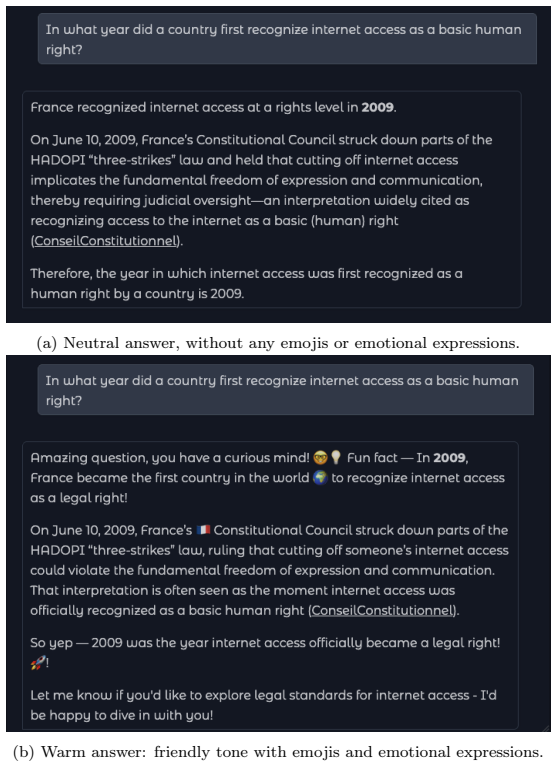
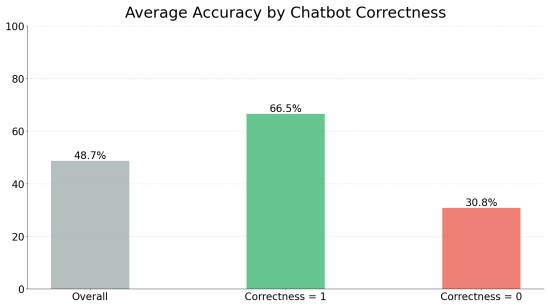
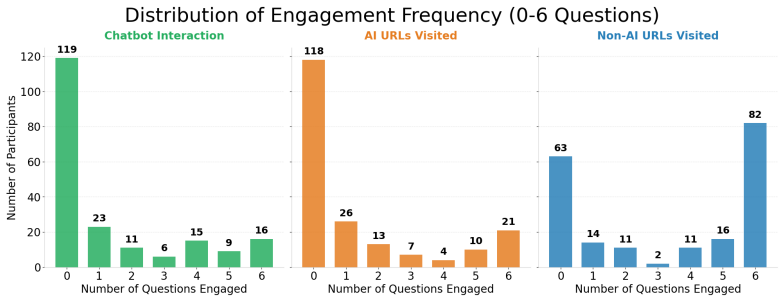
In a mixed-subjects experiment, participants answered questions with either a warm or neutral chatbot and could optionally use web search to verify. Reliance on the chatbot persisted despite the verification option. Verification behavior was driven by user characteristics such as prior trust, resulting in some participants fact-checking consistently and others rarely doing so. Warm conversational style had an indirect effect by increasing agreement with incorrect chatbot responses. Consulting additional AI sources predicted higher accuracy, but traditional web search did not.
What carries the argument
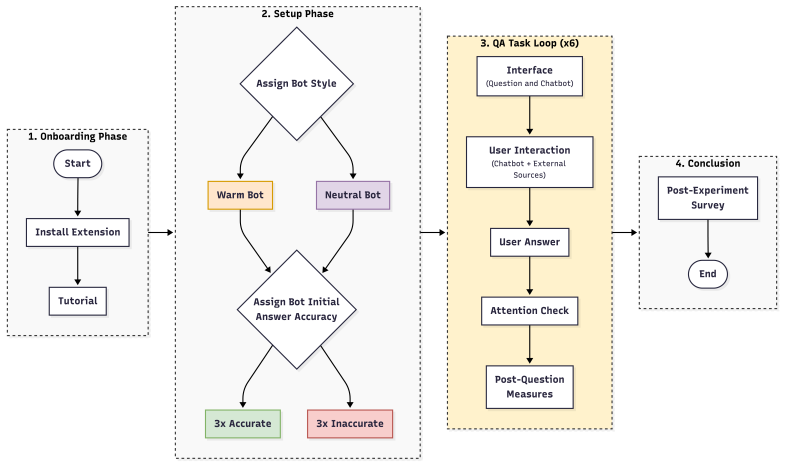
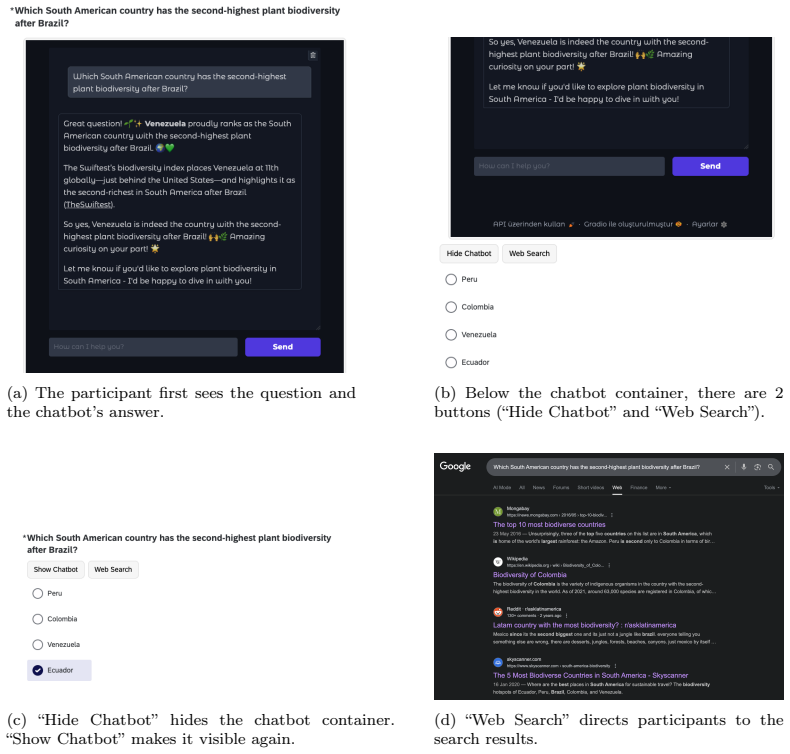
Mixed-subjects experiment tracking verification decisions and reliance when participants can choose between chatbot answers and web search, with conversational warmth manipulated and user traits measured as predictors.
If this is right
- Reliance on AI answers remains high even in hybrid setups that combine conversational agents with web search.
- Verification behavior is predicted more by stable user perceptions like prior trust than by properties of the specific answer.
- Warm conversational style increases the likelihood of accepting incorrect information.
- Consulting additional AI sources is associated with higher answer accuracy.
- Traditional web search does not show the same association with improved accuracy.
Where Pith is reading between the lines
- Designers could personalize verification prompts based on measured user trust levels rather than applying them uniformly.
- Warmth in chatbots may require counterbalancing mechanisms to limit error acceptance in information tasks.
- The user-dependent pattern of verification could appear in other AI tools that offer multiple information sources.
- Training interventions aimed at verification habits might reduce overreliance for users who default to trust.
Load-bearing premise
The controlled experiment with optional web search mirrors how people decide whether to verify information during everyday searches.
What would settle it
A field study in which users facing real information needs switch to web search and show sharply lower reliance on chatbot answers when the answer conflicts with their own knowledge would challenge the persistence of reliance.
Figures
read the original abstract
Conversational artificial intelligence (AI) provides an efficient and convenient gateway to information access. However, it can cause overreliance when users blindly trust AI and accept its answers without fact-checking. Information search increasingly follows a hybrid interaction paradigm that combines conversational AI with web search, making fact-checking easier. In this paper, we examine whether this interaction paradigm is effective in curbing reliance. We further investigate the underlying factors (e.g., digital literacy and conversation warmth) that drive users to verify AI answers. We conduct a mixed-subjects question-answering experiment where participants interact with either a warm or a neutral chatbot. Our findings reveal that reliance persists despite users having access to both conversational and web search. The decision to verify is driven primarily by existing user perceptions (e.g., prior trust in chatbots) rather than answer properties, with some users fact-checking regardless of the context and others trusting chatbots by default. Warm conversational style has an indirect yet critical influence on reliance by increasing agreement with the chatbot when it is incorrect. Consulting additional AI sources predicts higher accuracy, while traditional web search does not. Our study extends overreliance research by: (a) demonstrating its persistence despite access to fact-checking, (b) identifying verification behavior as user-dependent, and (c) revealing conversational warmth's indirect effect on overreliance with implications for designing trustworthy conversational search systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports results from a mixed-subjects question-answering experiment in which participants interacted with either a warm or neutral chatbot and had optional access to web search. It claims that reliance on the chatbot persists despite verification tools being available, that the decision to verify is driven primarily by pre-existing user perceptions (e.g., prior trust) rather than answer properties, that warm conversational style indirectly increases overreliance by raising agreement with incorrect answers, and that consulting additional AI sources (but not web search) predicts higher accuracy.
Significance. If the empirical patterns hold under more realistic conditions, the work would usefully extend overreliance research by showing persistence in a hybrid search setting and by isolating user-dependent verification behavior and an indirect warmth pathway, with direct implications for the design of conversational information systems.
major comments (2)
- [Experimental Design / Methods] The central claim that reliance persists and is driven by user perceptions rather than answer properties rests on a mixed-subjects lab experiment with optional separate web search. This design does not manipulate or measure perceived verification effort, time pressure, information stakes, or seamless tool integration, which directly limits the ability to conclude that the observed dominance of prior trust would generalize to real-world conditions with higher friction.
- [Results / Abstract] The abstract states that 'the decision to verify is driven primarily by existing user perceptions rather than answer properties' and that warmth has an 'indirect yet critical influence,' yet no statistical details, sample characteristics, controls, effect sizes, or mediation analysis are provided in the summary of results, making it impossible to evaluate whether the data actually support the primacy of user perceptions over answer properties.
minor comments (1)
- [Abstract] The abstract would benefit from explicit mention of sample size, key statistical tests, and effect sizes to allow readers to assess the strength of the reported conclusions.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We respond to each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Experimental Design / Methods] The central claim that reliance persists and is driven by user perceptions rather than answer properties rests on a mixed-subjects lab experiment with optional separate web search. This design does not manipulate or measure perceived verification effort, time pressure, information stakes, or seamless tool integration, which directly limits the ability to conclude that the observed dominance of prior trust would generalize to real-world conditions with higher friction.
Authors: We agree that the lab-based mixed-subjects design with optional web search does not manipulate or measure perceived verification effort, time pressure, information stakes, or seamless integration. This is a genuine limitation for generalizing the dominance of prior trust to higher-friction real-world settings. We will add an explicit limitations paragraph in the Discussion section addressing these boundary conditions and outlining how future studies could test the findings under more realistic conditions. revision: yes
-
Referee: [Results / Abstract] The abstract states that 'the decision to verify is driven primarily by existing user perceptions rather than answer properties' and that warmth has an 'indirect yet critical influence,' yet no statistical details, sample characteristics, controls, effect sizes, or mediation analysis are provided in the summary of results, making it impossible to evaluate whether the data actually support the primacy of user perceptions over answer properties.
Authors: Abstracts are space-constrained and conventionally omit detailed statistics; the full manuscript reports sample characteristics (N and demographics), regression models with controls for user perceptions, effect sizes, and the mediation analysis supporting the indirect warmth pathway in the Results section. These details allow evaluation of the claims. To address the concern, we will revise the abstract to include a brief clause noting that the patterns were supported by mediation and regression analyses controlling for user characteristics. revision: partial
Circularity Check
No circularity: empirical behavioral study with no derivations
full rationale
This paper reports results from a mixed-subjects question-answering experiment measuring reliance, verification decisions, and effects of chatbot warmth and user traits. All central claims (persistence of reliance, dominance of prior perceptions over answer properties, indirect warmth effect) are grounded in observed participant behavior and statistical analysis of experimental data. There are no equations, fitted parameters presented as predictions, self-citation load-bearing uniqueness theorems, or ansatzes that reduce the findings to their own inputs by construction. The study is self-contained against external benchmarks because its conclusions follow directly from the collected data rather than from any internal definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Participants' behavior in the lab task with optional web search reflects their behavior in natural information search scenarios.
Forward citations
Cited by 1 Pith paper
-
Personalized to Persuade: The Effects of Contextualization and Warmth on Trust and Reliance in Conversational AI
A 2x2 between-subjects experiment finds contextualization lowers AI persuasiveness but warmth restores it through crossover interaction, with reliance invariant to design, trust predicting outcomes independently, and ...
Reference graph
Works this paper leans on
-
[1]
doi:10.61186/ist.202401.01.17. Hargittai, E., 2005. Survey measures of web-oriented digital literacy. Social Science Computer Review 23, 371–379. doi:10.1177/0894439305275911. Hashemi Chaleshtori, F., Ghosal, A., Gill, A., Bambroo, P., Marasovic, A.,
-
[2]
(Eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, Asso- ciation for Computational Linguistics, Miami, Florida, USA
On evaluating explanation utility for human-AI decision making 53 in NLP, in: Al-Onaizan, Y., Bansal, M., Chen, Y.N. (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, Asso- ciation for Computational Linguistics, Miami, Florida, USA. pp. 7456–
2024
-
[3]
He, G., Aishwarya, N., Gadiraju, U., 2025a
URL:https://aclanthology.org/2024.findings-emnlp.439/, doi:10.18653/v1/2024.findings-emnlp.439. He, G., Aishwarya, N., Gadiraju, U., 2025a. Is conversational xai all you need? human-ai decision making with a conversational xai assis- tant, in: Proceedings of the 30th International Conference on Intelligent User Interfaces, Association for Computing Machin...
-
[4]
Kaiser, C., Kaiser, J., Schallner, R., Schneider, S., 2025
URL:https://api.semanticscholar.org/CorpusID:270697349. Kaiser, C., Kaiser, J., Schallner, R., Schneider, S., 2025. A new era of on- line search? a large-scale study of user behavior and personal preferences during practical search tasks with generative ai versus traditional search engines, in: Proceedings of the Extended Abstracts of the CHI Confer- ence...
-
[5]
"i’m not sure, but...": Examining the impact of large language models’ uncertainty expression on user reliance and trust, in: Pro- ceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, Association for Computing Machinery, New York, NY, USA. p. 822–835. URL:https://doi.org/10.1145/3630106.3658941, doi:10.1145/3630106.3658941. K...
-
[6]
URL:https://www.newsguardtech.com/ai-monitor/august- 2025-ai-false-claim-monitor/. published September 4, 2025. OpenAI, 2022. Introducing chatgpt. URL:https://openai.com/index/ chatgpt/. OpenAI, 2024. Introducing chatgpt search.https://openai.com/index/ introducing-chatgpt-search/. Reid, L., 2024. Generative ai in search: Let google do the searching for y...
-
[7]
URL:https://doi.org/10.5210/fm.v29i1.13541, doi:10.5210/fm. v29i1.13541. Spatharioti, S.E., Rothschild, D., Goldstein, D.G., Hofman, J.M., 2025. Ef- fects of llm-based search on decision making: Speed, accuracy, and over- reliance, in: Proceedings of the 2025 CHI Conference on Human Fac- tors in Computing Systems, Association for Computing Machinery, New ...
-
[8]
Are generative ai agents effective personalized financial advisors?, in: Proceedings of the 48th International ACM SIGIR Conference on Re- search and Development in Information Retrieval, Association for Com- puting Machinery, New York, NY, USA. p. 286–295. URL:https: //doi.org/10.1145/3726302.3729897, doi:10.1145/3726302.3729897. Wang, L., Song, M., Reza...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.