When LLM Reward Design Fails: Diagnostic-Driven Refinement for Sparse Structured RL
Pith reviewed 2026-06-29 14:08 UTC · model grok-4.3
The pith
LLM reward functions for sparse RL improve when treated as iterative debugging guided by training diagnostics and a failure taxonomy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
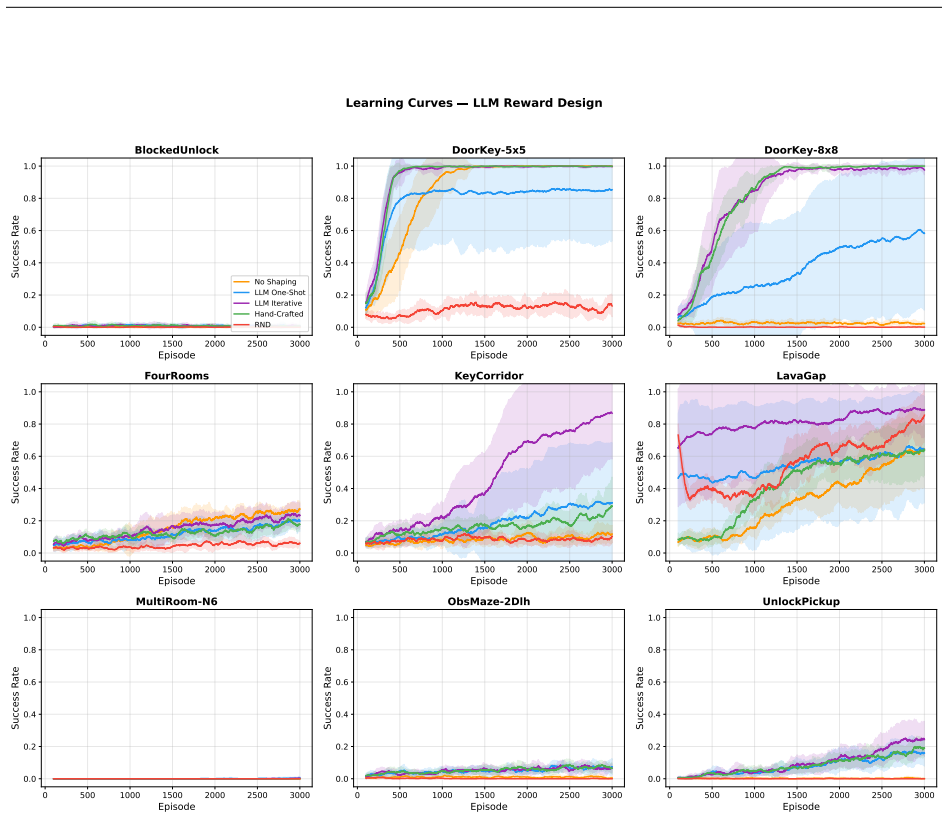
For sparse structured RL tasks, LLM reward design is better framed as debugging than one-shot generation. Diagnostic-driven iterative refinement, where training diagnostics and a failure-mode taxonomy guide targeted reward-function revisions, improves DoorKey-8x8 from 2.3% to 97.6% and KeyCorridor from 31.2% to 86.7%. Controls separate the effect from retrying or extra training, with the taxonomy prompt emerging as a major mechanism and dynamic labels providing only partial additional benefit.
What carries the argument
Diagnostic-driven iterative refinement that uses return trends, success rates, and a three-mode failure taxonomy to produce targeted revisions to LLM-generated reward functions.
If this is right
- Taxonomy-guided refinement accounts for most of the observed gains over metrics-only re-prompting.
- Static-vocabulary controls recover a large fraction of the performance, indicating the taxonomy itself carries substantial value.
- Success-based diagnostics can produce false positives in dense-reward locomotion tasks.
- Return-trend feedback removes one false-positive mechanism but does not yield robust gains in continuous control.
- Point estimates suggest larger gains when LLM reward-function variance dominates, though bootstrap intervals remain wide.
Where Pith is reading between the lines
- The protocol may extend to other sparse-reward domains that expose event logs or semantic state descriptions without requiring changes to the core refinement loop.
- Event_text fields could be tested as an optional diagnostic channel whose effect may be neutral, helpful, or harmful depending on the task.
- The method's cost advantage over population search could be quantified directly by comparing total LLM calls to achieve a target success rate across matched environments.
- Calibration limits observed against author labels suggest that human review of revised reward code remains necessary even after automated refinement.
Load-bearing premise
The selected training diagnostics reliably surface the three failure modes and the taxonomy-guided revisions generalize beyond the specific MiniGrid environments and seed variance tested.
What would settle it
Running the same refinement protocol on a new sparse structured environment with reliable semantic interfaces yields no improvement over one-shot LLM rewards, or removing the taxonomy prompt causes no measurable drop in final performance.
Figures







read the original abstract
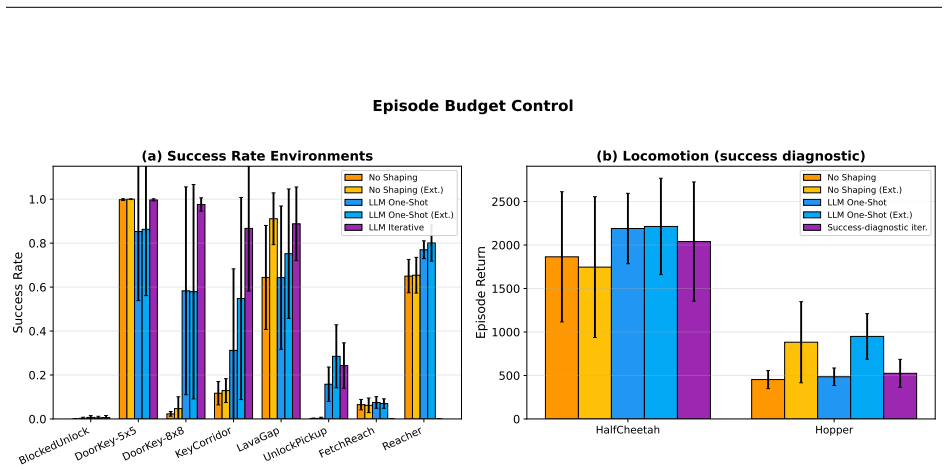
For sparse, structured reinforcement-learning tasks with semantic reward-function interfaces, LLM-generated reward shaping is better framed as debugging than one-shot generation. We study PPO-trained agents using MiniGrid as core evaluation and MuJoCo as boundary stress test. Our audit finds two dominant one-shot failure modes -- reward flooding and semantic/API misunderstanding -- plus a rarer weak-shaping case. We propose diagnostic-driven iterative refinement, where training diagnostics and a failure-mode taxonomy guide targeted reward-function revision. Refinement improves DoorKey-8x8 from 2.3% to 97.6% and KeyCorridor from 31.2% to 86.7% with high seed-to-seed variance. Controls show these gains are not from retrying or extra training: metrics-only re-prompting yields large drops, while a static-vocabulary control recovers much of the gap (87.6%; 70.7%), showing the taxonomy prompt is a major mechanism and dynamic labels provide only partially isolated incremental evidence. Budget-matched and Best-of-3 comparisons separate refinement from selection and training-time effects. Component-removal tests, sensitivity analyses, and an audit against author labels provide converging evidence for the debugging interpretation while revealing calibration limits. Continuous-control results show the boundary: success-based diagnostics can misfire in dense-reward locomotion, and return-trend feedback removes one false-positive mechanism without robust gains. The low-call protocol is a cost contrast with population-based reward search, not a benchmark comparison. In four crossed-variance-design environments, point estimates suggest larger gains when LLM reward-function variance dominates but bootstrap intervals are wide. The method is bounded to sparse structured tasks with reliable interfaces under PPO; fields like event_text may help, hurt, or be neutral.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM reward design for sparse structured RL tasks is better framed as diagnostic-driven iterative refinement using training diagnostics (return trends, success rates) and a failure-mode taxonomy, rather than one-shot generation. On MiniGrid, refinement raises DoorKey-8x8 success from 2.3% to 97.6% and KeyCorridor from 31.2% to 86.7%; multiple controls (metrics-only re-prompting, static-vocabulary, budget-matched, Best-of-3, component-removal) and an author-label audit indicate gains arise from taxonomy-guided revision rather than retrying or extra training. MuJoCo tests delineate the boundary where success-based diagnostics misfire in dense-reward settings.
Significance. If the results hold, the work supplies a concrete debugging protocol for LLM reward shaping that separates refinement, selection, and training effects via explicit controls and component-removal tests. The empirical deltas with crossed-variance design and low-call cost framing are useful for practitioners working on sparse tasks with semantic interfaces; the explicit boundary test on MuJoCo is also a strength.
major comments (3)
- [Audit and component-removal analysis] The central claim that return trends and success rates reliably surface the three failure modes (reward flooding, semantic/API misunderstanding, weak-shaping) rests on the audit and component-removal tests, yet the manuscript provides no quantitative validation (inter-rater agreement, threshold ablation, or noise-separation metrics) that these signals distinguish the modes from environment-specific patterns or seed variance.
- [Crossed-variance design results] In the four crossed-variance-design environments, point estimates favor the method when LLM variance dominates, but the reported high seed-to-seed variance and wide bootstrap intervals undermine the inference that gains result from correct mode identification rather than lucky alignment with the test environments.
- [Continuous-control boundary test] The MuJoCo boundary experiment correctly flags that success-based diagnostics can misfire in dense-reward locomotion and that return-trend feedback removes one false-positive mechanism, yet the absence of robust gains even after this correction indicates the method's scope is narrower than the sparse-structured-task framing suggests.
minor comments (1)
- [Abstract] The sentence in the abstract stating that 'the low-call protocol is a cost contrast with population-based reward search, not a benchmark comparison' is imprecise and should be clarified.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We respond to each major comment below, acknowledging where evidence is limited and noting existing qualifications in the manuscript.
read point-by-point responses
-
Referee: [Audit and component-removal analysis] The central claim that return trends and success rates reliably surface the three failure modes (reward flooding, semantic/API misunderstanding, weak-shaping) rests on the audit and component-removal tests, yet the manuscript provides no quantitative validation (inter-rater agreement, threshold ablation, or noise-separation metrics) that these signals distinguish the modes from environment-specific patterns or seed variance.
Authors: We agree the audit uses author labels without inter-rater agreement or explicit noise-separation metrics, which limits its strength as standalone validation. Component-removal tests supply quantitative evidence via performance drops, and multiple controls (metrics-only re-prompting, static-vocabulary, budget-matched) converge on the taxonomy's role. We will revise to explicitly state the audit's limitations and add a brief threshold-sensitivity note where data permit, but cannot retroactively compute inter-rater statistics. revision: partial
-
Referee: [Crossed-variance design results] In the four crossed-variance-design environments, point estimates favor the method when LLM variance dominates, but the reported high seed-to-seed variance and wide bootstrap intervals undermine the inference that gains result from correct mode identification rather than lucky alignment with the test environments.
Authors: The manuscript already qualifies these results as point estimates with wide bootstrap intervals and high seed variance, presenting them as suggestive rather than conclusive proof of mode identification. The crossed design isolates LLM variance contribution but does not claim definitive causal attribution beyond the observed patterns. No revision is required. revision: no
-
Referee: [Continuous-control boundary test] The MuJoCo boundary experiment correctly flags that success-based diagnostics can misfire in dense-reward locomotion and that return-trend feedback removes one false-positive mechanism, yet the absence of robust gains even after this correction indicates the method's scope is narrower than the sparse-structured-task framing suggests.
Authors: The manuscript already frames the MuJoCo results as a boundary test showing where success-based diagnostics fail in dense-reward settings and explicitly states the method is bounded to sparse structured tasks. The lack of robust gains is reported as expected evidence of this scope limit, not an unaddressed weakness. No revision needed. revision: no
- Inter-rater agreement metrics for the failure-mode audit, as labeling was performed solely by the authors without additional independent raters.
Circularity Check
No significant circularity; empirical results are self-contained
full rationale
The paper reports experimental outcomes on MiniGrid and MuJoCo tasks using PPO, with explicit controls (metrics-only re-prompting, static-vocabulary, budget-matched, Best-of-3, component-removal tests) that separate refinement effects from selection and training artifacts. No equations, fitted parameters, or predictions are presented that reduce by construction to inputs; the central claims rest on observed performance deltas and audit against author labels rather than any self-definitional or self-citation load-bearing derivation. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Start with the o ri gin al reward
-
[2]
Add one - time bonuses (+0.1 to +0.3) for su bgo al s
-
[3]
Use state dict to ensure bonuses given only ONCE
-
[4]
e v e n t _ t e x t
Check info [ " e v e n t _ t e x t " ] for events
-
[5]
Keep bonuses small vs goal reward (~1.0)
-
[6]
Self - c o n t a i n e d f unc ti on
No imports . Self - c o n t a i n e d f unc ti on . D.2 Refinement Prompt For iterative refinement, the prompt additionally includes the previous reward function source code, training metrics, and diagnosed failure modes: 1# CURRENT REWARD FU NC TIO N 2{ c u r r e n t _ s o u r c e } 3 4# T RAI NI NG RESULTS 5- E pis od es trained : { e p i s o d e s _ t ...
-
[7]
Reward f loo di ng : Do NOT add per - step bonuses
-
[8]
Action - index c o n f u s i o n : Mi ni Gri d action 150= turn_left , 2= forward , NOT d i r e c t i o n s
-
[9]
k e y _ p i c k e d _ u p
Too - weak shaping : +0.1 may be too small . 17Use position - based pro gr ess tr ack in g . E Iterative Refinement Example Table 17 shows the iterative refinement process on DoorKey-8×8 (seed 42). The LLM progressively improves the reward function based on probe training diagnostics. Iter Probe SR Key Changes 0 29% Basic one-time bonuses for key pickup (...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.