A Theoretical and Experimental Study of a Novel Adaptive Learning Algorithm
Pith reviewed 2026-06-29 09:16 UTC · model grok-4.3
The pith
C-Adam optimizer is proposed with a convergence proof based on the line of sight approach.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the line of sight approach produces an optimizer called C-Adam whose update rule admits a convergence proof, thereby addressing the non-convergence limitation identified in Adam while retaining the benefits of adaptive learning rates.
What carries the argument
The line of sight approach, which adjusts the second-moment estimate in the adaptive update to enforce convergence.
If this is right
- C-Adam can replace Adam or AMSGrad in settings where a convergence guarantee is required.
- Neural network training runs would exhibit reduced risk of oscillation-induced failure.
- The same line of sight modification could be examined for other adaptive methods that currently lack proofs.
Where Pith is reading between the lines
- If the approach generalizes, similar modifications might restore convergence guarantees to other first-order methods without second-moment tracking.
- Empirical comparisons on very large models would test whether the added guarantee scales without extra hyper-parameter tuning.
Load-bearing premise
The line of sight approach produces an optimizer variant whose convergence can be proven and that performs at least as well as Adam or AMSGrad on practical tasks.
What would settle it
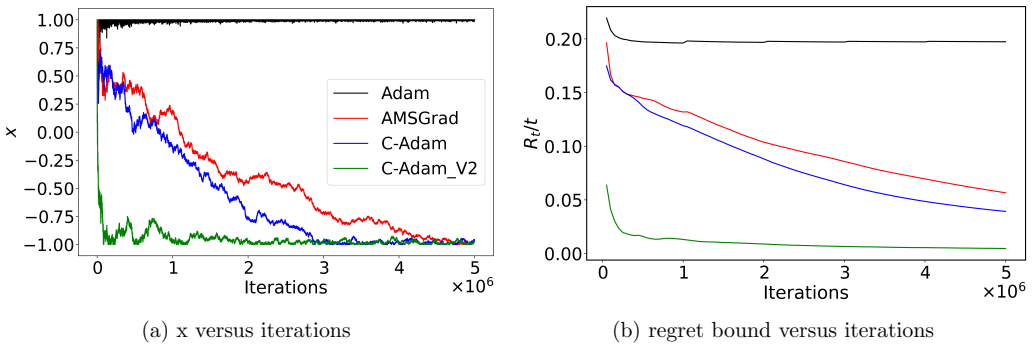
A training run or benchmark experiment in which C-Adam diverges or reaches a worse final loss than AMSGrad on the same problem and initialization.
Figures


read the original abstract
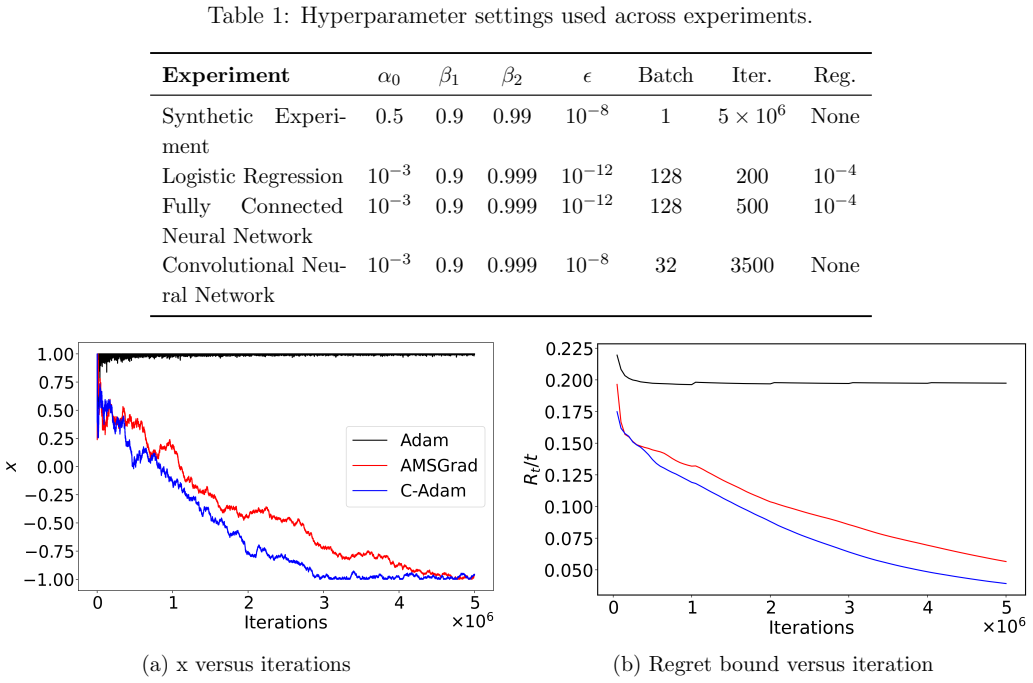
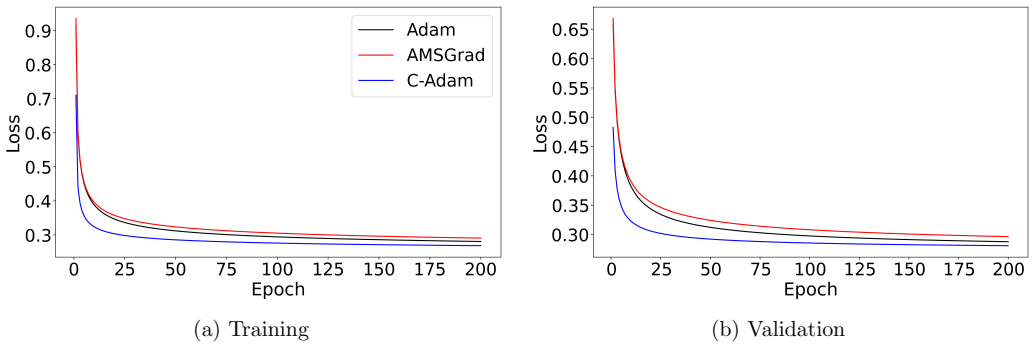
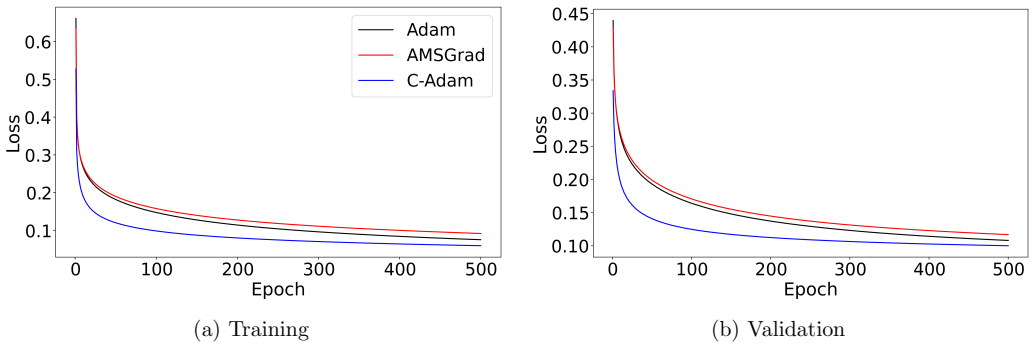
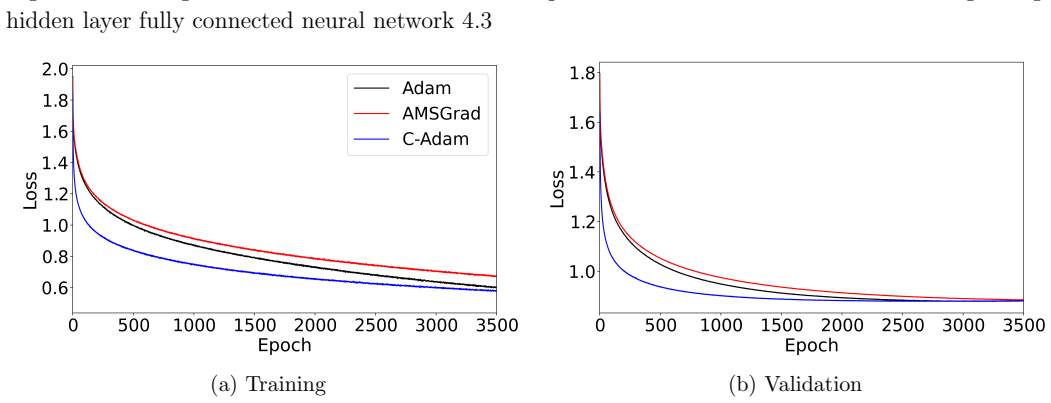
A crucial component of machine learning algorithms is minimizing loss functions with less computational cost and less oscillations. While adaptive learning rate-based optimizers have been widely used for real-world tasks, they do not guarantee convergence, which is why AMSGrad was later introduced to investigate the non-convergence behaviour of Adam. In this paper, popular adaptive optimization methods like Adam and AMSGrad are critically reviewed with an emphasis on their fundamental design concepts. To address limitations of the above mentioned optimizers, a new optimizer variant, C-Adam, is proposed based on the line of sight approach. A theoretical proof for convergence is also provided and the optimizer is validated through a number of real-life based numerical experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reviews limitations of Adam and AMSGrad, proposes a new optimizer C-Adam derived from a 'line of sight approach,' supplies a convergence proof, and reports numerical experiments on real-world tasks showing improved performance.
Significance. A rigorously proven convergent adaptive optimizer that demonstrably improves on Adam/AMSGrad in experiments would be a useful contribution to the optimization literature; the explicit provision of a proof and reproducible experiments strengthens the work if the derivation holds.
minor comments (3)
- [Abstract] The abstract states that a convergence proof is provided but does not indicate the assumptions (e.g., bounded gradients, convexity) under which the result holds; a brief statement of the main assumptions in the abstract would improve accessibility.
- [§3] Notation for the line-of-sight update rule and the moment estimates should be cross-referenced to the corresponding equations in §3 to avoid ambiguity for readers familiar with Adam.
- [§5] Figure captions for the experimental loss curves should explicitly state the number of independent runs and whether shaded regions represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the significance of a rigorously proven convergent adaptive optimizer, and the recommendation of minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity; derivation self-contained against external benchmarks
full rationale
The paper defines C-Adam via the line-of-sight approach, states a convergence proof, and reports experiments. No load-bearing step reduces by construction to a fitted input, self-citation chain, or renamed known result; the proof and optimizer definition are presented as independent of the target performance claims. The central result therefore does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sign potential-driven multiplicative optimization for robust deep reinforcement learning
Loukia Avramelou, Manos Kirtas, Nikolaos Passalis, and Anastasios Tefas. Sign potential-driven multiplicative optimization for robust deep reinforcement learning. Neural Networks, 188:107492, 2025
2025
-
[2]
Convolutional neural network-based mapping of material micro- structures to deep material networks for non-linear mechanical response prediction
Ling Wu and Ludovic Noels. Convolutional neural network-based mapping of material micro- structures to deep material networks for non-linear mechanical response prediction. Computer Methods in Applied Mechanics and Engineering, 449:118554, 2026
2026
-
[3]
When Meaning Isn't Literal: Exploring Idiomatic Meaning Across Languages and Modalities
Sarmistha Das, Shreyas Guha, Suvrayan Bandyopadhyay, Salisa Phosit, Kitsuchart Pasupa, and Sriparna Saha. When meaning isn’t literal: Exploring idiomatic meaning across languages and modalities. arXiv preprint arXiv:2604.10787, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Gradient-enhanced physics-informed neural networks for forward and inverse pde problems
Jeremy Yu, Lu Lu, Xuhui Meng, and George Em Karniadakis. Gradient-enhanced physics-informed neural networks for forward and inverse pde problems. Computer Methods in Applied Mechanics and Engineering, 393:114823, 2022
2022
-
[5]
Nguyen, Phuong Ha Nguyen, Peter Richt´ arik, Katya Scheinberg, Martin Tak´ aˇ c, and Marten van Dijk
Lam M. Nguyen, Phuong Ha Nguyen, Peter Richt´ arik, Katya Scheinberg, Martin Tak´ aˇ c, and Marten van Dijk. New convergence aspects of stochastic gradient algorithms. Journal of Machine Learning Research, 20(176):1–49, 2019
2019
-
[6]
Aiming towards the minimizers: fast convergence of sgd for overparametrized problems
Chaoyue Liu, Dmitriy Drusvyatskiy, Misha Belkin, Damek Davis, and Yian Ma. Aiming towards the minimizers: fast convergence of sgd for overparametrized problems. Advances in neural information processing systems, 36:60748–60767, 2023
2023
-
[7]
Adaptive subgradient methods for online learning and stochastic optimization
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(61):2121–2159, 2011
2011
-
[8]
RMSProp: Divide the gradient by a running average of its recent magnitude
Tijmen Tieleman and Geoffrey Hinton. RMSProp: Divide the gradient by a running average of its recent magnitude. Coursera: Neural Networks for Machine Learning, Lecture 6.5, 2012
2012
-
[9]
Matthew D. Zeiler. ADADELTA: An adaptive learning rate method.arXiv preprint arXiv:1212.5701, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[10]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[11]
Is your batch size the problem? revisiting the adam-sgd gap in language modeling
Teodora Sre´ ckovi´ c, Jonas Geiping, and Antonio Orvieto. Is your batch size the problem? revisiting the adam-sgd gap in language modeling. arXiv preprint arXiv:2506.12543, 2025. 17
-
[12]
Applying transfer learning using bert-based models for hate speech detection
Sakshi Kalra, Kalit Naresh Inani, Yashvardhan Sharma, and Gajendra Singh Chauhan. Applying transfer learning using bert-based models for hate speech detection. In FIRE (Working Notes), pages 200–208, 2021
2021
-
[13]
On the Convergence of Adam and Beyond
Sashank J. Reddi, Satyen Kale, and Sanjiv Kumar. On the convergence of Adam and beyond. arXiv preprint arXiv:1904.09237, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[14]
Adaptive Gradient Methods with Dynamic Bound of Learning Rate
Liangchen Luo, Yuanhao Xiong, Yan Liu, and Xu Sun. Adaptive gradient methods with dynamic bound of learning rate. arXiv preprint arXiv:1902.09843, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[15]
Adaptive methods for nonconvex optimization
Manzil Zaheer, Sashank Reddi, Devendra Sachan, Satyen Kale, and Sanjiv Kumar. Adaptive methods for nonconvex optimization. Advances in neural information processing systems, 31, 2018
2018
-
[16]
Multilayered neural network with an amsgrad optimization learning method
Serhiy Sveleba, I Katerynchuk, I Kunyo, O Semotiuk, Ya Shmyhelskyy, Serhiy Velhosh, and V Franiv. Multilayered neural network with an amsgrad optimization learning method. Electronics and information technologies, 25, 2024
2024
-
[17]
A new image classification system using deep convolution neural network and modified amsgrad optimizer
Arman I Mohammed and Ahmed AK Tahir. A new image classification system using deep convolution neural network and modified amsgrad optimizer. Journal of Duhok University, 22(2):89–101, 2019
2019
-
[18]
Nostalgic Adam: Weighting more of the past gradients when designing the adaptive learning rate
Haoyang Huang, Chang Wang, and Bin Dong. Nostalgic Adam: Weighting more of the past gradients when designing the adaptive learning rate. arXiv preprint arXiv:1805.07557, 2018
-
[19]
On the convergence speed of AMSGrad and beyond
Tao Tan, Shouyi Yin, Kai Liu, and Ming Wan. On the convergence speed of AMSGrad and beyond. In 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), pages 464–470. IEEE, 2019
2019
-
[20]
Convex Optimization
Stephen Boyd and Lieven Vandenberghe. Convex Optimization. Cambridge University Press, Cambridge, UK, 2004. 18
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.