Usability Analysis of Configurator User Interfaces with Multimodal Large Language Models
Pith reviewed 2026-06-29 06:55 UTC · model grok-4.3
The pith
Multimodal large language models can reliably detect configurator-specific usability issues and suggest improvements when using 18 domain criteria.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
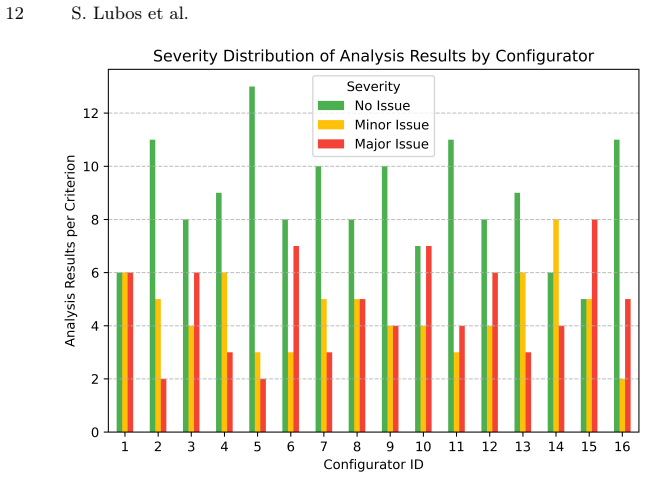
By applying 18 configurator-specific usability criteria to screenshots or descriptions of 16 real-world configurators, multimodal large language models generate individual severity ratings and actionable improvement recommendations for each criterion, and a subsequent review finds these outputs to be reliable and domain-aware.
What carries the argument
The set of 18 configurator-specific usability criteria, each evaluated separately by the MLLM to produce severity ratings and suggestions.
If this is right
- Analysis effort for configurator usability decreases because MLLMs handle initial assessments.
- Improvement suggestions are tailored to the configurator domain.
- The approach works across multiple real-world examples.
- Human oversight is still required for final validation.
Where Pith is reading between the lines
- Integration with existing UI design tools could automate parts of the review process.
- Expanding the criteria list might cover additional aspects of configurator interaction.
- Similar techniques could apply to usability analysis in other specialized software domains.
- Larger-scale studies with more configurators would test consistency across different MLLM versions.
Load-bearing premise
A qualitative human review of the MLLM outputs sufficiently establishes reliability, and the 18 criteria capture configurator usability without major omissions or overlaps.
What would settle it
Independent expert evaluations of the same 16 configurators using the 18 criteria, measuring the level of agreement with MLLM severity ratings and recommendation quality.
Figures



read the original abstract
Configuration is a key technology for tailoring complex software systems, services, and products. A successful application of configurators not only depends on technical correctness, performance, and domain modeling but also on their usability. While general usability heuristics are widely used, configurator-specific criteria and tool support for systematic user interface (UI) analysis are limited. This paper explores the use of multimodal large language models (MLLMs) for scalable and semi-automated usability analysis of configurator UIs. We synthesize 18 configurator-specific usability criteria from the literature and apply these criteria in an MLLM-based analysis of 16 real-world configurators. Each criterion is assessed individually to generate severity ratings for usability issues and actionable improvement suggestions. A review of the results confirms that MLLMs can reliably identify configurator-specific usability issues and provide domain-aware improvement recommendations. Although human validation remains necessary, this approach has the potential to significantly reduce the required effort to analyze configurator usability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes using multimodal large language models (MLLMs) for semi-automated usability analysis of configurator user interfaces. It synthesizes 18 configurator-specific criteria from the literature, applies them via MLLMs to evaluate 16 real-world configurators (producing per-criterion severity ratings and improvement suggestions), and asserts that a qualitative review of the outputs confirms the MLLMs can reliably detect issues and offer domain-aware recommendations (while still requiring human validation).
Significance. If the reliability claim were supported by objective evidence, the work would represent a useful empirical demonstration of applying existing MLLMs to a specialized software-engineering domain where general heuristics are insufficient. The synthesis of 18 domain criteria and the concrete application to 16 configurators could lower the effort for systematic UI analysis, provided the criteria are shown to be non-redundant and the MLLM outputs are validated against expert baselines.
major comments (1)
- [Abstract, §4, and §5] Abstract, §4, and §5: The assertion that MLLMs 'can reliably identify configurator-specific usability issues' rests entirely on an unspecified qualitative review of the generated severity ratings and suggestions. No quantitative validation is reported (no inter-rater agreement metrics such as Cohen/Fleiss kappa, no precision/recall against ground-truth issues identified by experts, no ablation on criterion overlap/omission, and no baseline comparison). Because this review is the sole support for the central claim of reliability, the claim is unsupported by objective evidence.
minor comments (2)
- [§5] The paper should clarify the exact procedure used for the 'review of the results' (who performed it, how many configurators were inspected in detail, and what rubric was applied) to allow readers to assess its scope.
- [§3] Details on the literature synthesis process for the 18 criteria (search strategy, inclusion criteria, and any redundancy or coverage checks) would strengthen the methodological transparency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the reliability claim in the abstract, §4, and §5 rests on qualitative review alone and lacks objective quantitative support, which is a limitation of the current exploratory study. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract, §4, and §5] Abstract, §4, and §5: The assertion that MLLMs 'can reliably identify configurator-specific usability issues' rests entirely on an unspecified qualitative review of the generated severity ratings and suggestions. No quantitative validation is reported (no inter-rater agreement metrics such as Cohen/Fleiss kappa, no precision/recall against ground-truth issues identified by experts, no ablation on criterion overlap/omission, and no baseline comparison). Because this review is the sole support for the central claim of reliability, the claim is unsupported by objective evidence.
Authors: We acknowledge that the central claim relies solely on an author-conducted qualitative review of the MLLM outputs without quantitative metrics, inter-rater agreement, expert baselines, or ablation studies. This is a genuine limitation of the work, which is positioned as an initial demonstration rather than a validated method. In the revision we will: (1) tone down the language in the abstract, §4, and §5 to state that the outputs 'appeared consistent with domain expectations upon qualitative review' instead of claiming 'reliability'; (2) add an explicit description of the review process (authors with configurator expertise examined a sample of outputs for plausibility and actionability); and (3) expand the limitations and future-work sections to highlight the absence of quantitative validation and the need for expert ground-truth comparisons. We cannot retroactively add the requested quantitative analyses to this study but will treat the point as a clear direction for follow-on research. revision: yes
Circularity Check
No significant circularity; empirical application with no self-referential reductions
full rationale
The paper synthesizes 18 criteria from external literature, applies existing MLLMs to 16 configurators, and performs a qualitative review of outputs. No equations, fitted parameters, predictions, or self-citation chains appear. The central claim rests on author inspection of MLLM results rather than any derivation that reduces to its own inputs by construction. This is a standard empirical domain application with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 25th International Conference on Advanced Information Systems En- gineering
Abbasi, E.K., Hubaux, A., Acher, M., Boucher, Q., Heymans, P.: The anatomy of a sales configurator: an empirical study of 111 cases. In: Proceedings of the 25th International Conference on Advanced Information Systems En- gineering. p. 162–177. CAiSE’13, Springer-Verlag, Berlin, Heidelberg (2013). https://doi.org/10.1007/978-3-642-38709-8_11
-
[2]
In: Meiselwitz, G
Castro, J.W., Garnica, I., Rojas, L.A.: Automated tools for usability evaluation: A systematic mapping study. In: Meiselwitz, G. (ed.) Social Computing and Social Media: Design, User Experience and Impact. pp. 28–46. Springer International Publishing, Cham (2022)
2022
-
[3]
In: Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems
Duan, P., Warner, J., Li, Y., Hartmann, B.: Generating automatic feedback on ui mockups with large language models. In: Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems. CHI ’24, Association for Computing Machinery, New York, NY, USA (2024). https://doi.org/10.1145/3613904.3642782
-
[4]
Morgan Kaufmann (2014)
Felfernig, A., Hotz, L., Bagley, C., Tiihonen, J.: Knowledge-based Configuration – From Research to Business Cases. Morgan Kaufmann (2014)
2014
-
[5]
IEEE Transactions on Engineering Man- agement54(1), 41–56 (2007)
Felfernig, A.: Standardized configuration knowledge representations as technolog- ical foundation for mass customization. IEEE Transactions on Engineering Man- agement54(1), 41–56 (2007). https://doi.org/10.1109/TEM.2006.889066 Usability Analysis of Configurator UIs with Multimodal LLMs 19
-
[6]
Felfernig, A., Falkner, A., Benavides, D.: Analysis of Feature Models, pp. 45–72. Springer International Publishing, Cham (2024). https://doi.org/10.1007/978-3- 031-61874-1_3
-
[7]
Psychological bulletin76(5), 378 (1971)
Fleiss, J.L.: Measuring nominal scale agreement among many raters. Psychological bulletin76(5), 378 (1971)
1971
-
[8]
Gemini Team Google: Gemini: A family of highly capable multimodal models (2024),https://arxiv.org/abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Guerino, G., Rodrigues, L., Capeleti, B., Mello, R.F., Freire, A., Zaina, L.: Can gpt-4o evaluate usability like human experts? a comparative study on issue iden- tification in heuristic evaluation. In: Human-Computer Interaction – INTERACT 2025:20thIFIPTC13InternationalConference,BeloHorizonte,Brazil,September 8–12, 2025, Proceedings, Part III. p. 381–40...
-
[10]
British Journal of Mathematical and Statistical Psychology61(1), 29–48 (2008)
Gwet, K.L.: Computing inter-rater reliability and its variance in the presence of high agreement. British Journal of Mathematical and Statistical Psychology61(1), 29–48 (2008). https://doi.org/https://doi.org/10.1348/000711006X126600
-
[11]
Hewett, T.T., Baecker, R., Card, S., Carey, T., Gasen, J., Mantei, M., Perlman, G., Strong, G., Verplank, W.: Human-Computer Interaction, pp. 5–29. ACM, New York, NY, USA (1992)
1992
-
[12]
ISO/IEC/IEEE 9241-11:2018(E) (2018)
International Organization for Standardization: ISO/IEC/IEEE International Standard - Ergonomics of human-system interaction – Part 11: Usability: Defi- nitions and concepts. ISO/IEC/IEEE 9241-11:2018(E) (2018)
2018
-
[13]
Jiang, J., Wang, F., Shen, J., Kim, S., Kim, S.: A survey on large language mod- els for code generation. ACM Trans. Softw. Eng. Methodol.35(2) (Jan 2026). https://doi.org/10.1145/3747588,https://doi.org/10.1145/3747588
-
[14]
Konstantinidis, M., Le, L.W., Gao, X.: An empirical comparative assessment of inter-rater agreement of binary outcomes and multiple raters. Symmetry14(2) (2022). https://doi.org/10.3390/sym14020262
- [15]
-
[16]
Leclercq, T., Abbasi, E.K., Dumas, B., Remiche, M.A., Heymans, P.: Essential expectations of users of web configurators: An empirical survey. Proc. ACM Hum.- Comput. Interact.6(EICS) (Jun 2022). https://doi.org/10.1145/3534519
-
[17]
In: Joint Proceedings of the ACM IUI 2018 Workshops (2018), https://ceur-ws.org/Vol-2068/wii1.pdf
Leclercq, T., Cordy, M., Dumas, B., Heymans, P.: On studying bad practices in configuration uis. In: Joint Proceedings of the ACM IUI 2018 Workshops (2018), https://ceur-ws.org/Vol-2068/wii1.pdf
2018
-
[18]
In: Felfernig, A., Hotz, L., Bagley, C., Ti- ihonen, J
Leitner, G., Felfernig, A., Blazek, P., Reinfrank, F., Ninaus, G.: Chapter 8 - user interfaces for configuration environments. In: Felfernig, A., Hotz, L., Bagley, C., Ti- ihonen, J. (eds.) Knowledge-Based Configuration, pp. 89–106. Morgan Kaufmann, Boston (2014). https://doi.org/10.1016/B978-0-12-415817-7.00008-6
-
[19]
Lubos, S., Felfernig, A., Garber, D., Le, V.M., Tran, T.N.T.: Towards llm-based usabilityanalysisforrecommenderuserinterfaces.In:Proceedingsofthe12thJoint Workshop on Interfaces and Human Decision Making for Recommender Systems (IntRS 2025) (2025),https://ceur-ws.org/Vol-4027/paper7.pdf
2025
-
[20]
Lubos, S., Felfernig, A., Garber, D., Leitner, G., Schwazer, J., Henrich, M.: Inves- tigating multimodal large language models to support usability evaluation (2026), https://arxiv.org/abs/2508.16165
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
configurator-database.com/, accessed: 04 December 2025 20 S
cyLEDGE Media: Configurator database (2022),https://www. configurator-database.com/, accessed: 04 December 2025 20 S. Lubos et al
2022
-
[22]
In: Soares, M.M., Rosenzweig, E., Marcus, A
Namoun, A., Alrehaili, A., Tufail, A.: A review of automated website usability evaluation tools: Research issues and challenges. In: Soares, M.M., Rosenzweig, E., Marcus, A. (eds.) Design, User Experience, and Usability: UX Research and Design. pp. 292–311. Springer International Publishing, Cham (2021)
2021
-
[23]
In: Proceed- ings of the SIGCHI Conference on Human Factors in Computing Systems
Nielsen, J.: Enhancing the explanatory power of usability heuristics. In: Proceed- ings of the SIGCHI Conference on Human Factors in Computing Systems. p. 152–158. CHI ’94, Association for Computing Machinery, New York, NY, USA (1994). https://doi.org/10.1145/191666.191729
-
[24]
Perin, E., Trentin, A., Forza, C.: The effect of sales configurator capabilities on the valueperceivedbythecustomerthroughthecustomizationprocess.In:Proceedings of the 15th International Configuration Workshop (2013),https://ceur-ws.org/ Vol-1128/paper10.pdf
2013
-
[25]
64 Sigma Jahan, Saurabh Singh Rajput, Tushar Sharma, and Mohammad Masudur Rahman
Pourasad, A.E., Maalej, W.: Does GenAI Make Usability Testing Obsolete? . In: 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE).pp.675–675.IEEEComputerSociety,LosAlamitos,CA,USA(May2025). https://doi.org/10.1109/ICSE55347.2025.00138
-
[26]
In: Proceedings of the 27th IEEE/ACM International Conference on Automated Software Engineering
Rabiser, R., Grünbacher, P., Lehofer, M.: A qualitative study on user guid- ance capabilities in product configuration tools. In: Proceedings of the 27th IEEE/ACM International Conference on Automated Software Engineering. p. 110–119. ASE ’12, Association for Computing Machinery, New York, NY, USA (2012). https://doi.org/10.1145/2351676.2351693
-
[27]
Reynolds, L., McDonell, K.: Prompt programming for large language models: Be- yond the few-shot paradigm. In: Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems. CHI EA ’21, Association for Computing Machinery, New York, NY, USA (2021). https://doi.org/10.1145/3411763.3451760
-
[28]
In: Proceedings of the International Conference on Economic, Technical and Organisational aspects of Product Configuration Systems (PETO 2004), Lyngby, Denmark
Rogoll, T., Piller, F.: Product configuration from the customer’s perspective: A comparison of configuration systems in the apparel industry. In: Proceedings of the International Conference on Economic, Technical and Organisational aspects of Product Configuration Systems (PETO 2004), Lyngby, Denmark. pp. 179–199 (2004)
2004
-
[29]
In: Proceedings of the 34th International Conference on Software Engineering
Siegmund, N., Kolesnikov, S.S., Kästner, C., Apel, S., Batory, D., Rosenmüller, M., Saake, G.:Predicting performance via automated feature-interaction detection. In: Proceedings of the 34th International Conference on Software Engineering. p. 167–177. ICSE ’12, IEEE Press (2012)
2012
-
[30]
Thüm, T., Apel, S., Kästner, C., Schaefer, I., Saake, G.: A classification and survey of analysis strategies for software product lines. ACM Comput. Surv.47(1) (Jun 2014). https://doi.org/10.1145/2580950
-
[31]
Computers in Industry64(4), 436–447 (2013)
Trentin, A., Perin, E., Forza, C.: Sales configurator capabili- ties to avoid the product variety paradox: Construct develop- ment and validation. Computers in Industry64(4), 436–447 (2013). https://doi.org/https://doi.org/10.1016/j.compind.2013.02.006
-
[32]
Family medicine37, 360–3 (06 2005)
Viera, A., Garrett, J.: Understanding interobserver agreement: The kappa statistic. Family medicine37, 360–3 (06 2005)
2005
-
[33]
A survey on multimodal large language models , volume=
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on mul- timodal large language models. National Science Review11(12) (Nov 2024). https://doi.org/10.1093/nsr/nwae403
-
[34]
Yoon, J., Feldt, R., Yoo, S.: Intent-driven mobile gui testing with au- tonomous large language model agents. In: 2024 IEEE Conference on Software Testing, Verification and Validation (ICST). pp. 129–139 (2024). https://doi.org/10.1109/ICST60714.2024.00020 Usability Analysis of Configurator UIs with Multimodal LLMs 21
-
[35]
Zhong, R., McDonald, D.W., Hsieh, G.: Synthetic heuristic evaluation: A compar- ison between ai- and human-powered usability evaluation (2025),https://arxiv. org/abs/2507.02306
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.