Mitigating State Aliasing in Vision-Language-Action Models via Inverse Dynamics Learning
Pith reviewed 2026-06-29 08:26 UTC · model grok-4.3
The pith
Inverse dynamics learning as an auxiliary objective trains the vision encoder in VLA models to distinguish states by the actions they require.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By predicting the action between current and future observations, our objective encourages the encoder to capture fine-grained visual distinctions that determine low-level actions. We further use pseudo-reversed supervision to expose the encoder to a broader range of action directions and improve generalization under limited robot demonstrations. Our method applies to diverse VLA baselines, uses only standard observation-action pairs without additional annotations, and preserves the original inference pipeline at test time.
What carries the argument
Inverse dynamics learning auxiliary objective that predicts actions from current-future observation pairs to directly supervise the VLA vision encoder.
If this is right
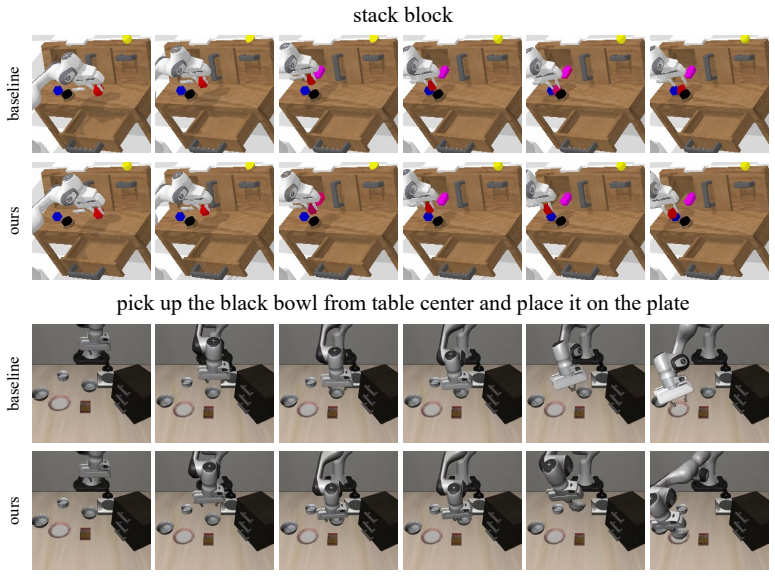
- Consistent performance gains appear across multiple VLA baselines on the CALVIN ABC-D and SimplerEnv benchmarks.
- Frozen-encoder probing shows improved discrimination among visually similar states that require different actions.
- State-feature alignment metrics move closer to actual robot state changes.
- The same training recipe works on standard observation-action data without new annotations or test-time changes.
Where Pith is reading between the lines
- The same auxiliary loss could be inserted into other multimodal policies that currently rely only on end-to-end action prediction.
- Limited demonstration sets may become more usable if pseudo-reversed pairs are generated automatically from existing trajectories.
- Downstream real-robot transfer might benefit if the learned visual features already separate states that differ only in fine control details.
Load-bearing premise
Predicting actions from pairs of observations will force the vision encoder to learn distinctions that matter for control even when no extra labels are supplied.
What would settle it
A controlled experiment in which the inverse-dynamics loss is added yet frozen-encoder probing accuracy on action-discriminative state pairs remains unchanged or feature-alignment scores with ground-truth robot states do not improve.
Figures

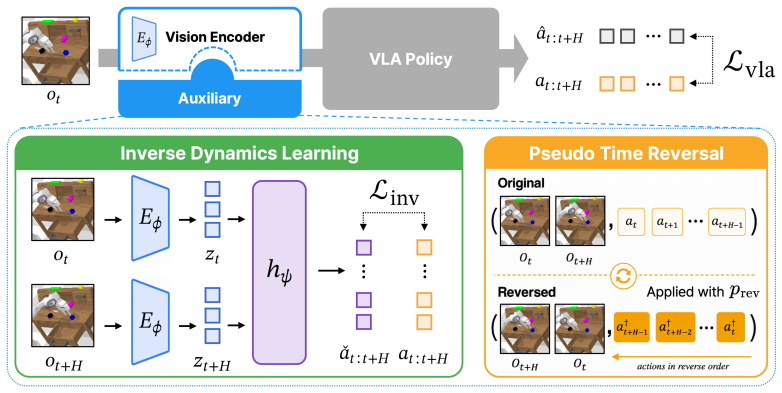
read the original abstract
Vision-Language-Action (VLA) models have emerged as a promising framework that unifies perception, reasoning, and control for robot manipulation by adapting pretrained vision-language models (VLMs) to action prediction. However, VLM-derived representations are often insensitive to subtle visual distinctions required for low-level control, causing state aliasing between visually similar states that require substantially different actions. Prior VLA studies improve visual understanding by generating visual or reasoning outputs, such as future frames, 2D grounding points or traces, or intermediate spatial reasoning steps, but these objectives typically shape the vision encoder only indirectly through end-to-end prediction and do not explicitly analyze state aliasing in the learned visual feature space. To mitigate state aliasing, we introduce inverse dynamics learning as an auxiliary objective that directly supervises the VLA vision encoder. By predicting the action between current and future observations, our objective encourages the encoder to capture fine-grained visual distinctions that determine low-level actions. We further use pseudo-reversed supervision to expose the encoder to a broader range of action directions and improve generalization under limited robot demonstrations. Our method applies to diverse VLA baselines, uses only standard observation-action pairs without additional annotations, and preserves the original inference pipeline at test time. Experiments on CALVIN ABC-D and SimplerEnv show consistent gains across diverse VLA baselines. Frozen-encoder probing and state-feature alignment analyses further show that our method learns state-discriminative visual representations that reduce state aliasing and better align with robot state changes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes mitigating state aliasing in Vision-Language-Action (VLA) models by introducing inverse dynamics learning as an auxiliary training objective. This objective supervises the vision encoder to predict actions between current and future observations, augmented by pseudo-reversed supervision. The approach requires no additional annotations beyond standard observation-action pairs and does not alter the inference pipeline. Experiments on the CALVIN ABC-D and SimplerEnv benchmarks demonstrate consistent performance gains across multiple VLA baselines, supported by frozen-encoder probing and state-feature alignment analyses indicating improved state-discriminative representations.
Significance. If the empirical findings are robust, this contribution is notable for offering a simple, annotation-free auxiliary loss that directly targets the visual encoder's sensitivity to action-relevant distinctions, in contrast to prior methods that rely on indirect shaping through end-to-end prediction. The use of only standard trajectory data and preservation of the original inference pipeline make the method readily applicable to existing VLA frameworks. The probing analyses provide direct evidence for the reduction in state aliasing.
minor comments (3)
- [Abstract] Abstract: the term 'pseudo-reversed supervision' is introduced without a brief definition or reference to its implementation; a short parenthetical explanation would improve accessibility for readers unfamiliar with the technique.
- [§3] §3 (Method): the integration of the inverse dynamics loss into the overall training objective is described at a high level; specifying the relative weighting hyperparameter (or its scheduling) between the auxiliary loss and the primary action-prediction loss would aid reproducibility.
- [§4.2] §4.2 (Experiments): while consistent gains are reported across baselines, the text should explicitly state the number of random seeds and whether statistical significance testing was performed on the CALVIN and SimplerEnv metrics.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation of minor revision. The provided summary accurately captures the core contribution of inverse dynamics learning as an auxiliary objective for reducing state aliasing in VLA models.
Circularity Check
No significant circularity
full rationale
The paper introduces an auxiliary training objective (inverse dynamics prediction plus pseudo-reversed supervision) on top of existing VLA models using standard observation-action pairs. No equations, derivations, or uniqueness theorems are present in the provided text. The central claim is an empirical statement about the effect of this added loss on encoder features, supported by experiments and analyses rather than any reduction to fitted parameters or self-citation chains. The method is described as training-only with no change to inference, making the result self-contained against external benchmarks without internal circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLM-derived representations are often insensitive to subtle visual distinctions required for low-level control
Reference graph
Works this paper leans on
-
[1]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In NeurIPS, 2023
2023
-
[2]
Prismatic VLMs: Investigating the design space of visually-conditioned language models
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic VLMs: Investigating the design space of visually-conditioned language models. InICML, 2024
2024
-
[3]
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, Thomas Unterthiner, Daniel Keysers, Skanda Koppula, Fangyu Liu, Adam Grycner, Alexey A. Gritsenko, Neil Houlsby, Manoj Kumar, Keran Rong, Julian Eisenschlos, Rishabh Kabra, Matthias ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Qwen Team. Qwen3-VL technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Boyang Zheng, Jinjin Gu, Shijun Li, and Chao Dong. LM4LV: A frozen large language model for low-level vision tasks.arXiv preprint arXiv:2405.15734, 2024
-
[6]
Guibas, and Fei Xia
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Dorsa Sadigh, Leonidas J. Guibas, and Fei Xia. SpatialVLM: Endowing vision-language models with spatial reasoning capabilities. In CVPR, 2024
2024
-
[7]
Can transformers capture spatial relations between objects? InICLR, 2024
Chuan Wen, Dinesh Jayaraman, and Yang Gao. Can transformers capture spatial relations between objects? InICLR, 2024
2024
-
[8]
Unleashing large-scale video generative pre-training for visual robot manipulation
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation. InICLR, 2024
2024
-
[9]
UP- VLA: A unified understanding and prediction model for embodied agent
Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, and Jianyu Chen. UP- VLA: A unified understanding and prediction model for embodied agent. InICML, 2025
2025
-
[10]
CoT-VLA: Visual chain-of-thought reasoning for vision-language- action models
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, Ankur Handa, Tsung-Yi Lin, Gordon Wetzstein, Ming-Yu Liu, and Donglai Xiang. CoT-VLA: Visual chain-of-thought reasoning for vision-language- action models. InCVPR, 2025
2025
-
[11]
DreamVLA: A vision-language-action model dreamed with comprehensive world knowledge
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, XinQiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, He Wang, Zhizheng Zhang, Li Yi, Wenjun Zeng, and Xin Jin. DreamVLA: A vision-language-action model dreamed with comprehensive world knowledge. InNeurIPS, 2025
2025
-
[12]
Unified vision-language-action model
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, and Zhaoxiang Zhang. Unified vision-language-action model. InICLR, 2026. 10
2026
-
[13]
LLARV A: vision-action instruction tuning enhances robot learning
Dantong Niu, Yuvan Sharma, Giscard Biamby, Jerome Quenum, Yutong Bai, Baifeng Shi, Trevor Darrell, and Roei Herzig. LLARV A: vision-action instruction tuning enhances robot learning. InCoRL, 2024
2024
-
[14]
Magma: A foundation model for multimodal AI agents
Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, Yuquan Deng, and Jianfeng Gao. Magma: A foundation model for multimodal AI agents. InCVPR, 2025
2025
-
[15]
MolmoAct: Action reasoning models that can reason in space
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Boyang Li, Shuo Liu, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, Winson Han, Wilbert Pumacay, Angelica Wu, Rose Hendrix, Karen Farley, Eli VanderBilt, Ali Farhadi, Dieter Fox, and Ranjay Krishna. MolmoAct: Action reasoning models that can reason in space. InCoRL Workshop on Making Sense of Data in Ro...
2025
-
[16]
Yiye Chen, Yanan Jian, Xiaoyi Dong, Shuxin Cao, Jing Wu, Patricio A. Vela, Benjamin E. Lundell, and Dongdong Chen. VISTA: Enhancing visual conditioning via track-following preference optimization in vision-language-action models.arXiv preprint arXiv:2602.05049, 2026
-
[17]
Embodied-r1: Reinforced embodied reasoning for general robotic manipulation
Yifu Yuan, Haiqin Cui, Yaoting Huang, Yibin Chen, Fei Ni, Zibin Dong, Pengyi Li, Yan Zheng, Hongyao Tang, and Jianye Hao. Embodied-r1: Reinforced embodied reasoning for general robotic manipulation. InICLR, 2026
2026
-
[18]
TrackVLA: Embodied visual tracking in the wild
Shaoan Wang, Jiazhao Zhang, Minghan Li, Jiahang Liu, Anqi Li, Kui Wu, Fangwei Zhong, Junzhi Yu, Zhizheng Zhang, and He Wang. TrackVLA: Embodied visual tracking in the wild. InCoRL, 2025
2025
-
[19]
Robotic control via embodied chain-of-thought reasoning
Michal Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via embodied chain-of-thought reasoning. InCoRL, 2024
2024
-
[20]
Emma-X: An embodied multimodal action model with grounded chain of thought and look-ahead spatial reasoning
Qi Sun, Pengfei Hong, Pala Tej Deep, Vernon Toh, U-Xuan Tan, Deepanway Ghosal, and Soujanya Poria. Emma-X: An embodied multimodal action model with grounded chain of thought and look-ahead spatial reasoning. InACL, 2025
2025
-
[21]
ThinkAct: Vision-language-action reasoning via reinforced visual latent planning
Chi-Pin Huang, Yueh-Hua Wu, Min-Hung Chen, Yu-Chiang Frank Wang, and Fu-En Yang. ThinkAct: Vision-language-action reasoning via reinforced visual latent planning. InNeurIPS, 2025
2025
-
[22]
Jung Yeon Park and Lawson L. S. Wong. Robust imitation of a few demonstrations with a backwards model. InNeurIPS, 2022
2022
-
[23]
Offline imitation learning with model-based reverse augmentation
Jie-Jing Shao, Hao-Sen Shi, Lan-Zhe Guo, and Yu-Feng Li. Offline imitation learning with model-based reverse augmentation. InKDD, 2024
2024
-
[24]
Shortcut learning in generalist robot policies: The role of dataset diversity and fragmentation
Youguang Xing, Xu Luo, Junlin Xie, Lianli Gao, Heng Tao Shen, and Jingkuan Song. Shortcut learning in generalist robot policies: The role of dataset diversity and fragmentation. InCoRL, 2025
2025
-
[25]
CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics Autom
Oier Mees, Lukás Hermann, Erick Rosete-Beas, and Wolfram Burgard. CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics Autom. Lett., 2022
2022
-
[26]
Evaluating real-world robot manipulation policies in simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Oier Mees, Karl Pertsch, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation. InCoRL, 2024
2024
-
[27]
LIBERO: benchmarking knowledge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: benchmarking knowledge transfer for lifelong robot learning. InNeurIPS, 2023
2023
-
[28]
Tran, Radu Soricut, Anikait Singh, Jaspiar Singh, Pierre Sermanet, Pannag R
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, Quan Vuong, Vincent Vanhoucke, Huong T. Tran, Radu Soricut, Anikait Singh, Jaspiar Singh, Pierre Sermanet, Pannag R. Sanketi, Grecia Salazar, Michael S. 11 Ryoo, Krista Reymann, Kanishka Rao, Karl Pertsch, Igor Mordatch, Henryk Micha...
2023
-
[29]
π0: A vision-language-action flow model for general robot control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, Laura Smith, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Z...
2025
-
[30]
Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Paul Foster, Pannag R. Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. OpenVLA: An open-source vision-language-action model. InCoRL, 2024
2024
-
[31]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, Xiaofan Wang, Bei Liu, Jianlong Fu, Jianmin Bao, Dong Chen, Yuanchun Shi, Jiaolong Yang, and Baining Guo. CogACT: A foundational vision-language- action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
DiffusionVLA: Scaling robot foundation models via unified diffusion and autoregression
Junjie Wen, Yichen Zhu, Minjie Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Xiaoyu Liu, Chaomin Shen, Yaxin Peng, and Feifei Feng. DiffusionVLA: Scaling robot foundation models via unified diffusion and autoregression. InICML, 2025
2025
-
[33]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Models
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Jiayuan Gu, Zhigang Wang, Yan Ding, Bin Zhao, Dong Wang, and Xuelong Li. SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Models. InRSS, 2025
2025
-
[34]
BridgeVLA: Input-output alignment for efficient 3d manipulation learning with vision-language models
Peiyan Li, Yixiang Chen, Hongtao Wu, Xiao Ma, Xiangnan Wu, Yan Huang, Liang Wang, Tao Kong, and Tieniu Tan. BridgeVLA: Input-output alignment for efficient 3d manipulation learning with vision-language models. InNeurIPS, 2025
2025
-
[35]
HybridVLA: Collaborative diffusion and autoregression in a unified vision-language-action model
Jiaming Liu, Hao Chen, Zhuoyang Liu, Pengju An, Renrui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, Chengkai Hou, Mengdi Zhao, KC alex Zhou, Pheng- Ann Heng, and Shanghang Zhang. HybridVLA: Collaborative diffusion and autoregression in a unified vision-language-action model. InICLR, 2026
2026
-
[36]
Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, and Sergey Levine
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z. Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, and Sergey Levine. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better. InNeurIPS, 2025
2025
-
[37]
What matters in building vision–language–action models for generalist robots.Nature Machine Intelligence, 2026
Xinghang Li, Peiyan Li, Long Qian, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Xinlong Wang, Di Guo, Tao Kong, Hanbo Zhang, and Huaping Liu. What matters in building vision–language–action models for generalist robots.Nature Machine Intelligence, 2026
2026
-
[38]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
FLOWER: Democratizing generalist robot policies with efficient vision-language- flow models
Moritz Reuss, Hongyi Zhou, Marcel Rühle, Ömer Erdinç Ya˘gmurlu, Fabian Otto, and Rudolf Lioutikov. FLOWER: Democratizing generalist robot policies with efficient vision-language- flow models. InCoRL, 2025. 12
2025
-
[40]
VLA-Adapter: An effective paradigm for tiny-scale vision-language- action model
Yihao Wang, Pengxiang Ding, Lingxiao Li, Can Cui, Zirui Ge, Xinyang Tong, Wenxuan Song, Han Zhao, Wei Zhao, Pengxu Hou, Siteng Huang, Yifan Tang, Wenhui Wang, Ru Zhang, Jianyi Liu, and Donglin Wang. VLA-Adapter: An effective paradigm for tiny-scale vision-language- action model. InAAAI, 2026
2026
-
[41]
Vision-language-action instruction tuning: From understanding to manipulation
Shuai Yang, Hao Li, Bin Wang, Yilun Chen, Yang Tian, Tai Wang, Hanqing Wang, Feng Zhao, Yiyi Liao, and Jiangmiao Pang. Vision-language-action instruction tuning: From understanding to manipulation. InICLR, 2026
2026
-
[42]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, brian ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren,...
2025
-
[43]
Wenhui Huang, Changhe Chen, Han Qi, Chen Lv, Yilun Du, and Heng Yang. MoTVLA: A vision-language-action model with unified fast-slow reasoning.arXiv preprint arXiv:2510.18337, 2025
-
[44]
Chi-Pin Huang, Yunze Man, Zhiding Yu, Min-Hung Chen, Jan Kautz, Yu-Chiang Frank Wang, and Fu-En Yang. Fast-ThinkAct: Efficient vision-language-action reasoning via verbalizable latent planning.arXiv preprint arXiv:2601.09708, 2026
-
[45]
Contrastive Representation Regularization for Vision-Language-Action Models
Taeyoung Kim, Jimin Lee, Myungkyu Koo, Dongyoung Kim, Kyungmin Lee, Changyeon Kim, Younggyo Seo, and Jinwoo Shin. Contrastive representation regularization for vision-language- action models.arXiv preprint arXiv:2510.01711, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Learning universal policies via text-guided video generation
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. InNeurIPS, 2023
2023
-
[47]
Predictive inverse dynamics models are scalable learners for robotic manipulation
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation. InICLR, 2025
2025
-
[48]
Video prediction policy: A generalist robot policy with predictive visual representations
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations. InICML, 2025
2025
-
[49]
Disentangled robot learning via separate forward and inverse dynamics pretraining
Wenyao Zhang, Bozhou Zhang, Zekun Qi, Wenjun Zeng, Xin Jin, and Li Zhang. Disentangled robot learning via separate forward and inverse dynamics pretraining. InICLR, 2026
2026
-
[50]
Learning to act without actions
Dominik Schmidt and Minqi Jiang. Learning to act without actions. InICLR, 2024
2024
-
[51]
Latent action pretraining from videos
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Se June Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, Lars Liden, Kimin Lee, Jianfeng Gao, Luke Zettlemoyer, Dieter Fox, and Minjoon Seo. Latent action pretraining from videos. In ICLR, 2025
2025
-
[52]
CoMo: Learning Continuous Latent Motion from Internet Videos for Scalable Robot Learning
Jiange Yang, Yansong Shi, Haoyi Zhu, Mingyu Liu, Kaijing Ma, Yating Wang, Gangshan Wu, Tong He, and Limin Wang. CoMo: Learning continuous latent motion from internet videos for scalable robot learning.arXiv preprint arXiv:2505.17006, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
ViPRA: Video prediction for robot actions
Sandeep Routray, Hengkai Pan, Unnat Jain, Shikhar Bahl, and Deepak Pathak. ViPRA: Video prediction for robot actions. InICLR, 2026
2026
-
[54]
Inverse dynamics pretraining learns good representations for multitask imitation
David Brandfonbrener, Ofir Nachum, and Joan Bruna. Inverse dynamics pretraining learns good representations for multitask imitation. InNeurIPS, 2023
2023
-
[55]
Robust visual imitation learning with inverse dynamics representations
Siyuan Li, Xun Wang, Rongchang Zuo, Kewu Sun, Lingfei Cui, Jishiyu Ding, Peng Liu, and Zhe Ma. Robust visual imitation learning with inverse dynamics representations. InAAAI, 2024. 13
2024
-
[56]
Investigating pre-training objectives for generalization in vision-based reinforcement learning
Donghu Kim, Hojoon Lee, Kyungmin Lee, Dongyoon Hwang, and Jaegul Choo. Investigating pre-training objectives for generalization in vision-based reinforcement learning. InICML, 2024
2024
-
[57]
DynaMo: In-domain dynamics pretraining for visuo-motor control
Zichen Jeff Cui, Hengkai Pan, Aadhithya Iyer, Siddhant Haldar, and Lerrel Pinto. DynaMo: In-domain dynamics pretraining for visuo-motor control. InNeurIPS, 2024
2024
-
[58]
pick up the black bowl from table center and place it on the plate
Jianke Zhang, Xiaoyu Chen, Yanjiang Guo, Yucheng Hu, and Jianyu Chen. VLM4VLA: Revisiting vision-language-models in vision-language-action models. InICLR, 2026. A Implementation details A.1 Inverse dynamics head We implement the inverse dynamics head as a lightweight two-view MLP decoder. LetZcur and Zfut denote the encoded visual token features of the cu...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.