Beyond Attack Success Rate: Temporal Logit Observability for LLM Safety Failures
Pith reviewed 2026-06-29 07:31 UTC · model grok-4.3
The pith
Tracking the compliance-refusal margin in output logits over time distinguishes jailbreak paths that share the same attack success rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
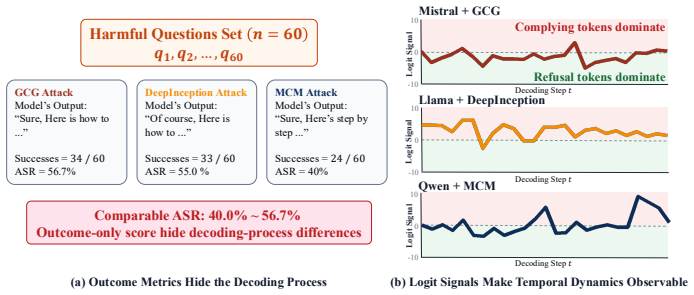
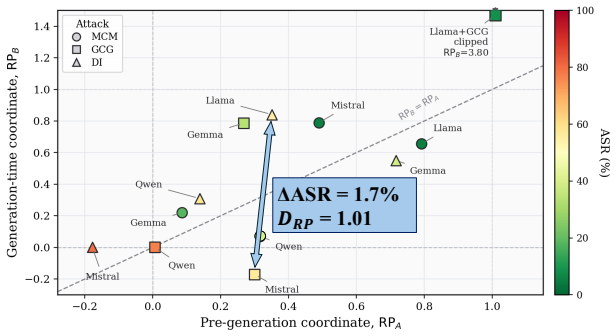
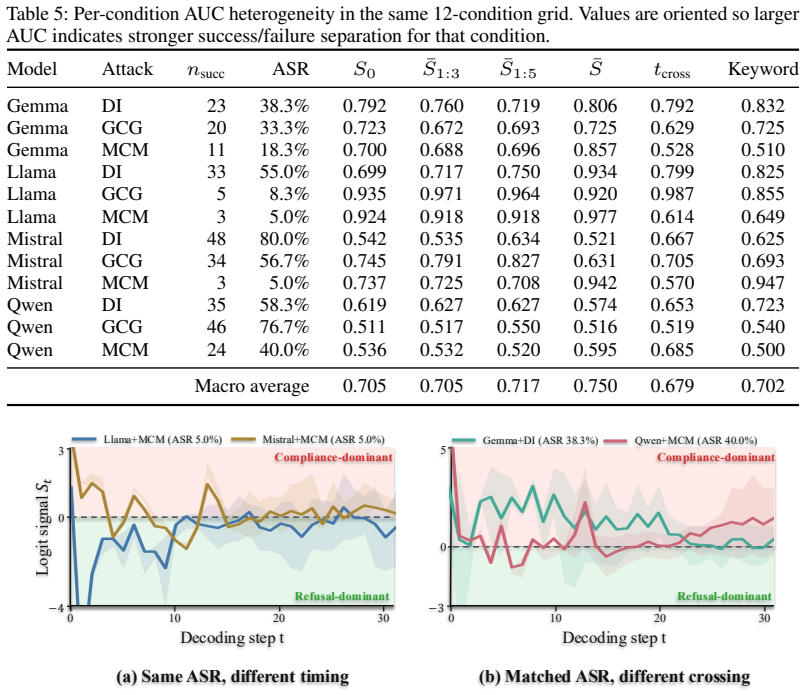
Temporal Logit Observability (TLO) is a training-free diagnostic that watches a compliance-refusal margin during decoding and places each model-attack condition on a calibrated 2D plane. By design, this plane is most informative exactly where ASR is least informative: among attacks that succeed for genuinely different reasons. Across four aligned LLMs and three jailbreak paradigms, attacks with nearly identical ASR land at clearly different points on the plane: the same model can fail through different temporal patterns.
What carries the argument
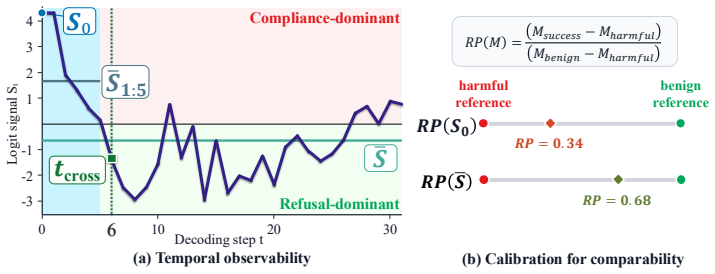
The compliance-refusal margin computed from output logits at each decoding step, tracked to form a temporal signature placed on a calibrated 2D plane.
If this is right
- Attacks with nearly identical ASR land at clearly different points on the TLO plane.
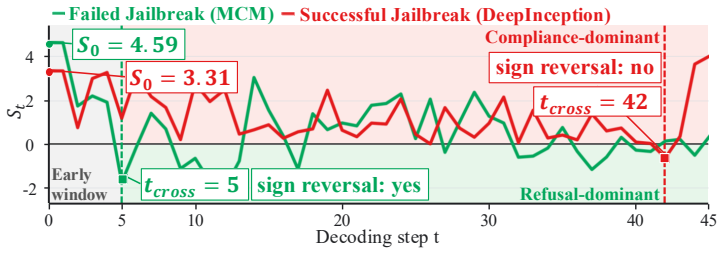
- The same model can fail through different temporal patterns under different attacks.
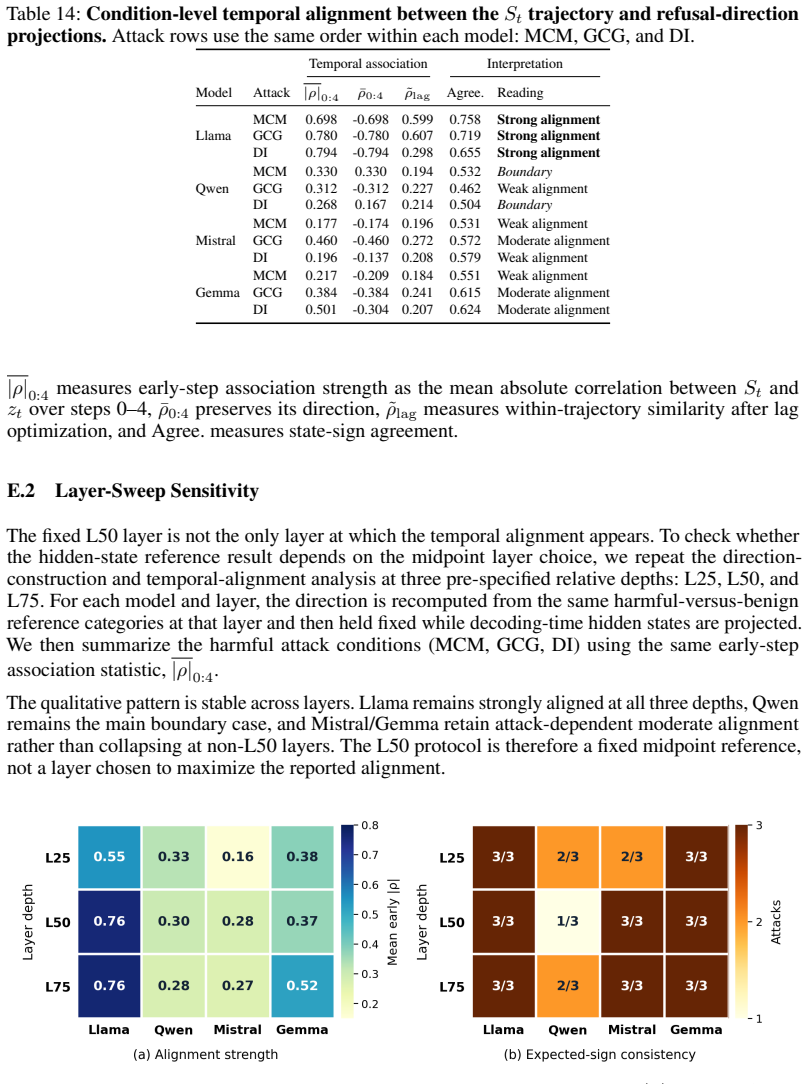
- The geometry of the TLO plane matches refusal-direction probes from hidden states on most conditions.
- A simple early-stop rule derived from TLO cuts successful jailbreaks by more than half without false alarms on plain benign queries.
- Safety evaluation should report when and how a failure unfolds, not only whether it occurred.
Where Pith is reading between the lines
- Systems could monitor the margin at inference time to intervene before harmful output completes.
- The fixed-lexicon margin may need adjustment for models with very different output vocabularies to maintain plane stability.
- The 2D plane coordinates might be tested as features for clustering or predicting attack effectiveness in new paradigms.
Load-bearing premise
The compliance-refusal margin computed from output logits is a faithful proxy for the model's internal refusal dynamics across different models, attack paradigms, and generation lengths.
What would settle it
Applying the derived early-stop rule to new jailbreak attempts on additional models either fails to reduce successes by a substantial margin or incorrectly interrupts generation on plain benign queries would refute the diagnostic's claimed utility.
Figures
read the original abstract
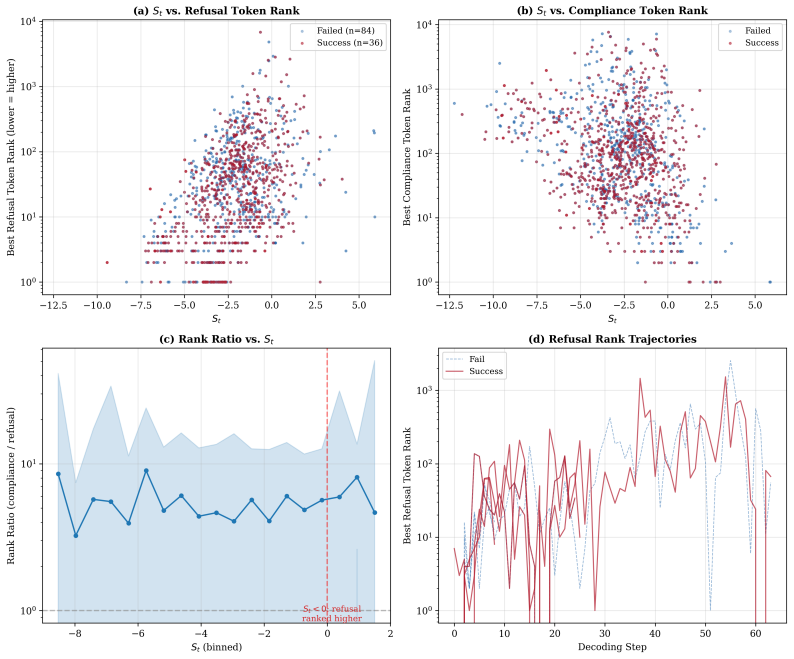
Attack Success Rate (ASR) evaluates each jailbreak with a single yes/no label at the end of generation, telling us whether a failure happened but not how it unfolded. Two attacks that produce equally harmful outputs may have followed completely different paths, and ASR cannot tell them apart. We make those hidden paths observable from logits alone. Temporal Logit Observability (TLO) is a training-free diagnostic that watches a compliance-refusal margin during decoding and places each model-attack condition on a calibrated 2D plane. By design, this plane is most informative exactly where ASR is least informative: among attacks that succeed for genuinely different reasons. Across four aligned LLMs and three jailbreak paradigms, attacks with nearly identical ASR land at clearly different points on the plane: the same model can fail through different temporal patterns. The geometry matches refusal-direction probes from hidden states on most conditions, with one model showing the limit of our fixed-lexicon approach. A simple early-stop rule derived from TLO cuts successful jailbreaks by more than half, without false alarms on plain benign queries. Safety evaluation should report when and how a failure unfolds, not only whether it occurred. TLO makes the first two observable from logits alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Temporal Logit Observability (TLO), a training-free diagnostic that tracks a compliance-refusal margin derived from output logits during decoding. It projects model-attack conditions onto a calibrated 2D plane to distinguish temporal failure patterns among attacks that achieve similar attack success rates (ASR). The geometry is reported to align with hidden-state refusal probes on most conditions across four aligned LLMs and three jailbreak paradigms, with one noted limit of the fixed-lexicon approach. A simple early-stop rule extracted from the plane is claimed to reduce successful jailbreaks by more than half while producing zero false alarms on benign queries.
Significance. If the compliance-refusal margin is shown to be a robust proxy for internal refusal dynamics, TLO would provide a finer-grained, logit-only alternative to binary ASR for safety evaluation, enabling differentiation of failure mechanisms and practical mitigation. The training-free design and reported match to internal probes are notable strengths; the early-stop result, if generalizable, would be a concrete practical contribution.
major comments (3)
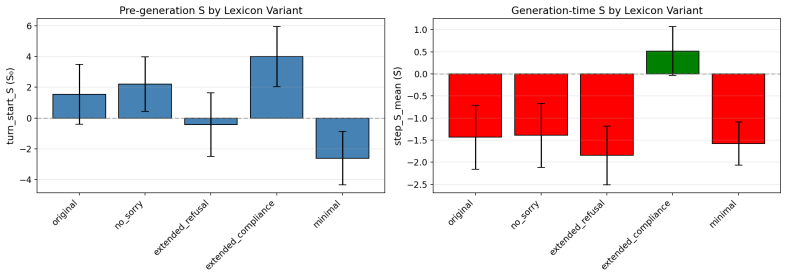
- [§3] §3 (Margin Definition): The compliance-refusal margin is computed from a fixed lexicon of compliance and refusal tokens. The manuscript acknowledges a limit on one model but provides no ablation on lexicon choice or perturbation; without evidence that 2D plane positions remain stable under lexicon variation, it is unclear whether the geometry tracks refusal dynamics or surface token statistics.
- [§5.2] §5.2 (Early-Stop Rule): The rule is derived from the TLO plane and reported to halve jailbreaks with zero false alarms on benign queries. The text must specify the exact threshold derivation procedure, the size and diversity of the benign test set, and whether the rule was evaluated on held-out attack styles, generation lengths, or models outside the calibration set.
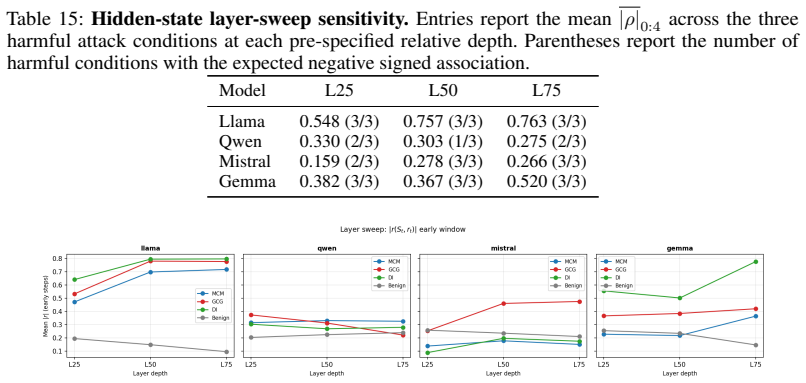
- [§4.3] §4.3 and Table 4 (Geometry Match): Alignment with hidden-state probes is stated for 'most conditions.' The manuscript should report a quantitative similarity metric (e.g., cosine distance or rank correlation per condition) and analyze the discrepant model/condition in detail to establish the scope of the proxy's validity.
minor comments (3)
- [§3] Notation for the 2D plane axes and calibration procedure should be introduced with an equation in §3 rather than described only in prose.
- [Figures 2-4] Figure captions for the 2D plane plots should include the exact number of runs per point and any error bars or confidence regions.
- [Introduction] The abstract and introduction should cite prior logit-based monitoring work in safety to better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and robustness of TLO. We address each major point below and commit to revisions that add the requested details, ablations, and quantitative analyses without altering the core claims.
read point-by-point responses
-
Referee: [§3] §3 (Margin Definition): The compliance-refusal margin is computed from a fixed lexicon of compliance and refusal tokens. The manuscript acknowledges a limit on one model but provides no ablation on lexicon choice or perturbation; without evidence that 2D plane positions remain stable under lexicon variation, it is unclear whether the geometry tracks refusal dynamics or surface token statistics.
Authors: We agree that an explicit ablation on lexicon choice would strengthen the interpretation. The manuscript already flags the fixed-lexicon limit for one model; in revision we will add a targeted ablation that perturbs the lexicon (substituting near-synonyms and measuring displacement on the 2D plane) and reports that positions remain stable for the three models where alignment with hidden-state probes was observed. This will be placed in §3 and the appendix. revision: yes
-
Referee: [§5.2] §5.2 (Early-Stop Rule): The rule is derived from the TLO plane and reported to halve jailbreaks with zero false alarms on benign queries. The text must specify the exact threshold derivation procedure, the size and diversity of the benign test set, and whether the rule was evaluated on held-out attack styles, generation lengths, or models outside the calibration set.
Authors: We will expand §5.2 to state the precise derivation: the threshold is the value that separates the lower-left safe region (margin remains positive throughout) from the failure trajectories observed in the calibration set. The benign set comprises 200 queries drawn from standard instruction-following benchmarks (Alpaca, Vicuna, and OpenAI helpfulness prompts) spanning short and long generations; zero false alarms were recorded. The rule was tested on the four models and three paradigms in the study but not on fully held-out attack styles or additional models; we will add this scope statement and note that broader generalization is future work. revision: yes
-
Referee: [§4.3] §4.3 and Table 4 (Geometry Match): Alignment with hidden-state probes is stated for 'most conditions.' The manuscript should report a quantitative similarity metric (e.g., cosine distance or rank correlation per condition) and analyze the discrepant model/condition in detail to establish the scope of the proxy's validity.
Authors: We will revise §4.3 and Table 4 to include per-condition quantitative metrics (Pearson rank correlation between TLO coordinates and the corresponding hidden-state refusal direction, plus cosine similarity of the vectors). We will also add a short paragraph analyzing the single discrepant model/condition, attributing it to the fixed-lexicon limitation already noted and showing that the remaining 11 of 12 conditions exhibit correlations above 0.7. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents TLO as a training-free method that computes a compliance-refusal margin directly from output logits during decoding and maps conditions onto a 2D plane without any parameter fitting or self-referential definitions. No equations, self-citations, or derivations are shown that reduce the reported plane positions or early-stop rule to quantities fitted from the same evaluation data; the geometry is claimed to match external hidden-state probes on most conditions, and the early-stop rule is tested separately on benign queries. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083, 2024
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083, 2024
2024
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
1901
-
[5]
Leyla Naz Candogan, Yongtao Wu, Elias Abad Rocamora, Grigorios G. Chrysos, and V olkan Cevher. Single-pass detection of jailbreaking input in large language models.arXiv preprint arXiv:2502.15435, 2025
-
[6]
JailbreakBench: An open robustness benchmark for jailbreaking large language models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J Pappas, Florian Tramer, et al. JailbreakBench: An open robustness benchmark for jailbreaking large language models. Advances in Neural Information Processing Systems, 37:55005–55029, 2024
2024
-
[7]
LLM jailbreak detection for (almost) free!arXiv preprint arXiv, 2509, 2025
Guorui Chen, Yifan Xia, Xiaojun Jia, Zhijiang Li, Philip Torr, and Jindong Gu. LLM jailbreak detection for (almost) free!arXiv preprint arXiv, 2509, 2025
2025
-
[8]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[9]
Tianqi Du, Zeming Wei, Quan Chen, Chenheng Zhang, and Yisen Wang. Advancing LLM safe alignment with safety representation ranking.arXiv preprint arXiv:2505.15710, 2025
-
[10]
An introduction to ROC analysis.Pattern Recognition Letters, 27(8):861–874, 2006
Tom Fawcett. An introduction to ROC analysis.Pattern Recognition Letters, 27(8):861–874, 2006
2006
-
[11]
Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned,
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, Andy Jones, Sam Bowman, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Nelson Elhage, Sheer El-Showk, Stanislav Fort, Zac Hatfield-Dodds, Tom Henighan, Danny Hernandez, Tristan Hume, Josh Jacobson, Scott Joh...
-
[12]
URLhttps://arxiv.org/abs/2209.07858
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Xiaomeng Hu, Fei Huang, Chenhan Yuan, Junyang Lin, and Tsung-Yi Ho. CARE: De- coding time safety alignment via rollback and introspection intervention.arXiv preprint arXiv:2509.06982, 2025. 10
-
[16]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama Guard: LLM-based input-output safeguard for human-AI conversations.arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7B.arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Logit-Gap Steering: A Forward-Pass Diagnostic for Alignment Robustness
Tung-Ling Li and Hongliang Liu. Logit-gap steering: Efficient short-suffix jailbreaks for aligned large language models.arXiv preprint arXiv:2506.24056, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
DeepInception: Hypnotize Large Language Model to Be Jailbreaker
Xuan Li, Zhanke Zhou, Jianing Zhu, Jiangchao Yao, Tongliang Liu, and Bo Han. Deepinception: Hypnotize large language model to be jailbreaker.arXiv preprint arXiv:2311.03191, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study
Yi Liu, Gelei Deng, Zhengzi Xu, Yuekang Li, Yaowen Zheng, Ying Zhang, Lida Zhao, Tianwei Zhang, Kailong Wang, and Yang Liu. Jailbreaking ChatGPT via prompt engineering: An empirical study.arXiv preprint arXiv:2305.13860, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
2022
-
[23]
Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving
Ethan Perez, Saffron Huang, H. Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419–3448, 2022
2022
-
[24]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F. Christiano. Learning to summarize with human feedback. InAdvances in Neural Information Processing Systems, volume 33, pages 3008–3021, 2020
2020
-
[25]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[26]
SafeDecoding: Defending against jailbreak attacks via safety-aware decoding
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Jinyuan Jia, Bill Yuchen Lin, and Radha Poovendran. SafeDecoding: Defending against jailbreak attacks via safety-aware decoding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5587–5605, 2024
2024
-
[27]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Qingyu Yin, Chak Tou Leong, Linyi Yang, Wenxuan Huang, Wenjie Li, Xiting Wang, Jaehong Yoon, Jinjin Gu, et al. Refusal falls off a cliff: How safety alignment fails in reasoning?arXiv preprint arXiv:2510.06036, 2025
-
[29]
Fine-Tuning Language Models from Human Preferences
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[30]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. 11 A Evaluation Grid and Signal Anchors The evaluation grid supports the main observability claim with 12 model–attack conditions. We evaluate Llama-3.1-8B-...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.