Predicting Causal Effects from Natural Language Queries using Structured Representations
Pith reviewed 2026-06-29 08:04 UTC · model grok-4.3
The pith
Finetuning a two-step framework that first builds structured representations of queries reduces error in predicting causal effect sizes from natural language by 27 to 71 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that separating semantic interpretation of a natural language query into a synthetic structured representation from the subsequent numerical estimation of effect size, followed by supervised finetuning of the encoder, yields lower prediction error and stronger out-of-domain generalization than prompting large language models end-to-end.
What carries the argument
The two-step framework that first generates a synthetic structured representation of the query before predicting effect size using a supervised encoder model.
If this is right
- Finetuning reduces absolute error by 27% to 71% compared to prompted out-of-the-box LLMs.
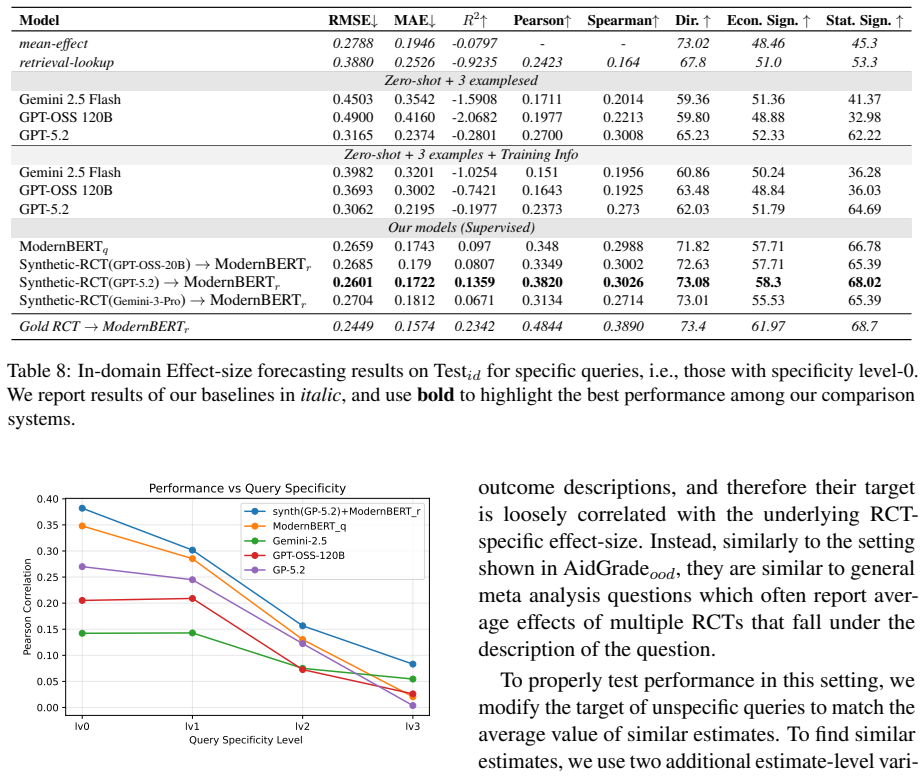
- The two-step framework improves out-of-domain generalization.
- The benchmark enables systematic testing across different levels of query implicitness, abstraction, and ambiguity.
- Separating semantic interpretation from numerical effect estimation is the mechanism that drives the reported gains.
Where Pith is reading between the lines
- Predicted effect sizes could be used to rank which new randomized trials are most worth conducting.
- The same separation into structured representation plus supervised estimation may apply to other text-to-numeric forecasting tasks.
- Larger-scale versions of the benchmark could test whether gains persist when queries span many scientific fields.
Load-bearing premise
The benchmark's construction of natural language questions aligned with experiment descriptions, varied along implicitness, abstraction, and ambiguity, accurately simulates realistic information-seeking scenarios for causal effect prediction.
What would settle it
A held-out collection of queries drawn from new domains in which the two-step finetuned model shows no reduction in absolute error and no gain in generalization relative to direct prompting of large language models.
Figures

read the original abstract
Randomized controlled trials are a cornerstone of medicine and the social sciences as they enable reliable estimates of causal effects. However, they are costly and time-consuming to conduct, motivating interest in predicting causal effects from existing experimental evidence. Recent advances in large language models (LLMs) have demonstrated strong performance on knowledge-intensive tasks, raising the question of whether these models can be used for forecasting causal effect sizes. To investigate this, we introduce Query2Effect, a new large-scale benchmark consisting of more than 72,000 natural language questions aligned with experiment descriptions, created to simulate realistic information-seeking scenarios by varying query specificity along dimensions of implicitness, abstraction, and ambiguity. We then propose a two-step framework that first generates a synthetic structured representation of a query before predicting effect size using a supervised encoder model. Experiments show that finetuning plays a crucial role in improving prediction performance, with absolute error reducing by -27% up to -71% compared to prompted out-of-the-box LLMs, and that our two-step framework is beneficial for out-of-domain generalization, highlighting the benefits of separating semantic interpretation from numerical effect estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Query2Effect, a benchmark of >72k natural language questions aligned to experiment descriptions and varied along implicitness, abstraction, and ambiguity to simulate causal-effect information-seeking. It proposes a two-step framework that first produces a synthetic structured representation of the query and then applies a supervised encoder to predict effect size. Experiments claim that fine-tuning yields absolute-error reductions of 27–71% versus prompted out-of-the-box LLMs and that the two-step design improves out-of-domain generalization.
Significance. If the benchmark is shown to be a faithful proxy for realistic queries, the work would supply a useful large-scale testbed and a modular architecture that separates semantic interpretation from numerical estimation. The scale of the dataset and the reported fine-tuning gains constitute concrete empirical contributions; however, their broader significance hinges on external validation of the benchmark’s realism.
major comments (2)
- [Benchmark construction section] Benchmark construction section: the paper states that varying implicitness, abstraction, and ambiguity produces queries that “simulate realistic information-seeking scenarios,” yet supplies no external validation (e.g., comparison to real user queries from domain experts or literature searches). Because the headline claims of fine-tuning gains and OOD generalization rest on this assumption, the absence of such validation is load-bearing.
- [Experimental results section] Experimental results section: the reported absolute-error reductions (−27 % to −71 %) are presented without accompanying information on the precise baselines, data splits, error bars, or statistical tests used. This omission prevents assessment of whether the two-step framework’s advantage is robust or benchmark-specific.
minor comments (2)
- [Method section] Clarify the exact definition and generation procedure for the “synthetic structured representation” (including any learned components) so that the separation between the two steps can be reproduced.
- Add a limitations paragraph that explicitly discusses the synthetic nature of the query distribution and the conditions under which the reported gains may not transfer.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Benchmark construction section] Benchmark construction section: the paper states that varying implicitness, abstraction, and ambiguity produces queries that “simulate realistic information-seeking scenarios,” yet supplies no external validation (e.g., comparison to real user queries from domain experts or literature searches). Because the headline claims of fine-tuning gains and OOD generalization rest on this assumption, the absence of such validation is load-bearing.
Authors: We appreciate the referee's observation. The benchmark was constructed by systematically varying the three dimensions based on linguistic principles from information-seeking and query formulation literature. We acknowledge that no direct external validation against real user queries from domain experts was performed. In the revised manuscript, we will expand the benchmark construction section with additional discussion of the design rationale, grounding in prior work, an explicit limitations paragraph, and suggestions for future external validation. This will better frame the scope of our simulation claims without overstating realism. revision: yes
-
Referee: [Experimental results section] Experimental results section: the reported absolute-error reductions (−27 % to −71 %) are presented without accompanying information on the precise baselines, data splits, error bars, or statistical tests used. This omission prevents assessment of whether the two-step framework’s advantage is robust or benchmark-specific.
Authors: We agree that greater transparency is needed. While some details appear in the appendix, the revised main experimental results section will explicitly specify the baselines (exact LLMs and prompt templates), data splits (including OOD construction criteria), error bars (standard deviations across random seeds), and statistical tests (e.g., paired significance tests). These additions will enable readers to assess robustness directly. revision: yes
Circularity Check
No circularity; empirical benchmark and supervised learning study
full rationale
The paper presents Query2Effect as a constructed benchmark of >72k aligned NL questions and evaluates a two-step framework via finetuning experiments showing error reductions. No equations, derivations, or load-bearing self-citations reduce any prediction to quantities defined by the authors' own fitted parameters or prior ansatzes. The central claims rest on independent experimental comparisons against prompted LLMs and OOD splits, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
M3Retrieve: Benchmarking multimodal re- trieval for medicine. InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 15263–15276, Suzhou, China. As- sociation for Computational Linguistics. Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Alt- man, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haimi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
What is the impact of [intervention] on [outcome]?
Consort 2025 statement: updated guideline for reporting randomized trials.Nature Medicine, 31(6):1776–1783. Ali Hummos, Felipe del Río, Brabeeba Mien Wang, Julio Hurtado, Cristian B Calderon, and Guangyu Robert Yang. 2024. Gradient-based in- ference of abstract task representations for gen- eralization in neural networks.ArXiv preprint, abs/2407.17356. Ko...
-
[3]
Generate exactly FOUR queries
-
[4]
Each query must be ONE sentence
-
[5]
Do NOT include answers, explanations, metadata, or formatting beyond what is requested
-
[6]
Queries must differ meaningfully in implicitness, abstraction, and ambiguity
-
[7]
Do NOT hallucinate details that are not present in the RCT (e.g., dosage, sample size, metrics)
-
[8]
When information is not allowed by the difficulty level, it must be omitted, not guessed
-
[9]
Queries should sound like realistic questions asked by policymakers, practitioners, or researchers. -------------------------------------------------- RCT INFORMATION -------------------------------------------------- Intervention: - Description: {intervention_description} Outcome: - Description: {outcome_description} Sector: - Description: {sector} -----...
-
[10]
I0-A0-U0 (Fully explicit, concrete, unambiguous)
-
[11]
I1-A1-U1 (Implicit elements, paraphrased, mildly underspecified)
-
[12]
I2-A2-U2 (Conceptual abstraction with multiple plausible interpretations)
-
[13]
query":
I3-A3-U3 (Very high-level, ill-posed causal question) -------------------------------------------------- OUTPUT FORMAT (STRICT) -------------------------------------------------- Each object must have the following structure: { "query": "<one-sentence>", "difficulty": { "implicitness": "I0|I1|I2|I3", "abstraction": "A0|A1|A2|A3", "ambiguity": "U0|U1|U2|U3...
-
[14]
Generate a detailed description (rather than just a keyword or keyphrase) for each of the intervention and outcome
-
[15]
intervention
Prefer underspecification over extrapolating knowledge without basis. ------------------------------------------------------------ WHAT YOU MAY INFER ------------------------------------------------------------ You MAY extract or cautiously infer: - Intervention type (if named or clearly implied) - Outcome variable (possibly abstracted) - Target populatio...
-
[16]
Hedges g score: a float between -2 and 2 representing the estimated impact of the intervention on the outcome
-
[17]
Lower bound of the confidence interval for Hedges g: must be a float smaller than Hedges g
-
[18]
Hedges_g
Upper bound of the confidence interval for Hedges g: must be a float larger than Hedges g. Format your output exactly as a JSON object like: {"Hedges_g": <float between -2 and 2>, "Hedges_g_ci_lower": <float smaller than Hedges_g>, "Hedges_g_ci_upper": <float larger than Hedges_g>, } --- I will give you three examples of intervention–outcome pairs with th...
1956
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.