Eigen-Spike Emergence and Quadratic Equivalents for Conjugate Kernels on Nonlinearly Separable Data
Pith reviewed 2026-06-29 05:30 UTC · model grok-4.3
The pith
A quadratic equivalent of the conjugate kernel predicts when nonlinear features produce label-aligned eigen-spikes on XOR data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
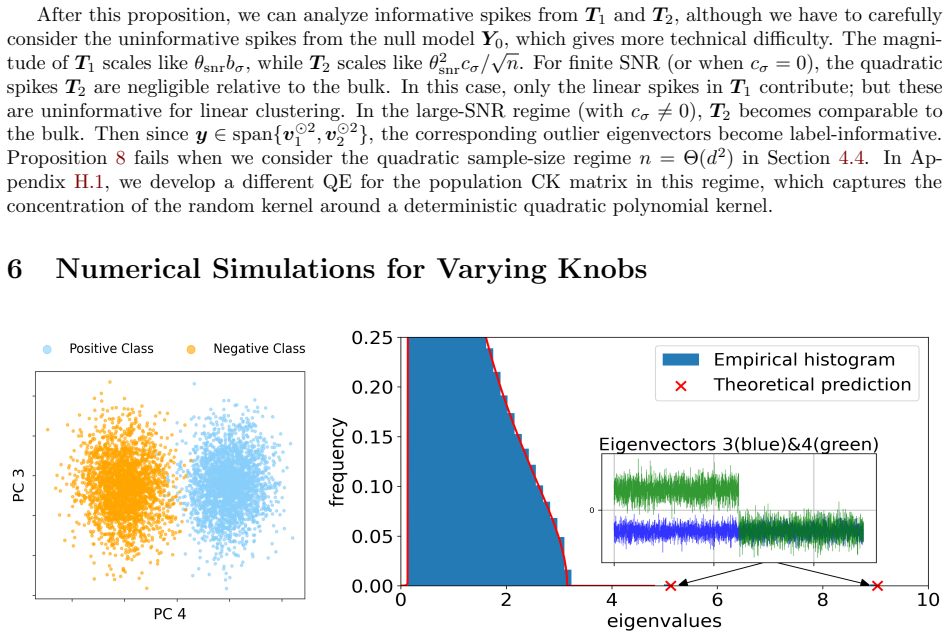
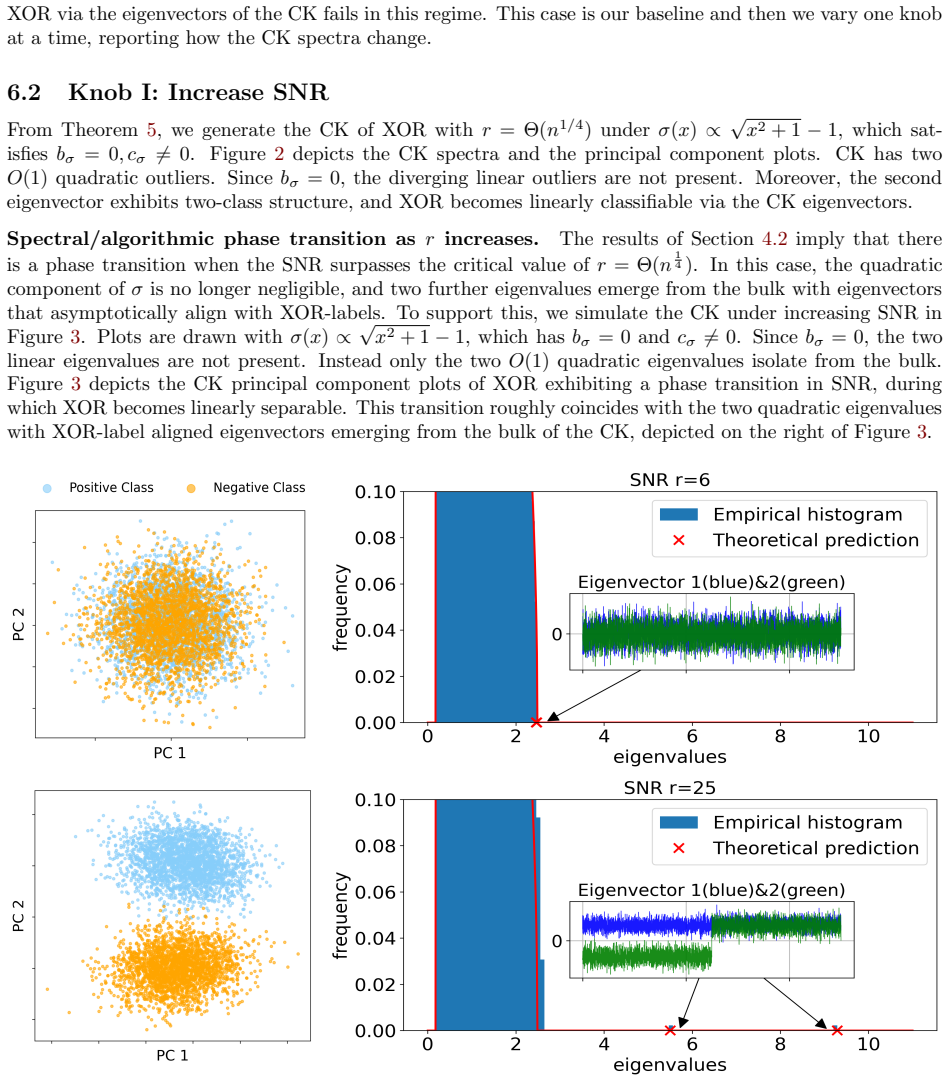
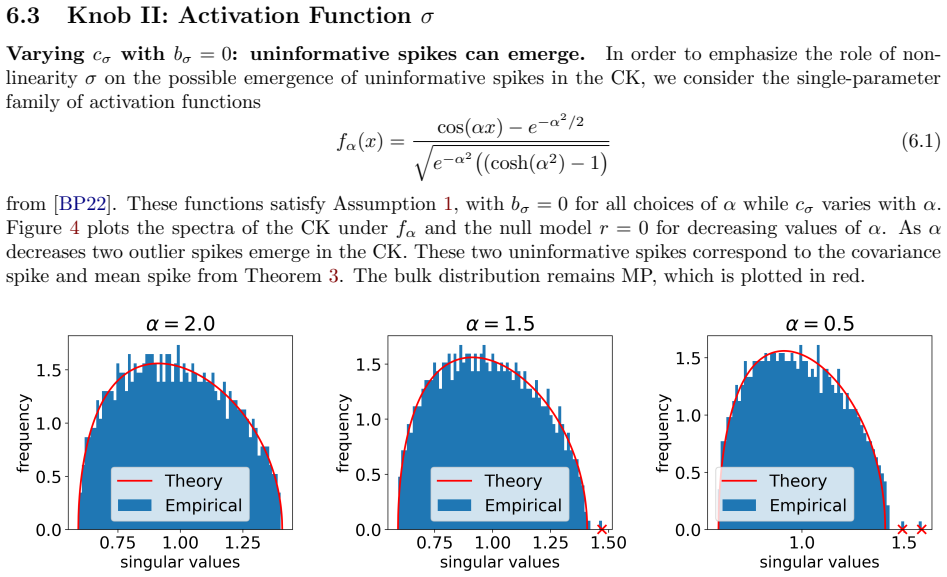
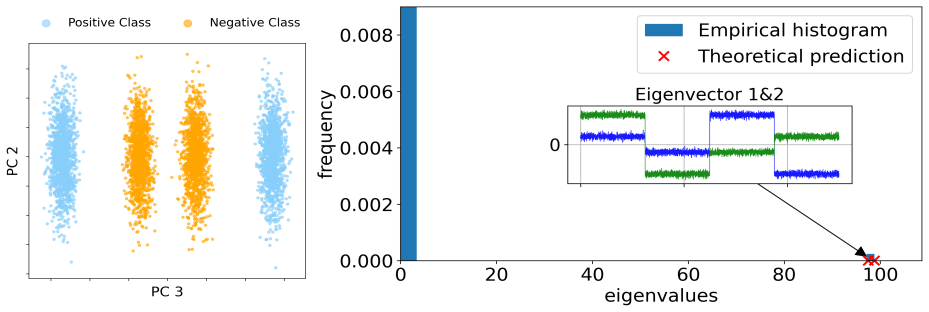
We develop a robust quadratic equivalent of the CK matrix that enables a precise analysis of emergent informative spikes, as one modifies various knobs common in ML practice: sample complexity, signal-to-noise ratio (SNR), nonlinear activation choice, and pretrained features. We identify regimes in which these knobs move the CK beyond the linear equivalent and produce BBP-type transitions to label-aligned outlier eigenspaces.
What carries the argument
The robust quadratic equivalent of the conjugate kernel matrix, which approximates the spectral behavior of the nonlinear feature map and tracks the emergence and alignment of outlier eigenvalues with XOR labels.
Load-bearing premise
The alignment of outlier eigenvectors in the conjugate kernel with XOR labels serves as a valid proxy for nonlinear learnability on high-dimensional data.
What would settle it
Numerical simulations in which the predicted locations or existence of label-aligned outlier eigenvalues deviate systematically from the quadratic equivalent for fixed choices of activation and sample size would falsify the equivalence.
Figures



read the original abstract
Recent work in random matrix theory (RMT) has developed the notion of deterministic equivalents: typically linear surrogate models that approximate the spectral behavior of large nonlinear random matrices, such as nonlinear feature maps in neural networks (NNs). Such equivalents make theoretical predictions tractable by reducing a complex model to a simpler one with properties that fall under the umbrella of classical RMT tools. However, this leaves open the question of whether this idealized linear equivalence remains meaningful for classification of high-dimensional nonlinearly separable data. Motivated by this, we consider the conjugate kernel (CK), which is the nonlinear feature map of a one-layer feedforward NN, under a canonical nonlinearly separable dataset for the XOR problem; and we use the study of informative outlier eigenvalues in the CK and whether their corresponding eigenvectors asymptotically align with XOR labels as a proxy for nonlinear learnability. We develop a robust quadratic equivalent of the CK matrix that enables a precise analysis of emergent informative spikes, as one modifies various knobs common in ML practice: sample complexity, signal-to-noise ratio (SNR), nonlinear activation choice, and pretrained features. We identify regimes in which these knobs move the CK beyond the linear equivalent and produce BBP-type transitions to label-aligned outlier eigenspaces. Our analysis helps bring deterministic-equivalence tools from RMT to bear on problems of practical relevance in ML.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a quadratic deterministic equivalent for the conjugate kernel (CK) matrix arising from a one-layer network on XOR data. It uses the emergence of label-aligned outlier eigenvalues (and their BBP-type transitions) under changes in sample complexity, SNR, activation choice, and pretrained features as a proxy for nonlinear learnability, thereby extending linear deterministic-equivalent tools to a nonlinearly separable classification setting.
Significance. If the quadratic equivalent is accurate and the alignment proxy is justified, the work supplies a tractable RMT model for when informative spikes appear in CK matrices beyond the linear regime, directly addressing how common ML knobs affect spectral behavior on nonlinearly separable data. The manuscript ships explicit quadratic equivalents and identifies concrete regimes for spike emergence, which are strengths.
major comments (3)
- [§3] §3 (proxy definition): the manuscript treats asymptotic alignment of CK outlier eigenvectors with XOR labels as a proxy for nonlinear learnability without deriving a link to classification risk, margin, or training dynamics; this assumption is load-bearing for the claim that the quadratic equivalent analyzes practical ML knobs.
- [Theorem 4.1] Theorem 4.1 / Eq. (12): the quadratic equivalent is stated to be robust, yet no concentration or approximation-error bound is supplied that would guarantee it tracks the true CK spectrum (and therefore the BBP transition) uniformly over the claimed ranges of sample complexity and SNR.
- [§5.2] §5.2 (pretrained-features experiment): the reported alignment improvement is shown only for the quadratic surrogate; without a direct comparison of the surrogate spectrum to the empirical CK spectrum on the same pretrained-feature instances, it is unclear whether the observed BBP transition is an artifact of the equivalent or a property of the original kernel.
minor comments (2)
- Notation for the quadratic equivalent (e.g., the definition of the effective noise term) is introduced without an explicit comparison table to the linear equivalent, making it harder to see exactly where the quadratic correction appears.
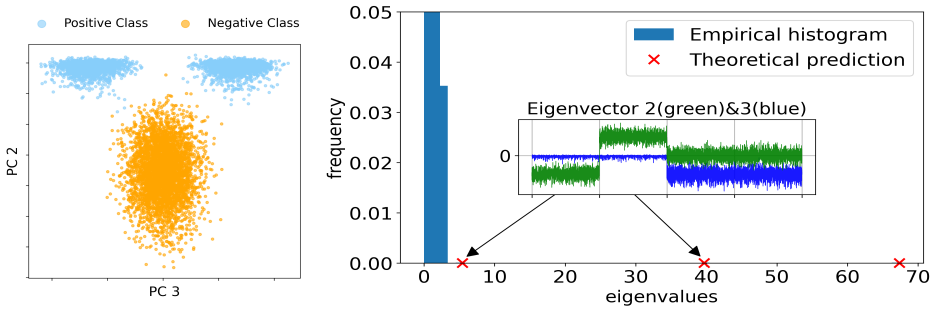
- Figure 3 caption does not state the number of Monte-Carlo realizations used to compute the empirical eigenvalue histograms, which is needed to assess variability of the reported spike locations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (proxy definition): the manuscript treats asymptotic alignment of CK outlier eigenvectors with XOR labels as a proxy for nonlinear learnability without deriving a link to classification risk, margin, or training dynamics; this assumption is load-bearing for the claim that the quadratic equivalent analyzes practical ML knobs.
Authors: We view the eigenvector alignment as a natural proxy in the RMT setting for when the kernel matrix begins to encode the label structure, analogous to how outlier eigenvalues indicate signal in linear models. Deriving an explicit connection to classification risk or training dynamics would require analyzing the full learning pipeline, which exceeds the scope of this work focused on the spectral properties of the conjugate kernel. We will revise §3 to more explicitly state that the alignment serves as a spectral proxy for the emergence of nonlinear separability and discuss its relation to learnability in the context of BBP transitions. revision: partial
-
Referee: [Theorem 4.1] Theorem 4.1 / Eq. (12): the quadratic equivalent is stated to be robust, yet no concentration or approximation-error bound is supplied that would guarantee it tracks the true CK spectrum (and therefore the BBP transition) uniformly over the claimed ranges of sample complexity and SNR.
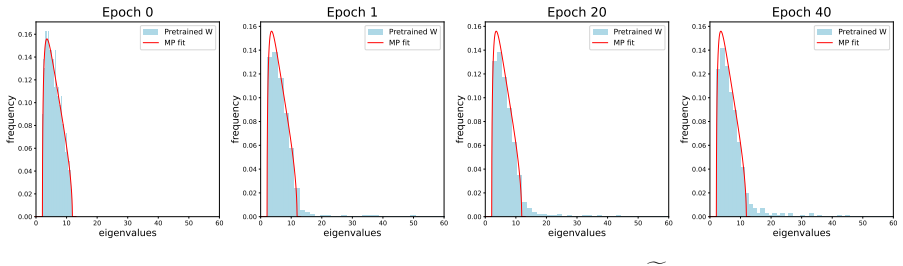
Authors: The derivation of the quadratic equivalent relies on asymptotic analysis in the high-dimensional regime. While we do not provide explicit concentration inequalities, the equivalent is validated through Monte Carlo simulations that show close agreement with the empirical spectrum across the relevant parameter ranges. We will update the discussion around Theorem 4.1 to clarify that the robustness is in the asymptotic sense and highlight the numerical evidence supporting its use for predicting BBP transitions. revision: partial
-
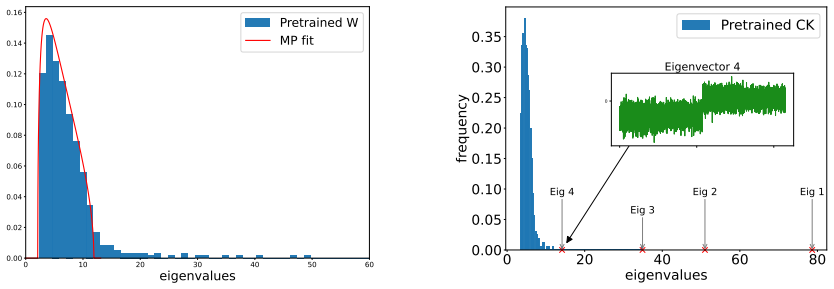
Referee: [§5.2] §5.2 (pretrained-features experiment): the reported alignment improvement is shown only for the quadratic surrogate; without a direct comparison of the surrogate spectrum to the empirical CK spectrum on the same pretrained-feature instances, it is unclear whether the observed BBP transition is an artifact of the equivalent or a property of the original kernel.
Authors: This is a valid point. In the revised version, we will add a figure or table comparing the eigenvalue spectrum and eigenvector alignments of the quadratic equivalent directly to those computed from the empirical conjugate kernel matrix using the same pretrained feature instances. This will confirm that the observed transitions are not artifacts of the surrogate. revision: yes
Circularity Check
No circularity; proxy assumption is explicit modeling choice with no reduction to inputs
full rationale
The provided abstract and context contain no equations or derivation steps that reduce a claimed prediction or result to its own inputs by construction. The paper explicitly adopts the alignment of CK outlier eigenvectors with XOR labels 'as a proxy for nonlinear learnability' after noting an open question about linear equivalents for nonlinear classification; this is framed as a motivated modeling decision rather than a derived equivalence. No self-citations, fitted parameters renamed as predictions, ansatzes smuggled via citation, or uniqueness theorems are referenced. The quadratic equivalent is introduced to enable analysis of BBP transitions under ML knobs, but the central claim does not loop back to presuppose its own outputs. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
We denote|X| ≺YorX=O ≺(Y) as the stochastic domination ofXbyYuniformly inu∈U n: if for all smallϵ >0 and largeD >0, there exists someN 0(ϵ, D), such that for alln≥N 0(ϵ, D), sup u∈Un P(|Xn(u)| ≥n ϵYn(u))≤n −D. 25 0 10 20 30 40 50 60 eigenvalues 0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 0.16frequency Epoch 0 Pretrained W MP fit 0 10 20 30 40 50 60 eigenvalue...
-
[2]
If{A n}are random matrices, we interpret ∥An∥op =o P(1)⇐ ⇒ ∥A n∥op P − →0
For simplicity, for a family of random matricesAand a family of non-negative random variablesζ, A=O ≺(ζ) represents|⟨v,Au⟩| ≺ζ∥v∥∥u∥uniformly for all deterministic vectorsvandu. If{A n}are random matrices, we interpret ∥An∥op =o P(1)⇐ ⇒ ∥A n∥op P − →0. For simplicity, in the proofs, we use∥A n∥to represent operator norm∥A n∥op. B.1 Properties of XOR Data ...
-
[3]
Write logQ m = log Γ(m+ 1 2)−log Γ(m) − 1 2 logm
logz−z+ 1 2 log(2π) + 1 12z − 1 360z3 +O(z −5),(B.23) see [DLMF, (5.11.2)] or [AS64,§6.1,§6.3]. Write logQ m = log Γ(m+ 1 2)−log Γ(m) − 1 2 logm. Using (B.23) withz=m+ 1 2 andz=m, we obtain logQ m =mlog(m+ 1 2)−(m+ 1 2)−(m− 1
-
[4]
The logarithmic terms simplify to mlog 1 + 1 2m − 1 2
− 1 12m − 1 360(m+ 1 2)3 + 1 360m3 − 1 2 logm+O(m −5). The logarithmic terms simplify to mlog 1 + 1 2m − 1 2 . Expanding with the binomial and Taylor series log(1 +x) =x− x2 2 + x3 3 +O(x 4) and (1 +x) −1 = 1−x+ x2 −x 3 +O(x 4), we get mlog 1 + 1 2m = 1 2 − 1 8m + 1 24m2 − 1 64m3 +O(m −4), and 1 12(m+ 1
-
[5]
Further, the difference− 1 360(m+ 1 2 )3 + 1 360m3 isO(m −4) (since the leading term cancels and the remainder begins at orderm −4)
− 1 12m =− 1 24m2 + 1 48m3 +O(m −4). Further, the difference− 1 360(m+ 1 2 )3 + 1 360m3 isO(m −4) (since the leading term cancels and the remainder begins at orderm −4). Collecting terms, we find logQ m =− 1 8m + 1 192m3 +O(m −4). Exponentiating and using exp(u) = 1 +u+ u2 2 + u3 6 +O(u 4) withu=− 1 8m + 1 192m3 , we obtain Qm = 1− 1 8m + 1 128m2 + 5 1024...
-
[6]
The matricesYΠ s andY ♯ s have operator normO P(1):Y ♯ 0 Πs is bounded by Proposition 31, and the quadratic term has norm |cσ|θ2 0 2 ∥a⊙2∥ ∥Πsq∥=O P(1) by Lemmas 55 and 56
Hence the first estimate in (G.15) follows. The matricesYΠ s andY ♯ s have operator normO P(1):Y ♯ 0 Πs is bounded by Proposition 31, and the quadratic term has norm |cσ|θ2 0 2 ∥a⊙2∥ ∥Πsq∥=O P(1) by Lemmas 55 and 56. Therefore, we have ∥Ks −K ♯ s∥ ≤(∥YΠ s∥+∥Y ♯ s ∥)∥YΠ s −Y ♯ s ∥=o P(1). 75 G.3 The Compressed Covariance Spike The order-one analysis must k...
-
[7]
Define its Hermite coefficients ζ(i) k :=E[σ (i)(ξ)hk(ξ)], k∈N, 82 and the diagonal matricesD k := diag(ζ(1) k ,
For eachi∈[n], sets i :=∥x i∥and define the scaled activation σ(i)(t) :=σ(s it). Define its Hermite coefficients ζ(i) k :=E[σ (i)(ξ)hk(ξ)], k∈N, 82 and the diagonal matricesD k := diag(ζ(1) k , . . . , ζ(n) k ). Define the Gram and correlation matrices G:=X ⊤X,D:= diag(s 1, . . . , sn),R:=D −1GD−1. NoteR ii = 1 andR ij = x⊤ i xj sisj . Lemma 60(Hermite ex...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.