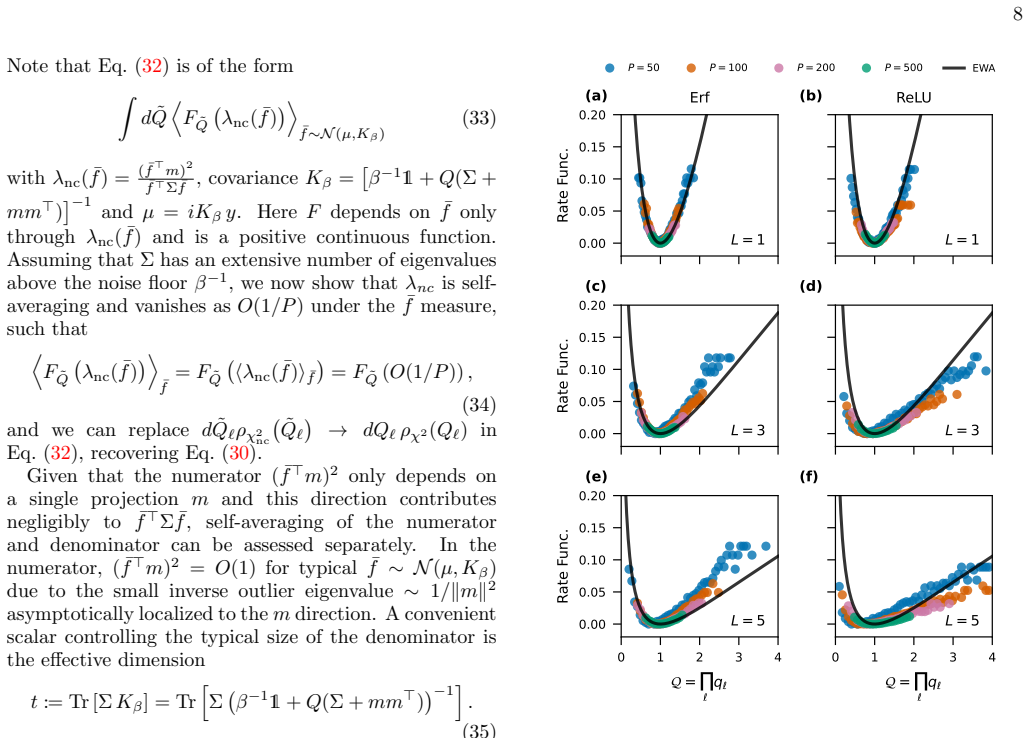
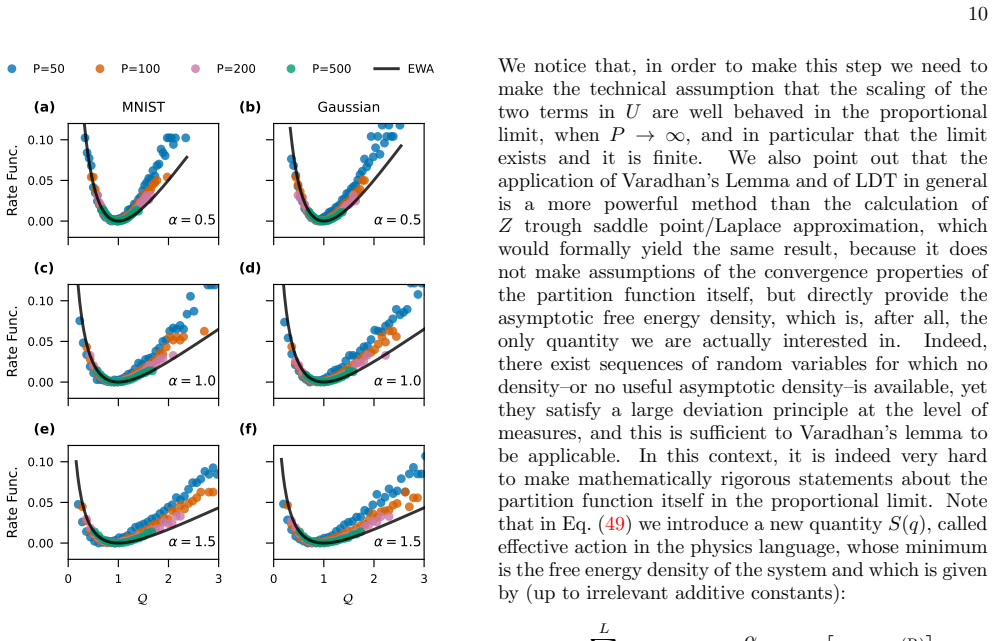
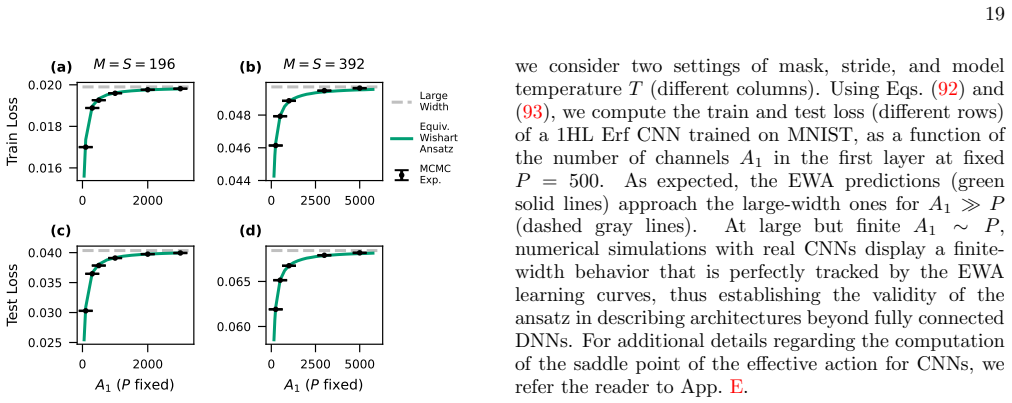
Kernel Renormalization in Bayesian Deep Neural Networks: the Equivalent Wishart Ansatz in the Proportional Regime
Pith reviewed 2026-06-29 09:03 UTC · model grok-4.3
The pith
Bayesian deep MLPs in the proportional regime reduce to a renormalized NNGP kernel governed by at most L self-consistent scalar order parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose an equivalent Wishart Ansatz to capture the dominant stochastic fluctuations of the hierarchical empirical kernels of MLPs. This allows us to perform a large deviation analysis for the partition function of MLPs in the proportional limit, expressed in terms of a renormalized NNGP kernel. In this description, even strong representation learning in the proportional limit is encoded in at most L scalar order parameters, determined self-consistently.
What carries the argument
The Equivalent Wishart Ansatz, which approximates the dominant fluctuations of the hierarchical empirical kernels to enable the large-deviation analysis of the partition function.
If this is right
- Generalization error is obtained by solving a closed set of equations involving at most L scalar order parameters.
- Finite-width corrections to the NNGP kernel are fully captured by a single renormalized kernel per layer.
- Representation learning is reduced to the self-consistent adjustment of these L parameters.
- The same renormalization structure applies to CNNs through a hierarchical local kernel mechanism.
- The theory reproduces posterior sampling results for networks of depth up to 10 and training sets of size around 1000.
Where Pith is reading between the lines
- The reduction to L parameters suggests that the proportional regime may remain tractable even for deeper networks if the order-parameter equations can be iterated efficiently.
- The hierarchical renormalization identified for CNNs may generalize to other architectures that possess local receptive fields.
- Numerical solution of the self-consistent equations could be used to scan the dependence of generalization on depth without retraining finite networks.
- The Wishart ansatz may connect the Bayesian setting to other high-dimensional kernel analyses that rely on similar fluctuation assumptions.
Load-bearing premise
The Equivalent Wishart Ansatz accurately captures the dominant stochastic fluctuations of the hierarchical empirical kernels.
What would settle it
Direct posterior sampling on an MLP of depth 5 with width proportional to a training set of size 1000 on MNIST or CIFAR-10 yields test errors that deviate systematically from the values obtained by solving the self-consistent equations for the renormalized kernel.
Figures





read the original abstract
The scaling limit where both the size of the training set $P$ and the width $N$ of a deep neural network grow at the same rate, the so-called proportional-width regime, has been intensely studied for shallow, single-hidden-layer networks. However, extending these non-perturbative results from shallow architectures to deep non-linear networks has proven very challenging. Here we present an effective approximate approach to predict the generalization performance of Bayesian multi-layer perceptrons (MLPs) of fixed depth $L$ on arbitrary high-dimensional data. We propose an equivalent Wishart Ansatz to capture the dominant stochastic fluctuations of the hierarchical empirical kernels of MLPs. This allows us to perform a large deviation analysis for the partition function of MLPs in the proportional limit, expressed in terms of a renormalized NNGP kernel. In this description, even strong representation learning in the proportional limit is encoded in at most $L$ scalar order parameters, determined self-consistently. Extending the approach to convolutional architectures (CNNs), we identify a hierarchical local kernel renormalization mechanism, which allows to quantify more complex data-dependent transformations of the large-width kernel in CNNs due to finite-width effects. We test our effective theory against sampling experiments from the Bayesian posterior of finite deep neural networks with depths $L \sim O(10)$ and $P\sim O(10^3)$ on classic benchmark datasets, finding overall very good agreement together with two distinct types of systematic deviations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an Equivalent Wishart Ansatz to model the dominant stochastic fluctuations of hierarchical empirical kernels in Bayesian MLPs of fixed depth L in the proportional regime (P ~ N). This ansatz enables a large-deviation analysis of the partition function expressed via a renormalized NNGP kernel, reducing even strong representation learning to at most L self-consistent scalar order parameters. The approach is extended to CNNs via hierarchical local kernel renormalization. Validation is performed against posterior sampling on benchmarks with L ~ O(10) and P ~ O(10^3), reporting overall good agreement alongside two classes of systematic deviations.
Significance. If the ansatz accurately isolates the leading fluctuations, the framework would offer a tractable non-perturbative description of finite-width effects and representation learning in deep Bayesian networks, reducing the problem to a small number of order parameters. The empirical tests on multiple datasets and architectures provide concrete evidence of practical utility even if the derivation remains approximate. The reduction to L scalars and the CNN extension are notable strengths for the proportional-limit literature.
major comments (2)
- [Abstract / Ansatz introduction] Abstract and the section introducing the ansatz: the Equivalent Wishart Ansatz is posited to capture the dominant stochastic fluctuations of the hierarchical empirical kernels, yet no derivation or error-bound analysis is supplied for why this specific form isolates the leading large-deviation contributions. This is load-bearing for the central claim that the partition function reduces to a renormalized NNGP kernel with at most L scalars.
- [Validation / Empirical tests] Validation section (L~O(10), P~O(10^3) benchmarks): two distinct classes of systematic deviations between the ansatz predictions and posterior sampling are reported but neither their magnitude nor their effect on the self-consistent order parameters is quantified. Without this, it remains unclear whether the ansatz truly dominates the fluctuations in the proportional regime or whether sub-leading corrections remain relevant.
minor comments (1)
- [Theory section] Notation for the renormalized kernel and order parameters should be introduced with explicit definitions and a table summarizing the L scalars for clarity.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We address each major point below, clarifying the status of the ansatz and outlining revisions to the validation analysis.
read point-by-point responses
-
Referee: [Abstract / Ansatz introduction] Abstract and the section introducing the ansatz: the Equivalent Wishart Ansatz is posited to capture the dominant stochastic fluctuations of the hierarchical empirical kernels, yet no derivation or error-bound analysis is supplied for why this specific form isolates the leading large-deviation contributions. This is load-bearing for the central claim that the partition function reduces to a renormalized NNGP kernel with at most L scalars.
Authors: The Equivalent Wishart Ansatz is introduced as an effective approximation motivated by the exact solvability of the shallow (L=1) case and by the observed structure of kernel fluctuations in the proportional regime. No rigorous derivation or error-bound analysis is provided in the manuscript, as obtaining such bounds for the deep nonlinear case remains an open technical challenge. The ansatz enables a consistent large-deviation treatment that reduces the problem to L self-consistent scalars; its utility is supported by the reported empirical agreement rather than by a formal proof. We will revise the introduction and abstract to state more explicitly that the ansatz is posited on the basis of structural analogy and numerical validation, without claiming a derivation of leading-order dominance. revision: partial
-
Referee: [Validation / Empirical tests] Validation section (L~O(10), P~O(10^3) benchmarks): two distinct classes of systematic deviations between the ansatz predictions and posterior sampling are reported but neither their magnitude nor their effect on the self-consistent order parameters is quantified. Without this, it remains unclear whether the ansatz truly dominates the fluctuations in the proportional regime or whether sub-leading corrections remain relevant.
Authors: We agree that the magnitude of the two classes of systematic deviations and their propagation into the self-consistent order parameters should be quantified to better assess the ansatz's accuracy. In the revised manuscript we will add explicit measurements (relative errors, deviation histograms, and sensitivity analysis of the order parameters) for the reported benchmarks, allowing readers to evaluate whether sub-leading corrections remain relevant. revision: yes
Circularity Check
No significant circularity; ansatz is an explicit modeling assumption validated externally.
full rationale
The paper explicitly proposes the Equivalent Wishart Ansatz as an effective approximation to capture kernel fluctuations, then uses it to perform a large-deviation analysis that reduces the problem to L self-consistent scalar order parameters for a renormalized NNGP kernel. This is an input assumption rather than a quantity derived from the final result. The manuscript reports direct empirical validation against posterior sampling on finite networks (L~O(10), P~O(10^3)), with quantified agreement and noted systematic deviations, providing an external benchmark. No quoted step shows a prediction or order parameter reducing by construction to a fitted input or prior self-citation; the self-consistency is the standard fixed-point solution of the effective theory, not a definitional loop. The derivation chain is therefore self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper The Equivalent Wishart Ansatz captures the dominant stochastic fluctuations of hierarchical empirical kernels of MLPs.
invented entities (1)
-
Renormalized NNGP kernel
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gaussian 24 process behaviour in wide deep neural networks,
Alexander G. de G. Matthews, Jiri Hron, Mark Rowland, Richard E. Turner, and Zoubin Ghahramani, “Gaussian 24 process behaviour in wide deep neural networks,” in International Conference on Learning Representations (2018)
2018
-
[2]
Bayesian deep convolutional networks with many channels are gaussian processes,
Roman Novak, Lechao Xiao, Yasaman Bahri, Jaehoon Lee, Greg Yang, Daniel A. Abolafia, Jeffrey Pennington, and Jascha Sohl-dickstein, “Bayesian deep convolutional networks with many channels are gaussian processes,” inInternational Conference on Learning Representations (2019)
2019
-
[3]
Infinite attention: NNGP and NTK for deep attention networks,
Jiri Hron, Yasaman Bahri, Jascha Sohl-Dickstein, and Roman Novak, “Infinite attention: NNGP and NTK for deep attention networks,” inInternational Conference on Machine Learning(PMLR, 2020) pp. 4376–4386
2020
-
[4]
A mean field view of the landscape of two-layer neural networks,
Song Mei, Andrea Montanari, and Phan-Minh Nguyen, “A mean field view of the landscape of two-layer neural networks,” Proceedings of the National Academy of Sciences115(2018)
2018
-
[5]
Parameters as interacting particles: long time convergence and asymptotic error scaling of neural networks,
Grant Rotskoff and Eric Vanden-Eijnden, “Parameters as interacting particles: long time convergence and asymptotic error scaling of neural networks,” inAdvances in Neural Information Processing Systems, Vol. 31 (Curran Associates, Inc., 2018)
2018
-
[6]
On the global convergence of gradient descent for over-parameterized models using optimal transport,
L´ ena¨ ıc Chizat and Francis Bach, “On the global convergence of gradient descent for over-parameterized models using optimal transport,” inAdvances in Neural Information Processing Systems, Vol. 31 (Curran Associates, Inc., 2018)
2018
-
[7]
Tensor programs iv: Feature learning in infinite-width neural networks,
Greg Yang and Edward J. Hu, “Tensor programs iv: Feature learning in infinite-width neural networks,” in Proceedings of the 38th International Conference on Machine Learning, PMLR, Vol. 139, edited by Marina Meila and Tong Zhang (PMLR, 2021) pp. 11727–11737
2021
-
[8]
Finite versus infinite neural networks: an empirical study,
Jaehoon Lee, Samuel Schoenholz, Jeffrey Pennington, Ben Adlam, Lechao Xiao, Roman Novak, and Jascha Sohl-Dickstein, “Finite versus infinite neural networks: an empirical study,” inAdvances in Neural Information Processing Systems, Vol. 33, edited by H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (Curran Associates, Inc., 2020) pp. 15156–15172
2020
-
[9]
The space of interactions in neural network models,
E. Gardner, “The space of interactions in neural network models,” Journal of Physics A: Mathematical and General21, 257 (1988)
1988
-
[10]
Neural networks and physical systems with emergent collective computational abilities,
J. J. Hopfield, “Neural networks and physical systems with emergent collective computational abilities,” Proceedings of the National Academy of Sciences79, 2554–2558 (1982)
1982
-
[11]
Generalization in Fully Connected Committee Machines,
H. Schwarze and J. Hertz, “Generalization in Fully Connected Committee Machines,” Europhysics Letters 21, 785 (1993)
1993
-
[12]
Weight Space Structure and Internal Representations: A Direct Approach to Learning and Generalization in Multilayer Neural Networks,
R´ emi Monasson and Riccardo Zecchina, “Weight Space Structure and Internal Representations: A Direct Approach to Learning and Generalization in Multilayer Neural Networks,” Physical Review Letters75, 2432– 2435 (1995)
1995
-
[13]
Bayes-optimal learning of deep random networks of extensive-width,
Hugo Cui, Florent Krzakala, and Lenka Zdeborova, “Bayes-optimal learning of deep random networks of extensive-width,” inProceedings of the 40th International Conference on Machine Learning, PMLR, Vol. 202 (2023) pp. 6468–6521
2023
-
[14]
Information-theoretic reduction of deep neural networks to linear models in the overparametrized proportional regime,
Francesco Camilli, Daria Tieplova, Eleonora Bergamin, and Jean Barbier, “Information-theoretic reduction of deep neural networks to linear models in the overparametrized proportional regime,” inProceedings of Thirty Eighth Conference on Learning Theory, PMLR, Vol. 291 (2025) pp. 757–798
2025
-
[15]
Statistical mechanics of deep linear neural networks: The backpropagating kernel renormalization,
Qianyi Li and Haim Sompolinsky, “Statistical mechanics of deep linear neural networks: The backpropagating kernel renormalization,” Phys. Rev. X11, 031059 (2021)
2021
-
[16]
Feature learning in finite-width bayesian deep linear networks with multiple outputs and convolutional layers,
Federico Bassetti, Marco Gherardi, Alessandro Ingrosso, Mauro Pastore, and Pietro Rotondo, “Feature learning in finite-width bayesian deep linear networks with multiple outputs and convolutional layers,” Journal of Machine Learning Research26, 1–35 (2025)
2025
-
[17]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks,
Andrew M. Saxe, James L. McClelland, and Surya Ganguli, “Exact solutions to the nonlinear dynamics of learning in deep linear neural networks,” in2nd International Conference on Learning Representations, ICLR, edited by Yoshua Bengio and Yann LeCun (2014)
2014
-
[18]
Bayesian interpolation with deep linear networks,
Boris Hanin and Alexander Zlokapa, “Bayesian interpolation with deep linear networks,” Proceedings of the National Academy of Sciences120, e2301345120 (2023)
2023
-
[19]
Deep linear network training dynamics from random initialization: Data, width, depth, and hyperparameter transfer,
Blake Bordelon and Cengiz Pehlevan, “Deep linear network training dynamics from random initialization: Data, width, depth, and hyperparameter transfer,” in Proceedings of the 42nd International Conference on Machine Learning, PMLR, Vol. 267 (2025) pp. 4968– 4997
2025
-
[20]
From kernels to features: A multi-scale adaptive theory of feature learning,
Noa Rubin, Kirsten Fischer, Javed Lindner, Inbar Seroussi, Zohar Ringel, Michael Kr¨ amer, and Moritz Helias, “From kernels to features: A multi-scale adaptive theory of feature learning,” inProceedings of the 42nd International Conference on Machine Learning, PMLR, Vol. 267 (2025) pp. 52225–52257
2025
-
[21]
Optimal errors and phase transitions in high-dimensional generalized linear models,
Jean Barbier, Florent Krzakala, Nicolas Macris, L´ eo Miolane, and Lenka Zdeborov´ a, “Optimal errors and phase transitions in high-dimensional generalized linear models,” Proceedings of the National Academy of Sciences116, 5451–5460 (2019)
2019
-
[22]
Fundamental Limits of Weak Recovery with Applications to Phase Retrieval,
Marco Mondelli and Andrea Montanari, “Fundamental Limits of Weak Recovery with Applications to Phase Retrieval,” Foundations of Computational Mathematics 19, 703–773 (2019)
2019
-
[23]
Learning single-index models with shallow neural networks,
Alberto Bietti, Joan Bruna, Clayton Sanford, and Min Jae Song, “Learning single-index models with shallow neural networks,” inAdvances in Neural Information Processing Systems, Vol. 35 (Curran Associates, Inc., 2022) pp. 9768–9783
2022
-
[24]
Fundamental limits of weak learnability in high-dimensional multi-index models,
Emanuele Troiani, Yatin Dandi, Leonardo Defilippis, Lenka Zdeborova, Bruno Loureiro, and Florent Krzakala, “Fundamental limits of weak learnability in high-dimensional multi-index models,” inHigh- dimensional Learning Dynamics 2024: The Emergence of Structure and Reasoning(2024)
2024
-
[25]
Linearized two-layers neural networks in high dimension,
Behrooz Ghorbani, Song Mei, Theodor Misiakiewicz, and Andrea Montanari, “Linearized two-layers neural networks in high dimension,” The Annals of Statistics 49, 1029 – 1054 (2021)
2021
-
[26]
Asymptotics of feature learning in two-layer networks after one gradient-step,
Hugo Cui, Luca Pesce, Yatin Dandi, Florent Krzakala, Yue Lu, Lenka Zdeborova, and Bruno Loureiro, “Asymptotics of feature learning in two-layer networks after one gradient-step,” inForty-first International Conference on Machine Learning(2024)
2024
-
[27]
Scaling Laws and Spectra of Shallow Neural Networks in the Feature Learning Regime
Leonardo Defilippis, Yizhou Xu, Julius Girardin, Emanuele Troiani, Vittorio Erba, Lenka Zdeborov´ a, Bruno Loureiro, and Florent Krzakala, “Scaling laws and spectra of shallow neural networks in the feature learning regime,” arXiv:2509.24882 (2025). 25
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Spectral bias and task-model alignment explain generalization in kernel regression and infinitely wide neural networks,
Abdulkadir Canatar, Blake Bordelon, and Cengiz Pehlevan, “Spectral bias and task-model alignment explain generalization in kernel regression and infinitely wide neural networks,” Nature communications12, 1–12 (2021)
2021
-
[29]
Six lectures on linearized neural networks,
Theodor Misiakiewicz and Andrea Montanari, “Six lectures on linearized neural networks,” Journal of Statistical Mechanics: Theory and Experiment2024, 104006 (2024)
2024
-
[30]
Predicting kernel regression learning curves from only raw data statistics,
Dhruva Karkada, Joseph Turnbull, Yuxi Liu, and James B. Simon, “Predicting kernel regression learning curves from only raw data statistics,” arXiv:2510.14878 (2025)
-
[31]
Exact marginal prior distributions of finite bayesian neural networks,
Jacob A Zavatone-Veth and Cengiz Pehlevan, “Exact marginal prior distributions of finite bayesian neural networks,” inAdvances in Neural Information Processing Systems, edited by A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan (2021)
2021
-
[32]
A statistical mechanics framework for bayesian deep neural networks beyond the infinite-width limit,
R. Pacelli, S. Ariosto, M. Pastore, F. Ginelli, M. Gherardi, and P. Rotondo, “A statistical mechanics framework for bayesian deep neural networks beyond the infinite-width limit,” Nature Machine Intelligence5, 1497–1507 (2023)
2023
-
[33]
Central limit theorems for non-linear functionals of gaussian fields,
P´ eter Breuer and P´ eter Major, “Central limit theorems for non-linear functionals of gaussian fields,” Journal of Multivariate Analysis13, 425–441 (1983)
1983
-
[34]
Moment bounds and central limit theorems for gaussian subordinated arrays,
Jean-Marc Bardet and Donatas Surgailis, “Moment bounds and central limit theorems for gaussian subordinated arrays,” Journal of Multivariate Analysis 114, 457–473 (2013)
2013
-
[35]
Local kernel renormalization as a mechanism for feature learning in overparametrized convolutional neural networks,
R. Aiudi, R. Pacelli, P. Baglioni, A. Vezzani, R. Burioni, and P. Rotondo, “Local kernel renormalization as a mechanism for feature learning in overparametrized convolutional neural networks,” Nature Communications 16(2025)
2025
-
[36]
Kernel shape renormalization explains output-output correlations in finite bayesian one-hidden-layer networks,
P. Baglioni, L. Giambagli, A. Vezzani, R. Burioni, P. Rotondo, and R. Pacelli, “Kernel shape renormalization explains output-output correlations in finite bayesian one-hidden-layer networks,” Phys. Rev. E111, 065312 (2025)
2025
-
[37]
Predictive power of a bayesian effective action for fully connected one hidden layer neural networks in the proportional limit,
P. Baglioni, R. Pacelli, R. Aiudi, F. Di Renzo, A. Vezzani, R. Burioni, and P. Rotondo, “Predictive power of a bayesian effective action for fully connected one hidden layer neural networks in the proportional limit,” Phys. Rev. Lett.133, 027301 (2024)
2024
-
[38]
Statistical mechanics of transfer learning in fully connected networks in the proportional limit,
Alessandro Ingrosso, Rosalba Pacelli, Pietro Rotondo, and Federica Gerace, “Statistical mechanics of transfer learning in fully connected networks in the proportional limit,” Phys. Rev. Lett.134, 177301 (2025)
2025
-
[39]
Order parameters and phase transitions of continual learning in deep neural networks,
Haozhe Shan, Qianyi Li, and Haim Sompolinsky, “Order parameters and phase transitions of continual learning in deep neural networks,” Proceedings of the National Academy of Sciences123, e2501899123 (2026)
2026
-
[40]
Inversion dynamics of class manifolds in deep learning reveals tradeoffs underlying generalization,
Simone Ciceri, Lorenzo Cassani, Matteo Osella, Pietro Rotondo, Filippo Valle, and Marco Gherardi, “Inversion dynamics of class manifolds in deep learning reveals tradeoffs underlying generalization,” Nature Machine Intelligence6, 40–47 (2024)
2024
-
[41]
Microscopic and collective signatures of feature learning in neural networks,
Andrea Corti, Rosalba Pacelli, Pietro Rotondo, and Marco Gherardi, “Microscopic and collective signatures of feature learning in neural networks,” arXiv:2508.20989 (2025)
-
[42]
Separation of scales and a thermodynamic description of feature learning in some cnns,
Inbar Seroussi, Gadi Naveh, and Zohar Ringel, “Separation of scales and a thermodynamic description of feature learning in some cnns,” Nature Communications 14, 908 (2023)
2023
-
[43]
Critical feature learning in deep neural networks,
Kirsten Fischer, Javed Lindner, David Dahmen, Zohar Ringel, Michael Kr¨ amer, and Moritz Helias, “Critical feature learning in deep neural networks,” inProceedings of the 41st International Conference on Machine Learning, PMLR, Vol. 235 (2024) pp. 13660–13690
2024
-
[44]
Adaptive kernel predictors from feature-learning infinite limits of neural networks,
Clarissa Lauditi, Blake Bordelon, and Cengiz Pehlevan, “Adaptive kernel predictors from feature-learning infinite limits of neural networks,” inProceedings of the 42nd International Conference on Machine Learning, PMLR, Vol. 267 (2025) pp. 32617–32648
2025
-
[45]
Coding schemes in neural networks learning classification tasks,
Alexander van Meegen and Haim Sompolinsky, “Coding schemes in neural networks learning classification tasks,” Nature Communications16, 3354 (2025)
2025
-
[46]
LDP for the covariance process in fully connected Gaussian neural networks,
Luisa Andreis, Federico Bassetti, and Christian Hirsch, “LDP for the covariance process in fully connected Gaussian neural networks,” Electronic Journal of Probability31, 1 – 35 (2026)
2026
-
[47]
Why bigger is not always better: on finite and infinite neural networks,
Laurence Aitchison, “Why bigger is not always better: on finite and infinite neural networks,” inProceedings of the 37th International Conference on Machine Learning, PMLR, Vol. 119 (2020) pp. 156–164
2020
-
[48]
The large deviation approach to statistical mechanics,
Hugo Touchette, “The large deviation approach to statistical mechanics,” Physics Reports478, 1–69 (2009)
2009
-
[49]
Kernel shape renormalization in bayesian shallow networks: a gaussian process perspective,
Rosalba Pacelli, Lorenzo Giambagli, and Paolo Baglioni, “Kernel shape renormalization in bayesian shallow networks: a gaussian process perspective,” in2024 IEEE Workshop on Complexity in Engineering (COMPENG) (2024) pp. 1–6
2024
-
[50]
Carl Edward Rasmussen and Christopher K. I. Williams, Gaussian Processes for Machine Learning(The MIT Press, 2005)
2005
-
[51]
An integral which occurs in statistics,
A. E. Ingham, “An integral which occurs in statistics,” Mathematical Proceedings of the Cambridge Philosophical Society29, 271–276 (1933)
1933
-
[52]
¨Uber Die Analytische Theorie Der Quadratischen Formen,
Carl Ludwig Siegel, “ ¨Uber Die Analytische Theorie Der Quadratischen Formen,” Annals of Mathematics36, 527–606 (1935)
1935
-
[53]
Constantine Pozrikidis,An introduction to grids, graphs, and networks(Oxford University Press, 2014)
2014
-
[54]
Deep convolutional networks as shallow gaussian processes,
Adri` a Garriga-Alonso, Carl Edward Rasmussen, and Laurence Aitchison, “Deep convolutional networks as shallow gaussian processes,” inInternational Conference on Learning Representations(2019)
2019
-
[55]
deepbays,
R. Pacelli and P. Baglioni, “deepbays,”https://github. com/rpacelli/deepbays(2026-05-28), The full analysis code and numerical results will be provided with the published version of the paper
2026
-
[56]
Monte carlo errors with less errors,
Ulli Wolff, “Monte carlo errors with less errors,” Computer Physics Communications156, 143–153 (2004)
2004
-
[57]
What are bayesian neural network posteriors really like?
Pavel Izmailov, Sharad Vikram, Matthew D. Hoffman, and Andrew Gordon Wilson, “What are bayesian neural network posteriors really like?” inInternational Conference on Machine Learning(2021)
2021
-
[58]
Globally gated deep linear networks,
Qianyi Li and Haim Sompolinsky, “Globally gated deep linear networks,” Advances in Neural Information Processing Systems35, 34789–34801 (2022)
2022
-
[59]
Random fully connected neural networks as perturbatively solvable hierarchies,
Boris Hanin, “Random fully connected neural networks as perturbatively solvable hierarchies,” Journal of Machine Learning Research25, 1–58 (2024). 26
2024
-
[60]
The no-u-turn sampler: adaptively setting path lengths in hamiltonian monte carlo
Matthew D Hoffman, Andrew Gelman,et al., “The no-u-turn sampler: adaptively setting path lengths in hamiltonian monte carlo.” Journal of Machine Learning Research15, 1593–1623 (2014)
2014
-
[61]
Comments on “Representations of knowledge in complex systems
Julian Besag, “Comments on “Representations of knowledge in complex systems” by U. Grenander and M. I. Miller,” inJournal of the Royal Statistical Society Seies B, Vol. 56 (1994) pp. 591–592
1994
-
[62]
Exponential convergence of langevin distributions and their discrete approximations,
Gareth O Roberts and Richard L Tweedie, “Exponential convergence of langevin distributions and their discrete approximations,” Bernoulli2, 341–363 (1996)
1996
-
[63]
Mcmc methods for functions: modifying old algorithms to make them faster,
Simon L Cotter, Gareth O Roberts, Andrew M Stuart, and David White, “Mcmc methods for functions: modifying old algorithms to make them faster,” Statistical Science , 424–446 (2013)
2013
-
[64]
Self-consistent dynamical field theory of kernel evolution in wide neural networks,
Blake Bordelon and Cengiz Pehlevan, “Self-consistent dynamical field theory of kernel evolution in wide neural networks,” Advances in Neural Information Processing Systems35, 32240–32256 (2022)
2022
-
[65]
Mitigating the curse of detail: Scaling arguments for feature learning and sample complexity,
Noa Rubin, Orit Davidovich, and Zohar Ringel, “Mitigating the curse of detail: Scaling arguments for feature learning and sample complexity,” arXiv:2512.04165 (2025)
-
[66]
Finite depth and width corrections to the neural tangent kernel,
Boris Hanin and Mihai Nica, “Finite depth and width corrections to the neural tangent kernel,” inInternational Conference on Learning Representations(2020)
2020
-
[67]
Gibbs Measures from Deep Shaped Multilayer Perceptrons,
Boris Hanin and Alexander Zlokapa, “Gibbs Measures from Deep Shaped Multilayer Perceptrons,” Physical Review Letters136, 067301 (2026)
2026
-
[68]
The Loss Surfaces of Multilayer Networks,
Anna Choromanska, MIkael Henaff, Michael Mathieu, Gerard Ben Arous, and Yann LeCun, “The Loss Surfaces of Multilayer Networks,” inProceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, PMLR, Vol. 38 (2015) pp. 192–204
2015
-
[69]
Deep learning without poor local minima,
Kenji Kawaguchi, “Deep learning without poor local minima,” Advances in neural information processing systems29(2016)
2016
-
[70]
Loss surfaces, mode connectivity, and fast ensembling of dnns,
Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry Vetrov, and Andrew G Wilson, “Loss surfaces, mode connectivity, and fast ensembling of dnns,” in Advances in Neural Information Processing Systems, Vol. 31, edited by S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Curran Associates, Inc., 2018)
2018
-
[71]
Essentially no barriers in neural network energy landscape,
Felix Draxler, Kambis Veschgini, Manfred Salmhofer, and Fred Hamprecht, “Essentially no barriers in neural network energy landscape,” inProceedings of the 35th International Conference on Machine Learning, PMLR, Vol. 80 (2018) pp. 1309–1318
2018
-
[72]
Jean Barbier, Francesco Camilli, Minh-Toan Nguyen, Mauro Pastore, and Rudy Skerk, “Optimal generalisation and learning transition in extensive- width shallow neural networks near interpolation,” arXiv:2501.18530 (2025)
-
[73]
Bayes- optimal learning of an extensive-width neural network from quadratically many samples,
Antoine Maillard, Emanuele Troiani, Simon Martin, Lenka Zdeborov´ a, and Florent Krzakala, “Bayes- optimal learning of an extensive-width neural network from quadratically many samples,” inAdvances in Neural Information Processing Systems, Vol. 37 (Curran Associates, Inc., 2024) pp. 82085–82132
2024
-
[74]
The nuclear route: Sharp asymptotics of ERM in overparameterized quadratic networks,
Vittorio Erba, Emanuele Troiani, Lenka Zdeborova, and Florent Krzakala, “The nuclear route: Sharp asymptotics of ERM in overparameterized quadratic networks,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems(2026)
2026
-
[75]
An empirical analysis of compute-optimal large language model training,
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katherine Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Oriol Vinyals, Jack William Rae, and Laur...
2022
-
[76]
Deep equals shallow for reLU networks in kernel regimes,
Alberto Bietti and Francis Bach, “Deep equals shallow for reLU networks in kernel regimes,” inInternational Conference on Learning Representations(2021)
2021
-
[77]
Estimates of singular numbers of integral operators,
M Sh Birman and M Z Solomyak, “Estimates of singular numbers of integral operators,” Russian Mathematical Surveys32, 15 (1977)
1977
-
[78]
Understanding the difficulty of training deep feedforward neural networks,
Xavier Glorot and Yoshua Bengio, “Understanding the difficulty of training deep feedforward neural networks,” inProceedings of the thirteenth international conference on artificial intelligence and statistics(JMLR Workshop and Conference Proceedings, 2010) pp. 249–256
2010
-
[79]
Composable Effects for Flexible and Accelerated Probabilistic Programming in NumPyro
Du Phan, Neeraj Pradhan, and Martin Jankowiak, “Composable effects for flexible and accelerated probabilistic programming in numpyro,” arXiv:1912.11554 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[80]
Inference from Iterative Simulation Using Multiple Sequences,
Andrew Gelman and Donald B. Rubin, “Inference from Iterative Simulation Using Multiple Sequences,” Statistical Science7, 457–472 (1992). 27 Appendix A: Non-central equivalent Wishart Ansatz
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.