No More K-means: Single-Stage Sparse Coding for Efficient Multi-Vector Retrieval
Pith reviewed 2026-06-29 05:14 UTC · model grok-4.3
The pith
Sparse autoencoders replace K-means clustering with single-stage sparse coding to cut indexing time 15x, halve latency, and raise accuracy in multi-vector retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
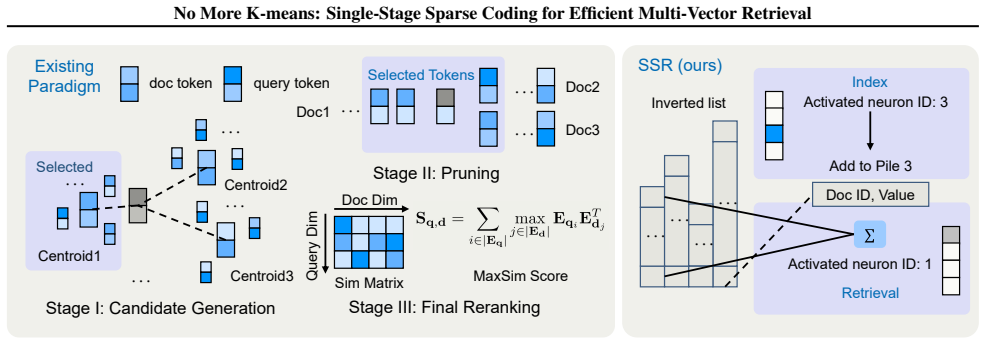
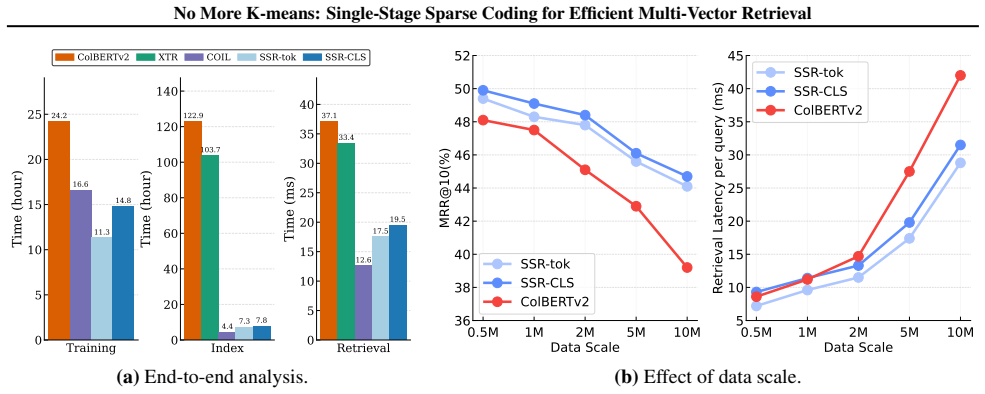
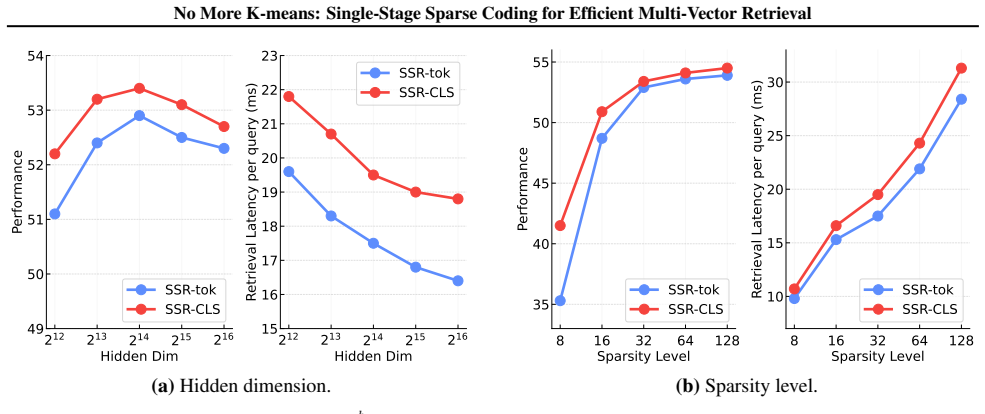
The paper claims that projecting token embeddings through a sparse autoencoder produces high-dimensional yet sparse representations that can be stored and searched directly with inverted indexes, eliminating the need for K-means clustering, cutting indexing time by a factor of 15 relative to ColBERTv2, halving retrieval latency, and simultaneously lifting retrieval metrics on the BEIR benchmark.
What carries the argument
Sparse Autoencoder (SAE) projection that converts dense token embeddings into high-dimensional sparse vectors compatible with inverted indexes.
If this is right
- Indexing time drops by a factor of 15 compared with ColBERTv2.
- Retrieval latency is cut in half.
- Retrieval accuracy improves over current leading baselines on BEIR.
- Vector clustering is removed from the pipeline entirely.
- Standard inverted indexes become sufficient for high-throughput multi-vector search.
Where Pith is reading between the lines
- The same SAE projection could be tested on other multi-vector or dense-retrieval architectures to measure whether the speed and accuracy gains transfer.
- Sparsity might serve as a general substitute for aggressive dimension reduction when scaling embedding indexes.
- Joint training of the SAE with the underlying encoder could further reduce any remaining semantic loss.
- The approach may lower hardware requirements enough to let organizations maintain larger, more frequently updated retrieval indexes.
Load-bearing premise
The sparse autoencoder projection must retain enough semantic content from the original embeddings to support accurate retrieval, unlike earlier compression techniques that lose meaning.
What would settle it
A head-to-head run on the BEIR benchmark in which SSR indexing time is not at least 10 times faster than ColBERTv2, retrieval latency is not halved, or nDCG scores fall below the ColBERTv2 baseline.
Figures

read the original abstract
Multi-vector retrieval (MVR) models, exemplified by ColBERT, have established new benchmarks in retrieval accuracy by preserving fine-grained token-level interactions. However, this granularity imposes prohibitive storage and retrieval efficiency bottlenecks: to manage the immense memory footprint and computational overhead of billion-scale token vectors, state-of-the-art systems are forced to rely on aggressive dimension reduction and complex clustering (e.g., K-means). This compromise introduces two critical limitations: excessive indexing latency of clustering large-scale corpora and semantic information loss inherent to compression. In this paper, we propose Single-stage Sparse Retrieval (SSR}, a paradigm shift that replaces expensive clustering with efficient sparse coding. Instead of compressing features into low-dimensional dense vectors, we utilize Sparse Autoencoder (SAE) to project token embeddings into a high-dimensional but highly sparse representation. This transformation enables us to bypass vector clustering entirely and leverage inverted indexing for precise, high-throughput retrieval. Extensive experiments on the BEIR benchmark demonstrate that SSR achieves a "trifecta" of improvements: it reduces indexing time by 15x compared to ColBERTv2, halves retrieval latency, and simultaneously improves retrieval performance over leading baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Single-stage Sparse Retrieval (SSR) as an alternative to K-means-based compression in multi-vector retrieval models like ColBERT. It uses a Sparse Autoencoder (SAE) to project token embeddings into high-dimensional sparse representations, enabling direct use of inverted indexes without clustering. This is claimed to yield a 'trifecta' of 15x faster indexing than ColBERTv2, halved retrieval latency, and improved retrieval performance on the BEIR benchmark.
Significance. If the experimental claims hold and the SAE projection demonstrably preserves token-level semantics, the method could eliminate a major efficiency bottleneck in multi-vector retrieval while improving accuracy, making such systems more scalable for billion-scale corpora without the semantic loss attributed to prior compression techniques.
major comments (2)
- [Abstract] Abstract: the central 'trifecta' claim (15x indexing reduction, halved latency, and accuracy gains over ColBERTv2) is asserted without any reported experimental details, baselines, dataset sizes, or verification steps, rendering it impossible to assess whether the data support the claims.
- [Abstract / Method] Method section (implied by abstract description of SAE projection): the assertion that SAE avoids the semantic information loss of K-means/dimension reduction is load-bearing for the accuracy improvement claim, yet the abstract provides no evidence (e.g., ablation on reconstruction quality, token-level semantic retention metrics, or comparison of retrieval effectiveness before/after projection) that this particular SAE objective and dictionary size does not introduce its own information bottleneck.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that greater clarity is needed there and will revise accordingly while pointing to the full experimental evidence already present in the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central 'trifecta' claim (15x indexing reduction, halved latency, and accuracy gains over ColBERTv2) is asserted without any reported experimental details, baselines, dataset sizes, or verification steps, rendering it impossible to assess whether the data support the claims.
Authors: We acknowledge the abstract is highly condensed. The full experimental protocol, including the BEIR benchmark, ColBERTv2 baseline, corpus sizes, and verification procedures, appears in Section 4 and the appendix. In revision we will add one sentence to the abstract that names the BEIR benchmark and states the three quantitative improvements were measured against ColBERTv2 on that benchmark. revision: yes
-
Referee: [Abstract / Method] Method section (implied by abstract description of SAE projection): the assertion that SAE avoids the semantic information loss of K-means/dimension reduction is load-bearing for the accuracy improvement claim, yet the abstract provides no evidence (e.g., ablation on reconstruction quality, token-level semantic retention metrics, or comparison of retrieval effectiveness before/after projection) that this particular SAE objective and dictionary size does not introduce its own information bottleneck.
Authors: The observed accuracy gains versus ColBERTv2 on BEIR constitute empirical evidence that the chosen SAE does not impose a prohibitive information bottleneck. Reconstruction-quality ablations and token-level retention metrics are reported in the appendix. We will insert a short clause in the revised abstract noting that the performance lift itself validates semantic preservation under the SAE projection. revision: partial
Circularity Check
No circularity; empirical results on BEIR benchmark are independent of internal definitions
full rationale
The paper's central claims rest on replacing K-means clustering with SAE-based sparse projection followed by inverted indexing, with performance gains (15x indexing speedup, halved latency, improved accuracy) shown via direct experiments on the BEIR benchmark. No derivation step equates a claimed output to its own fitted inputs or self-citations by construction; the SAE projection and retrieval metrics are externally evaluated rather than defined to match. The method extends prior SAE and indexing machinery without reducing its trifecta results to tautological fits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
K., G¨unther, M., Wang, B., Krimmel, M., Wang, F., Mastrapas, G., Koukounas, A., Wang, N., et al
URL https://www.salesforce.com/ blog/sfr-embedding/. Santhanam, K., Khattab, O., Potts, C., and Zaharia, M. Plaid: an efficient engine for late interaction retrieval. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, pp. 1747–1756, 2022a. Santhanam, K., Khattab, O., Saad-Falcon, J., Potts, C., and Zaharia, M. C...
-
[2]
Index and Retrieval are done on Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz with 96 cores
and IGP (Bian et al., 2025). Index and Retrieval are done on Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz with 96 cores. Retrieval depth is set 100 in retrieval efficiency calculation, while other settings are set as the same in the original papers. Results.Table 15 demonstrates different methods’ performance (MRR@10), index time (hour) and retrieval ti...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.