CodeGolf Bench: A Multi-Language Benchmark for Evaluating Concise Code Generation Capabilities of Large Language Models
Pith reviewed 2026-06-29 06:23 UTC · model grok-4.3
The pith
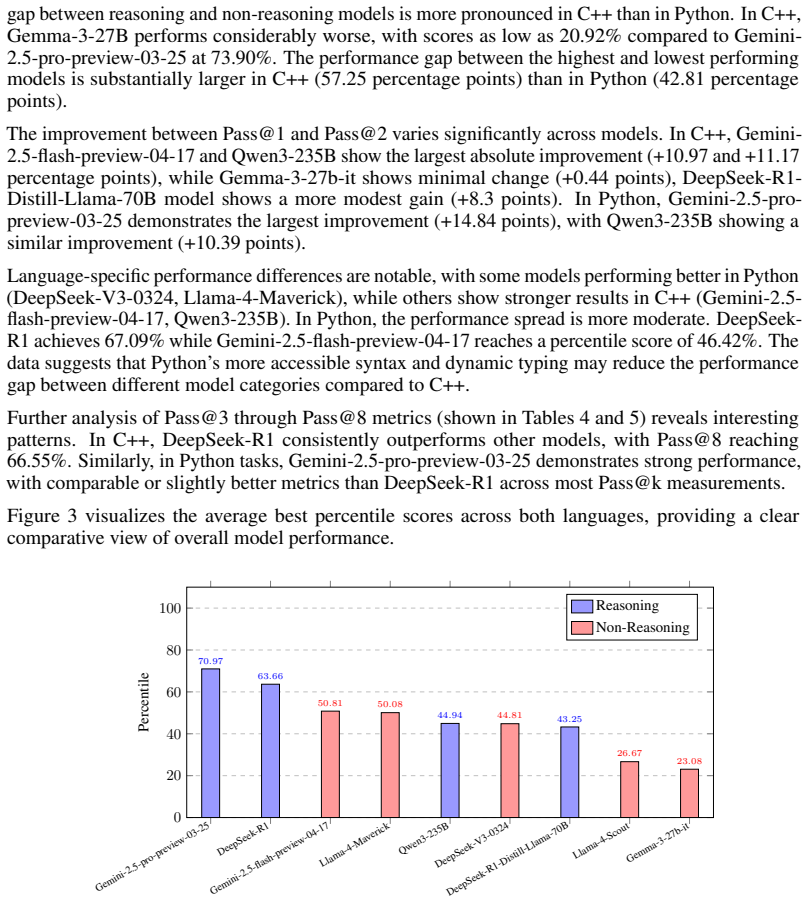
Reasoning LLMs reach 70.97 average percentile on code golf tasks while non-reasoning models lag
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
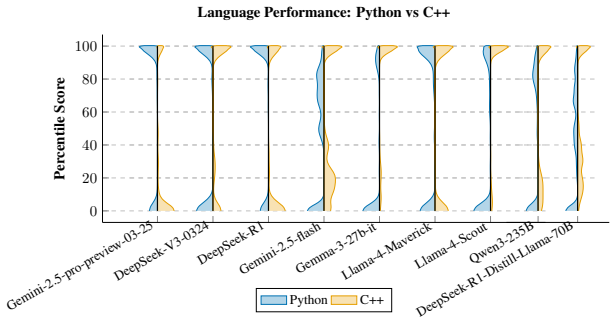
CodeGolf Bench evaluates LLMs on concise code generation by comparing their solutions' lengths to human percentiles on code.golf problems. In tests on Python and C++ tasks, reasoning models reached a best average percentile of 70.97%, while non-reasoning models scored significantly lower. The performance difference is larger in C++ than in Python.
What carries the argument
CodeGolf Bench, which pulls new problems and human baselines from the code.golf platform to measure concise code generation in multiple languages.
If this is right
- Reasoning models are better at optimizing code for brevity in languages with strict syntax.
- Non-reasoning models particularly struggle with efficiency optimization across both languages.
- The benchmark supports evaluation in up to 60 languages for broader coverage.
- Dynamic human baselines enable continuous tracking of LLM progress as new solutions appear.
Where Pith is reading between the lines
- The benchmark could be used to test whether explicit reasoning steps improve an LLM's ability to compress code solutions.
- It may apply to practical settings where minimal code size matters, such as resource-constrained devices.
- Evaluating additional languages could expose which syntax features create the largest gaps between model types.
- Live baselines mean benchmark scores for a given model can shift downward over time if humans find shorter solutions.
Load-bearing premise
The code.golf problems and human baselines provide an unbiased measure of concise code generation ability without platform-specific biases.
What would settle it
Running the same LLMs on a new set of code.golf problems and measuring whether their solution lengths consistently fall below the top human submissions on those problems would test if the reported performance advantage holds.
Figures




read the original abstract
This paper introduces Code Bench, a benchmark capable of evaluating Large Language Models (LLMs) concise code generation abilities in 60 programming languages. Based on code golf, a recreational programming competition focused on minimal character or byte solutions, the benchmark provides a distinctive measure of LLMs ability to produce efficient, concise code. Unlike existing benchmarks limited by fixed problem sets and language coverage, CodeGolf Bench leverages the code.golf platform to provide new problems and live human performance baselines. Evaluation of nine LLMs on Python and C++ tasks demonstrates that reasoning models significantly outperform non-reasoning models, achieving best average percentile of 70.97%. This performance gap is particularly pronounced in C++, highlighting reasoning's importance for languages with strict syntax requirements. Non-reasoning models struggle more with efficiency optimization across both languages, with best percentiles significantly lower than reasoning counterparts. CodeGolf Bench offers a dynamic framework for evaluating LLM code generation capabilities against evolving human performance on code golf.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CodeGolf Bench, a benchmark for evaluating LLMs' concise code generation capabilities across 60 programming languages, derived from the code.golf platform to leverage new problems and live human baselines. It reports an evaluation of nine LLMs on Python and C++ tasks, claiming that reasoning models significantly outperform non-reasoning models with a best average percentile of 70.97%, with the gap especially pronounced in C++.
Significance. If the human baselines prove representative and free of platform artifacts, the benchmark could offer a dynamic, evolving framework for measuring code conciseness that complements fixed-problem suites. The reported advantage for reasoning models in C++ would then provide evidence that chain-of-thought or similar techniques aid optimization under strict syntactic constraints.
major comments (2)
- [Abstract] Abstract: the central claim that reasoning models achieve a best average percentile of 70.97% (and a larger gap in C++) is presented without any description of how percentiles are computed from code.golf submissions, the number or selection criteria for tasks, the definition of reference length, or controls for submission-volume or language-popularity biases. These omissions are load-bearing for the outperformance conclusion.
- [Benchmark description] Benchmark description (presumed §3): the assertion that code.golf supplies 'unbiased' human baselines and representative problems is not accompanied by any analysis of selection effects (golfability bias) or normalization procedures, leaving the reported C++ advantage vulnerable to platform-specific confounds rather than a general property of reasoning models.
minor comments (1)
- [Abstract] Abstract: the benchmark is advertised for 60 languages yet only Python and C++ results are shown; a brief statement on the scope of the initial evaluation would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater methodological transparency. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that reasoning models achieve a best average percentile of 70.97% (and a larger gap in C++) is presented without any description of how percentiles are computed from code.golf submissions, the number or selection criteria for tasks, the definition of reference length, or controls for submission-volume or language-popularity biases. These omissions are load-bearing for the outperformance conclusion.
Authors: We agree that the abstract would benefit from additional context to support the central claims. In the revised manuscript we will expand the abstract to briefly state that percentiles are computed by ranking each model submission against all human submissions on the same code.golf problem (using the shortest valid human solution as the reference length), that the evaluation uses a fixed set of 50 Python and 50 C++ problems selected for having at least 100 human submissions, and that problems were chosen to balance submission volume across languages. A short clause on bias mitigation will also be added. revision: yes
-
Referee: [Benchmark description] Benchmark description (presumed §3): the assertion that code.golf supplies 'unbiased' human baselines and representative problems is not accompanied by any analysis of selection effects (golfability bias) or normalization procedures, leaving the reported C++ advantage vulnerable to platform-specific confounds rather than a general property of reasoning models.
Authors: Section 3 describes the construction of the benchmark from live code.golf data, but we acknowledge that an explicit discussion of selection effects is absent. We will add a new paragraph in the revision that (a) notes the golfability bias inherent in the platform (problems are chosen by the community for their amenability to short solutions), (b) reports that we restricted the task set to problems with sufficient submission volume to reduce popularity effects, and (c) explains that no additional normalization beyond percentile ranking was applied. We will qualify the term 'unbiased' to 'live, community-provided baselines' and discuss the implications for interpreting the C++ results. revision: yes
Circularity Check
No circularity: benchmark uses external code.golf data and baselines as independent reference
full rationale
The paper introduces CodeGolf Bench by directly adopting problems and human performance baselines from the external code.golf platform without any fitting of parameters, self-definitional mappings, or load-bearing self-citations. The central evaluation (reasoning models at 70.97% average percentile on Python/C++ tasks) compares LLM outputs against these external human baselines; no equation or claim reduces the reported gap to a quantity derived from the paper's own inputs or prior self-work. The derivation chain is therefore self-contained against an external benchmark source.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
URL https://arxiv.org/ abs/2108.07732. M. Beltrán-Escobar, T. E. Alarcón, J. Y . Rumbo-Morales, S. López, G. Ortiz-Torres, and F. D. J. Sorcia-Vázquez. A review on resource-constrained embedded vision systems–based tiny machine learning for robotic applications.Algorithms, 17(11):476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
doi: 10.3390/a17110476. J. Bungo. The use of compiler optimizations for embedded systems software.ACM Crossroads, 15 (1):10–18,
-
[4]
Bigo(bench) -- can llms generate code with controlled time and space complexity?, 2025
URL https://arxiv.org/ abs/2503.15242. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique P. de O. Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, and Alex Ray. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
-
[5]
Evaluating Large Language Models Trained on Code
URL https://arxiv.org/ abs/2107.03374. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with apps. InAdvances in Neural Information Processing Systems, volume 34, pages 24936–24948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
10 Dong Huang, Yuhao Qing, Weiyi Shang, Heming Cui, and Jie M
URL https://proceedings.neurips.cc/paper/2021/hash/ 9fd1da39760a8a8a3c6cf8e497b0baa3-Abstract.html. 10 Dong Huang, Yuhao Qing, Weiyi Shang, Heming Cui, and Jie M. Zhang. Effibench: Benchmarking the efficiency of automatically generated code,
2021
-
[8]
URLhttps://arxiv.org/abs/2310.06220. Mohammad Abdullah Matin Khan, M Saiful Bari, Xuan Long Do, Weishi Wang, Md Rizwan Parvez, and Shafiq Joty. XCodeEval: An execution-based large scale multilingual multitask benchmark for code understanding, generation, translation and retrieval. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of th...
-
[9]
doi: 10.18653/v1/2024.acl-long.367
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.367. URLhttps://aclanthology.org/2024.acl-long.367/. Rainer Leupers.Code Optimization Techniques for Embedded Processors: Methods, Algorithms, and Tools. Kluwer Academic Publishers, USA,
-
[10]
URL https: //arxiv.org/abs/2311.12721. Shanghaoran Quan, Jiaxi Yang, Bowen Yu, Bo Zheng, Dayiheng Liu, An Yang, Xuancheng Ren, Bofei Gao, Yibo Miao, Yunlong Feng, Zekun Wang, Jian Yang, Zeyu Cui, Yang Fan, Yichang Zhang, Binyuan Hui, and Junyang Lin. Codeelo: Benchmarking competition-level code generation of llms with human-comparable elo ratings,
- [11]
-
[12]
URLhttps://arxiv.org/abs/2404.10952. Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz- Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, Shubh-Agrawal, Sandeep Singh Sandha, Siddartha Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, and Micah Goldblum. Livebench: A challenging, contamination...
-
[13]
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
URL https://arxiv. org/abs/2406.19314. Wikipedia contributors. Code golf — Wikipedia, the free encyclopedia,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
wikipedia.org/wiki/Code_golf
URL https://en. wikipedia.org/wiki/Code_golf. [Online; accessed 2024]. Zhaojian Yu, Yilun Zhao, Arman Cohan, and Xiao-Ping Zhang. Humaneval pro and mbpp pro: Evaluating large language models on self-invoking code generation,
2024
-
[15]
URL https://arxiv. org/abs/2412.21199. 11 A Technical Appendices and Supplementary Material Table 3: Benchmark comparison Benchmark compari- son Publicly Available Dataset Publicly Available Solutions Publicly Available Test Cases APPS Yes Yes Yes xCodeEval Yes Yes Yes CodeElo Yes Limited Limited LiveBench Yes Yes Yes (Questions) BigO(Bench) Yes Yes (Anno...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.