Dex2HOI: Dexterous Bimanual Two-Object Interaction Generation
Pith reviewed 2026-06-29 08:03 UTC · model grok-4.3
The pith
A dual-stream diffusion model generates dexterous bimanual two-object interactions from text at real-time speeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
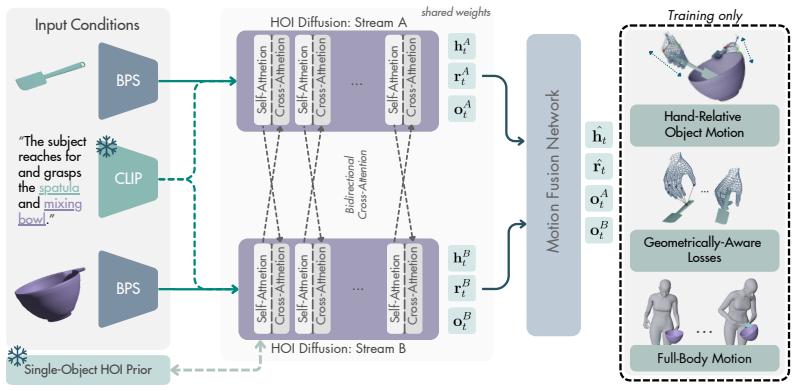
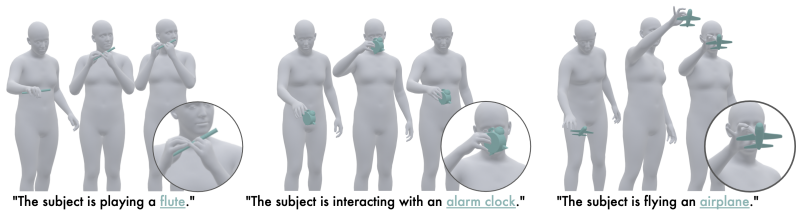
Dex2HOI is a unified diffusion model for single- and two-object HOI synthesis from text. It processes each object in a dedicated stream coordinated by bidirectional cross-attention, fuses the streams with a Motion Fusion Network that uses hand-relative object representations and contact-aware conditioning, and samples the diffusion process autoregressively over prefix-conditioned windows to produce arbitrarily long sequences at real-time speed while omitting test-time optimization.
What carries the argument
Dual-Stream Diffusion architecture with bidirectional cross-attention, Motion Fusion Network, hand-relative representations, contact-aware conditioning, and autoregressive prefix-conditioned window sampling.
If this is right
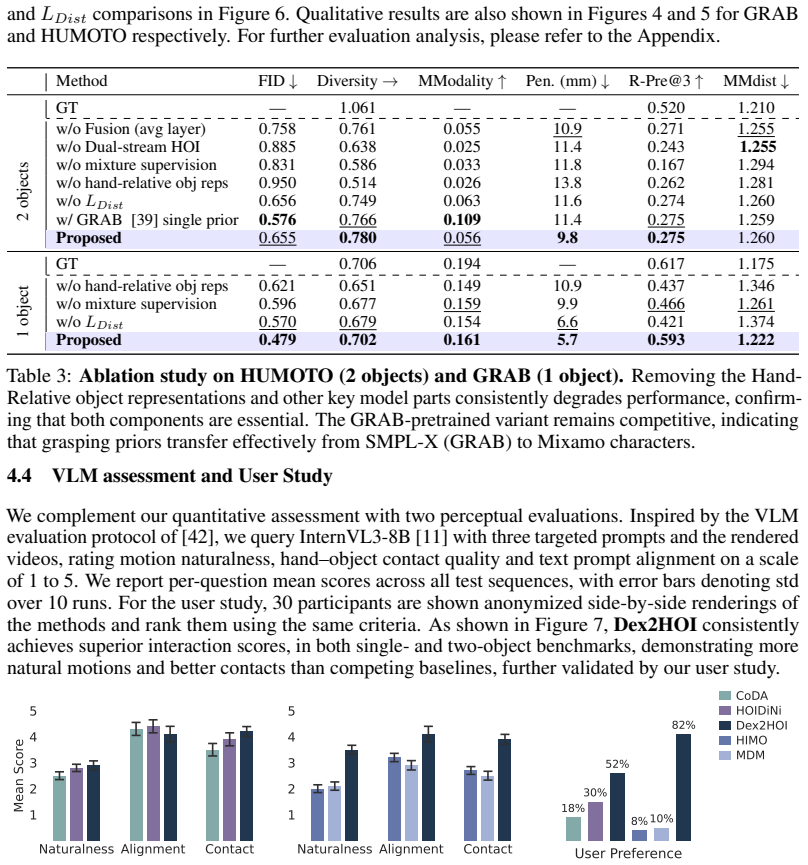
- Achieves state-of-the-art quantitative results on single- and two-object HOI benchmarks.
- Generates arbitrarily long sequences at real-time speed.
- Delivers up to 540 times inference speedup over prior state-of-the-art methods.
- Supports both single-object and two-object cases inside one model.
- Removes the need for redundant test-time optimization steps.
Where Pith is reading between the lines
- Adding further streams could extend the approach to three or more objects.
- Real-time performance may suit interactive uses such as virtual environments or robot planning.
- Hand-relative representations could improve generalization to novel object geometries.
Load-bearing premise
The dual-stream diffusion with bidirectional cross-attention and contact-aware conditioning produces coherent coordinated bimanual two-object motions without post-hoc optimization.
What would settle it
Test generations on two-object prompts that exhibit frequent hand-object interpenetrations or visibly uncoordinated hand movements.
Figures




read the original abstract
Recent advances in 4D Human-Object Interaction (HOI) generation have enabled increasingly realistic motion synthesis, particularly for single-object manipulation. Yet current research overlooks an inherent property of human behavior: people naturally coordinate both hands and manipulate multiple objects simultaneously. To address this gap, we present Dex2HOI, a unified diffusion model for single- and two-object HOI synthesis from text. At its core, Dex2HOI employs a Dual-Stream Diffusion approach, where each object is processed in a dedicated interaction stream and coordinated through bidirectional cross-attention. To synthesize the final motion, we introduce a Motion Fusion Network integrated with novel hand-relative object representations and contact-aware conditioning applied across the whole sequence. By sampling the diffusion process autoregressively over prefix-conditioned windows, Dex2HOI generates arbitrarily long sequences at real-time speed omitting redundant test-time optimization, achieving up to x540 inference speed-up over prior state-of-the-art methods. Extensive evaluation on both single- and two-object benchmarks demonstrates state-of-the-art quantitative results, marking a step beyond conventional single-object HOI generation and toward expressive multi-object manipulation. Code and models will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dex2HOI, a unified text-conditioned diffusion model for generating dexterous bimanual single- and two-object human-object interactions. Its core components are a dual-stream diffusion architecture with bidirectional cross-attention between object streams, hand-relative object representations, contact-aware conditioning, a Motion Fusion Network, and autoregressive sampling over prefix-conditioned windows that enables arbitrarily long sequences in real time without test-time optimization, yielding up to 540x inference speedup over prior methods while reporting SOTA quantitative results on single- and two-object benchmarks.
Significance. If the architectural claims hold, the work meaningfully extends 4D HOI generation beyond single-object cases to coordinated bimanual multi-object manipulation and removes a major practical bottleneck (test-time optimization) for long-horizon synthesis. The combination of dual-stream coordination and prefix-window autoregression is a concrete step toward scalable, real-time motion generation with potential downstream value in robotics and animation.
minor comments (2)
- [Abstract] Abstract states that the model achieves 'state-of-the-art quantitative results' on both single- and two-object benchmarks, but does not name the specific metrics, datasets, or competing methods used for the comparison.
- [Abstract] The description of the Motion Fusion Network and how contact-aware conditioning is applied 'across the whole sequence' would benefit from an explicit diagram or pseudocode showing the data flow between the dual streams and the fusion stage.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of Dex2HOI, the recognition of its contributions to bimanual multi-object HOI generation, and the recommendation for minor revision. No major comments were listed in the report.
Circularity Check
No significant circularity detected
full rationale
The paper introduces a new dual-stream diffusion architecture for bimanual two-object HOI generation, relying on bidirectional cross-attention, hand-relative representations, contact-aware conditioning, and autoregressive prefix-window sampling. No equations, fitted parameters, or predictions are described that reduce by construction to the inputs. No self-citations are invoked as load-bearing justifications for uniqueness theorems, ansatzes, or derivations. The speedup claim follows directly from the architectural choice to omit test-time optimization, and the model is presented as self-contained without any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adobe mixamo.https://www.mixamo.com/
Adobe Inc. Adobe mixamo.https://www.mixamo.com/
-
[2]
Physically plausible full-body hand-object interaction synthesis
Jona Braun, Sammy Christen, Muhammed Kocabas, Emre Aksan, and Otmar Hilliges. Physically plausible full-body hand-object interaction synthesis. InInternational Conference on 3D Vision (3DV), 2024
2024
-
[3]
Text2hoi: Text-guided 3d motion generation for hand-object interaction
Junuk Cha, Jihyeon Kim, Jae Shin Yoon, and Seungryul Baek. Text2hoi: Text-guided 3d motion generation for hand-object interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[4]
Narang, Karl Van Wyk, Umar Iqbal, Stan Birchfield, Jan Kautz, and Dieter Fox
Yu-Wei Chao, Wei Yang, Yu Xiang, Pavlo Molchanov, Ankur Handa, Jonathan Tremblay, Yashraj S. Narang, Karl Van Wyk, Umar Iqbal, Stan Birchfield, Jan Kautz, and Dieter Fox. DexYCB: A benchmark for capturing hand grasping of objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[5]
Executing your commands via motion diffusion in latent space
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. Executing your commands via motion diffusion in latent space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[6]
Object-centric dexterous manipulation from human motion data
Yuanpei Chen, Chen Wang, Yaodong Yang, and Karen Liu. Object-centric dexterous manipulation from human motion data. InConference on Robot Learning (CoRL)
-
[7]
HO-Flow: Generalizable Hand-Object Interaction Generation with Latent Flow Matching
Zerui Chen, Rolandos Alexandros Potamias, Shizhe Chen, Jiankang Deng, Cordelia Schmid, and Stefanos Zafeiriou. Ho-flow: Generalizable hand-object interaction generation with latent flow matching.arXiv preprint arXiv:2604.10836, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Diffh2o: Diffusion-based synthesis of hand-object interactions from textual descriptions
Sammy Christen, Shreyas Hampali, Fadime Sener, Edoardo Remelli, Tomas Hodan, Eric Sauser, Shugao Ma, and Bugra Tekin. Diffh2o: Diffusion-based synthesis of hand-object interactions from textual descriptions. InSIGGRAPH Asia Conference Papers, 2024
2024
-
[9]
Peishan Cong, Ziyi Wang, Zhiyang Dou, Yiming Ren, Wei Yin, Kai Cheng, Yujing Sun, Xiaoxiao Long, Xinge Zhu, and Yuexin Ma. Laserhuman: language-guided scene-aware human motion generation in free environment.arXiv preprint arXiv:2403.13307, 2024
-
[10]
Contact-guided 3d human-object interaction generation
Christian Diller et al. Contact-guided 3d human-object interaction generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[11]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Black, and Otmar Hilliges
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kaufmann, Michael J. Black, and Otmar Hilliges. ARCTIC: A dataset for dexterous bimanual hand-object manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[13]
Hongming Fu, Wenjia Wang, Xiaozhen Qiao, Rolandos Alexandros Potamias, Taku Komura, Shuo Yang, Zheng Liu, and Bo Zhao. Egograsp: World-space hand-object interaction estimation from egocentric videos.arXiv preprint arXiv:2601.01050, 2026
-
[14]
Imos: Intent-driven full-body motion synthesis for human-object interactions
Anindita Ghosh, Rishabh Dabral, Vladislav Golyanik, Christian Theobalt, and Philipp Slusallek. Imos: Intent-driven full-body motion synthesis for human-object interactions. InEurographics, 2023
2023
-
[15]
Hoigpt: Learning long sequence hand-object interaction with language models
Mingzhen Huang, Fu-Jen Chu, Bugra Tekin, Kevin J Liang, Haoyu Ma, Weiyao Wang, Xingyu Chen, Pierre Gleize, Hongfei Xue, Siwei Lyu, Kris Kitani, Matt Feiszli, and Hao Tang. Hoigpt: Learning long sequence hand-object interaction with language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[16]
Diffusion-based generation, optimization, and planning in 3d scenes
Siyuan Huang, Zan Wang, Puhao Li, Baoxiong Jia, Tengyu Liu, Yixin Zhu, Wei Liang, and Song-Chun Zhu. Diffusion-based generation, optimization, and planning in 3d scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 10
2023
-
[17]
Full-body articulated human-object interaction.arXiv preprint arXiv:2212.10621, 2023
Nan Jiang, Tengyu Liu, Zhexuan Cao, Jieming Cui, Zhiyuan zhang, Yixin Chen, He Wang, Yixin Zhu, and Siyuan Huang. Full-body articulated human-object interaction.arXiv preprint arXiv:2212.10621, 2023
-
[18]
Autonomous character-scene interaction synthesis from text instruction
Nan Jiang et al. Autonomous character-scene interaction synthesis from text instruction. InSIGGRAPH Asia Conference Papers, 2024
2024
-
[19]
Optimizing diffusion noise can serve as universal motion priors
Korrawe Karunratanakul, Konpat Preechakul, Emre Aksan, Thabo Beeler, Supasorn Suwajanakorn, and Siyu Tang. Optimizing diffusion noise can serve as universal motion priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[20]
ParaHome: Parameterizing everyday home activities towards 3d generative modeling of human-object interactions
Jeonghwan Kim, Jisoo Kim, Jeonghyeon Na, and Hanbyul Joo. ParaHome: Parameterizing everyday home activities towards 3d generative modeling of human-object interactions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[21]
Object motion guided human motion synthesis.ACM Transactions on Graphics, 2023
Jiaman Li, Jiajun Wu, and C Karen Liu. Object motion guided human motion synthesis.ACM Transactions on Graphics, 2023
2023
-
[22]
Controllable human-object interaction synthesis
Jiaman Li, Alexander Clegg, Roozbeh Mottaghi, Jiajun Wu, Xavier Puig, and C Karen Liu. Controllable human-object interaction synthesis. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[23]
Maniptrans: Efficient dexterous bimanual manipulation transfer via residual learning
Kailin Li, Puhao Li, Tengyu Liu, Yuyang Li, and Siyuan Huang. Maniptrans: Efficient dexterous bimanual manipulation transfer via residual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[24]
Latenthoi: On the generalizable hand object motion generation with latent hand diffusion
Muchen Li, Sammy Christen, Chengde Wan, Yujun Cai, Renjie Liao, Leonid Sigal, and Shugao Ma. Latenthoi: On the generalizable hand object motion generation with latent hand diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[25]
Intergen: Diffusion-based multi-human motion generation under complex interactions.International Journal of Computer Vision, 2024
Han Liang, Wenqian Zhang, Wenxuan Li, Jingyi Yu, and Lan Xu. Intergen: Diffusion-based multi-human motion generation under complex interactions.International Journal of Computer Vision, 2024
2024
-
[26]
Humoto: A 4d dataset of mocap human object interactions
Jiaxin Lu, Chun-Hao Paul Huang, Uttaran Bhattacharya, Qixing Huang, and Yi Zhou. Humoto: A 4d dataset of mocap human object interactions. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[27]
HIMO: A new benchmark for full-body human interacting with multiple objects
Xintao Lv, Liang Xu, Yichao Yan, Xin Jin, Congsheng Xu, Shuwen Wu, Yifan Liu, Lincheng Li, Mengxiao Bi, Wenjun Zeng, and Xiaokang Yang. HIMO: A new benchmark for full-body human interacting with multiple objects. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[28]
Synthesizing physically plausible human motions in 3d scenes
Liang Pan, Jingbo Wang, Buzhen Huang, Junyu Zhang, Haofan Wang, Xu Tang, and Yangang Wang. Synthesizing physically plausible human motions in 3d scenes. InInternational Conference on 3D Vision (3DV), 2024
2024
-
[29]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[30]
HOI-Diff: Text-driven synthesis of 3d human-object interactions using diffusion models
Xiaogang Peng, Yiming Xie, Zizhao Wu, Varun Jampani, Deqing Sun, and Huaizu Jiang. HOI-Diff: Text-driven synthesis of 3d human-object interactions using diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2025
2025
-
[31]
Coda: Coordinated diffusion noise optimization for whole-body manipulation of articulated objects
Huaijin Pi, Zhi Cen, Zhiyang Dou, and Taku Komura. Coda: Coordinated diffusion noise optimization for whole-body manipulation of articulated objects. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[32]
Efficient learning on point clouds with basis point sets
Sergey Prokudin, Christoph Lassner, and Javier Romero. Efficient learning on point clouds with basis point sets. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[33]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, et al. Learning transferable visual models from natural language supervision.arXiv preprint arXiv:2103.00020, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [34]
-
[35]
Mixermdm: Learnable composition of human motion diffusion models
Pablo Ruiz-Ponce, German Barquero, Cristina Palmero, Sergio Escalera, and José García-Rodríguez. Mixermdm: Learnable composition of human motion diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 11
2025
-
[36]
Interact2ar: Full-body human-human interaction generation via autoregressive diffusion models
Pablo Ruiz-Ponce, Sergio Escalera, José García-Rodríguez, Jiankang Deng, and Rolandos Alexandros Potamias. Interact2ar: Full-body human-human interaction generation via autoregressive diffusion models. arXiv preprint arXiv:2512.19692, 2025
-
[37]
Interactive character control with auto-regressive motion diffusion models.ACM Transactions on Graphics, 2024
Yi Shi, Jingbo Wang, Xuekun Jiang, Bingkun Lin, Bo Dai, and Xue Bin Peng. Interactive character control with auto-regressive motion diffusion models.ACM Transactions on Graphics, 2024
2024
-
[38]
A survey on human interaction motion generation.International Journal of Computer Vision, 2026
Kewei Sui, Anindita Ghosh, Inwoo Hwang, Bing Zhou, Jian Wang, and Chuan Guo. A survey on human interaction motion generation.International Journal of Computer Vision, 2026
2026
-
[39]
Black, and Dimitrios Tzionas
Omid Taheri, Nima Ghorbani, Michael J. Black, and Dimitrios Tzionas. Grab: A dataset of whole-body human grasping of objects. InEuropean Conference on Computer Vision (ECCV), 2020
2020
-
[40]
Black, and Dimitrios Tzionas
Omid Taheri, Vasileios Choutas, Michael J. Black, and Dimitrios Tzionas. Goal: Generating 4d whole-body motion for hand-object grasping. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[41]
Omid Taheri, Yi Zhou, Dimitrios Tzionas, Yang Zhou, Duygu Ceylan, Soren Pirk, and Michael J. Black. Grip: Generating interaction poses using spatial cues and latent consistency. InInternational Conference on 3D Vision (3DV), 2024
2024
-
[42]
arXiv preprint arXiv:2512.23464 (2025)
Tencent Hunyuan 3D Digital Human Team. Hy-motion 1.0: Scaling flow matching models for text-to- motion generation.arXiv preprint arXiv:2512.23464, 2025
-
[43]
Human motion diffusion model
Guy Tevet, Sigal Raab, Brian Gordon, Yoni Shafir, Daniel Cohen-Or, and Amit Haim Bermano. Human motion diffusion model. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[44]
CLoSD: Closing the loop between simulation and diffusion for multi-task character control
Guy Tevet, Sigal Raab, Setareh Cohan, Daniele Reda, Zhengyi Luo, Xue Bin Peng, Amit Haim Bermano, and Michiel van de Panne. CLoSD: Closing the loop between simulation and diffusion for multi-task character control. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[45]
Yinhuai Wang, Jing Lin, Ailing Zeng, Zhengyi Luo, Jian Zhang, and Lei Zhang. Physhoi: Physics-based imitation of dynamic human-object interaction.arXiv preprint arXiv:2312.04393, 2023
-
[46]
Intercontrol: Zero-shot human interaction generation by controlling every joint
Zhenzhi Wang, Jingbo Wang, Yixuan Li, Dahua Lin, and Bo Dai. Intercontrol: Zero-shot human interaction generation by controlling every joint. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[47]
Unleashing guidance without classifiers for human-object interaction animation
Ziyin Wang, Sirui Xu, Chuan Guo, Bing Zhou, Jiangshan Gong, Jian Wang, Yu-Xiong Wang, and Liang- Yan Gui. Unleashing guidance without classifiers for human-object interaction animation. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[48]
Karen Liu
Zhen Wu, Jiaman Li, Pei Xu, and C. Karen Liu. Human-object interaction from human-level instructions. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[49]
Interact: Advancing large-scale versatile 3d human-object interaction generation
Sirui Xu, Dongting Li, Yucheng Zhang, Xiyan Xu, Qi Long, Ziyin Wang, Yunzhi Lu, Shuchang Dong, Hezi Jiang, Akshat Gupta, Yu-Xiong Wang, and Liang-Yan Gui. Interact: Advancing large-scale versatile 3d human-object interaction generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[50]
Intermimic: Towards universal whole-body control for physics-based human-object interactions
Sirui Xu, Hung Yu Ling, Yu-Xiong Wang, and Liangyan Gui. Intermimic: Towards universal whole-body control for physics-based human-object interactions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[51]
OakInk: A large- scale knowledge repository for understanding hand-object interaction
Lixin Yang, Kailin Li, Xinyu Zhan, Fei Wu, Anran Xu, Liu Liu, and Cewu Lu. OakInk: A large- scale knowledge repository for understanding hand-object interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[52]
G-hop: Generative hand-object prior for interaction reconstruction and grasp synthesis
Yufei Ye, Abhinav Gupta, Kris Kitani, and Shubham Tulsiani. G-hop: Generative hand-object prior for interaction reconstruction and grasp synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[53]
Black, Xue Bin Peng, and Davis Rempe
Hongwei Yi, Justus Thies, Michael J. Black, Xue Bin Peng, and Davis Rempe. Generating human interaction motions in scenes with text control. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[54]
Chainhoi: Joint-based kinematic chain modeling for human-object interaction generation
Ling-An Zeng, Guohong Huang, Yi-Lin Wei, Shengbo Gu, Yu-Ming Tang, Jingke Meng, and Wei-Shi Zheng. Chainhoi: Joint-based kinematic chain modeling for human-object interaction generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 12
2025
-
[55]
Manipnet: neural manipulation synthesis with a hand-object spatial representation.ACM Transactions on Graphics, 2021
He Zhang, Yuting Ye, Takaaki Shiratori, and Taku Komura. Manipnet: neural manipulation synthesis with a hand-object spatial representation.ACM Transactions on Graphics, 2021
2021
-
[56]
Motiondiffuse: Text-driven human motion generation with diffusion model.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. Motiondiffuse: Text-driven human motion generation with diffusion model.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[57]
Zhang et al
X. Zhang et al. Behave: Dataset and method for tracking human object interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[58]
Diffgrasp: Whole-body grasping synthesis guided by object motion using a diffusion model
Yonghao Zhang, Qiang He, Yanguang Wan, Yinda Zhang, Xiaoming Deng, Cuixia Ma, and Hongan Wang. Diffgrasp: Whole-body grasping synthesis guided by object motion using a diffusion model. In Proceedings of the AAAI Conference on Artificial Intelligence, 2025
2025
-
[59]
DartControl: A diffusion-based autoregressive motion model for real-time text-driven motion control
Kaifeng Zhao, Gen Li, and Siyu Tang. DartControl: A diffusion-based autoregressive motion model for real-time text-driven motion control. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[60]
On the continuity of rotation representa- tions in neural networks
Yi Zhou, Connelly Barnes, Lu Jingwan, Yang Jimei, and Li Hao. On the continuity of rotation representa- tions in neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 13
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.