When are LLMs Sufficient Policy Optimizers for Sequential RL Tasks?
Pith reviewed 2026-06-29 05:40 UTC · model grok-4.3
The pith
Large language models can act as sufficient policy optimizers for many sequential reinforcement learning tasks by iteratively generating and refining executable policies from environment descriptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
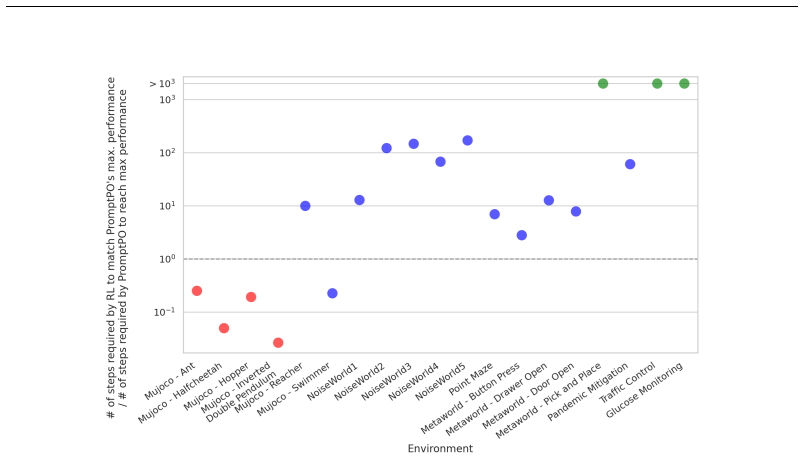
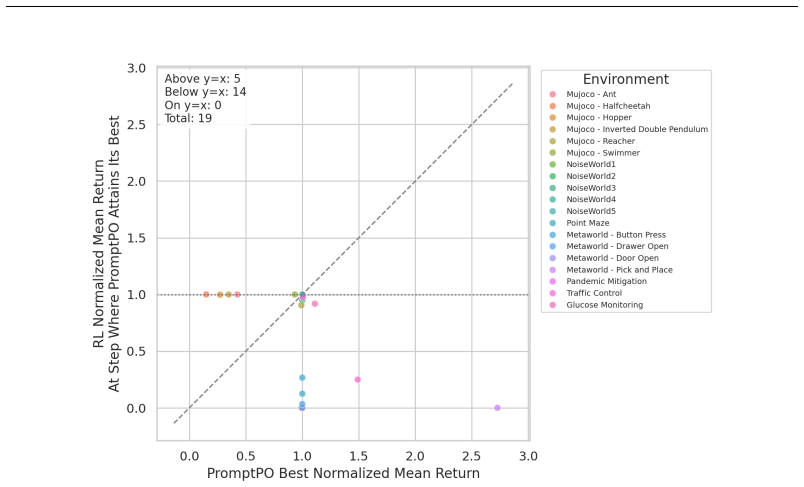
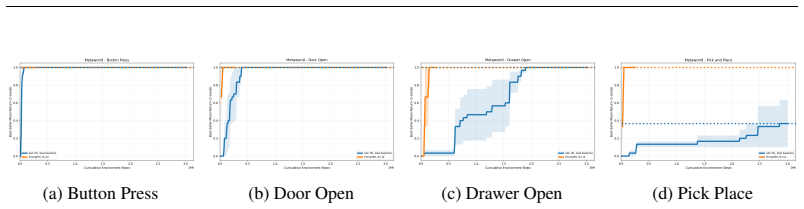
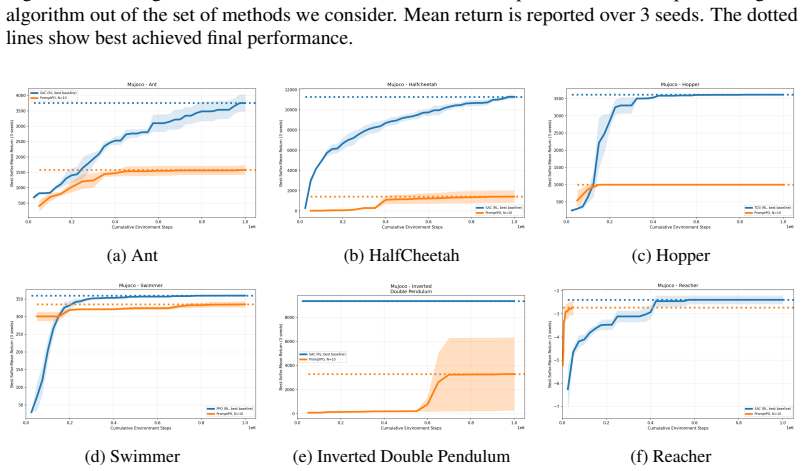
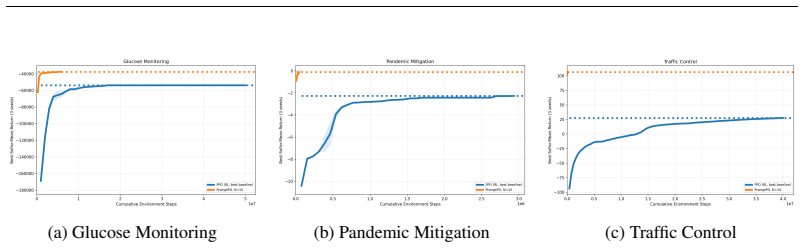
LLM-based policy optimization is sufficient when the LLM can leverage prior knowledge about the environment or optimization strategy, as demonstrated by PromptPO matching or exceeding standard RL baselines with substantially fewer environment interactions across various tasks, though it underperforms in MuJoCo domains requiring fine-grained continuous control.
What carries the argument
Prompted Policy Optimization (PromptPO), an iterative method that prompts an LLM with Python descriptions of state, action, and reward spaces to generate and refine executable policies using rollout feedback.
If this is right
- PromptPO outputs policies that can range from tuned controllers to full planning algorithms like value iteration without explicit prompting.
- LLM-based methods require substantially fewer environment interactions than classical RL in suitable domains.
- Performance is sufficient in hard exploration, Meta-World robotics, and real-world control problems.
- Limitations appear in settings requiring fine-grained continuous control.
Where Pith is reading between the lines
- PromptPO could be extended to hybrid systems where LLMs handle high-level planning and traditional RL fine-tunes low-level actions.
- Domains with structured knowledge or discrete actions are likely better suited for this approach than continuous control tasks.
- Future work might test if providing the LLM with optimization strategy hints further improves efficiency.
Load-bearing premise
The LLM receives accurate Python descriptions of the state space, action space, and reward function and can produce executable policies whose rollouts provide reliable feedback for iterative refinement.
What would settle it
Running PromptPO on a new MuJoCo-like continuous control task and observing whether it consistently underperforms standard RL baselines by a significant margin would support the limitation claim; success in a knowledge-rich discrete task would support sufficiency.
Figures








read the original abstract
We study when large language models (LLMs) can serve as effective black-box policy optimizers for reinforcement learning (RL) tasks, i.e., when can we replace classical RL algorithms with an LLM? We explore this question by introducing Prompted Policy Optimization (PromptPO), an iterative method that prompts an LLM with Python descriptions of the state space, action space, and reward function, then has it generate and refine executable policies based on rollout feedback. Across hard exploration environments, Meta-World robotics tasks, and several real-world control problems, PromptPO often matches or exceeds the performance of standard RL baselines while using substantially fewer environment interactions. To maximize expected return, and without further explicit prompting, the policies PromptPO outputs range from tuned proportional controllers or rule-based plans to policies that run planning algorithms like value iteration. Our results demonstrate that LLM-based policy optimization is sufficient when the LLM can leverage prior knowledge about the environment or optimization strategy. PromptPO underperforms standard RL baselines in MuJoCo domains. This demonstrates possible limitations of LLM-based policy optimization to settings that requiring fine-grained continuous control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Prompted Policy Optimization (PromptPO), an iterative method that prompts an LLM with Python descriptions of the state space, action space, and reward function, then refines executable policies based on rollout feedback. It reports that PromptPO matches or exceeds standard RL baselines in hard exploration environments, Meta-World robotics tasks, and real-world control problems while using substantially fewer environment interactions, with policies ranging from tuned controllers to planning algorithms; it explicitly underperforms in MuJoCo continuous-control domains. The central claim is that LLM-based policy optimization is sufficient when the LLM can leverage prior knowledge about the environment or optimization strategy.
Significance. If the empirical results hold under rigorous evaluation, the work provides concrete evidence that LLMs can function as black-box policy optimizers in structured RL settings where explicit MDP descriptions encode prior knowledge, achieving comparable returns with reduced sample complexity. It also identifies a clear failure mode in fine-grained continuous control, helping delineate the applicability boundaries of LLM-driven RL methods.
major comments (2)
- [Abstract] Abstract: the claim that PromptPO 'often matches or exceeds the performance of standard RL baselines' is load-bearing for the central result yet is presented without any quantitative metrics, baseline names, number of runs, variance estimates, or statistical tests; the provided text alone does not allow verification of this comparison.
- [Abstract] Abstract: the sufficiency condition rests on the LLM receiving 'accurate Python descriptions' and producing 'executable policies whose rollouts provide reliable feedback,' but no details are given on how these descriptions are authored, validated for correctness, or how execution reliability is ensured; this assumption is load-bearing for the reported success/failure distinction.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of how the abstract presents our central claims. We address each point below and will revise the abstract accordingly in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that PromptPO 'often matches or exceeds the performance of standard RL baselines' is load-bearing for the central result yet is presented without any quantitative metrics, baseline names, number of runs, variance estimates, or statistical tests; the provided text alone does not allow verification of this comparison.
Authors: We agree that the abstract would be strengthened by including more specific quantitative context for the performance claim. In the revised manuscript we will update the abstract to reference key results, such as the number of environment interactions required relative to baselines (e.g., PPO, SAC, DQN) and the number of independent runs, while directing readers to the full tables, variance estimates, and statistical comparisons in Sections 4–5 and the appendix. revision: yes
-
Referee: [Abstract] Abstract: the sufficiency condition rests on the LLM receiving 'accurate Python descriptions' and producing 'executable policies whose rollouts provide reliable feedback,' but no details are given on how these descriptions are authored, validated for correctness, or how execution reliability is ensured; this assumption is load-bearing for the reported success/failure distinction.
Authors: The referee correctly notes that the abstract does not detail the authoring and validation process. These procedures are described in Section 3 of the manuscript: descriptions are manually constructed from each environment’s official documentation and source code, then validated by confirming that generated policies execute without runtime errors in the simulator. We will add a concise clause to the abstract summarizing this process and the error-handling mechanism used during rollout feedback. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces PromptPO as an empirical method and evaluates it through direct comparisons to RL baselines on multiple task suites. No equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text. All central claims rest on observable experimental outcomes (performance matching, interaction counts, domain-specific limitations) that are externally falsifiable and do not reduce to the method's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
7 Marcin Andrychowicz, Anton Raichuk, Piotr Sta´nczyk, Manu Orsini, Sertan Girgin, Raphaël Marinier, Léonard Hussenot, Matthieu Geist, Olivier Pietquin, Marcin Michalski, Sylvain Gelly, and Olivier Bachem. What matters in on-policy reinforcement learning? a large-scale empirical study.arXiv preprint arXiv:2006.05990,
-
[4]
RL$^2$: Fast Reinforcement Learning via Slow Reinforcement Learning
Yan Duan, John Schulman, Xi Chen, Peter L Bartlett, Ilya Sutskever, and Pieter Abbeel. Fast reinforcement learning via slow reinforcement learning.arXiv preprint arXiv:1611.02779,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Challenges of Real-World Reinforcement Learning
Gabriel Dulac-Arnold, Daniel Mankowitz, and Todd Hester. Challenges of real-world reinforcement learning.arXiv preprint arXiv:1904.12901,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[6]
Hyperparameters in reinforcement learning and how to tune them.arXiv preprint arXiv:2306.01324,
Theresa Eimer, Marius Lindauer, and Roberta Raileanu. Hyperparameters in reinforcement learning and how to tune them.arXiv preprint arXiv:2306.01324,
-
[7]
Farama Foundation
Accessed: 2026-04-03. Farama Foundation. Point maze environment. https://robotics.farama.org/envs/ maze/point_maze/,
2026
-
[8]
Scott Fujimoto, Herke van Hoof, and David Meger
Accessed: 2026-04-03. Scott Fujimoto, Herke van Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InInternational Conference on Machine Learning (ICML), pp. 1587–1596,
2026
-
[9]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maxi- mum entropy deep reinforcement learning with a stochastic actor.arXiv preprint arXiv:1801.01290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Daniel Hennes, Zun Li, John Schultz, and Marc Lanctot. Code-space response oracles: Generating interpretable multi-agent policies with large language models.arXiv preprint arXiv:2603.10098,
-
[11]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. InInternational conference on machine learning, pp. 9118–9147. PMLR, 2022a. Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
GitHub repository. Varun Kompella, Roberto Capobianco, Stacy Jong, Jonathan Browne, Spencer Fox, Lauren Meyers, Peter Wurman, and Peter Stone. Reinforcement learning for optimization of covid-19 mitigation policies.arXiv preprint arXiv:2010.10560,
-
[13]
Cassidy Laidlaw, Shivam Singhal, and Anca Dragan. Correlated proxies: A new definition and improved mitigation for reward hacking, 2025.URL https://arxiv. org/abs/2403.03185. Yoonho Lee, Joseph Boen, and Chelsea Finn. Feedback descent: Open-ended text optimization via pairwise comparison.arXiv preprint arXiv:2511.07919,
-
[14]
Reinforcement learning in practice: Opportunities and challenges.arXiv preprint arXiv:2202.11296,
8 Yuxi Li. Reinforcement learning in practice: Opportunities and challenges.arXiv preprint arXiv:2202.11296,
-
[15]
DOI: 10.1038/nature14236. Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wag- ner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphae- volve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/nature14236
-
[16]
The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models
Alexander Pan, Kush Bhatia, and Jacob Steinhardt. The effects of reward misspecification: Mapping and mitigating misaligned models, 2022.URL https://arxiv. org/abs/2201.03544,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Richard S
Accessed: 2026-04-03. Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, 2 edition,
2026
-
[19]
Emanuel Todorov, Tom Erez, and Yuval Tassa
URLhttps://arxiv.org/abs/2306.07580. Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 5026–5033,
-
[20]
Voyager: An Open-Ended Embodied Agent with Large Language Models
URL https://github.com/Farama-Foundation/Gymnasium. Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine
DOI: 10.1109/TRO.2021.3087314. Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InProceedings of the Conference on Robot Learning (CoRL),
-
[22]
TextGrad: Automatic "Differentiation" via Text
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. Textgrad: Automatic" differentiation" via text.arXiv preprint arXiv:2406.07496,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Yifan Zhou, Sachin Grover, Mohamed El Mistiri, Kamalesh Kalirathnam, Pratyush Kerhalkar, Swaroop Mishra, Neelesh Kumar, Sanket Gaurav, Oya Aran, and Heni Ben Amor. Prompted policy search: Reinforcement learning through linguistic and numerical reasoning in llms.arXiv preprint arXiv:2511.21928,
-
[24]
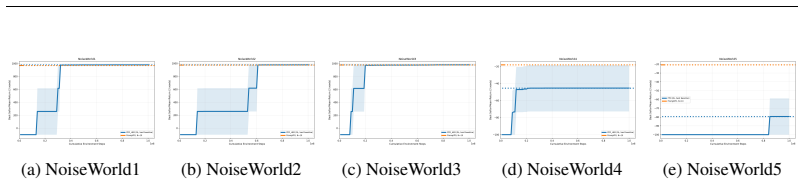
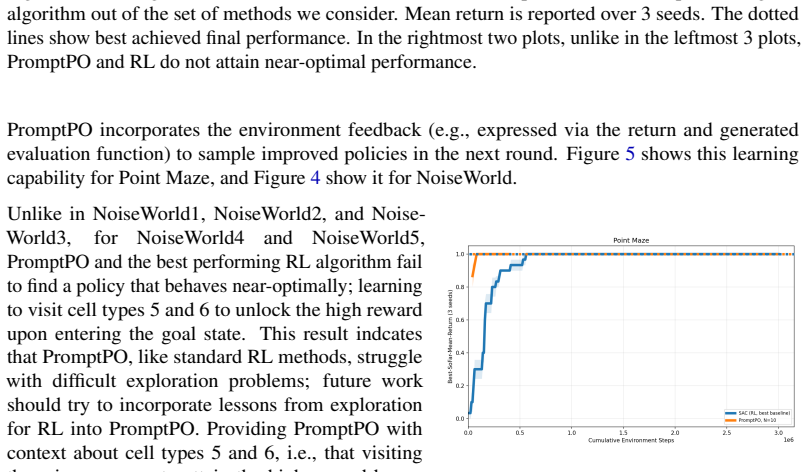
The agent accrues a −1 reward at each timestep, and +1000 reward for reaching the goal state. NosieWorld has additional 6 cell types: • Cell type 0 is a blank; transitions out of cell type 0 are deterministic • Cell type 1 is a wall; no transitions into these cells are successful. • Cell type 2 is such that any transitions out of this cell are successful ...
2026
-
[25]
The difference in relative performance between PromptPO and RL in the Mujoco and Metaworld environments provide insight into the type of environments where PromptPO is a sufficient policy optimizer; for Mujoco, the action space consists of torques applied to hinge joints, while for Meta- world it is the end-effector displacement and gripper finger positio...
2022
-
[26]
8 Prompts used by PromptPO Trajectory Feedback Prompt Implement a class called Feedback with a method summarize_trajectory(self, traj)
These results showcase PromptPO’s strength as a policy optimizer in real world settings where it may be capable of leveraging its pretraining data as a strong prior on generating a performant policy. 8 Prompts used by PromptPO Trajectory Feedback Prompt Implement a class called Feedback with a method summarize_trajectory(self, traj). traj is a list of obs...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.