On Revisiting Entropy for Identifying Mislabeled Images
Pith reviewed 2026-06-28 23:10 UTC · model grok-4.3
The pith
A signed integral of prediction entropy changes during training identifies mislabeled images more reliably than prior techniques.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
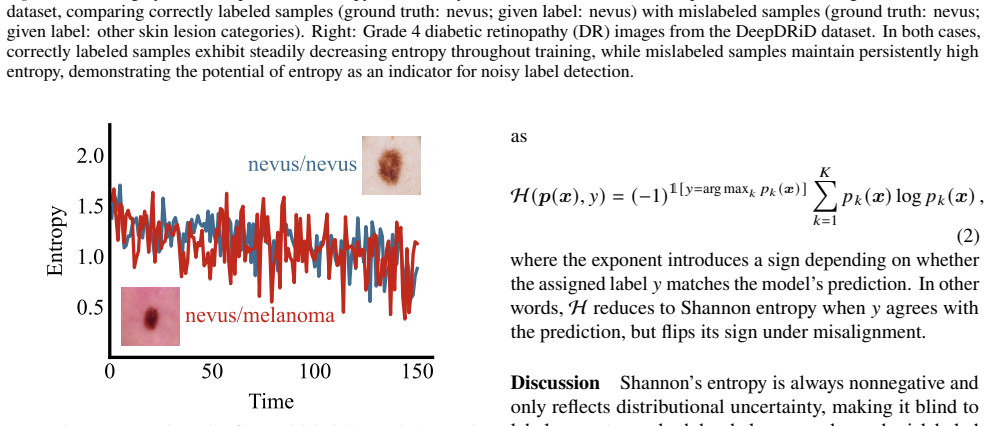
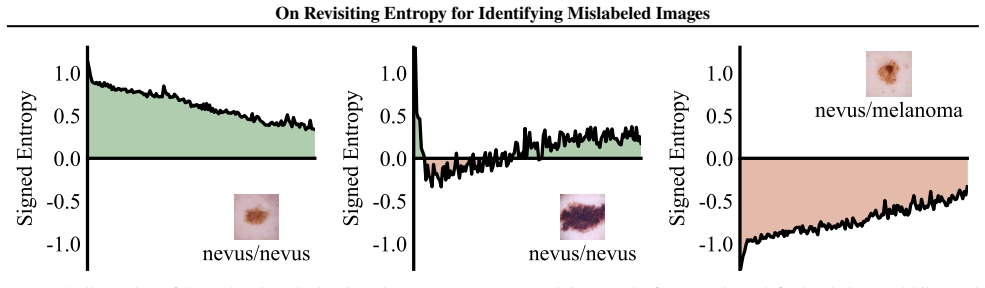
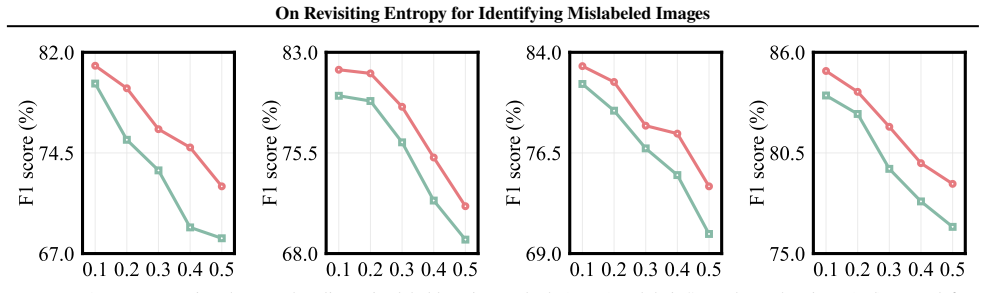
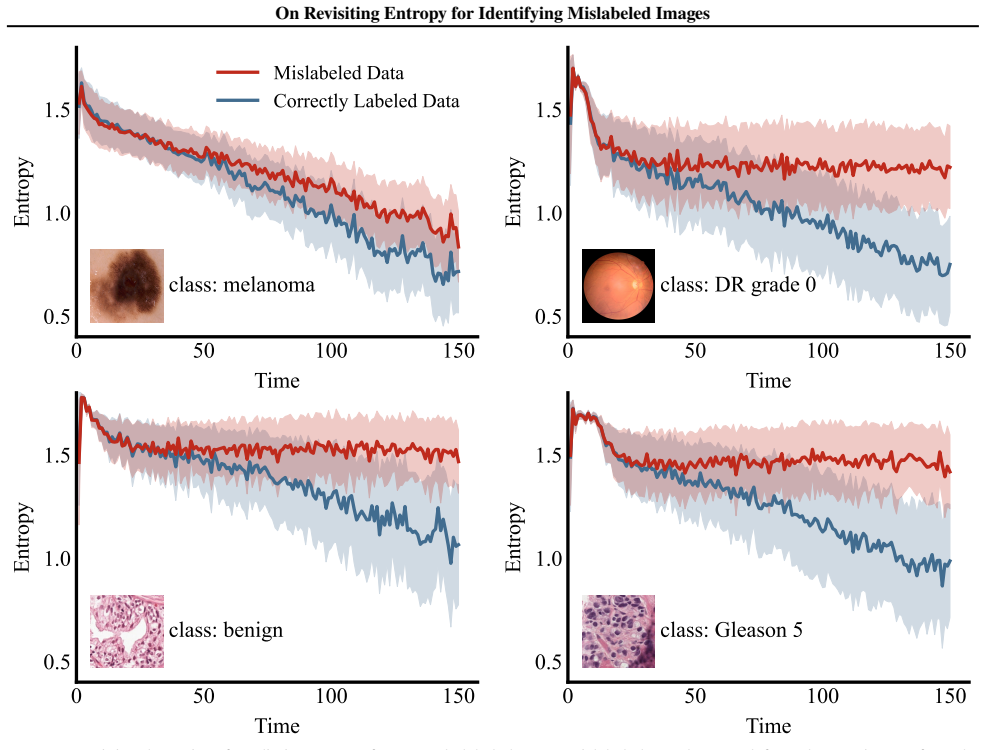
The central claim is that correctly labeled samples exhibit consistent entropy decrease during training while mislabeled samples maintain relatively high entropy throughout the process; the signed entropy integral (SEI) statistic captures both the magnitude and temporal trend of prediction entropy across training epochs and achieves state-of-the-art performance in mislabeled data identification on four medical imaging datasets while remaining computationally efficient.
What carries the argument
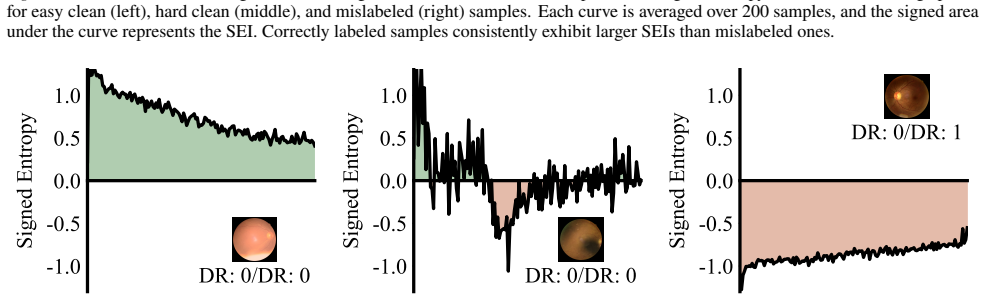
signed entropy integral (SEI), a cumulative sum of signed changes in prediction entropy between consecutive training epochs that encodes both level and trend of label correctness
If this is right
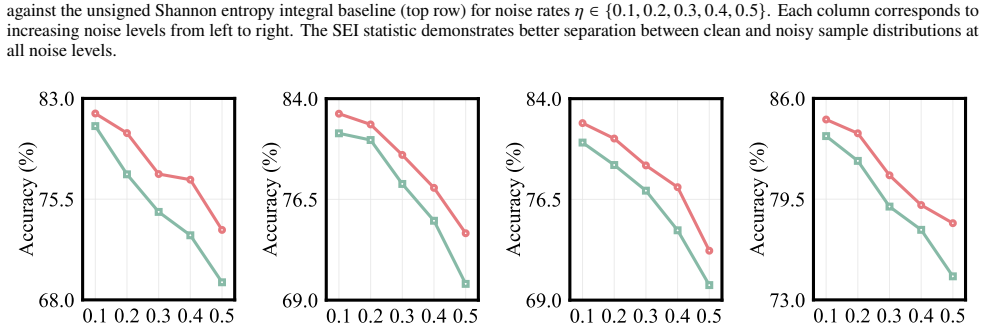
- SEI outperforms existing mislabeled-data detectors on four medical imaging datasets spanning multiple modalities and pathologies.
- The statistic applies directly to both standard classification networks and CLIP-based models without architectural changes.
- SEI requires only the entropy values already computed during normal training, preserving computational efficiency.
- The method identifies mislabeled samples by a single scalar per image after training completes.
Where Pith is reading between the lines
- If the entropy-separation pattern holds outside medicine, SEI could be tested on standard image-classification benchmarks with synthetic label noise to check broader applicability.
- Entropy monitoring might be combined with loss-based cleaning methods to improve detection precision, though the paper evaluates SEI alone.
- The same entropy trend could potentially guide early stopping or learning-rate schedules when label noise is suspected.
Load-bearing premise
Correctly labeled samples exhibit consistent entropy decrease during training while mislabeled samples maintain relatively high entropy throughout the process.
What would settle it
A controlled training run on a dataset with verified ground-truth labels in which the entropy trajectories of correct and incorrect samples fail to separate according to the described pattern would falsify the core premise.
Figures








read the original abstract
Mislabeled samples in training datasets severely degrade the performance of deep networks, as overparameterized models tend to memorize erroneous labels. We address this challenge by proposing a novel approach for mislabeled data detection that leverages training dynamics. Our method is grounded in the key observation that correctly labeled samples exhibit consistent entropy decrease during training, while mislabeled samples maintain relatively high entropy throughout the training process. Building on this insight, we introduce a signed entropy integral (SEI) statistic that captures both the magnitude and temporal trend of prediction entropy across training epochs. SEI is broadly applicable to classification networks and demonstrates particular effectiveness when integrated with contrastive language-image pretraining (CLIP) architectures. Through extensive experiments on four medical imaging datasets -- a domain particularly susceptible to labeling errors due to diagnostic complexity -- spanning diverse modalities and pathologies, we demonstrate that SEI achieves state-of-the-art performance in mislabeled data identification, outperforming existing methods while maintaining computational efficiency and implementation simplicity. Our code is available at https://github.com/MedAITech/SEI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the signed entropy integral (SEI) statistic for mislabeled sample detection. It is grounded in the empirical observation that correctly labeled examples exhibit consistent prediction-entropy decrease over training epochs while mislabeled examples maintain relatively high entropy; SEI integrates both magnitude and sign of this trend. The authors report that SEI achieves state-of-the-art identification performance on four medical imaging datasets spanning modalities and pathologies when used with CLIP backbones, while remaining computationally lightweight. Code is released.
Significance. If the entropy-dynamics observation proves robust, SEI would supply a simple, training-dynamics-based alternative to existing mislabel detectors that does not require auxiliary models or clean validation sets. The public code release is a clear strength. The restriction to CLIP backbones and four medical datasets, however, together with the purely empirical grounding, caps the result’s generality and long-term significance.
major comments (2)
- [Abstract] Abstract: the central claim rests on the stated observation that “correctly labeled samples exhibit consistent entropy decrease … while mislabeled samples maintain relatively high entropy.” No derivation, no analysis of dependence on loss, optimizer, schedule, or label-noise fraction, and no examination of the regime in which both classes eventually reach low entropy are supplied; this directly affects whether SEI remains discriminative.
- [Experiments] Experiments (implied by performance claims): the SOTA assertion is presented without error bars, without ablation on the sign choice or integration limits inside SEI, and without correction for multiple testing across four datasets; these omissions make it impossible to judge whether the reported outperformance is statistically reliable or dataset-specific.
minor comments (2)
- [Abstract] The abstract would be clearer if it included the explicit integral definition of SEI rather than only describing its motivation.
- A short limitations paragraph discussing possible failure modes (e.g., late-training entropy collapse for both classes) would improve transparency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The work is empirical and focuses on the practical performance of SEI for mislabeled sample detection in medical imaging with CLIP backbones. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim rests on the stated observation that “correctly labeled samples exhibit consistent entropy decrease … while mislabeled samples maintain relatively high entropy.” No derivation, no analysis of dependence on loss, optimizer, schedule, or label-noise fraction, and no examination of the regime in which both classes eventually reach low entropy are supplied; this directly affects whether SEI remains discriminative.
Authors: The central claim is presented explicitly as an empirical observation from training dynamics on the evaluated datasets, not as a theoretically derived property. The manuscript does not claim universality across all losses, optimizers, or noise levels, and the method is proposed for its utility in the medical imaging setting with CLIP. We did not include analysis of the late-training regime where both classes may reach low entropy because our experiments focus on the epochs where the distinction is observed and useful for detection. We can revise the abstract and add a limitations paragraph clarifying the empirical grounding and scope. revision: partial
-
Referee: [Experiments] Experiments (implied by performance claims): the SOTA assertion is presented without error bars, without ablation on the sign choice or integration limits inside SEI, and without correction for multiple testing across four datasets; these omissions make it impossible to judge whether the reported outperformance is statistically reliable or dataset-specific.
Authors: We agree that error bars from repeated runs and ablations on SEI components (sign and integration limits) would strengthen the results and will add them in revision. The four datasets are distinct in modality and pathology; we view the consistent outperformance as supportive rather than requiring formal multiple-testing correction, but we can add a clarifying statement. The SOTA claim is based on the reported metrics outperforming prior methods on these datasets. revision: yes
Circularity Check
No circularity; method is an empirical statistic validated on held-out datasets
full rationale
The paper grounds SEI in an empirical observation of entropy trajectories and defines the statistic directly from training dynamics; it then reports experimental performance on four medical datasets. No equations, fitted parameters, or self-citations are shown that reduce the claimed detection performance to the inputs by construction. The derivation chain is therefore self-contained and externally falsifiable via the reported experiments.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tackling algorith- mic bias and promoting transparency in health datasets: the standing together consensus recommendations.The Lancet Digital Health, 7:e64–e88, 2025
Cole-Lewis, H., Glocker, B., et al. Tackling algorith- mic bias and promoting transparency in health datasets: the standing together consensus recommendations.The Lancet Digital Health, 7:e64–e88, 2025
2025
-
[2]
Unsupervised label noise modeling and loss cor- rection
Arazo, E., Ortego, D., Albert, P., O’Connor, N., and McGuin- ness, K. Unsupervised label noise modeling and loss cor- rection. InProceedings of the International Conference on Machine Learning, pp. 312–321, 2019
2019
-
[3]
Dirichlet-based per-sample weighting by transition matrix for noisy la- bel learning
Bae, H., Shin, S., Na, B., and Moon, I. Dirichlet-based per-sample weighting by transition matrix for noisy la- bel learning. InProceedings of the 12th International Conference on Learning Representations, 2024
2024
-
[4]
Chen, J., Ramanathan, V., Xu, T., and Martel, A. L. De- tecting noisy labels with repeated cross-validations. In Proceedings of the Medical Image Computing and Com- puter Assisted Intervention, pp. 197–207, 2024
2024
-
[5]
Understanding and utilizing deep neural networks trained with noisy labels
Chen, P., Liao, B., Chen, G., and Zhang, S. Understanding and utilizing deep neural networks trained with noisy labels. InProceedings of the International Conference on Machine Learning, pp. 1062–1070, 2019
2019
-
[6]
X., and Mou, L
Chen, Y., Wang, Q., Li, C., Hu, J., Shi, Y., Xiong, S., Zhu, X. X., and Mou, L. Propl: Universal semi-supervised ultrasound image segmentation via prompt-guided pseudo- labeling. InProceedings of the AAAI Conference on Artificial Intelligence, pp. 3101–3110, 2026
2026
-
[7]
Class-dependent label-noise learning with cycle-consistency regularization
Han, B., and Liu, T. Class-dependent label-noise learning with cycle-consistency regularization. InProceedings of the Advances in Neural Information Processing Systems, pp. 11104–11116, 2022
2022
-
[8]
Learning with instance-dependent label noise: A sample sieve approach
Cheng, H., Zhu, Z., Li, X., Gong, Y., Sun, X., and Liu, Y. Learning with instance-dependent label noise: A sample sieve approach. InProceedings of the 9th International Conference on Learning Representations, 2021
2021
-
[9]
Weakly supervised learning with side information for noisy labeled images
Cheng, L., Zhou, X., Zhao, L., Li, D., Shang, H., Zheng, Y., Pan, P., and Xu, Y. Weakly supervised learning with side information for noisy labeled images. InProceedings of the European Conference on Computer Vision, pp. 306–321, 2020
2020
-
[10]
X., and Mou, L
Dong, L., Tan, Q., Li, C., Hu, J., Shi, Y., Dong, W., Zhu, X. X., and Mou, L. Dual distillation for few-shot anomaly detection. InProceedings of the 14th International Con- ference on Learning Representations, 2026. 9 On Revisiting Entropy for Identifying Mislabeled Images
2026
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. InProceedings of the 9th International Conference on Learning Representations, 2021
2021
-
[12]
and Azizpour, H
Englesson, E. and Azizpour, H. Robust classification via regression for learning with noisy labels. InProceed- ings of the 12th International Conference on Learning Representations, 2024
2024
-
[13]
Deep Self-Learning from noisy labels
Han, J., Luo, P., and Wang, X. Deep Self-Learning from noisy labels. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pp. 5138–5147, 2019
2019
-
[14]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 770–778, 2016
2016
-
[15]
O2U-Net: A simple noisy label detection approach for deep neural networks
Huang, J., Qu, L., Jia, R., and Zhao, B. O2U-Net: A simple noisy label detection approach for deep neural networks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3325–3333, 2019
2019
-
[16]
N., Lungren, M
Patel, B. N., Lungren, M. P., and Ng, A. Y. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. InProceedings of the AAAI Conference on Artificial Intelligence, pp. 590–597, 2019
2019
-
[17]
Delving into sample loss curve to embrace noisy and imbalanced data
Jiang, S., Li, J., Wang, Y., Huang, B., Zhang, Z., and Xu, T. Delving into sample loss curve to embrace noisy and imbalanced data. InProceedings of the AAAI Conference on Artificial Intelligence, pp. 7024–7032, 2022
2022
-
[18]
Splitnet: Learnable clean-noisy label splitting for learning with noisy labels
Kim, D., Ryoo, K., Cho, H., and Kim, S. Splitnet: Learnable clean-noisy label splitting for learning with noisy labels. International Journal of Computer Vision, 133(2):549– 566, 2025
2025
-
[19]
Learning discriminative dynamics with label corruption for noisy label detection
Kim, S., Lee, D., Kang, S., Chae, S., Jang, S., and Yu, H. Learning discriminative dynamics with label corruption for noisy label detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 22477–22487, 2024
2024
-
[20]
J., and Ronneberger, O
Rezende, D. J., and Ronneberger, O. A probabilistic U-Net for segmentation of ambiguous images. InProceedings of the Advances in Neural Information Processing Systems, pp. 6965–6975, 2018
2018
-
[21]
Scale-aware contrastive reverse distillation for unsupervised medical anomaly detection
Li, C., Shi, Y., Hu, J., Zhu, X., and Mou, L. Scale-aware contrastive reverse distillation for unsupervised medical anomaly detection. InProceedings of the 13th Interna- tional Conference on Learning Representations, 2025
2025
-
[22]
Li, J., Socher, R., and Hoi, S. C. H. DivideMix: Learning with noisy labels as semi-supervised learning. InPro- ceedings of the 8th International Conference on Learning Representations, 2020
2020
-
[23]
Ciompi, F., Ghafoorian, M., van der Laak, J. A. W. M., van Ginneken, B., and S ´anchez, C. I. A survey on deep learning in medical image analysis.Medical Image Analysis, 42:60–88, 2017
2017
-
[24]
Deepdrid: Diabetic retinopathy-grading and image quality estimation challenge.Patterns, 3:100512, 2022
Jia, W., Shen, D., Sheng, B., and Zhang, P. Deepdrid: Diabetic retinopathy-grading and image quality estimation challenge.Patterns, 3:100512, 2022
2022
-
[25]
Early-learning regularization prevents memorization of noisy labels
Liu, S., Niles-Weed, J., Razavian, N., and Fernandez-Granda, C. Early-learning regularization prevents memorization of noisy labels. InProceedings of the Advances in Neural Information Processing Systems, pp. 20331–20342, 2020
2020
-
[26]
K., and Kumar, S
Lukasik, M., Bhojanapalli, S., Menon, A. K., and Kumar, S. Does label smoothing mitigate label noise? In Proceedings of the International Conference on Machine Learning, pp. 6448–6458, 2020
2020
-
[27]
Semi-supervised medical image segmentation through dual-task consis- tency
Luo, X., Chen, J., Song, T., and Wang, G. Semi-supervised medical image segmentation through dual-task consis- tency. InProceedings of the AAAI Conference on Artificial Intelligence, pp. 8801–8809, 2021
2021
-
[28]
Difficulty-aware attention network with confidence learning for medical image segmentation
Nie, D., Wang, L., Xiang, L., Zhou, S., Adeli, E., and Shen, D. Difficulty-aware attention network with confidence learning for medical image segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, pp. 1085–1092, 2019
2019
-
[29]
G., Jiang, L., and Chuang, I
Northcutt, C. G., Jiang, L., and Chuang, I. L. Confident learning: Estimating uncertainty in dataset labels.Journal of Artificial Intelligence Research, 70:1373–1411, 2021
2021
-
[30]
R., and Weinberger, K
Pleiss, G., Zhang, T., Elenberg, E. R., and Weinberger, K. Q. Identifying mislabeled data using the area under the margin ranking. InProceedings of the Advances in Neural Information Processing Systems, pp. 17044–17056, 2020. 10 On Revisiting Entropy for Identifying Mislabeled Images
2020
-
[31]
Learning transferable visual models from natural language supervision
Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, pp. 8748–8763, 2021
2021
-
[32]
Learning to reweight examples for robust deep learning
Ren, M., Zeng, W., Yang, B., and Urtasun, R. Learning to reweight examples for robust deep learning. InPro- ceedings of the International Conference on Machine Learning, pp. 4334–4343, 2018
2018
-
[33]
Imagenet large scale visual recognition challenge
Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115:211–252, 2015
2015
-
[34]
A survey of label-noise deep learning for medical image analysis.Medical Image Analysis, 95:103166, 2024
Shi, J., Zhang, K., Guo, C., Yang, Y., Xu, Y., and Wu, J. A survey of label-noise deep learning for medical image analysis.Medical Image Analysis, 95:103166, 2024
2024
-
[35]
SELFIE: Refurbishing unclean samples for robust deep learning
Song, H., Kim, M., and Lee, J. SELFIE: Refurbishing unclean samples for robust deep learning. InProceedings of the International Conference on Machine Learning, pp. 5907–5915, 2019
2019
-
[36]
Noisegpt: La- bel noise detection and rectification through probability curvature
Wang, H., Huang, Z., Lin, Z., and Liu, T. Noisegpt: La- bel noise detection and rectification through probability curvature. InProceedings of the Advances in Neural Information Processing Systems, pp. 120159–120183, 2024
2024
-
[37]
Symmetric cross entropy for robust learning with noisy labels
Wang, Y., Ma, X., Chen, Z., Luo, Y., Yi, J., and Bailey, J. Symmetric cross entropy for robust learning with noisy labels. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 322–330, 2019
2019
-
[38]
Learning with noisy labels revisited: A study using real-world human annotations
Wei, J., Zhu, Z., Cheng, H., Liu, T., Niu, G., and Liu, Y. Learning with noisy labels revisited: A study using real-world human annotations. InProceedings of the 10th International Conference on Learning Representations, 2022
2022
-
[39]
Vision-Language models are strong noisy label detectors
Wei, T., Li, H., Li, C., Shi, J., Li, Y., and Zhang, M. Vision-Language models are strong noisy label detectors. InProceedings of the Advances in Neural Information Processing Systems, pp. 58154–58173, 2024
2024
-
[40]
Robust early-learning: Hindering the memorization of noisy labels
Xia, X., Liu, T., Han, B., Gong, C., Wang, N., Ge, Z., and Chang, Y. Robust early-learning: Hindering the memorization of noisy labels. InProceedings of the 9th International Conference on Learning Representations, 2021
2021
-
[41]
ProMix: Combating label noise via maximizing clean sample utility
Xiao, R., Dong, Y., Wang, H., Feng, L., Wu, R., Chen, G., and Zhao, J. ProMix: Combating label noise via maximizing clean sample utility. InProceedings of the International Joint Conference on Artificial Intelligence, pp. 4442–4450, 2023
2023
-
[42]
Learning from massive noisy labeled data for image classification
Xiao, T., Xia, T., Yang, Y., Huang, C., and Wang, X. Learning from massive noisy labeled data for image classification. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 2691–2699, 2015
2015
-
[43]
Learning from noisy labels via dynamic loss thresholding.IEEE Transactions on Knowledge and Data Engineering, 2023
Zhang, M.-L. Learning from noisy labels via dynamic loss thresholding.IEEE Transactions on Knowledge and Data Engineering, 2023
2023
-
[44]
Active negative loss functions for learning with noisy labels
Ye, X., Li, X., Dai, S., Liu, T., Sun, Y., and Tong, W. Active negative loss functions for learning with noisy labels. InProceedings of the Advances in Neural Information Processing Systems, pp. 6917–6940, 2023
2023
-
[45]
Early stopping against label noise without validation data
Yuan, S., Feng, L., and Liu, T. Early stopping against label noise without validation data. InProceedings of the 12th International Conference on Learning Representations, 2024
2024
-
[46]
LEMoN: Label error detection using multimodal neighbors
Zhang, H., Balagopalan, A., Oufattole, N., Jeong, H., Wu, Y., Zhu, J., and Ghassemi, M. LEMoN: Label error detection using multimodal neighbors. InProceedings of the International Conference on Machine Learning, 2025
2025
-
[47]
and Sabuncu, M
Zhang, Z. and Sabuncu, M. R. Generalized cross entropy loss for training deep neural networks with noisy labels. InProceedings of the Advances in Neural Information Processing Systems, pp. 8792–8802, 2018
2018
-
[48]
Strong aug
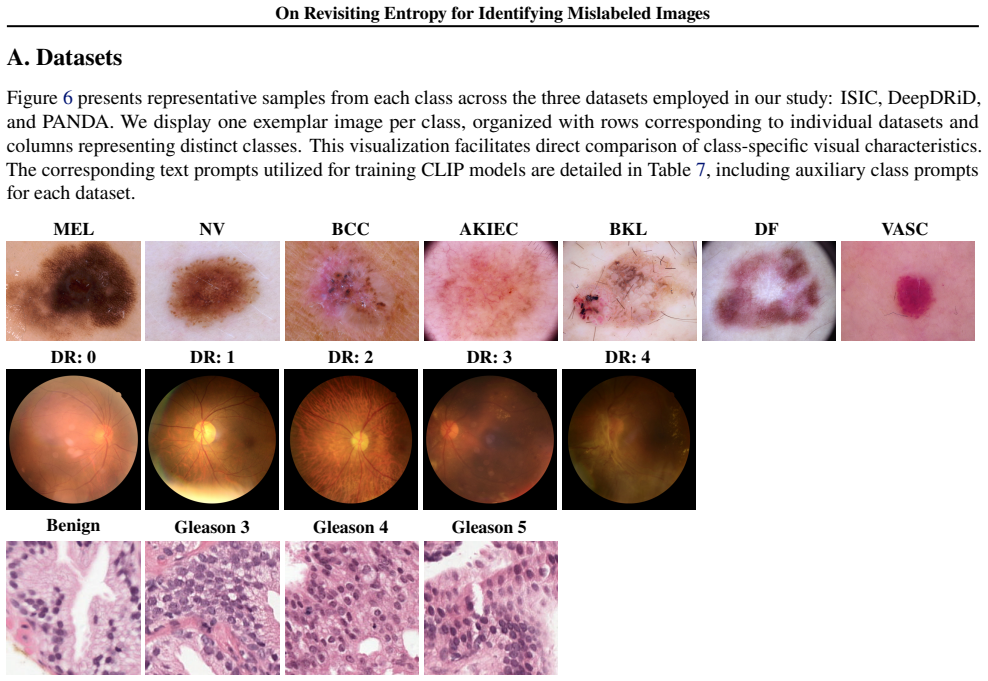
Zhu, Z., Dong, Z., and Liu, Y. Detecting corrupted labels without training a model to predict. InProceedings of the International Conference on Machine Learning, pp. 27412–27427, 2022. 11 On Revisiting Entropy for Identifying Mislabeled Images A. Datasets Figure 6 presents representative samples from each class across the three datasets employed in our st...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.