LongTraceRL: Learning Long-Context Reasoning from Search Agent Trajectories with Rubric Rewards
Pith reviewed 2026-06-28 22:05 UTC · model grok-4.3
The pith
Search agent trajectories supply tiered distractors and entity rubrics that let reinforcement learning supervise long-context reasoning steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
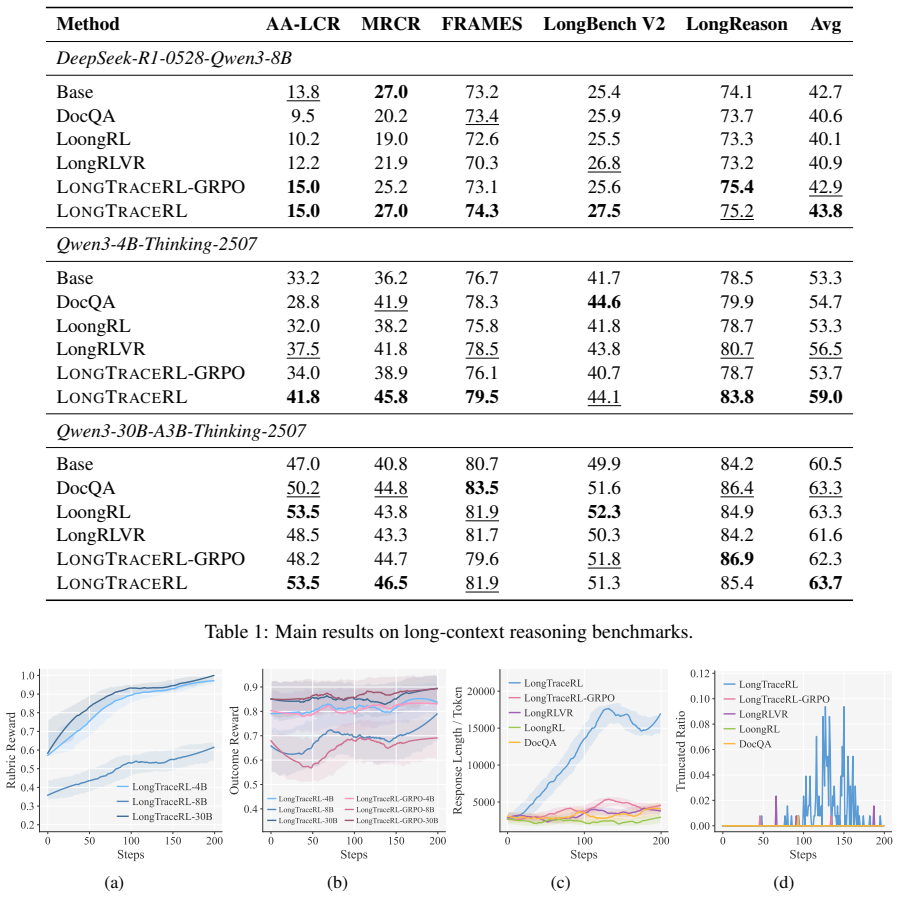
LongTraceRL generates multi-hop questions via knowledge-graph random walks, constructs tiered distractors from search-agent trajectories, and applies a positive-only rubric reward that uses gold entities as fine-grained process supervision; this produces training signals that are more challenging than random sampling or one-shot search and that distinguish reasoning quality among correct answers without enabling reward hacking.
What carries the argument
Tiered distractors drawn from search-agent trajectories together with a positive-only rubric reward that scores gold entities along the reasoning chain.
If this is right
- The resulting models outperform strong baselines on five long-context reasoning benchmarks.
- Reasoning traces become more comprehensive and evidence-grounded rather than shortcut-based.
- The same data-construction and reward approach scales across model sizes from 4B to 30B parameters.
- Positive-only application of the rubric prevents reward hacking while still providing process-level signal.
- Training contexts built from real search trajectories are harder than those from random sampling or single-shot search.
Where Pith is reading between the lines
- The same trajectory-harvesting idea could be applied to generate training data for tasks other than multi-hop question answering.
- If search logs become available at scale, the method offers a way to create challenging long-context examples without manual annotation.
- The rubric could be extended to reward ordering or completeness of entity mentions in addition to presence.
- Models trained this way might transfer better to real-world retrieval-augmented settings where distractors are naturally uneven.
Load-bearing premise
The documents an agent read but did not cite really function as substantially harder distractors than random pages, and the entity rubric truly separates good reasoning from poor reasoning among correct answers.
What would settle it
Retrain the same models on the same questions but replace the tiered distractors with randomly sampled documents of equal length and measure whether accuracy and reasoning quality drop.
Figures











read the original abstract
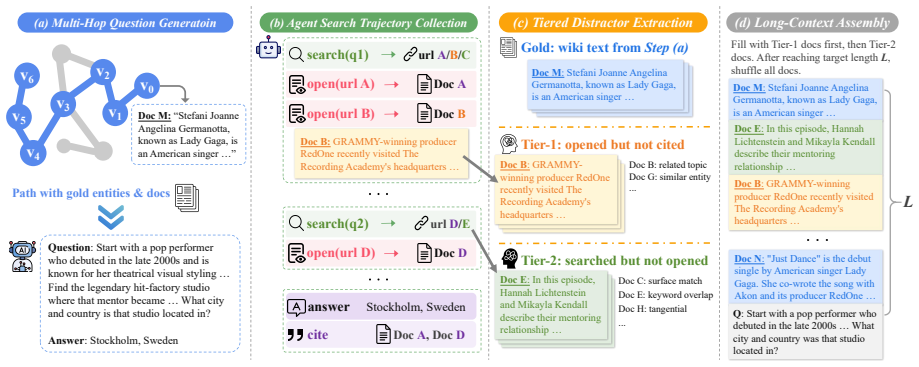
Long-context reasoning remains a central challenge for large language models, which often fail to locate and integrate key information in extensive distracting content. Reinforcement learning with verifiable rewards (RLVR) has shown promise for this task, yet existing methods are limited by low-confusability distractors and sparse, outcome-only reward signals that cannot supervise intermediate reasoning steps. To address these issues, we introduce \textsc{LongTraceRL}. For data construction, we generate multi-hop questions via knowledge graph random walks and leverage search agent trajectories to build \emph{tiered distractors}: documents the agent read but did not cite (high confusability) and documents that appeared in search results but were never opened (low confusability), producing training contexts that are far more challenging than those built by random sampling or one-shot search. For reward design, we propose a \emph{rubric reward} that uses the gold entities along each reasoning chain as fine-grained, entity-level process supervision. This rubric reward is applied only to responses with correct final answers (positive-only strategy), distinguishing the reasoning quality among correct responses and preventing reward hacking. Experiments on three reasoning LLMs (4B--30B) across five long-context benchmarks demonstrate that \textsc{LongTraceRL} consistently outperforms strong baselines and encourages comprehensive, evidence-grounded reasoning. Codes, datasets and models are available at \href{https://github.com/THU-KEG/LongTraceRL}{https://github.com/THU-KEG/LongTraceRL}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LongTraceRL for long-context reasoning in LLMs. It constructs multi-hop questions via KG random walks and uses search-agent trajectories to generate tiered distractors (high-confusability: documents read but uncited; low-confusability: results never opened). A positive-only rubric reward provides entity-level process supervision on gold entities, applied only to correct final answers. Experiments across three model sizes (4B–30B) and five benchmarks show consistent outperformance over strong baselines, with the method encouraging evidence-grounded reasoning. Code, data, and models are released.
Significance. If the empirical results hold under rigorous verification, the work offers a targeted engineering advance over prior RLVR methods by addressing low-confusability distractors and outcome-only rewards. The open release of artifacts strengthens reproducibility and enables follow-up work on long-context supervision.
major comments (2)
- [Experiments] Experiments section: the central claim of consistent outperformance requires explicit reporting of baseline implementations (including whether they receive the same tiered-distractor data) and statistical testing (e.g., standard errors or significance across seeds); without these, gains cannot be confidently attributed to the rubric reward versus data construction.
- [Reward Design] Reward design and ablations: the positive-only strategy is presented as preventing reward hacking while distinguishing reasoning quality, yet the manuscript must include an ablation comparing it to a version that includes negative examples or removes the rubric to confirm the claimed benefit; this is load-bearing for the reward contribution.
minor comments (2)
- Introduction and abstract: 'strong baselines' should be named with citations and brief descriptions on first mention rather than left implicit.
- [Data Construction] Data construction: clarify the exact procedure for extracting gold entities along reasoning chains and any filtering rules applied to trajectories.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim of consistent outperformance requires explicit reporting of baseline implementations (including whether they receive the same tiered-distractor data) and statistical testing (e.g., standard errors or significance across seeds); without these, gains cannot be confidently attributed to the rubric reward versus data construction.
Authors: We agree that explicit details on baseline implementations and statistical testing are required to attribute gains confidently. In the revision we will add a dedicated subsection describing how each baseline was trained, explicitly stating whether the same tiered-distractor data was used, and will report standard errors across multiple seeds together with statistical significance tests. revision: yes
-
Referee: [Reward Design] Reward design and ablations: the positive-only strategy is presented as preventing reward hacking while distinguishing reasoning quality, yet the manuscript must include an ablation comparing it to a version that includes negative examples or removes the rubric to confirm the claimed benefit; this is load-bearing for the reward contribution.
Authors: We acknowledge that an ablation isolating the positive-only rubric is necessary to substantiate its contribution. We will add experiments comparing the current positive-only rubric reward against (i) a variant that incorporates negative examples and (ii) a version that removes the rubric entirely, reporting the results in the revised manuscript. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical RL pipeline for long-context reasoning: KG random walks to generate questions, search-agent trajectories to construct tiered distractors, and a positive-only rubric reward based on gold entities. No equations, derivations, or fitted parameters are presented that reduce any reported outcome to a quantity defined by the method's own inputs. Results are measured on five external benchmarks across three LLMs, with the method presented as falsifiable via ablations; the contribution remains self-contained without self-definitional, fitted-prediction, or self-citation-load-bearing reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Search agent trajectories reliably identify high-confusability distractors that are more challenging than random or one-shot sampling
- domain assumption Entity-level rubric rewards applied only to correct final answers distinguish reasoning quality without enabling reward hacking
Reference graph
Works this paper leans on
-
[1]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao
Qwenlong-l1.5: Post-training recipe for long- context reasoning and memory management.CoRR, abs/2512.12967. Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Re- flexion: language agents with verbal reinforcement learning. InAdvances in Neural Information Pro- cessing Systems 36: Annual Conference on Neural Informati...
-
[2]
arXiv preprint arXiv:2510.19363 , year=
Loongrl: Reinforcement learning for ad- vanced reasoning over long contexts.CoRR, abs/2510.19363. John Yang, Carlos E. Jimenez, Alexander Wettig, Kil- ian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer in- terfaces enable automated software engineering. In Advances in Neural Information Processing Systems 38: Annua...
-
[3]
Chaining the evidence: Robust reinforcement learning for deep search agents with citation-aware rubric rewards.CoRR, abs/2601.06021. Dawei Zhu, Xiyu Wei, Guangxiang Zhao, Wenhao Wu, Haosheng Zou, Junfeng Ran, Xun Wang, Lin Sun, Xiangzheng Zhang, and Sujian Li. 2025a. Chain-of- thought matters: Improving long-context language models with reasoning path sup...
-
[4]
Mixed North African population, identity emerged through cultural blending after eastern tribal migrations
"Mixed North African population, identity emerged through cultural blending after eastern tribal migrations." → Doc [4] Arab-Berbers: mixed Berber/Arab origin, formed via Arab conquest and intermarriage (incl. Banu Hilal migration). … So the watercourse is the Genil. </think> Let me work through the chain step by step, matching each clue with the documents
-
[5]
The Arab-Berber identity came into being as a direct result of the Arab conquest of North Africa, and the intermarriage
Mixed North African population from eastern migrations → Arab-Berbers [Doc 4]: > "Arab-Berbers are people of mixed Berber, Arab and other non-Berber origin... The Arab-Berber identity came into being as a direct result of the Arab conquest of North Africa, and the intermarriage... Banu Hilal and Sulaym Arab tribes... intermarried with the local rural main...
-
[6]
The Banu Hilal... emigrated to North Africa in the 11th century... they quickly defeated the Zirids and deeply weakened the neighboring Hammadid dynasty and the Zenata
Migrating confederation that weakened a Berber confederacy → Banu Hilal weakened the Zenata [Doc 3]: > "The Banu Hilal... emigrated to North Africa in the 11th century... they quickly defeated the Zirids and deeply weakened the neighboring Hammadid dynasty and the Zenata." The Zenata [Doc 1] later produced a ruling house — the Marinids [Doc 5]: "a Sunni M...
-
[7]
supported the Kingdom of Granada in Al-Andalus
Dynasty ruling a western Maghrebi realm, intervening across a narrow sea → Marinid dynasty [Doc 5]: > "ruled Morocco from the 13th to the 15th century... supported the Kingdom of Granada in Al-Andalus... attempt to gain a direct foothold on the European side of the Strait of Gibraltar."
-
[8]
between 1482 and 1491, during the reign of the Catholic Monarchs Isabella I of Castile and Ferdinand II of Aragon... ending all Islamic rule on the Iberian peninsula
Final Islamic state in the peninsula, destroyed by united Christian crowns → Emirate of Granada, destroyed in the Granada War [Doc 10]: > "between 1482 and 1491, during the reign of the Catholic Monarchs Isabella I of Castile and Ferdinand II of Aragon... ending all Islamic rule on the Iberian peninsula."
-
[9]
In January 1492 Muhammad XII of Granada, the last Nasrid ruler... formally relinquished his sovereignty and surrendered his territories to Castile
Final ruler formally yielding authority → Muhammad XII (Boabdil) [Doc 2]: > "In January 1492 Muhammad XII of Granada, the last Nasrid ruler... formally relinquished his sovereignty and surrendered his territories to Castile."
-
[10]
the royal procession moved from Santa Fe to a place a little more than a mile from Granada, where Ferdinand took up his position by the banks of the Genil
Watercourse at the ceremonial surrender → From Doc [7], eyewitness letter to the bishop of León: > "the royal procession moved from Santa Fe to a place a little more than a mile from Granada, where Ferdinand took up his position by the banks of the Genil." Doc [6] confirms the Genil flows through Granada. Final Answer: Genil (Genil River) Case from rollou...
2023
-
[11]
2021-2025 Engineering Industry Forecast
"2021-2025 Engineering Industry Forecast" — ACEC Research Institute (Doc 5): 5-year forecast explicitly covering 2022
2021
-
[12]
2022 engineering and construction industry outlook
"2022 engineering and construction industry outlook" — Deloitte Research Center for Energy & Industrials (Doc 9): explicitly a 2022 outlook. Case 3 on AA-LCR: Fully Solved by LongTraceRL-4B Figure 11: A success case from AA-LCR where the LONGTRACERL-4B trained with rubric reward checks each candidate document and finds both qualifying outlooks with correc...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.