An Empirical Study on Logging Evolution On Stack Overflow: Trends, Topics, and Challenges
Pith reviewed 2026-06-29 10:30 UTC · model grok-4.3
The pith
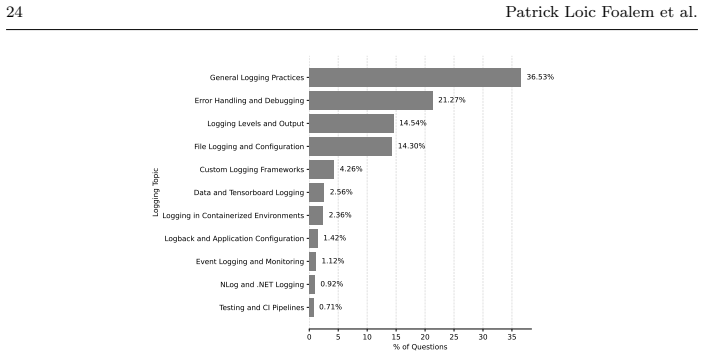
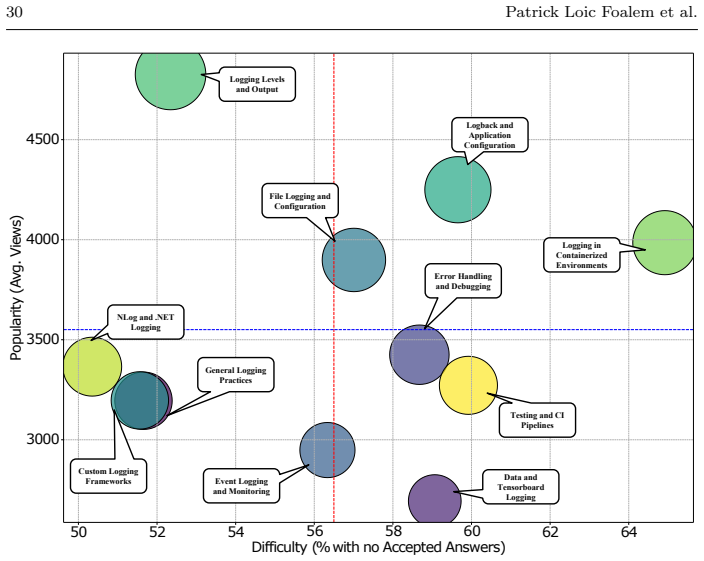
Logging in containerized environments is the most challenging topic on Stack Overflow, with 64.9% of questions lacking accepted answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our analysis identifies 11 distinct topics, with the top three (General Logging Practices, Error Handling and Debugging, and Logging Levels and Output) accounting for over 70% of all logging-related discussions. Notably, Logging in Containerized Environments emerged as the most difficult topic: 64.9% of its questions lack an accepted answer, and its median resolution time is among the highest. These findings highlight enduring practitioner struggles with logging in Docker or other containerized environments and the integration of logging pipelines into orchestrators such as Kubernetes and cloud environments.
What carries the argument
LLM-based classification of posts into 11 topics validated on a manually checked ground-truth sample, together with three community metrics of difficulty: share of questions without accepted answers, share of unanswered questions, and median time to an accepted answer.
If this is right
- General Logging Practices, Error Handling and Debugging, and Logging Levels and Output together dominate more than 70% of logging questions.
- Logging in Containerized Environments shows the worst difficulty scores of the 11 topics.
- The data indicate concrete integration problems when logging pipelines meet Docker, Kubernetes, and cloud orchestrators.
- The results supply direct guidance for developers, framework vendors, researchers, and educators on where logging support is weakest.
Where Pith is reading between the lines
- Tool vendors could reduce unanswered questions by shipping clearer logging examples and APIs for container orchestration platforms.
- Educators might add targeted modules on container logging to lower the observed resolution times.
- Repeating the same classification on GitHub issues or other forums could test whether the difficulty ranking holds outside Stack Overflow.
Load-bearing premise
The LLM classifier assigns posts to the 11 topics correctly and the three chosen community metrics accurately measure how difficult each topic is.
What would settle it
A fresh manual review of several thousand posts that produces a materially different topic distribution or changes which topic ranks as most difficult on the three metrics would falsify the central claims.
Figures







read the original abstract
Context: Logging is a crucial practice in software engineering, aiding developers in debugging applications when errors occur. While existing research has explored logging challenges from an academic perspective through literature reviews and source code analysis, a comprehensive study from the practitioners' perspective remains lacking. Objective: This paper aims to bridge this knowledge gap by presenting an in-depth analysis of trends, topics, and challenges in logging based on a dataset of 216,094 posts from Stack Overflow (SO), a popular Q\&A platform for developers. Method: We analyzed longitudinal trends by examining metadata related to users, questions, and tags associated with logging discussions. To identify prevalent discussion topics, we employed a Large Language Model (LLM)--based classification approach, based on a manually validated ground-truth sample. Topic popularity was assessed through average scores and views, while difficulty was measured using three community-driven metrics: the proportion of questions without accepted answers, the proportion of unanswered questions, and the median time to receive an accepted answer. Results: Our analysis identifies 11 distinct topics, with the top three (General Logging Practices, Error Handling and Debugging, and Logging Levels and Output) accounting for over 70\% of all logging-related discussions. Notably, Logging in Containerized Environments emerged as the most difficult topic: 64.9\% of its questions lack an accepted answer, and its median resolution time is among the highest. These findings highlight enduring practitioner struggles with logging in Docker or other containerized environments and the integration of logging pipelines into orchestrators such as Kubernetes and cloud environments. Conclusion: This study sheds light on the practical challenges of logging and provides actionable insights for developers, framework vendors, researchers, and educators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an empirical analysis of 216,094 Stack Overflow posts on logging. It examines longitudinal trends through user/question/tag metadata, applies an LLM-based classifier (validated against a manually checked ground-truth sample) to derive 11 topics, measures popularity via average scores and views, and quantifies difficulty via three community metrics (fraction without accepted answers, fraction unanswered, and median time to accepted answer). Key results are that the top three topics (General Logging Practices, Error Handling and Debugging, Logging Levels and Output) cover >70% of posts and that Logging in Containerized Environments is the hardest topic (64.9% lack an accepted answer, high median resolution time).
Significance. If the classification and metric results hold, the study supplies a large-scale, practitioner-grounded complement to existing academic logging literature. The scale of the dataset and the use of observable community metrics (accepted-answer rate, resolution time) are strengths that could support reproducible follow-up work. The identification of containerized environments as a persistent difficulty area offers concrete, actionable signals for tool builders, educators, and framework maintainers.
major comments (1)
- [Method] Method section (LLM classification paragraph): the claim that classification rests on 'a manually validated ground-truth sample' supplies no sample size, sampling procedure, inter-annotator agreement statistic, or per-topic confusion matrix. Because the headline topic distribution (>70% in top three) and the difficulty ranking of 'Logging in Containerized Environments' (64.9% no accepted answer) are direct functions of the 11-way partition of the 216 k posts, the absence of these validation quantities is load-bearing for the central empirical claims.
minor comments (2)
- [Results] Results section: the three difficulty metrics are presented without any control for potential confounders (e.g., question quality, asker reputation, tag visibility) that could correlate with topic; a short discussion of this would strengthen interpretability.
- [Abstract] Abstract and title: 'Evolution' appears in the title yet the reported analysis is cross-sectional topic classification plus aggregate trends; clarifying whether temporal evolution of the 11 topics themselves was measured would remove ambiguity.
Simulated Author's Rebuttal
Thank you for the thorough review and the recommendation for major revision. We have carefully considered the referee's comment on the validation of our LLM-based topic classification and provide a point-by-point response below. We commit to revising the manuscript accordingly to enhance the transparency and reproducibility of our methods.
read point-by-point responses
-
Referee: [Method] Method section (LLM classification paragraph): the claim that classification rests on 'a manually validated ground-truth sample' supplies no sample size, sampling procedure, inter-annotator agreement statistic, or per-topic confusion matrix. Because the headline topic distribution (>70% in top three) and the difficulty ranking of 'Logging in Containerized Environments' (64.9% no accepted answer) are direct functions of the 11-way partition of the 216 k posts, the absence of these validation quantities is load-bearing for the central empirical claims.
Authors: We agree that the current manuscript does not provide sufficient details on the ground-truth sample used to validate the LLM classifier. This information is indeed critical for assessing the reliability of the 11-topic classification and the subsequent analyses. In the revised version, we will expand the Method section to report the sample size, the sampling procedure employed, the inter-annotator agreement statistics, and include a per-topic confusion matrix. These additions will directly address the load-bearing nature of the validation for our empirical claims. revision: yes
Circularity Check
No circularity: purely empirical analysis of external public data
full rationale
The paper performs a standard empirical study on 216k Stack Overflow posts, using LLM classification validated against a manually checked ground-truth sample and three community metrics computed directly from post metadata. No equations, fitted parameters, predictions derived from subsets of the same data, or self-citation chains appear in the derivation. All reported statistics (topic distributions, difficulty rankings) are direct aggregates of observed SO data and are therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The manually validated ground-truth sample is representative and sufficient to confirm LLM classification accuracy across the full 216k posts.
Reference graph
Works this paper leans on
-
[1]
Un- veiling inefficiencies in llm-generated code: Toward a comprehensive taxonomy
Altaf Allah Abbassi, Leuson Da Silva, Amin Nikanjam, and Foutse Khomh. Un- veiling inefficiencies in llm-generated code: Toward a comprehensive taxonomy. arXiv preprint arXiv:2503.06327,
-
[2]
A systematic literature review on using machine learning algorithms for software requirements identification on stack overflow
Arshad Ahmad, Chong Feng, Muzammil Khan, Asif Khan, Ayaz Ullah, Shah Nazir, and Adnan Tahir. A systematic literature review on using machine learning algorithms for software requirements identification on stack overflow. Security and Communication Networks, 2020(1):8830683,
2020
-
[3]
An exploratory study on how software reuse is discussed in stack overflow
Eman Abdullah AlOmar, Diego Barinas, Jiaqian Liu, Mohamed Wiem Mkaouer, Ali Ouni, and Christian Newman. An exploratory study on how software reuse is discussed in stack overflow. InReuse in Emerging Software Engineering Practices: 19th International Conference on Software and Systems Reuse, ICSR 2020, Hammamet, Tunisia, December 2–4, 2020, Proceedings 19,...
2020
-
[4]
Going big: a large-scale study on what big data developers ask
Mehdi Bagherzadeh and Raffi Khatchadourian. Going big: a large-scale study on what big data developers ask. InProceedings of the 2019 27th ACM joint meeting on european software engineering conference and symposium on the foundations of software engineering, pages 432–442,
2019
-
[5]
Leuson Da Silva, Jordan Samhi, and Foutse Khomh. Chatgpt vs llama: Im- pact, reliability, and challenges in stack overflow discussions.arXiv preprint arXiv:2402.08801,
-
[6]
Replication package: Ml challenge
Leuson Foalem, Foutse, and Heng. Replication package: Ml challenge. 2024a. URL https://doi.org/10.6084/m9.figshare.31062553. Patrick Loic Foalem, Foutse Khomh, and Heng Li. Studying logging practice in machine learning-based applications.Information and Software Technology, 170: 107450, 2024b. Patrick Loic Foalem, Leuson Da Silva, Foutse Khomh, Heng Li, a...
-
[7]
Contextual analysis of program logs for understanding system behaviors
Qiang Fu, Jian-Guang Lou, Qingwei Lin, Rui Ding, Dongmei Zhang, and Tao Xie. Contextual analysis of program logs for understanding system behaviors. In 2013 10th Working Conference on Mining Software Repositories (MSR), pages 397–400. IEEE,
2013
-
[8]
Sina Gholamian and Paul AS Ward. A comprehensive survey of logging in software: From logging statements automation to log mining and analysis.arXiv preprint arXiv:2110.12489,
-
[9]
From code to courtroom: Llms as the new software judges.arXiv preprint arXiv:2503.02246,
Junda He, Jieke Shi, Terry Yue Zhuo, Christoph Treude, Jiamou Sun, Zhenchang Xing, Xiaoning Du, and David Lo. From code to courtroom: Llms as the new software judges.arXiv preprint arXiv:2503.02246,
-
[10]
doi: 10.1109/TNSM.2024.3440188. PYPL Index. Pypl popularity of programming languages,
-
[11]
What Do Developers Ask About ML Libraries? A Large-scale Study Using Stack Overflow
Md Johirul Islam, Hoan Anh Nguyen, Rangeet Pan, and Hridesh Rajan. What do developers ask about ml libraries? a large-scale study using stack overflow. arXiv preprint arXiv:1906.11940,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[12]
Failure pre- diction in ibm bluegene/l event logs
Yinglung Liang, Yanyong Zhang, Hui Xiong, and Ramendra Sahoo. Failure pre- diction in ibm bluegene/l event logs. InSeventh IEEE International Conference on Data Mining (ICDM 2007), pages 583–588. IEEE,
2007
-
[13]
Engineering ai judge systems.arXiv preprint arXiv:2411.17793,
Jiahuei Lin, Dayi Lin, Sky Zhang, and Ahmed E Hassan. Engineering ai judge systems.arXiv preprint arXiv:2411.17793,
-
[14]
Title Suppressed Due to Excessive Length 45 Yida Mu, Chun Dong, Kalina Bontcheva, and Xingyi Song. Large language models offer an alternative to the traditional approach of topic modelling.arXiv preprint arXiv:2403.16248,
-
[15]
2024 State of the Java Ecosystem.https://shorturl.at/lP2RR,
New Relic. 2024 State of the Java Ecosystem.https://shorturl.at/lP2RR,
2024
-
[16]
Stack Overflow.https://stackoverflow.com/questions/71354500, 2025a. Re- trieved on October 10,
-
[17]
Stack Overflow.https://stackoverflow.com/questions/54467849, 2025b. Re- trieved on October 10,
-
[18]
Stack Overflow.https://stackoverflow.com/questions/2031163, 2025c. Re- trieved on October 10,
-
[19]
Stack Overflow.https://stackoverflow.com/questions/14058453, 2025d
46 Patrick Loic Foalem et al. Stack Overflow.https://stackoverflow.com/questions/14058453, 2025d. Re- trieved on October 10,
-
[20]
Stack Overflow.https://stackoverflow.com/questions/78958199, 2025e. Re- trieved on October 10,
-
[21]
Stack Overflow.https://stackoverflow.com/questions/78901762, 2025f. Re- trieved on October 10,
-
[22]
Stack Overflow.https://stackoverflow.com/questions/4587174, 2025g. Re- trieved on October 10,
-
[23]
Stack Overflow.https://stackoverflow.com/questions/78860915, 2025h. Re- trieved on October 10,
-
[24]
Stack Overflow.https://stackoverflow.com/questions/5190860, 2025i. Re- trieved on October 10,
-
[25]
Stack Overflow.https://stackoverflow.com/questions/78613726, 2025j. Re- trieved on October 10,
-
[26]
Codejudge: Evaluating code generation with large language models.arXiv preprint arXiv:2410.02184,
Weixi Tong and Tianyi Zhang. Codejudge: Evaluating code generation with large language models.arXiv preprint arXiv:2410.02184,
-
[27]
Mining event logs with slct and loghound
Risto Vaarandi. Mining event logs with slct and loghound. InNOMS 2008- 2008 IEEE Network Operations and Management Symposium, pages 1071–1074. IEEE,
2008
-
[28]
Ai persona: Towards life-long personalization of llms.arXiv preprint arXiv:2412.13103,
Tiannan Wang, Meiling Tao, Ruoyu Fang, Huilin Wang, Shuai Wang, Yuchen Eleanor Jiang, and Wangchunshu Zhou. Ai persona: Towards life-long personalization of llms.arXiv preprint arXiv:2412.13103,
-
[29]
An empir- ical study of common challenges in developing deep learning applications
Tianyi Zhang, Cuiyun Gao, Lei Ma, Michael Lyu, and Miryung Kim. An empir- ical study of common challenges in developing deep learning applications. In 2019 IEEE 30th International Symposium on Software Reliability Engineering (ISSRE), pages 104–115. IEEE,
2019
-
[30]
Learning to log: Helping developers make informed logging decisions
Jieming Zhu, Pinjia He, Qiang Fu, Hongyu Zhang, Michael R Lyu, and Dongmei Zhang. Learning to log: Helping developers make informed logging decisions. In 2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, volume 1, pages 415–425. IEEE, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.