Regime-Adaptive Continual Learning for Portfolio Management
Pith reviewed 2026-06-28 20:28 UTC · model grok-4.3
The pith
ReCAP segments market data into regimes, builds a policy library, and updates only the active policy to adapt without forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
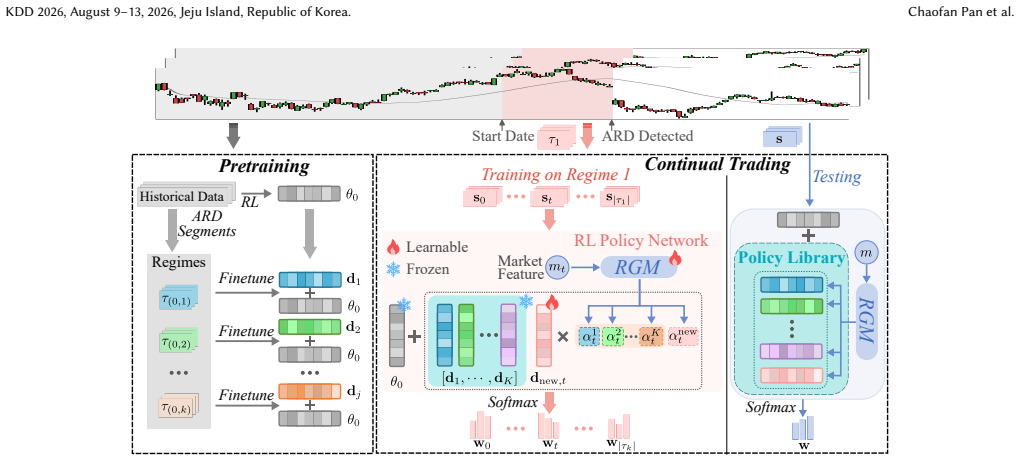
ReCAP employs an adaptive regime detection module to segment historical market data into variable-length regimes, enabling regime-specific learning of policy vectors and the construction of a policy library. During continual trading, a regime-gate module adaptively combines policy vectors from the library based on the current market state, facilitating rapid adaptation to newly detected regimes. Only the regime-gate and the current regime's policy vector are continually updated to preserve useful knowledge effectively.
What carries the argument
The regime detection module plus the regime-gate, which together maintain and selectively activate policies from a growing library.
Load-bearing premise
That market history breaks into regimes where separate policies deliver clear gains over any single shared policy.
What would settle it
If regime detection on a dataset produces segments whose optimal policies are statistically indistinguishable, ReCAP's returns should fall to the level of a single-policy baseline.
Figures


read the original abstract
Financial markets are inherently non-stationary, exhibiting frequent regime shifts and structural changes that render traditional Portfolio Management (PM) approaches ineffective. Existing remedies, such as rolling-window retraining and naive online fine-tuning, are hindered by high computational costs and insufficient knowledge utilization, respectively, resulting in low returns and limited adaptability. Continual learning (CL) offers a promising paradigm by enabling trading agents to accumulate and transfer knowledge across sequential tasks. In this paper, we propose \textbf{Re}gime-aware \textbf{C}ontinual \textbf{A}daptive \textbf{P}ortfolio management (\textbf{ReCAP}), a novel framework that integrates CL into PM to address the challenges of dynamic financial environments. ReCAP employs an adaptive regime detection module to segment historical market data into variable-length regimes, enabling regime-specific learning of policy vectors and the construction of a policy library. During continual trading, a regime-gate module adaptively combines policy vectors from the library based on the current market state, facilitating rapid adaptation to newly detected regimes. Only the regime-gate and the current regime's policy vector are continually updated to preserve useful knowledge effectively. Extensive experiments on five real-world datasets demonstrate that ReCAP consistently outperforms popular baselines, achieving superior returns in long-term investment horizons and rapid adaptation to regime shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
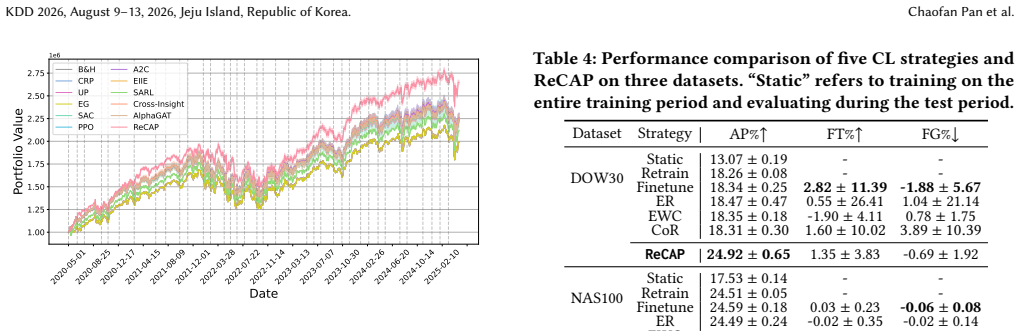
Summary. The manuscript proposes ReCAP, a continual learning framework for portfolio management that uses an adaptive regime detection module to segment historical market data into variable-length regimes, learns regime-specific policy vectors stored in a policy library, and employs a regime-gate module to combine policies for rapid adaptation during trading. Only the regime-gate and current regime's policy are updated to preserve knowledge. The central empirical claim is that ReCAP outperforms popular baselines on five real-world datasets, delivering superior returns over long horizons and faster adaptation to regime shifts.
Significance. If the results hold under rigorous controls, the framework offers a practical way to address non-stationarity in PM via selective continual updates and a policy library, potentially improving upon rolling-window retraining and naive fine-tuning. The selective update rule and regime-gate design are strengths that could generalize to other non-stationary sequential decision tasks in finance.
major comments (1)
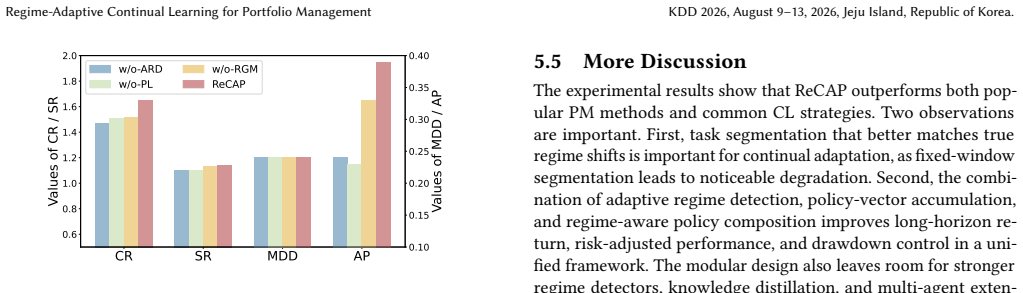
- [Methods and Results sections] The central claim that performance gains arise from regime-specific policies requires that the adaptive regime detection module produces variable-length segments corresponding to meaningfully distinct market states. No direct validation appears in the methods or results (e.g., no regime-specific return/volatility statistics, intra-regime homogeneity tests, or ablation that removes the detection module while retaining the gate and update rules). Without this, gains could be attributable to the gate or continual update mechanics alone, as noted in the skeptic's concern.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on validating the regime detection component. We address the point below and will revise the manuscript to incorporate additional analyses.
read point-by-point responses
-
Referee: [Methods and Results sections] The central claim that performance gains arise from regime-specific policies requires that the adaptive regime detection module produces variable-length segments corresponding to meaningfully distinct market states. No direct validation appears in the methods or results (e.g., no regime-specific return/volatility statistics, intra-regime homogeneity tests, or ablation that removes the detection module while retaining the gate and update rules). Without this, gains could be attributable to the gate or continual update mechanics alone, as noted in the skeptic's concern.
Authors: We agree that direct empirical validation of the regime detection module is necessary to isolate its contribution to the observed performance gains. The current manuscript relies on end-to-end performance and adaptation speed to imply the value of regime-specific policies, but does not provide the requested regime-level statistics or component ablation. In the revised version we will add: (i) regime-specific return and volatility statistics across the detected segments on all five datasets, (ii) intra-regime homogeneity metrics (e.g., variance of returns within each regime), and (iii) an ablation that disables the adaptive regime detection module while retaining the regime-gate and selective update rules. These additions will clarify whether the gains are attributable to the regime segmentation itself. revision: yes
Circularity Check
No circularity; framework and claims rest on external datasets and independent components
full rationale
The provided abstract and description present ReCAP as a novel integration of continual learning with adaptive regime detection and a policy library, with performance claims grounded in experiments on five external real-world datasets. No equations, self-citations, or derivation steps are shown that reduce predictions or regime segmentation to fitted inputs by construction, nor is any uniqueness theorem or ansatz imported from prior author work. The central claims remain independent of the method's own outputs, satisfying the criteria for a self-contained non-circular presentation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Guido Abate, Ignazio Basile, and Pierpaolo Ferrari. 2024. The Integration of Environmental, Social and Governance Criteria in Portfolio Optimization: An Empirical Analysis.Corporate Social Responsibility and Environmental Manage- ment31, 3 (2024), 2054–2065
2024
-
[2]
David Abel, André Barreto, Benjamin Van Roy, Doina Precup, Hado P van Hasselt, and Satinder Singh. 2023. A Definition of Continual Reinforcement Learning. In NeurIPS, Vol. 36. 50377–50407. KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Chaofan Pan et al
2023
-
[3]
Schapire
Amit Agarwal, Elad Hazan, Satyen Kale, and Robert E. Schapire. 2006. Algorithms for portfolio management based on the Newton method. InICML. 9–16
2006
-
[4]
Andrew Ang and Allan Timmermann. 2012. Regime Changes and Financial Markets.Annual Review of Financial Economics4, 2012 (2012), 313–337. https: //doi.org/10.1146/annurev-financial-110311-101808
-
[5]
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. 2018. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling.arXiv preprint arXiv:1803.0127110 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Avrim Blum and Adam Kalai. 1997. Universal Portfolios With and Without Transaction Costs. InCOLT. 309–313
1997
-
[7]
Allan Borodin, Ran El-Yaniv, and Vincent Gogan. 2000. On the Competitive Theory and Practice of Portfolio Selection. InLATIN. Springer, 173–196
2000
-
[8]
Allan Borodin, Ran El-Yaniv, and Vincent Gogan. 2003. Can We Learn to Beat the Best Stock. InNeurIPS, Vol. 16
2003
-
[9]
Barkha Dhingra, Shallu Batra, Vaibhav Aggarwal, Mahender Yadav, and Pankaj Kumar. 2024. Stock Market Volatility: A Systematic Review.Journal of Modelling in Management19, 3 (2024), 925–952
2024
-
[10]
István Erlich, Ganesh K Venayagamoorthy, and Nakawiro Worawat. 2010. A Mean-Variance Optimization Algorithm. InIEEE CEC. 1–6
2010
-
[11]
Li Gao and Weiguo Zhang. 2013. Weighted Moving Average Passive Aggressive Algorithm for Online Portfolio Selection. InIHMSC, Vol. 1. 327–330
2013
- [12]
-
[13]
Stefano Giglio, Bryan Kelly, and Dacheng Xiu. 2022. Factor Models, Machine Learning, and Asset Pricing.Annual Review of Financial Economics14, 1 (2022), 337–368
2022
-
[14]
Abhishek Gunjan and Siddhartha Bhattacharyya. 2023. A Brief Review of Portfo- lio Optimization Techniques.Artificial Intelligence Review56, 5 (2023), 3847–3886
2023
-
[15]
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. 2018. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. InICML. 1861–1870
2018
-
[16]
Muhammad Burhan Hafez and Stefan Wermter. 2021. Behavior Self-Organization Supports Task Inference for Continual Robot Learning. InIROS. IEEE, 6739–6746
2021
-
[17]
Jiayi He, Pengjian Shang, and Yali Zhang. 2020. Global Recurrence Quantification Analysis and Its Application in Financial Time Series.Nonlinear Dynamics100 (2020), 803–829
2020
-
[18]
David P Helmbold, Robert E Schapire, Yoram Singer, and Manfred K Warmuth
-
[19]
On-Line Portfolio Selection Using Multiplicative Updates.Mathematical Finance8, 4 (1998), 325–347
1998
-
[20]
Mohammad Enamul Hoque, Low Soo-Wah, and Mabruk Billah. 2023. Time- Frequency Connectedness and Spillover Among Carbon, Climate, and Energy Futures: Determinants and Portfolio Risk Management Implications.Energy Economics127 (2023), 107034
2023
-
[21]
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Han- naneh Hajishirzi, and Ali Farhadi. 2023. Editing models with task arithmetic. In ICLR
2023
-
[22]
David Isele and Akansel Cosgun. 2018. Selective Experience Replay for Lifelong Learning, In AAAI.AAAI32, 1, 3302–3309
2018
-
[23]
Zhengyao Jiang, Dixing Xu, and Jinjun Liang. 2017. A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem.arXiv preprint arXiv:1706.10059(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Dimitrios Katsikas, Nikolaos Passalis, and Anastasios Tefas. 2024. Bi-Directional Knowledge Transfer For Continual Deep Reinforcement Learning in Financial Trading. InMLSP. 1–6
2024
-
[25]
Dimitrios Katsikas, Nikolaos Passalis, and Anastasios Tefas. 2025. Plasticity Driven Knowledge Transfer for Continual Deep Reinforcement Learning in Financial Trading. InICPR. 80–93
2025
-
[26]
Khimya Khetarpal, Matthew Riemer, Irina Rish, and Doina Precup. 2022. To- wards Continual Reinforcement Learning: A Review and Perspectives.Journal of Artificial Intelligence Research75 (2022), 1401–1476
2022
-
[27]
Baddar, Kikyung Kim, HUIJIN LEE, Sae- hyun Ahn, Seungju Han, Sungjoo Suh, and Eunho Yang
Byungjai Kim, Chanho Ahn, Wissam J. Baddar, Kikyung Kim, HUIJIN LEE, Sae- hyun Ahn, Seungju Han, Sungjoo Suh, and Eunho Yang. 2025. Test-Time Ensem- ble via Linear Mode Connectivity: A Path to Better Adaptation. InICLR
2025
-
[28]
Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. 2017. Overcoming Catastrophic Forgetting in Neural Networks. Proceedings of the National Academy of Sciences114, 13 ...
2017
-
[29]
Jinho Lee, Raehyun Kim, Seok-Won Yi, and Jaewoo Kang. 2020. MAPS: Multi- Agent reinforcement learning-based Portfolio management System.. InIJCAI. 4520–4526
2020
-
[30]
Bin Li and Steven C. H. Hoi. 2012. On-line portfolio selection with moving average reversion. InICML. 563–570
2012
-
[31]
Shicheng Li, Jinshan Zhang, and Feng Wang. 2025. AlphaGAT: A Two-Stage Learning Approach for Adaptive Portfolio Selection. InIJCAI, Vol. 1. 7500–7508
2025
-
[32]
Xiao-Yang Liu, Hongyang Yang, Jiechao Gao, and Christina Dan Wang. 2021. FinRL: Deep reinforcement learning framework to automate trading in quantita- tive finance. InACM ICAIF
2021
-
[33]
Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timo- thy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. 2016. Asynchro- nous Methods for Deep Reinforcement Learning. InICML. 1928–1937
2016
-
[34]
Sattarov Otabek and Jaeyoung Choi. 2024. Multi-Level Deep Q-Networks for Bitcoin Trading Strategies.Scientific Reports14, 1 (2024), 771
2024
-
[35]
Adedoyin Tolulope Oyewole, Omotayo Bukola Adeoye, Wilhelmina Afua Addy, Chinwe Chinazo Okoye, Onyeka Chrisanctus Ofodile, and Chinonye Esther Ugochukwu. 2024. Predicting Stock Market Movements Using Neural Networks: A Review and Application Study.Computer Science & IT Research Journal5, 3 (2024), 651–670
2024
-
[36]
Chaofan Pan, Lingfei Ren, Yihui Feng, Linbo Xiong, Wei Wei, Yonghao Li, and Xin Yang. 2025. Multi-granularity Knowledge Transfer for Continual Reinforcement Learning. InIJCAI
2025
-
[37]
Chaofan Pan, Xin Yang, Yanhua Li, Wei Wei, Tianrui Li, Bo An, and Jiye Liang. 2025. A Survey of Continual Reinforcement Learning.arXiv preprint arXiv:2506.21872(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Julien Pénasse. 2022. Understanding Alpha Decay.Management Science68, 5 (2022), 3966–3973
2022
-
[39]
Sam Powers, Eliot Xing, Eric Kolve, Roozbeh Mottaghi, and Abhinav Gupta
-
[40]
InCoLLAs, Vol
CORA: Benchmarks, Baselines, and Metrics as a Platform for Continual Reinforcement Learning Agents. InCoLLAs, Vol. 199. 705–743
-
[41]
Huntley Schaller and Simon Van Norden. 1997. Regime Switching in Stock Market Returns.Applied Financial Economics7, 2 (1997), 177–191
1997
-
[42]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[43]
Proximal Policy Optimization Algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[44]
Ashish Kumar Shakya, Gopinatha Pillai, and Sohom Chakrabarty. 2023. Rein- forcement Learning Algorithms: A Brief Survey.Expert Systems with Applications 231 (2023), 120495
2023
-
[45]
William F Sharpe. 1970. Efficient Capital Markets: A Review of Theory and Empirical Work: Discussion.The Journal of Finance25, 2 (1970), 418–420
1970
-
[46]
Farzan Soleymani and Eric Paquet. 2021. Deep graph convolutional reinforcement learning for financial portfolio management – DeepPocket.Expert Systems with Applications182 (2021), 115127
2021
-
[47]
Rafał Surdej, Michał Bortkiewicz, Alex Lewandowski, Mateusz Ostaszewski, and Clare Lyle. 2025. Balancing Expressivity and Robustness: Constrained Rational Activations for Reinforcement Learning. InCoLLAs
2025
-
[48]
Taariq GH Surtee and Imhotep Paul Alagidede. 2023. A Novel Approach to Using Modern Portfolio Theory.Borsa Istanbul Review23, 3 (2023), 527–540
2023
-
[49]
Rundong Wang, Hongxin Wei, Bo An, Zhouyan Feng, and Jun Yao. 2021. Com- mission Fee Is Not Enough: A Hierarchical Reinforced Framework for Portfolio Management. InAAAI, Vol. 35. 626–633
2021
-
[50]
Zhicheng Wang, Biwei Huang, Shikui Tu, Kun Zhang, and Lei Xu. 2021. Deep- trader: A Deep Reinforcement Learning Approach for Risk-Return Balanced Portfolio Management With Market Conditions Embedding. InAAAI, Vol. 35. 643–650
2021
-
[51]
Austin Warner and Georgios Fellouris. 2022. CuSum for sequential change diagnosis. InIEEE ISIT. 486–491
2022
-
[52]
Maciej Wolczyk, Michal Zajac, Razvan Pascanu, Lukasz Kucinski, and Piotr Milos
-
[53]
InNeurIPS
Continual World: A Robotic Benchmark For Continual Reinforcement Learning. InNeurIPS. 28496–28510
-
[54]
Ke Xu, Yifan Zhang, Deheng Ye, Peilin Zhao, and Mingkui Tan. 2020. Relation- Aware Transformer for Portfolio Policy Learning. InIJCAI-20. 4647–4653
2020
-
[55]
Yunan Ye, Hengzhi Pei, Boxin Wang, Pin-Yu Chen, Yada Zhu, Ju Xiao, and Bo Li
-
[56]
InAAAI, Vol
Reinforcement-Learning Based Portfolio Management With Augmented Asset Movement Prediction States. InAAAI, Vol. 34. 1112–1119
-
[57]
Wentao Zhang, Yilei Zhao, Shuo Sun, Jie Ying, Yonggang Xie, Zitao Song, Xinrun Wang, and Bo An. 2024. Reinforcement Learning with Maskable Stock Represen- tation for Portfolio Management in Customizable Stock Pools. InACM WWW. 187–198
2024
-
[58]
Yifan Zhang, Peilin Zhao, Qingyao Wu, Bin Li, Junzhou Huang, and Mingkui Tan. 2022. Cost-Sensitive Portfolio Selection via Deep Reinforcement Learning. IEEE Transactions on Knowledge and Data Engineering34, 1 (2022), 236–248
2022
-
[59]
Zetao Zheng, Jie Shao, Shilong Deng, Anjie Zhu, Heng Tao Shen, and Xiaofang Zhou. 2024. Cross-Insight Trader: A Trading Approach Integrating Policies With Diverse Investment Horizons for Portfolio Management. InICDE. 4685–4698. Appendix A Definitions Definition A.1 (OHLCV).The Open-High-Low-Close-Volume is a time series representation of asset prices. For...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.