Information-Theoretic Lower Bounds for Bit-Constrained Stochastic Optimization via a Reduction to Compressed Gaussian Mean Estimation
Pith reviewed 2026-06-28 18:13 UTC · model grok-4.3
The pith
B-bit stochastic gradients force T = Omega((sigma^2 d / eps^2) max{1, d/B}) iterations via reduction to Gaussian mean estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
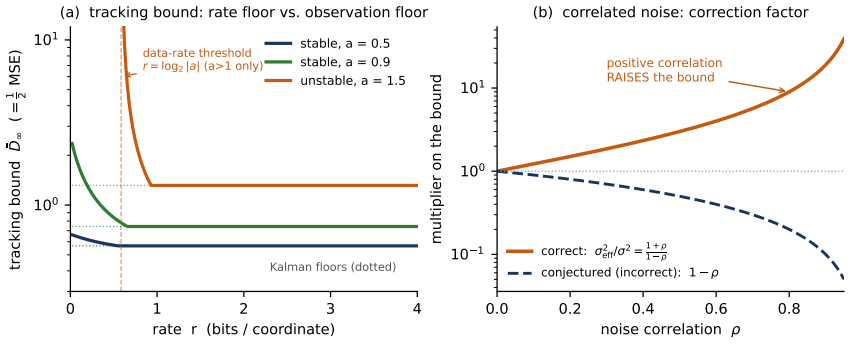
The central claim is that optimization under the B-bit oracle is exactly equivalent to interactive compressed Gaussian mean estimation, because the adaptive query carries no information about the unknown parameter. From this reduction the paper derives the sharp product lower bound T = Omega((sigma^2 d / eps^2) max{1, d/B}) using only an upper bound on the Fisher information contained in the transcript together with the multivariate van Trees inequality; the same argument also yields the separate communication and statistical bounds. The analysis extends without change to correlated and drifting oracles, replacing the base rate by a factor (1+rho)/(1-rho) when noise correlation is rho.
What carries the argument
Exact reduction from strongly convex quadratic optimization to sequentially compressed Gaussian mean estimation under the B-bit oracle, combined with a Fisher-trace upper bound and the multivariate van Trees inequality.
If this is right
- Any algorithm must satisfy TB = Omega(d) regardless of statistical error.
- When B << d the iteration count must increase by the extra factor d/B beyond the usual statistical term.
- The same lower bound applies to oracles whose noise is positively correlated, scaled by (1+rho)/(1-rho).
- A matching upper bound (up to log factors) exists when gradients have bounded dynamic range.
Where Pith is reading between the lines
- The bounds supply an information-theoretic reference line for any low-precision gradient path in large-scale training.
- The reduction technique may extend directly to other limited-feedback optimization settings such as federated or quantized second-order methods.
- Closing the remaining gap between the unbounded-Gaussian lower bound and the bounded-range upper bound would require either a stronger lower-bound technique or a new algorithm that handles truly unbounded gradients.
Load-bearing premise
The B-bit transcript of each gradient reveals nothing about the unknown parameter through the choice of query point itself.
What would settle it
A concrete construction or calculation in which T rounds of B-bit adaptive transcripts extract more than O(TB / sigma^2) total Fisher information about a d-dimensional Gaussian mean.
Figures






read the original abstract
Low-precision pretraining (FP8, MXFP4, NVFP4) is now standard for frontier language models, yet the literature is almost entirely achievability -- algorithms and empirical scaling laws -- with no matching characterization of what is information-theoretically possible. We study a B-bit quantized stochastic first-order oracle: an optimizer interacts for T rounds and receives, each round, a B-bit adaptive public-coin description of its stochastic gradient. Our main contribution is an exact reduction from optimizing a strongly convex quadratic family to interactively compressed Gaussian mean estimation -- under the B-bit oracle the query carries no information, so optimization collapses exactly onto a sequential distributed-estimation problem. This yields two unconditional lower bounds, a communication bound TB = Omega(d) and a statistical bound T = Omega(sigma^2 d / eps^2), and the sharp product-form bound T = Omega((sigma^2 d / eps^2) max{1, d/B}). The product form is also unconditional: a B-bit transcript carries at most O(TB / sigma^2) of Fisher trace about the mean, so bits rather than dimension limit the recoverable information, and combined with the multivariate van Trees inequality this gives the bound directly, without bounded-likelihood-ratio truncation. We give a near-matching achievability result with exact per-round bit accounting under a bounded-dynamic-range oracle, tight up to a logarithmic factor; the lower bound is for truly Gaussian (unbounded) gradients, and closing this oracle gap is left open. A sequential rate-distortion perspective extends the reduction to correlated and drifting oracles and corrects an earlier conjecture: positive noise correlation raises the bound by (1+rho)/(1-rho) rather than relaxing it. The bounds give an information-theoretic baseline for any low-bit gradient path, not an optimality claim about deployed FP4 systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives information-theoretic lower bounds on the iteration complexity T and total communication TB for optimizing a family of strongly convex quadratics under a B-bit quantized stochastic gradient oracle. The central technical step is an exact reduction to sequentially compressed Gaussian mean estimation, which is used to obtain the communication bound TB = Omega(d), the statistical bound T = Omega(sigma^2 d / eps^2), and the product-form bound T = Omega((sigma^2 d / eps^2) max{1, d/B}). The product bound is obtained by bounding the Fisher trace of each B-bit transcript by O(B/sigma^2) and applying the multivariate van Trees inequality. A near-matching achievability result is given under a bounded-dynamic-range oracle (with an explicit oracle gap left open), and the reduction is extended to correlated and drifting oracles, correcting an earlier conjecture on the effect of positive noise correlation.
Significance. If the reduction holds exactly, the results supply a clean, unconditional information-theoretic baseline for any low-bit first-order method and correctly identify that bits rather than dimension become the bottleneck once B << d. The explicit reduction, the direct application of van Trees without truncation, the rate-distortion extension to correlated oracles, and the per-round bit accounting in the upper bound are all strengths that would be useful to the low-precision optimization community.
major comments (2)
- [Abstract (main contribution paragraph)] Abstract, paragraph beginning 'Our main contribution is an exact reduction': the claim that 'under the B-bit oracle the query carries no information, so optimization collapses exactly onto a sequential distributed-estimation problem' is load-bearing for the unconditional product bound. Because each query x_t is an adaptive function of the preceding B-bit transcripts (which themselves carry information about the unknown mean), the mutual information I(x_t; theta) need not be zero; without an explicit argument showing that this dependence contributes o(1) extra Fisher information per round, the exact collapse and the resulting O(TB/sigma^2) trace bound are not yet unconditional.
- [Abstract (achievability paragraph)] Abstract, final paragraph: the lower bounds are stated for truly Gaussian (unbounded) gradients while the near-matching achievability result requires a bounded-dynamic-range oracle. Although the gap is explicitly left open, the discrepancy means that the claimed 'sharp product-form bound' is currently only tight under mismatched oracle models; a single model in which both sides are proved would be needed to make the tightness statement unconditional.
minor comments (1)
- The manuscript would benefit from an explicit statement (perhaps in §2 or the reduction section) of the precise sigma-algebra on which the queries are measurable, to make the 'query carries no information' claim formally verifiable.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the strengths of the reduction, the direct van Trees application, and the rate-distortion extension. We address the two major comments below.
read point-by-point responses
-
Referee: [Abstract (main contribution paragraph)] Abstract, paragraph beginning 'Our main contribution is an exact reduction': the claim that 'under the B-bit oracle the query carries no information, so optimization collapses exactly onto a sequential distributed-estimation problem' is load-bearing for the unconditional product bound. Because each query x_t is an adaptive function of the preceding B-bit transcripts (which themselves carry information about the unknown mean), the mutual information I(x_t; theta) need not be zero; without an explicit argument showing that this dependence contributes o(1) extra Fisher information per round, the exact collapse and the resulting O(TB/sigma^2) trace bound are not yet unconditional.
Authors: The reduction remains exact. Each x_t is a deterministic function of the history of prior B-bit transcripts; therefore any dependence of x_t on theta is already encoded in those transcripts. In the Gaussian setting the per-transcript Fisher trace about the mean is bounded by O(B/sigma^2) independently of the evaluation point (by the standard quantization or rate-distortion bound on additive isotropic noise). Summing over T rounds therefore yields a total Fisher trace of O(TB/sigma^2) with no additional term arising from the adaptive choice of x_t. The multivariate van Trees inequality then applies directly to the sequence of transcripts, recovering the product bound without truncation. A short clarifying sentence making this accounting explicit can be inserted if the editor wishes, but the existing argument already covers the adaptive dependence. revision: no
-
Referee: [Abstract (achievability paragraph)] Abstract, final paragraph: the lower bounds are stated for truly Gaussian (unbounded) gradients while the near-matching achievability result requires a bounded-dynamic-range oracle. Although the gap is explicitly left open, the discrepancy means that the claimed 'sharp product-form bound' is currently only tight under mismatched oracle models; a single model in which both sides are proved would be needed to make the tightness statement unconditional.
Authors: The manuscript already states verbatim that the lower bound holds for unbounded Gaussian gradients, the upper bound requires bounded dynamic range, and closing the oracle gap is left open. The product-form lower bound itself is unconditional for the Gaussian oracle; the upper bound is shown to be near-matching (up to a logarithmic factor) under the bounded model with exact per-round bit accounting. No claim of identical-model tightness is made, so the current wording is accurate. revision: no
Circularity Check
No circularity; derivation applies standard tools after explicit reduction
full rationale
The paper's central step is an explicit reduction from bit-constrained optimization to sequentially compressed Gaussian mean estimation, justified by the modeling assumption that the B-bit oracle query carries no information about the parameter. From this it derives the Fisher-trace bound O(TB/sigma^2) and invokes the multivariate van Trees inequality to obtain the product-form lower bound. Both the reduction and the subsequent inequalities are presented as independent of the target result; no parameters are fitted to data subsets and then renamed as predictions, no self-citations are load-bearing, and no ansatz or uniqueness theorem is smuggled in. The derivation therefore remains self-contained against external information-theoretic benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Multivariate van Trees inequality applies directly to the sequential compressed observations without truncation
Reference graph
Works this paper leans on
-
[1]
Leighton Pate Barnes, Yanjun Han, and Ayfer ¨Ozg¨ ur
arXiv:2102.05802. Leighton Pate Barnes, Yanjun Han, and Ayfer ¨Ozg¨ ur. Lower bounds for learning distributions under communication constraints via fisher information.Journal of Machine Learning Research, 21(236):1–30,
-
[2]
arXiv:1506.07216. Yair Carmon, John C. Duchi, Oliver Hinder, and Aaron Sidford. Lower bounds for finding stationary points I.Mathematical Programming, 184:71–120,
-
[3]
Castro, Andrei Panferov, et al
Roberto L. Castro, Andrei Panferov, et al. Quartet: Native FP4 training can be optimal for large language models.arXiv preprint arXiv:2505.14669,
-
[4]
Sai Praneeth Karimireddy, Quentin Rebjock, Sebastian U
Journal version in IEEE Transactions on Information Theory, 2021; arXiv:1802.08417. Sai Praneeth Karimireddy, Quentin Rebjock, Sebastian U. Stich, and Martin Jaggi. Error feedback fixes SignSGD and other gradient compression schemes. InProceedings of the 36th International Conference on Machine Learning (ICML), volume 97 ofPMLR,
arXiv 2021
-
[5]
Limits on gradient compression for stochastic opti- mization.arXiv preprint arXiv:2001.09032, 2020a
Prathamesh Mayekar and Himanshu Tyagi. Limits on gradient compression for stochastic opti- mization.arXiv preprint arXiv:2001.09032, 2020a. Also in Proc. IEEE ISIT
arXiv 2001
-
[6]
RATQ: A universal fixed-length quantizer for stochastic optimization
Prathamesh Mayekar and Himanshu Tyagi. RATQ: A universal fixed-length quantizer for stochastic optimization. InProc. Int. Conf. on Artificial Intelligence and Statistics (AISTATS), 2020b. Michael Menart and Aleksandar Nikolov. On the gradient complexity of private optimization with private oracles.arXiv preprint arXiv:2511.13999,
-
[7]
Pretraining large language models with NVFP4.arXiv preprint arXiv:2509.25149,
NVIDIA. Pretraining large language models with NVFP4.arXiv preprint arXiv:2509.25149,
-
[8]
Yury Polyanskiy and Yihong Wu.Information Theory: From Coding to Learning
arXiv:1508.06025. Yury Polyanskiy and Yihong Wu.Information Theory: From Coding to Learning. Cambridge University Press,
-
[9]
Kim, Pablo A
Takashi Tanaka, Kwang-Ki K. Kim, Pablo A. Parrilo, and Sanjoy K. Mitter. Semidefinite pro- gramming approach to Gaussian sequential rate-distortion trade-offs.IEEE Transactions on Automatic Control, 62(4):1896–1910,
1910
-
[10]
Xuan Tang, Jichu Li, and Difan Zou. A convergence analysis of adaptive optimizers under floating- point quantization.arXiv preprint arXiv:2510.21314,
-
[11]
arXiv:2502.20586. Alexandre B. Tsybakov.Introduction to Nonparametric Estimation. Springer,
-
[12]
The appendix is organized as follows
arXiv:1405.0782. The appendix is organized as follows. Appendix A contains the deferred proofs of the achievability results (Lemma 3 and Theorem 4). Appendix B reports the numerical sanity checks. Appendix C relates the product-form bound to the distributed-estimation literature, and Appendix D gives a self-contained Gaussian Fisher-trace bound together w...
-
[13]
Bits.The message is exactlys q≤Bbits (sindices into a grid of 2 q points); no scale is sent
ThusE∥ˆg∥2 ≤ω B∥g∥2 +G 2/s. Bits.The message is exactlys q≤Bbits (sindices into a grid of 2 q points); no scale is sent. IfB≥qdthens=d,ω B = 1; otherwises=⌊B/q⌋ ≥B/(2q), soω B =d/s≤2qd/B. This gives the statedω B. Proof of Theorem 4.Unbiasedness is the tower property:E[ˆg t |x t] =E[E[C B(gt)|g t]|x t] =E[g t | xt] =∇f(x t) (the compressor applies since∥g...
2018
-
[14]
0 500 1000 1500 2000 2500 3000 3500 4000 round t 10 1 100 101 gap f(xt) f (6a) two views coincide exactly optimization view estimation view 4 2 0 2 4 Yt, 1 = xt, 1 gt, 1 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40density (6b) law of Yt is query-independent query = 0: Y =0.051 query random: Y =0.055 query drifting: Y =0.057 ( 1,
2000
-
[15]
We record here how this relates to the distributed-estimation literature and why we use the Fisher route rather than a direct mutual-information/SDPI argument
is obtained through the Fisher-information route of Barnes and ¨Ozg¨ ur (2021). We record here how this relates to the distributed-estimation literature and why we use the Fisher route rather than a direct mutual-information/SDPI argument. •Braverman et al. (2016) prove adistributed data-processing inequalityfor decentralized estima- tion under the Gaussi...
2021
-
[16]
for the backward channelP V|Y givesI(V;M| U)≤η KL(PY , PV|Y )I(Y;M|U)≤η KL(PY , PV|Y )B, usingI(Y;M|U)≤H(M|U)≤Band U⊥(V, Y). 2.(χ 2 contraction = maximal correlation.)η χ2(PY , PV|Y ) =ρ 2 m(V, Y), and maximal correla- tion tensorizes over the (identical, independent) coordinates,ρ 2 m(V, Y) = max j ρ2 m(Vj, Yj) = ρ2 m(V1, Y1). 3.(Scalar bound.)ρ 2 m(V1, ...
2017
-
[17]
because the SDPI coefficient is a channel property
We knowη KL ≥ρ 2 m = Θ(SNR) (item 2–3), so if true the rate is the right one; boundingη KL from abovebyO(SNR) is an instance of the same Gaussian-channel strong-data-processing estimate that the distributed-DPI literature establishes by more involved means. We flag this honestly: the maximal-correlation argument settles theχ 2 contraction but not the mutu...
2016
-
[18]
is self-contained, whereas the converse and achievability invokeremote(indirect) sequential rate–distortion and entropy-coded quantization, which depart 25 from the exact fixed-lengthB-bit oracle of Definition 1 in ways we flag explicitly. The information- theoretic machinery is imported: directed information (Massey, 1990), the data-rate theorem (Nair an...
1990
-
[19]
Lemma 9(Rate, observation, time, and distortion bounds).LetN t :=N(θ t | F t−1)andN + t := N(θ t | F t)
E.2 Lower bound I: a self-contained entropy-power bound For a random vectorZ∈R d and aσ-algebraG, write the conditional entropy power (bits)N(Z| G) := 1 2πe22h(Z|G)/d ; for a GaussianN(µ,Σ) one hasN= (det Σ) 1/d. Lemma 9(Rate, observation, time, and distortion bounds).LetN t :=N(θ t | F t−1)andN + t := N(θ t | F t). For any encoder, with no distributional...
2006
-
[20]
themaxof ac d-inflated rate-limited term and the Kalman floor
In this expected-ratemodel and in the high-rate regime, the Kalman filter composed with the quantizer of Lemma 11 attains a steady-state distortion within the space-filling factorc d of the remote-NRDF lower bound of Proposition 3, i.e. themaxof ac d-inflated rate-limited term and the Kalman floor. The scheme requires only that the innovation have finite ...
1998
-
[21]
bound ong t
This is the innovation-quantization achievability of Kostina and Hassibi (2019), valid whenever the noise has finite differential entropy and hence requiring no a.s. bound ong t. The matching is in the average-rate sense; converting it to an exact fixed-length{0,1} B code per round is the open fixed-length question (L3 ′). Remark 9.Existing single-machine...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.