EMA: Approximate Nearest Neighbor Search with General Attribute Filtering and Dynamic Updates
Pith reviewed 2026-06-28 17:56 UTC · model grok-4.3
The pith
EMA attaches compact markers to graph edges to enable fast general attribute filtering in approximate nearest neighbor search with dynamic updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
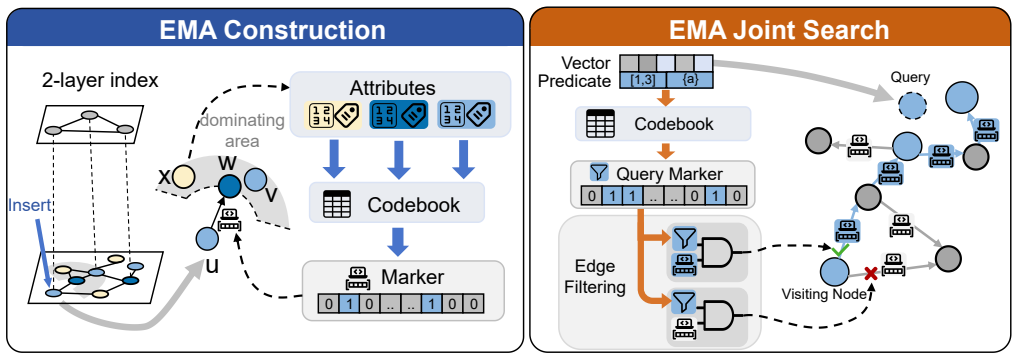
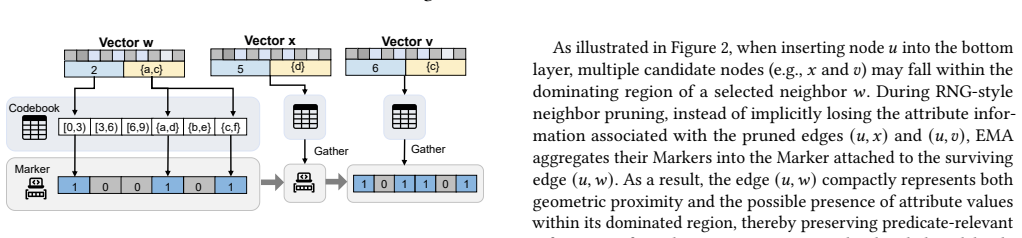
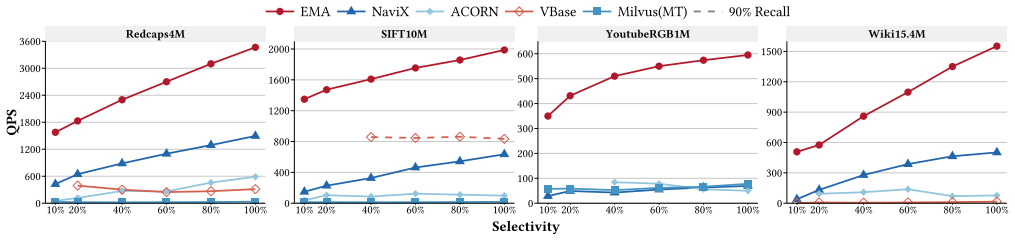
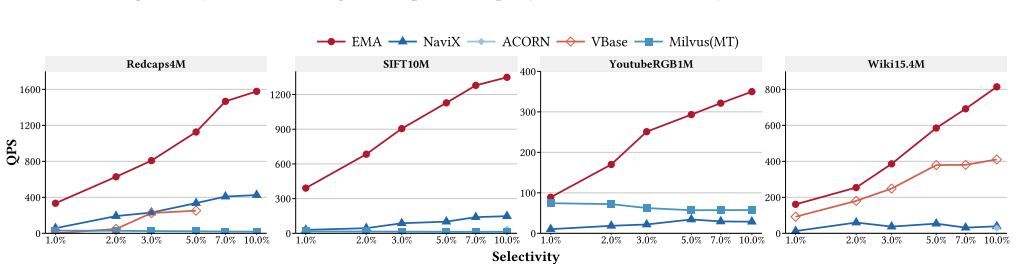
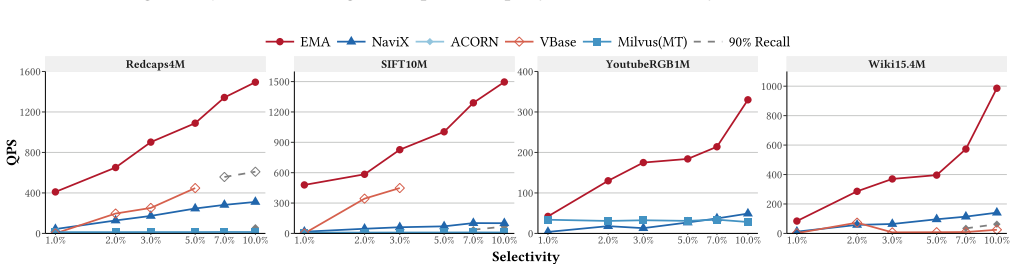
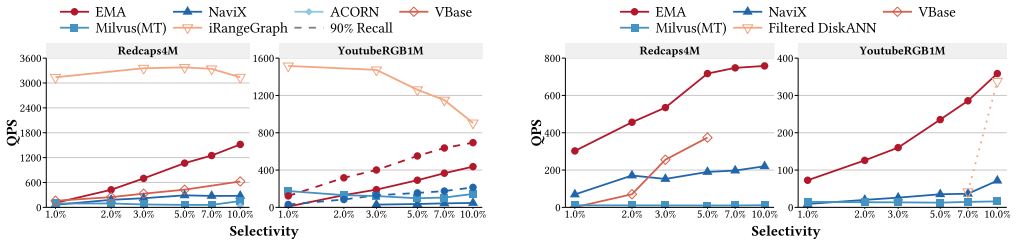
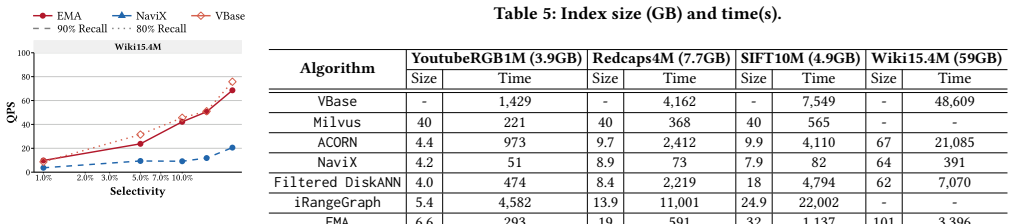
EMA achieves 1.68x--12.25x speedup over state-of-the-art general filtering ANN methods across diverse workloads by introducing Markers as compact summaries attached to graph edges that provide conservative predicate- and geometric-aware guidance with zero false negatives at the Marker level, then performing Marker-augmented joint search with a bounded edge recovery mechanism that enables efficient filtering while preserving graph navigability and supporting dynamic updates.
What carries the argument
Markers attached to graph edges, compact summaries that supply conservative predicate- and geometric-aware guidance with zero false negatives at the marker level.
If this is right
- EMA supports multi-predicate queries over mixed numerical and categorical attributes.
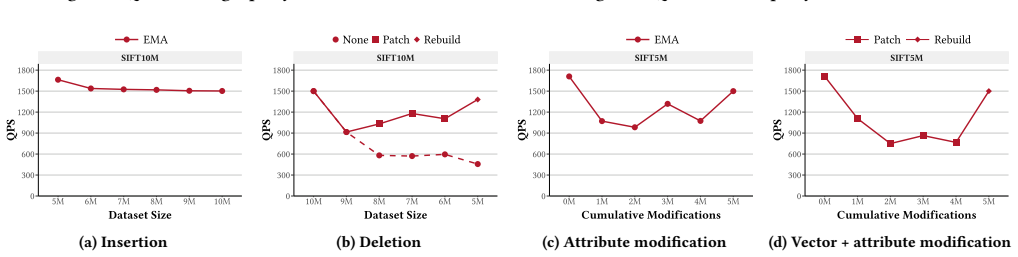
- It enables efficient dynamic updates to the index.
- It delivers 1.68x--12.25x speedup over prior general filtering ANN methods on diverse workloads.
- Marker-augmented joint search with bounded recovery preserves graph navigability during filtering.
Where Pith is reading between the lines
- Vector databases could support richer real-time filtering for recommendation and retrieval-augmented generation without separate index structures.
- The marker technique might apply to other proximity-graph indexes that currently lack general predicate support.
- Lower construction and memory costs could make filtered ANN viable at larger scales than current predicate-agnostic methods allow.
Load-bearing premise
Markers attached to graph edges provide conservative predicate- and geometric-aware guidance with zero false negatives at the Marker level, enabling efficient filtering while preserving graph navigability.
What would settle it
An experiment on a workload where marker-guided search returns a different result set from exhaustive filtered search, or where measured speedups fall below the claimed range across the tested workloads.
Figures
read the original abstract
Filtering Approximate Nearest Neighbor (FANN) search is a critical and emerging task for strengthening the query capability of vector databases, supporting applications such as recommendation systems, retrieval-augmented generation (RAG), and agent memory. However, most existing methods are limited to range or label filtering, often incurring unacceptable index construction time and memory overhead. Predicate-agnostic approaches further struggle to handle a wide range of predicate selectivities effectively. In this paper, we propose EMA, a filtering ANN algorithm that supports multi-predicate queries over mixed numerical and categorical attributes, and efficient dynamic updates. EMA introduces Markers as compact summaries attached to graph edges, providing conservative predicate- and geometric-aware guidance with zero false negatives at the Marker level. During query processing, EMA performs Marker-augmented joint search with a bounded edge recovery mechanism, enabling efficient filtering while preserving graph navigability. Extensive experiments demonstrate that EMA achieves 1.68x--12.25x speedup over state-of-the-art general filtering ANN methods across diverse workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EMA, a filtering ANN algorithm supporting multi-predicate queries over mixed numerical and categorical attributes together with dynamic updates. It introduces Markers as compact summaries attached to graph edges that provide conservative predicate- and geometric-aware guidance with zero false negatives at the Marker level, combined with Marker-augmented joint search and bounded edge recovery to preserve navigability. The central claim is that EMA delivers 1.68x--12.25x speedup over state-of-the-art general filtering ANN methods across diverse workloads.
Significance. If the Marker construction and bounded-recovery mechanism can be shown to deliver the claimed zero-false-negative property while maintaining graph navigability, and if the reported speedups are reproducible, the work would meaningfully advance predicate-aware ANN search in vector databases for RAG, recommendation, and agent-memory workloads.
major comments (1)
- Abstract: the claim of 1.68x--12.25x speedup is presented without any description of baselines, workloads, error bars, or exclusion criteria, preventing assessment of whether the data supports the central performance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comment. We address it point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: the claim of 1.68x--12.25x speedup is presented without any description of baselines, workloads, error bars, or exclusion criteria, preventing assessment of whether the data supports the central performance claim.
Authors: We agree that the abstract, as a concise summary, omits the specific experimental details needed for immediate assessment. The baselines are the state-of-the-art general filtering ANN methods (detailed in Section 2 and compared in Section 5), the workloads cover diverse predicate selectivities and attribute mixes on standard vector datasets, and results include error bars from repeated runs with no exclusion of outliers. To improve clarity and allow readers to evaluate the claim without reading the full paper, we will revise the abstract to briefly reference the evaluation setup (e.g., 'over state-of-the-art baselines on diverse workloads with reported error bars'). revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, derivations, fitted parameters, or mathematical claims that could reduce to inputs by construction. The work describes an algorithmic construction (Markers attached to graph edges for conservative guidance) and reports empirical speedups, with no self-definitional steps, fitted-input predictions, or load-bearing self-citations visible in the text. The central claims rest on experimental validation rather than any closed-form reduction, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Markers
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Martin Aumüller, Erik Bernhardsson, and Alexander Faithfull. 2020. ANN- Benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. Information Systems87 (2020), 101374
2020
-
[2]
Jon Louis Bentley. 1975. Multidimensional binary search trees used for associative searching.Commun. ACM18, 9 (1975), 509–517
1975
-
[3]
Angela Bonifati, Wim Martens, and Thomas Timm. 2017. An analytical study of large SPARQL query logs.arXiv preprint arXiv:1708.00363(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Lawrence Cayton. 2008. Fast nearest neighbor retrieval for bregman divergences. InProceedings of the 25th international conference on Machine learning. 112–119
2008
- [5]
-
[6]
Wei Dong. 2011. Kgraph: A library for approximate nearest neighbor search. Retrieved July12 (2011), 2020
2011
-
[7]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The faiss library.arXiv preprint arXiv:2401.08281(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [9]
-
[10]
Mocheng Li et al. 2026. EMA: Appendix. https://github.com/lmccccc/EMA/blob/ main/EMA_appendix.pdf. Supplementary material
2026
-
[11]
Xiyang Feng, Guodong Jin, Ziyi Chen, Chang Liu, and Semih Salihoğlu. 2023. Kùzu graph database management system. InThe Conference on Innovative Data Systems Research, Vol. 7. 25–35
2023
-
[12]
Jerome H Friedman, Jon Louis Bentley, and Raphael Ari Finkel. 1977. An algo- rithm for finding best matches in logarithmic expected time.ACM Transactions on Mathematical Software (TOMS)3, 3 (1977), 209–226
1977
-
[13]
Junhao Gan, Jianlin Feng, Qiong Fang, and Wilfred Ng. 2012. Locality-sensitive hashing scheme based on dynamic collision counting. InProceedings of the 2012 ACM SIGMOD international conference on management of data. 541–552
2012
-
[14]
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2013. Optimized product quantization.IEEE transactions on pattern analysis and machine intelligence36, 4 (2013), 744–755
2013
-
[15]
Siddharth Gollapudi, Neel Karia, Varun Sivashankar, Ravishankar Krishnaswamy, Nikit Begwani, Swapnil Raz, Yiyong Lin, Yin Zhang, Neelam Mahapatro, Premku- mar Srinivasan, et al. 2023. Filtered-diskann: Graph algorithms for approximate nearest neighbor search with filters. InProceedings of the ACM Web Conference
2023
-
[16]
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating large-scale inference with anisotropic vector quantization. InInternational Conference on Machine Learning. PMLR, 3887–3896
2020
-
[17]
Antonin Guttman. 1984. R-trees: A dynamic index structure for spatial searching. InProceedings of the 1984 ACM SIGMOD international conference on Management of data. 47–57
1984
-
[18]
Ben Harwood and Tom Drummond. 2016. Fanng: Fast approximate nearest neighbour graphs. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 5713–5722
2016
-
[19]
Qiang Huang, Jianlin Feng, Yikai Zhang, Qiong Fang, and Wilfred Ng. 2015. Query-aware locality-sensitive hashing for approximate nearest neighbor search. Proceedings of the VLDB Endowment9, 1 (2015), 1–12
2015
-
[20]
Piotr Indyk and Rajeev Motwani. 1998. Approximate nearest neighbors: towards removing the curse of dimensionality. InProceedings of the thirtieth annual ACM symposium on Theory of computing. 604–613
1998
-
[21]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. Diskann: Fast accurate billion-point nearest neighbor search on a single node.Advances in neural information pro- cessing Systems32 (2019)
2019
-
[22]
Hervé Jégou, Romain Tavenard, Matthijs Douze, and Laurent Amsaleg. 2011. Searching in one billion vectors: re-rank with source coding. In2011 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 861–864
2011
-
[23]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data7, 3 (2019), 535–547
2019
-
[24]
Andrew Kane. n.d.. PGVector. https://github.com/pgvector/pgvector. 13
-
[25]
1968.Regionalization, Theory and alternative algorithms
Philip M Lankford. 1968.Regionalization, Theory and alternative algorithms. Ph.D. Dissertation. The University of Chicago
1968
- [26]
-
[27]
Yury Malkov, Alexander Ponomarenko, Andrey Logvinov, and Vladimir Krylov
-
[28]
Approximate nearest neighbor algorithm based on navigable small world graphs.Information Systems45 (2014), 61–68
2014
-
[29]
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs.IEEE transactions on pattern analysis and machine intelligence42, 4 (2018), 824–836
2018
-
[30]
Yusuke Matsui, Ryota Hinami, and Shin’ichi Satoh. 2018. Reconfigurable Inverted Index. InProceedings of the 26th ACM international conference on Multimedia. 1715–1723
2018
-
[31]
Yitong Meng, Xinyan Dai, Xiao Yan, James Cheng, Weiwen Liu, Jun Guo, Benben Liao, and Guangyong Chen. 2020. Pmd: An optimal transportation-based user distance for recommender systems. InAdvances in Information Retrieval: 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, April 14–17, 2020, Proceedings, Part II 42. Springer, 272–280
2020
-
[32]
Thomas Neumann and Guido Moerkotte. 2011. Characteristic sets: Accurate cardinality estimation for RDF queries with multiple joins. In2011 IEEE 27th International Conference on Data Engineering. IEEE, 984–994
2011
-
[33]
Shumpei Okura, Yukihiro Tagami, Shingo Ono, and Akira Tajima. 2017. Embedding-based news recommendation for millions of users. InProceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 1933–1942
2017
-
[34]
Liana Patel, Siddharth Jha, Carlos Guestrin, and Matei Zaharia. 2024. Lotus: Enabling semantic queries with llms over tables of unstructured and structured data.arXiv e-prints(2024), arXiv–2407
2024
-
[35]
Liana Patel, Peter Kraft, Carlos Guestrin, and Matei Zaharia. 2024. Acorn: Per- formant and predicate-agnostic search over vector embeddings and structured data.Proceedings of the ACM on Management of Data2, 3 (2024), 1–27
2024
-
[36]
Arkadiusz Paterek. 2007. Improving regularized singular value decomposition for collaborative filtering. InProceedings of KDD cup and workshop, Vol. 2007. 5–8
2007
-
[37]
Zhencan Peng, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. [n.d.]. Dynamic Range-Filtering Approximate Nearest Neighbor Search. ([n. d.])
-
[38]
Zhencan Peng, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. 2025. Dynamic Range-Filtering Approximate Nearest Neighbor Search.Proceedings of the VLDB Endowment18, 10 (2025), 3256–3268
2025
-
[39]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[40]
In International conference on machine learning
Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763
- [41]
- [42]
-
[43]
Godfried T Toussaint. 1980. The relative neighbourhood graph of a finite planar set.Pattern recognition12, 4 (1980), 261–268
1980
-
[44]
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi- angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. 2021. Milvus: A purpose-built vector data management system. InProceedings of the 2021 international conference on management of data. 2614–2627
2021
-
[45]
Mengzhao Wang, Lingwei Lv, Xiaoliang Xu, Yuxiang Wang, Qiang Yue, and Jiongkang Ni. 2024. An efficient and robust framework for approximate near- est neighbor search with attribute constraint.Advances in Neural Information Processing Systems36 (2024)
2024
- [46]
-
[47]
Shu Wang, Yixiang Fang, Yingli Zhou, Xilin Liu, and Yuchi Ma. 2025. ArchRAG: Attributed Community-based Hierarchical Retrieval-Augmented Generation. arXiv preprint arXiv:2502.09891(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Weaviate. 2024. Weaviate. https://weaviate.io/
2024
-
[49]
Chuangxian Wei, Bin Wu, Sheng Wang, Renjie Lou, Chaoqun Zhan, Feifei Li, and Yuanzhe Cai. 2020. AnalyticDB-V: a hybrid analytical engine towards query fusion for structured and unstructured data.Proceedings of the VLDB Endowment 13, 12 (2020), 3152–3165
2020
-
[50]
Yuexuan Xu, Jianyang Gao, Yutong Gou, Cheng Long, and Christian S Jensen
-
[51]
irangegraph: Improvising range-dedicated graphs for range-filtering near- est neighbor search.Proceedings of the ACM on Management of Data2, 6 (2024), 1–26
2024
- [52]
-
[53]
Wen Yang, Tao Li, Gai Fang, and Hong Wei. 2020. Pase: Postgresql ultra-high- dimensional approximate nearest neighbor search extension. InProceedings of the 2020 ACM SIGMOD international conference on management of data. 2241–2253
2020
-
[54]
Peter Yianilos. 1993. Data structures and algorithms for nearest neighbor search in general metric spaces. (1993)
1993
-
[55]
Qianxi Zhang, Shuotao Xu, Qi Chen, Guoxin Sui, Jiadong Xie, Zhizhen Cai, Yaoqi Chen, Yinxuan He, Yuqing Yang, Fan Yang, et al . 2023. {VBASE}: Unifying online vector similarity search and relational queries via relaxed monotonicity. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). 377–395
2023
- [56]
-
[57]
Yingli Zhou, Yaodong Su, Youran Sun, Shu Wang, Taotao Wang, Runyuan He, Yongwei Zhang, Sicong Liang, Xilin Liu, Yuchi Ma, et al. 2025. In-depth Analysis of Graph-based RAG in a Unified Framework.arXiv preprint arXiv:2503.04338 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Chaoji Zuo, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. 2024. SeRF: seg- ment graph for range-filtering approximate nearest neighbor search.Proceedings of the ACM on Management of Data2, 1 (2024), 1–26. 14
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.