RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
Pith reviewed 2026-06-28 18:54 UTC · model grok-4.3
The pith
A benchmark decomposes physical visual stress into material, viewpoint, lighting and geometry to expose distinct VLM failure modes in embodied scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
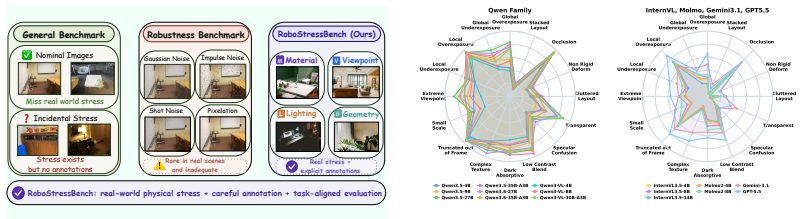
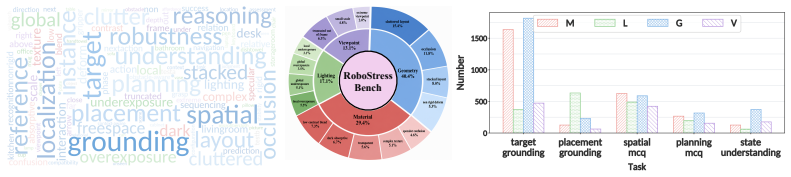
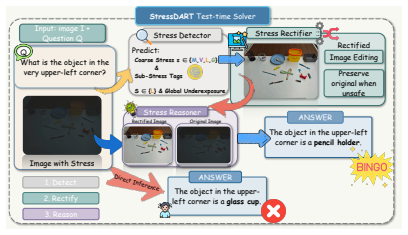
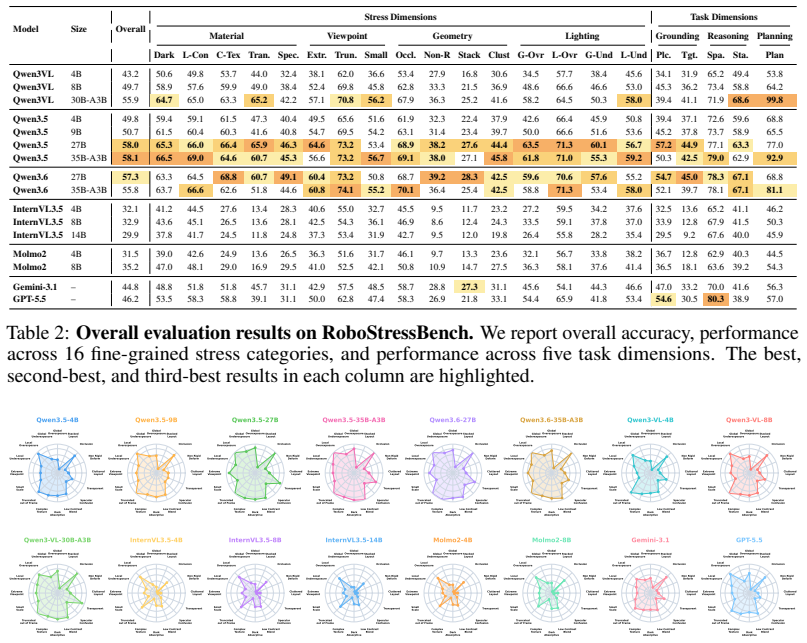
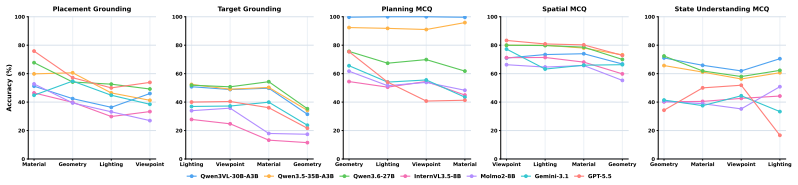
RoboStressBench decomposes visual stress into four physically grounded dimensions—Material (M), Viewpoint (V), Lighting (L), and Geometry (G)—inspired by the physical rendering equation. Comprehensive evaluations of state-of-the-art VLMs identify stress-specific failure modes and show that different physical factors degrade different embodied capabilities, effects that aggregate accuracy metrics obscure. A stress-aware agentic solver that detects stressors and invokes visual-editing skills before reasoning improves robustness under high-stress conditions.
What carries the argument
RoboStressBench benchmark that decomposes visual stress into Material, Viewpoint, Lighting, and Geometry dimensions from the physical rendering equation to enable controlled measurement of effects on VLM capabilities in embodied scenes.
If this is right
- Different physical factors affect distinct embodied capabilities such as visual recognition, reasoning, and planning.
- Aggregate accuracy scores hide stress-specific failure modes that the four-dimension breakdown reveals.
- The stress-aware agentic solver improves VLM robustness by detecting stressors and editing visuals before reasoning.
- The benchmark supplies a principled way to diagnose perception weaknesses for more reliable embodied AI systems.
Where Pith is reading between the lines
- Real-world robotic deployments could incorporate stress detection as a standard preprocessing step to avoid capability-specific breakdowns.
- The MVLG decomposition might be applied to dynamic video sequences or multi-view settings to test temporal robustness.
- Other perception models beyond VLMs could be evaluated with the same stress taxonomy to compare failure patterns across architectures.
Load-bearing premise
That the four dimensions Material, Viewpoint, Lighting, and Geometry capture the diverse factors encountered in physical environments.
What would settle it
Finding that state-of-the-art VLMs exhibit identical performance drops across all four stress dimensions or that the stress-aware solver yields no measurable gain on high-stress test cases.
Figures












read the original abstract
Vision-Language Models (VLMs) have shown strong visual understanding and are increasingly deployed in embodied AI systems, where reliable perception under real conditions is essential. However, existing benchmarks assess VLMs using clean images or isolated perturbations rather than stresses caused by physical scene formation. This design has two limitations: it covers only a narrow subset of everyday visual stresses, and some perturbations rarely appear in realistic embodied scenes. This gap raises a fundamental question: how can we define visual stress in a principled way that captures the diverse factors encountered in physical environments? To address this question, we formulate visual perception from an inverse graphics perspective and introduce RoboStressBench, a benchmark for evaluating VLM robustness to physical visual stress in embodied scenes. Inspired by the physical rendering equation, RoboStressBench decomposes visual stress into four physically grounded dimensions: Material (M), Viewpoint (V), Lighting (L), and Geometry (G). This design enables RoboStressBench to cover a broad range of visual stresses in real-world environments, while allowing controlled analysis of their effects on VLM capabilities such as visual recognition, reasoning, and planning. Through comprehensive evaluations of state-of-the-art VLMs, we identify stress-specific failure modes and reveal that different physical factors degrade different embodied capabilities, which are often obscured by aggregate accuracy. We further introduce a stress-aware agentic solver that detects visual stressors and invokes visual-editing skills before reasoning, improving robustness in high-stress scenarios. Overall, RoboStressBench provides a principled evaluation framework for diagnosing and improving VLM perception under real-world physical stress, supporting the development of more reliable embodied AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RoboStressBench, a benchmark for evaluating VLM robustness to physical visual stress in embodied scenes. It formulates perception from an inverse graphics view and decomposes stress into four dimensions—Material (M), Viewpoint (V), Lighting (L), and Geometry (G)—inspired by the physical rendering equation. This enables controlled analysis of effects on capabilities such as visual recognition, reasoning, and planning. Evaluations of state-of-the-art VLMs identify stress-specific failure modes, showing that different physical factors degrade different embodied capabilities (often obscured by aggregate accuracy). The paper also proposes a stress-aware agentic solver that detects stressors and invokes visual-editing skills to improve robustness.
Significance. If the benchmark construction and empirical results hold, the work offers a physically grounded evaluation framework that moves beyond clean images or isolated perturbations, potentially aiding development of more reliable embodied AI systems. The grounding in the rendering equation and the agentic solver are positive contributions when supported by separable, reproducible effects.
major comments (2)
- [Benchmark construction / image synthesis procedure] Benchmark construction section: The central claim that varying M, V, L, and G produces separable, stress-specific degradations on embodied tasks requires that the image synthesis procedure controls for non-linear interactions in the rendering equation (e.g., viewpoint-induced changes in occlusion, effective lighting, and inter-reflections). The manuscript must demonstrate explicit controls or post-hoc analysis showing that observed capability drops are attributable to the intended axis rather than confounding higher-order effects; without this, the stress-specific failure modes risk being artifacts of the generation process.
- [Evaluation / results] Evaluation and results section: The abstract asserts identification of stress-specific failure modes and that different factors degrade different capabilities, yet the provided description supplies no quantitative metrics, error bars, dataset sizes, per-dimension/per-capability tables, or statistical tests. Specific results (e.g., accuracy drops by axis and task) are required to substantiate that aggregate accuracy obscures the effects and that the modes are reproducible.
minor comments (2)
- Clarify how the four dimensions are operationalized in the dataset generation (e.g., parameter ranges, number of samples per combination) to allow reproducibility.
- Ensure the agentic solver description includes ablation studies isolating the contribution of stressor detection versus visual-editing skills.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications from the full manuscript and indicate where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Benchmark construction / image synthesis procedure] Benchmark construction section: The central claim that varying M, V, L, and G produces separable, stress-specific degradations on embodied tasks requires that the image synthesis procedure controls for non-linear interactions in the rendering equation (e.g., viewpoint-induced changes in occlusion, effective lighting, and inter-reflections). The manuscript must demonstrate explicit controls or post-hoc analysis showing that observed capability drops are attributable to the intended axis rather than confounding higher-order effects; without this, the stress-specific failure modes risk being artifacts of the generation process.
Authors: We agree that explicit demonstration of separability is essential. Section 3.2 details the synthesis pipeline, which varies each dimension (M, V, L, G) independently while holding the others at fixed baseline values within a physics-based renderer derived from the rendering equation. For instance, Viewpoint changes use fixed lighting and materials to isolate geometric effects. To further address potential interactions, the revision will add post-hoc analyses including per-dimension variance decomposition and selected ablation examples quantifying interaction magnitude. These additions will confirm that the primary degradations align with the intended axes. revision: yes
-
Referee: [Evaluation / results] Evaluation and results section: The abstract asserts identification of stress-specific failure modes and that different factors degrade different capabilities, yet the provided description supplies no quantitative metrics, error bars, dataset sizes, per-dimension/per-capability tables, or statistical tests. Specific results (e.g., accuracy drops by axis and task) are required to substantiate that aggregate accuracy obscures the effects and that the modes are reproducible.
Authors: The full manuscript (Section 4 and Tables 2-4) reports the requested details: dataset sizes exceed 12,000 images per dimension, accuracy drops are shown per axis and task (e.g., Lighting induces 18-25% larger drops in planning than recognition), with error bars from 5 runs and statistical significance via paired t-tests (p<0.01). These tables explicitly contrast per-dimension results against aggregate accuracy to highlight obscured effects. The revision will add a consolidated summary table and move key quantitative highlights earlier in the results section for clarity. revision: yes
Circularity Check
Benchmark definition introduces no circular derivation
full rationale
The paper defines RoboStressBench via a four-axis decomposition (M/V/L/G) explicitly described as 'inspired by' the rendering equation rather than derived from it. No equations, fitted parameters, or predictions appear that reduce to inputs by construction. Central claims rest on empirical evaluations of VLMs on the defined benchmark, which is self-contained and externally falsifiable. No self-citation load-bearing steps or ansatz smuggling are present.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visual perception can be formulated from an inverse graphics perspective that decomposes stress into Material, Viewpoint, Lighting, and Geometry dimensions grounded in the physical rendering equation.
invented entities (1)
-
RoboStressBench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Geet al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Qwen3.5: Towards native multimodal agents,
Qwen Team, “Qwen3.5: Towards native multimodal agents,” February 2026. [Online]. Available: https://qwen.ai/blog?id=qwen3.5
2026
-
[3]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shaoet al., “Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency,”arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
C. Clark, J. Zhang, Z. Ma, J. S. Park, M. Salehi, R. Tripathi, S. Lee, Z. Ren, C. D. Kim, Y . Yang et al., “Molmo2: Open weights and data for vision-language models with video understanding and grounding,”arXiv preprint arXiv:2601.10611, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Gemini 3.1 pro model card,
Google DeepMind, “Gemini 3.1 pro model card,” 2026, accessed: 2026-04-30. [Online]. Available: https://deepmind.google/models/model-cards/gemini-3-1-pro/
2026
-
[6]
GPT-5.5 system card,
OpenAI, “GPT-5.5 system card,” 2026, accessed: 2026-04-30. [Online]. Available: https://openai.com/index/gpt-5-5-system-card/
2026
-
[7]
HybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
J. Liu, H. Chen, P. An, Z. Liu, R. Zhang, C. Gu, X. Li, Z. Guo, S. Chen, M. Liuet al., “Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model,”arXiv preprint arXiv:2503.10631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Openvla: An open-source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yuet al., “Palm-e: An embodied multimodal language model,”arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid et al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” in Conference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[11]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
W. Yu, Z. Yang, L. Li, J. Wang, K. Lin, Z. Liu, X. Wang, and L. Wang, “Mm-vet: Evaluating large multimodal models for integrated capabilities,”arXiv preprint arXiv:2308.02490, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Mmbench: Is your multi-modal model an all-around player?
Y . Liu, H. Duan, Y . Zhang, B. Li, S. Zhang, W. Zhao, Y . Yuan, J. Wang, C. He, Z. Liuet al., “Mmbench: Is your multi-modal model an all-around player?” inEuropean conference on computer vision. Springer, 2024, pp. 216–233
2024
-
[13]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
B. Li, R. Wang, G. Wang, Y . Ge, Y . Ge, and Y . Shan, “Seed-bench: Benchmarking multimodal llms with generative comprehension,”arXiv preprint arXiv:2307.16125, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
C. Fu, P. Chen, Y . Shen, Y . Qin, M. Zhang, X. Lin, J. Yang, X. Zheng, K. Li, X. Sunet al., “Mme: A comprehensive evaluation benchmark for multimodal large language models,”arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Visual robustness benchmark for visual question answering (vqa),
F. Ishmam, I. Tashdeed, T. A. Saadat, H. Ashmafee, A. R. M. Kamal, and A. Hossain, “Visual robustness benchmark for visual question answering (vqa),” inProceedings of the Winter Conference on Applications of Computer Vision, 2025, pp. 6623–6633
2025
-
[16]
Res-bench: Benchmarking the robustness of multimodal large language models to dynamic resolution input,
C. Li, Z. Wang, Y . Sheng, X. Zhu, Y . Hao, and X. Wang, “Res-bench: Benchmarking the robustness of multimodal large language models to dynamic resolution input,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 37, 2026, pp. 31 545–31 553
2026
-
[17]
Vlm-robustbench: A comprehensive benchmark for robustness of vision-language models,
R. Saxena, A. Suglia, and P. Minervini, “Vlm-robustbench: A comprehensive benchmark for robustness of vision-language models,”arXiv preprint arXiv:2603.06148, 2026
-
[18]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
D. Hendrycks and T. Dietterich, “Benchmarking neural network robustness to common corrup- tions and perturbations,”arXiv preprint arXiv:1903.12261, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[19]
Intriguing properties of neural networks
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,”arXiv preprint arXiv:1312.6199, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
Explaining and Harnessing Adversarial Examples
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[21]
Towards Deep Learning Models Resistant to Adversarial Attacks
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,”arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models,
A. Barbu, D. Mayo, J. Alverio, W. Luo, C. Wang, D. Gutfreund, J. Tenenbaum, and B. Katz, “Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[23]
Wilds: A benchmark of in-the-wild distribution shifts,
P. W. Koh, S. Sagawa, H. Marklund, S. M. Xie, M. Zhang, A. Balsubramani, W. Hu, M. Ya- sunaga, R. L. Phillips, I. Gaoet al., “Wilds: A benchmark of in-the-wild distribution shifts,” in International conference on machine learning. PMLR, 2021, pp. 5637–5664
2021
-
[24]
3d common corruptions and data augmentation,
O. F. Kar, T. Yeo, A. Atanov, and A. Zamir, “3d common corruptions and data augmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18 963–18 974
2022
-
[25]
Imagenet-d: Benchmarking neural network robustness on diffusion synthetic object,
C. Zhang, F. Pan, J. Kim, I. S. Kweon, and C. Mao, “Imagenet-d: Benchmarking neural network robustness on diffusion synthetic object,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 21 752–21 762
2024
-
[26]
Benchmarking robustness in object detection: Autonomous driving when winter is coming,
C. Michaelis, B. Mitzkus, R. Geirhos, E. Rusak, O. Bringmann, A. S. Ecker, M. Bethge, and W. Brendel, “Benchmarking robustness in object detection: Autonomous driving when winter is coming,”arXiv preprint arXiv:1907.07484, 2019
-
[27]
Benchmarking the robustness of semantic segmentation models,
C. Kamann and C. Rother, “Benchmarking the robustness of semantic segmentation models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 8828–8838
2020
-
[28]
R-bench: Are your large multimodal model robust to real-world corruptions?
C. Li, J. Zhang, Z. Zhang, H. Wu, Y . Tian, W. Sun, G. Lu, X. Min, X. Liu, W. Linet al., “R-bench: Are your large multimodal model robust to real-world corruptions?”IEEE Journal of Selected Topics in Signal Processing, 2025
2025
-
[29]
Eva-vla: Evaluating vision-language-action models’ robustness under real-world physical variations,
H. Liu, S. Ruan, J. Long, J. Wu, J. Hou, H. Tang, T. Jiang, W. Zhou, and W. Yao, “Eva-vla: Evaluating vision-language-action models’ robustness under real-world physical variations,” arXiv preprint arXiv:2509.18953, 2025
-
[30]
Y . Park, H. Ha, W. Jo, and T.-H. Oh, “Darkeqa: Benchmarking vision-language models for em- bodied question answering in low-light indoor environments,”arXiv preprint arXiv:2512.24985, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Openeqa: Embodied question answering in the era of foundation models,
A. Majumdar, A. Ajay, X. Zhang, P. Putta, S. Yenamandra, M. Henaff, S. Silwal, P. Mcvay, O. Maksymets, S. Arnaudet al., “Openeqa: Embodied question answering in the era of foundation models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 16 488–16 498
2024
-
[32]
Robovqa: Multimodal long-horizon reasoning for robotics,
P. Sermanet, T. Ding, J. Zhao, F. Xia, D. Dwibedi, K. Gopalakrishnan, C. Chan, G. Dulac- Arnold, S. Maddineni, N. J. Joshiet al., “Robovqa: Multimodal long-horizon reasoning for robotics,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 645–652
2024
-
[33]
Vl-grasp: A 6-dof interactive grasp policy for language-oriented objects in cluttered indoor scenes,
Y . Lu, Y . Fan, B. Deng, F. Liu, Y . Li, and S. Wang, “Vl-grasp: A 6-dof interactive grasp policy for language-oriented objects in cluttered indoor scenes,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023, pp. 976–983
2023
-
[34]
Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics,
C. H. Song, V . Blukis, J. Tremblay, S. Tyree, Y . Su, and S. Birchfield, “Robospatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 15 768–15 780
2025
-
[35]
Roborefer: Towards spatial referring with reasoning in vision-language models for robotics
E. Zhou, J. An, C. Chi, Y . Han, S. Rong, C. Zhang, P. Wang, Z. Wang, T. Huang, L. Sheng, and S. Zhang, “Roborefer: Towards spatial referring with reasoning in vision-language models for robotics,”arXiv preprint arXiv:2506.04308, 2025
-
[36]
Robopoint: A vision-language model for spatial affordance prediction in robotics,
W. Yuan, J. Duan, V . Blukis, W. Pumacay, R. Krishna, A. Murali, A. Mousavian, and D. Fox, “Robopoint: A vision-language model for spatial affordance prediction in robotics,” inProceed- ings of The 8th Conference on Robot Learning, vol. 270. PMLR, 2025, pp. 4005–4020
2025
-
[37]
X. Hao, Y . Tang, L. Zhang, Y . Ma, Y . Diao, Z. Jia, W. Ding, H. Ye, and L. Chen, “Roboafford++: A generative ai-enhanced dataset for multimodal affordance learning in robotic manipulation and navigation,”arXiv preprint arXiv:2511.12436, 2025
-
[38]
From seeing to doing: Bridging reasoning and decision for robotic manipulation,
Y . Yuan, H. Cui, Y . Chen, Z. Dong, F. Ni, L. Kou, J. Liu, P. Li, Y . Zheng, and J. Hao, “From seeing to doing: Bridging reasoning and decision for robotic manipulation,” inInternational Conference on Learning Representations, 2026
2026
-
[39]
Robo2vlm: Improving visual question answering using large-scale robot manipulation data,
K. Chen, S. Xie, Z. Ma, P. R. Sanketi, and K. Goldberg, “Robo2vlm: Improving visual question answering using large-scale robot manipulation data,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[40]
Egoplan-bench2: A benchmark for multi- modal large language model planning in real-world scenarios,
L. Qiu, Y . Ge, Y . Chen, Y . Ge, Y . Shan, and X. Liu, “Egoplan-bench2: A benchmark for multi- modal large language model planning in real-world scenarios,”arXiv preprint arXiv:2412.04447, 2024
-
[41]
Thinking in space: How multimodal large language models see, remember, and recall spaces,
J. Yang, S. Yang, A. W. Gupta, R. Han, L. Fei-Fei, and S. Xie, “Thinking in space: How multimodal large language models see, remember, and recall spaces,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 10 632–10 643
2025
-
[42]
Embodiedbench: Comprehensive benchmarking multi- modal large language models for vision-driven embodied agents,
R. Yang, H. Chen, J. Zhang, M. Zhao, C. Qian, K. Wang, Q. Wang, T. V . Koripella, M. Movahedi, M. Li, H. Ji, H. Zhang, and T. Zhang, “Embodiedbench: Comprehensive benchmarking multi- modal large language models for vision-driven embodied agents,” inProceedings of the 42nd International Conference on Machine Learning, vol. 267. PMLR, 2025, pp. 70 576–70 631
2025
-
[43]
The rendering equation,
J. T. Kajiya, “The rendering equation,” inProceedings of the 13th annual conference on Computer graphics and interactive techniques, 1986
1986
-
[44]
Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models,
M. Du, B. Wu, Z. Li, X. Huang, and Z. Wei, “Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 2024, pp. 346–355
2024
-
[45]
Y . Tang, L. Zhang, S. Zhang, Y . Zhao, and X. Hao, “Roboafford: A dataset and benchmark for enhancing object and spatial affordance learning in robot manipulation,” inProceedings of the 33rd ACM International Conference on Multimedia, ser. MM ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 12706–12713. [Online]. Available: https://...
-
[46]
Qwen3.6-35B-A3B: Agentic coding power, now open to all,
Qwen Team, “Qwen3.6-35B-A3B: Agentic coding power, now open to all,” April 2026. [Online]. Available: https://qwen.ai/blog?id=qwen3.6-35b-a3b
2026
-
[47]
Qwen-image technical report,
C. Wu, J. Li, J. Zhou, J. Lin, K. Gao, K. Yan, S. ming Yin, S. Bai, X. Xu, Y . Chen, Y . Chen, Z. Tang, Z. Zhang, Z. Wang, A. Yang, B. Yu, C. Cheng, D. Liu, D. Li, H. Zhang, H. Meng, H. Wei, J. Ni, K. Chen, K. Cao, L. Peng, L. Qu, M. Wu, P. Wang, S. Yu, T. Wen, W. Feng, X. Xu, Y . Wang, Y . Zhang, Y . Zhu, Y . Wu, Y . Cai, and Z. Liu, “Qwen-image technica...
-
[48]
[Online]. Available: https://arxiv.org/abs/2508.02324
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Free stock photos, royalty free stock images & copyright free pictures,
Pexels, “Free stock photos, royalty free stock images & copyright free pictures,” https://www. pexels.com/, 2026, accessed: 2026-05-03
2026
-
[50]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Suet al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” in European conference on computer vision. Springer, 2024, pp. 38–55
2024
-
[51]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[52]
Nano Banana Pro: Gemini ai image generator & photo editor,
Google Gemini, “Nano Banana Pro: Gemini ai image generator & photo editor,” https://gemini. google/us/overview/image-generation/, 2026, accessed: 2026-05-07. 13 Appendix A RoboStressBench Details A.1 Data Sources RoboStressBench is constructed from three types of source data: existing public benchmarks, Internet- sourced real-world images, and self-collec...
2026
-
[53]
Existing public benchmarks.RoboStressBench uses samples from EmbSpatial-Bench [44], released under CC BY 4.0; RefSpatial-Bench [35], released under Apache 2.0; RoboAfford- Eval [45], released under CC BY 4.0; RoboSpatial-Home [ 34], released under Apache 2.0; ManipulationVQA [39], released under Apache 2.0; V ABench-P [38], released under Apache 2.0; and ...
-
[54]
Under the Pexels License, content is free to use and modify for commercial or non- commercial purposes without required attribution
Pexels-sourced real-world images.The dataset contains images sourced from Pexels [ 48]. Under the Pexels License, content is free to use and modify for commercial or non- commercial purposes without required attribution. The terms explicitly prohibit redis- tributing or selling the photos on other stock photo or wallpaper platforms. We release these image...
-
[55]
These derived samples inherit the license and usage constraints of their underlying source datasets and are not relicensed independently
Controlled stress synthesis.Some controlled stress samples are synthesized from existing benchmark images, such as lighting-stress variants generated from public benchmark sources. These derived samples inherit the license and usage constraints of their underlying source datasets and are not relicensed independently. Synthesis based on proprietary in-hous...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.