ThinkSwitch: Context Distillation with LoRA and Weight Interpolation for Specific-Purpose Reasoning Tasks
Pith reviewed 2026-06-28 17:50 UTC · model grok-4.3
The pith
ThinkSwitch transfers some reasoning benefit into weights by distilling answer-only pairs and reconstructing the thinking checkpoint via spherical interpolation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
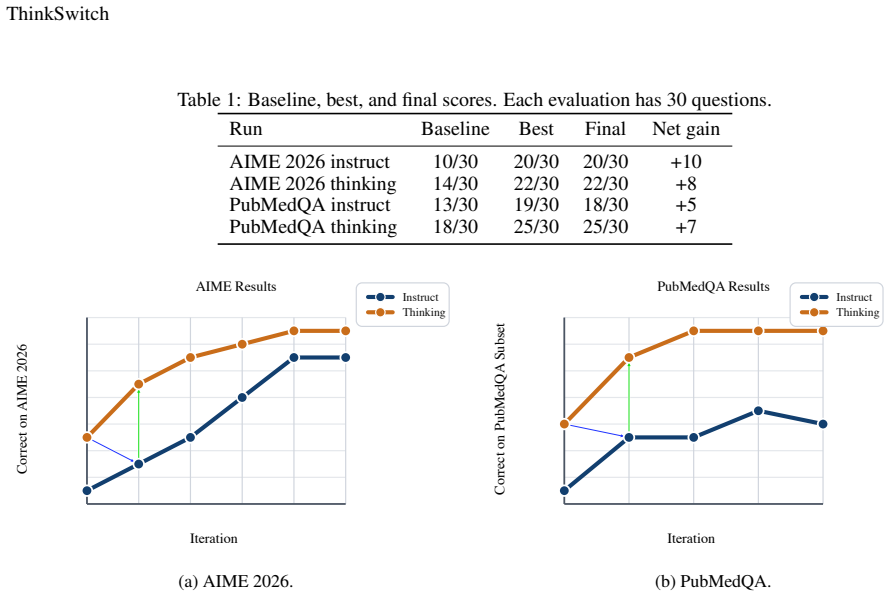
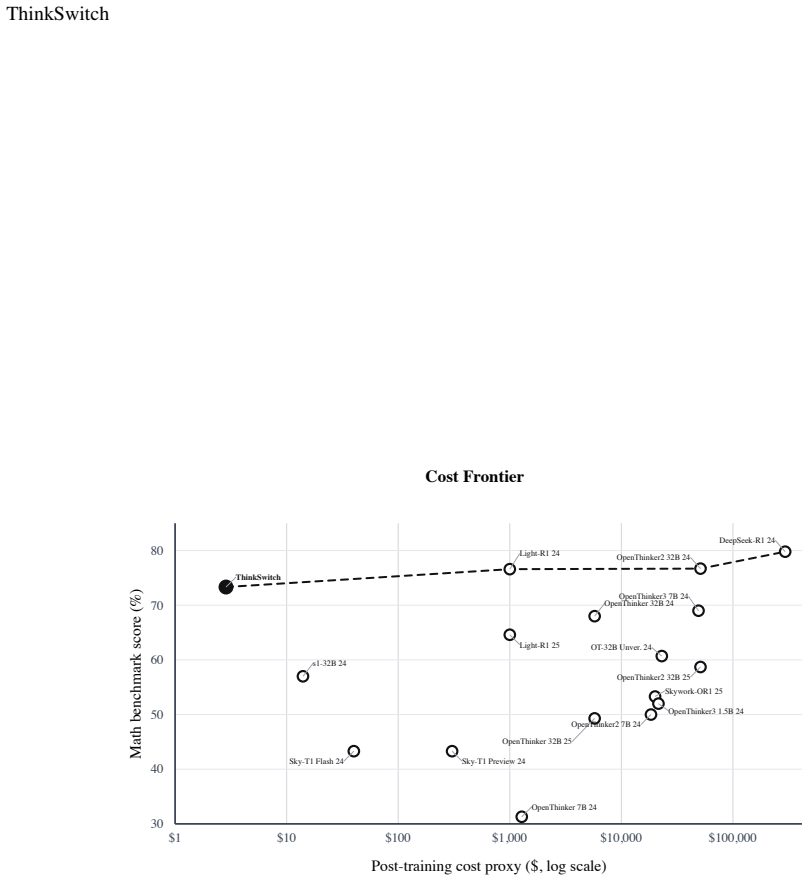
By alternating QLoRA distillation of answer-only outputs from a thinking checkpoint into an instruct checkpoint, followed by spherical weight interpolation to reconstruct the thinking checkpoint, the procedure raises accuracy on a 30-question AIME set from 10/30 to 20/30 for the instruct model and from 14/30 to 22/30 for the thinking model, and on a 30-question PubMedQA subset from 13/30 to 18/30 and 18/30 to 25/30 respectively, at a total cost of $2.86 on one RTX 3070 using only 15 training prompts per domain.
What carries the argument
Spherical weight interpolation between the QLoRA-updated instruct checkpoint and the prior thinking checkpoint to reconstruct a thinking model that continues to produce useful reasoning traces.
If this is right
- Both the instruct and thinking checkpoints can be improved in the same loop without external labels.
- The method runs on consumer hardware with 15 prompts and under three dollars of cloud cost.
- Reasoning benefits can be partially moved into weights while a separate thinking mode is retained.
- The procedure requires only task prompts as human input.
- The same loop applies across math and biomedical QA domains.
Where Pith is reading between the lines
- The interpolation step may allow the thinking mode to be refreshed without full retraining on future tasks.
- If the instruct model captures enough of the reasoning, downstream applications could drop the thinking trace at inference time to cut latency.
- The approach could be tested on whether the gains persist when the base models are larger than 4B parameters.
- It remains open whether the same loop would transfer to domains where the thinking trace contains domain-specific knowledge rather than general reasoning patterns.
Load-bearing premise
Spherical weight interpolation between the updated instruct checkpoint and the prior thinking checkpoint successfully reconstructs a thinking model that continues to generate useful reasoning traces rather than collapsing or losing capability.
What would settle it
A direct measurement showing that the interpolated thinking checkpoint produces reasoning traces whose removal no longer changes final-answer accuracy, or that accuracy on the held-out evaluation sets stops rising after one or two iterations.
Figures


read the original abstract
Large language models often improve on difficult tasks by spending inference-time compute on a reasoning trace before producing the final answer. That extra computation can be useful, but it also raises latency, token cost, and deployment complexity. We introduce \textbf{ThinkSwitch}, a low-compute procedure for co-training paired instruct and thinking checkpoints. Starting from compatible Qwen3-4B instruct and thinking models, each iteration asks the thinking checkpoint to generate answers, removes the reasoning trace, distills the answer-only pairs into the instruct checkpoint with QLoRA, and reconstructs a thinking checkpoint with spherical weight interpolation. The only human-supplied inputs are task prompts; the labels are generated by the model itself. On a 30-question AIME 2026 evaluation, ThinkSwitch improves the instruct checkpoint from 10/30 to 20/30 and the thinking checkpoint from 14/30 to 22/30. On a 30-question PubMedQA subset, it improves the instruct checkpoint from 13/30 to 18/30 and the thinking checkpoint from 18/30 to 25/30. The complete experiment uses 15 training prompts per domain and costs \$2.86 on a single cloud RTX 3070. The results are small-scale, but they indicate that targeted distillation loops can move part of the benefit of explicit reasoning into weights while preserving a separate thinking mode.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ThinkSwitch, a low-compute iterative procedure that starts from compatible Qwen3-4B instruct and thinking models, uses the thinking checkpoint to generate self-supervised answer-only pairs, distills them into the instruct checkpoint via QLoRA, and reconstructs the next thinking checkpoint via spherical weight interpolation. It reports accuracy gains on 30-question subsets of AIME 2026 (instruct 10/30→20/30, thinking 14/30→22/30) and PubMedQA (instruct 13/30→18/30, thinking 18/30→25/30) using only 15 training prompts per domain at a cost of $2.86.
Significance. If the central empirical claims hold after addressing the verification gaps, the work would demonstrate a practical route to partially internalize inference-time reasoning benefits into weights while retaining a distinct thinking mode, with potential relevance for latency-sensitive deployment of reasoning models. The self-supervised, low-resource nature is a positive attribute, but the current scale and missing controls make the contribution preliminary rather than definitive.
major comments (2)
- [Abstract] Abstract: the reported improvements on the thinking checkpoint (AIME 14/30→22/30, PubMedQA 18/30→25/30) depend on the unverified assumption that spherical interpolation between the QLoRA-updated instruct checkpoint and the prior thinking checkpoint preserves useful reasoning-trace generation rather than collapsing toward direct-answer behavior; no ablation, trace-quality metric, or verification of this property is supplied.
- [Experiments] Experiments: the numerical gains are presented without multiple independent runs, error bars, statistical significance tests, or any description of QLoRA hyperparameters, training epochs, or exact distillation procedure, preventing assessment of whether the gains are reproducible or attributable to the proposed loop rather than incidental fine-tuning.
minor comments (1)
- [Abstract] Abstract: the description of spherical interpolation would benefit from an explicit formula or reference to the precise interpolation method used (e.g., the weighting parameter or normalization).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported improvements on the thinking checkpoint (AIME 14/30→22/30, PubMedQA 18/30→25/30) depend on the unverified assumption that spherical interpolation between the QLoRA-updated instruct checkpoint and the prior thinking checkpoint preserves useful reasoning-trace generation rather than collapsing toward direct-answer behavior; no ablation, trace-quality metric, or verification of this property is supplied.
Authors: We agree that the preservation of reasoning-trace generation after spherical interpolation is supported only indirectly by the observed accuracy gains on the thinking checkpoint. No direct ablation, trace-quality metric, or verification is provided in the current manuscript. In revision we will add an analysis of sample outputs from the interpolated thinking checkpoint (e.g., presence and length of reasoning traces) together with a simple ablation comparing interpolated versus non-interpolated checkpoints on trace-related metrics. revision: yes
-
Referee: [Experiments] Experiments: the numerical gains are presented without multiple independent runs, error bars, statistical significance tests, or any description of QLoRA hyperparameters, training epochs, or exact distillation procedure, preventing assessment of whether the gains are reproducible or attributable to the proposed loop rather than incidental fine-tuning.
Authors: We acknowledge that the current presentation lacks multiple runs, error bars, statistical tests, and detailed hyperparameter information. The manuscript will be revised to include the exact QLoRA rank, learning rate, number of epochs, batch size, and the precise self-distillation procedure. Because the experiments were conducted under a strict low-resource budget, only single runs were performed; we will explicitly discuss this limitation and, if additional compute permits, report variance from a small number of repeated trials. revision: partial
Circularity Check
No significant circularity; empirical self-distillation on held-out evals
full rationale
The paper presents an empirical procedure: the thinking checkpoint generates answer-only pairs from task prompts, these are used to QLoRA-update the instruct checkpoint, and spherical interpolation reconstructs the next thinking checkpoint. Reported gains (AIME 14/30→22/30, PubMedQA 18/30→25/30 on the thinking checkpoint) are measured on separate 30-question evaluation sets distinct from the 15 training prompts per domain. No equations, uniqueness theorems, or self-citations appear in the provided text. The self-generation of labels is explicit but does not reduce the measured test-set improvements to the training inputs by construction; the method remains falsifiable on external benchmarks. This is a standard distillation loop with no load-bearing circular step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Spherical weight interpolation between instruct and thinking checkpoints preserves reasoning capability
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
Advances in Neural Information Processing Systems , volume=
Training Compute-Optimal Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Advances in Neural Information Processing Systems , volume=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Advances in Neural Information Processing Systems , volume=
Large Language Models are Zero-Shot Reasoners , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. arXiv preprint arXiv:2203.11171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Snell, Charlie and Lee, Jaehoon and Xu, Kelvin and Kumar, Aviral , journal=. Scaling
-
[7]
arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
International Conference on Learning Representations , year=
Think before you speak: Training Language Models With Pause Tokens , author=. International Conference on Learning Representations , year=
-
[9]
arXiv preprint arXiv:2311.11829 , year=
System 2 Attention (is something you might need too) , author=. arXiv preprint arXiv:2311.11829 , year=
-
[10]
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
Compressed Chain of Thought: Efficient Reasoning through Dense Representations , author=. arXiv preprint arXiv:2412.13171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , journal=
-
[13]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , journal=
-
[14]
Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung , journal=
-
[15]
Zhang, Qingru and Chen, Minshuo and Bukharin, Alexander and He, Pengcheng and Cheng, Yu and Chen, Weizhu and Zhao, Tuo , journal=
-
[16]
Huang, Chengsong and Liu, Qian and Lin, Bill Yuchen and Pang, Tianyu and Du, Chao and Lin, Min , journal=
-
[17]
Wu, Xun and Huang, Shaohan and Wei, Furu , journal=
-
[18]
Prabhakar, Akshara and Li, Yuanzhi and Narasimhan, Karthik and Arora, Sanjeev , journal=
-
[19]
Zhao, Ziyu and Gan, Leilei and Wang, Guoyin and others , journal=. Merging
-
[20]
Distilling the Knowledge in a Neural Network
Distilling the Knowledge in a Neural Network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Conference on Empirical Methods in Natural Language Processing , pages=
Sequence-Level Knowledge Distillation , author=. Conference on Empirical Methods in Natural Language Processing , pages=
-
[22]
A General Language Assistant as a Laboratory for Alignment
A General Language Assistant as a Laboratory for Alignment , author=. arXiv preprint arXiv:2112.00861 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv preprint arXiv:2209.15189 , year=
Learning by Distilling Context , author=. arXiv preprint arXiv:2209.15189 , year=
-
[24]
International Conference on Learning Representations , year=
Implicit Chain of Thought Reasoning via Knowledge Distillation , author=. International Conference on Learning Representations , year=
-
[25]
From Explicit
Deng, Yuntian and Choi, Yejin and Shieber, Stuart , journal=. From Explicit
-
[26]
Association for Computational Linguistics , year=
Large Language Models Are Reasoning Teachers , author=. Association for Computational Linguistics , year=
-
[27]
Association for Computational Linguistics Findings , year=
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes , author=. Association for Computational Linguistics Findings , year=
-
[28]
Association for Computational Linguistics , year=
Symbolic Chain-of-Thought Distillation: Small Models Can Also ``Think'' Step-by-Step , author=. Association for Computational Linguistics , year=
-
[29]
Association for Computational Linguistics Findings , year=
Distilling Reasoning Capabilities into Smaller Language Models , author=. Association for Computational Linguistics Findings , year=
-
[30]
International Conference on Learning Representations , year=
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author=. International Conference on Learning Representations , year=
-
[31]
International Conference on Learning Representations , year=
Editing Models with Task Arithmetic , author=. International Conference on Learning Representations , year=
-
[32]
Advances in Neural Information Processing Systems , volume=
Task Arithmetic in the Tangent Space: Improved Editing of Pre-Trained Models , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
International Conference on Machine Learning , pages=
Model Soups: Averaging Weights of Multiple Fine-tuned Models Improves Accuracy without Increasing Inference Time , author=. International Conference on Machine Learning , pages=
-
[34]
Yadav, Prateek and Tam, Derek and Choshen, Leshem and Raffel, Colin and Bansal, Mohit , journal=
-
[35]
Language Models are
Yu, Le and Yu, Bowen and Yu, Haiyang and Huang, Fei and Li, Yongbin , journal=. Language Models are
-
[36]
Goddard, Charles , howpublished=
-
[37]
Nature Machine Intelligence , year=
Evolutionary Optimization of Model Merging Recipes , author=. Nature Machine Intelligence , year=
-
[38]
Zelikman, Eric and Wu, Yuhuai and Mu, Jesse and Goodman, Noah D , journal=
-
[39]
Zelikman, Eric and Harik, Georges and Shao, Yijia and Jayasiri, Varuna and Haber, Nick and Goodman, Noah D , journal=
-
[40]
Hosseini, Arian and Yuan, Xingdi and Malkin, Nikolay and Courville, Aaron and Sordoni, Alessandro and Agarwal, Rishabh , journal=
-
[41]
Reinforced Self-Training (
Gulcehre, Caglar and Le Paine, Tom and Srinivasan, Srivatsan and Konyushkova, Ksenia and Weerts, Lotte and Sharma, Abhishek and Siddhant, Aditya and Ahern, Alex and Wang, Miaosen and Gu, Chenjie and others , journal=. Reinforced Self-Training (
-
[42]
Kumar, Aviral and Zhuang, Vincent and Agarwal, Rishabh and Su, Yi and Warkentin, John and Dayan, Peter and Flennerhag, Sebastian and Barber, David and Le, Quoc and others , journal=
-
[43]
Advances in Neural Information Processing Systems , volume=
Self-Refine: Iterative Refinement with Self-Feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Large Language Models Can Self-Improve
Large Language Models Can Self-Improve , author=. arXiv preprint arXiv:2210.11610 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
2011 , publisher=
Thinking, Fast and Slow , author=. 2011 , publisher=
2011
-
[46]
Thinking Fast and Slow in
Booch, Grady and Fabiano, Francesco and Horesh, Lior and Kate, Kiran and Lenchner, Jonathan and Linck, Nick and Loreggia, Andrea and Murgesan, Keerthiram and Mattei, Nicholas and Rossi, Francesca and Srivastava, Biplav , journal=. Thinking Fast and Slow in
-
[47]
From System 1 to System 2: A Survey of Reasoning Large Language Models
From System 1 to System 2: A Survey of Reasoning Large Language Models , author=. arXiv preprint arXiv:2502.17419 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Thinking Fast and Slow in
Ganapini, Marianna Bergamaschi and others , journal=. Thinking Fast and Slow in
-
[49]
Fast, slow, and metacognitive thinking in
Mattei, Nicholas and others , journal=. Fast, slow, and metacognitive thinking in
-
[50]
arXiv preprint arXiv:2505.16315 , year=
Incentivizing Dual Process Thinking for Efficient Large Language Model Reasoning , author=. arXiv preprint arXiv:2505.16315 , year=
-
[51]
Reasoning on a Spectrum: Aligning
Chollet, Fran. Reasoning on a Spectrum: Aligning. arXiv preprint arXiv:2502.12470 , year=
-
[52]
Jimenez, Carlos E and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , journal=
-
[53]
Yang, John and Jimenez, Carlos E and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , journal=
-
[54]
Agentless: Demystifying
Xia, Chunqiu Steven and Deng, Yinlin and Dunn, Soren and Zhang, Lingming , journal=. Agentless: Demystifying
-
[55]
Zhang, Yuntong and Ruan, Haifeng and Fan, Zhiyu and Roychoudhury, Abhik , journal=
-
[56]
Bairi, Ramakrishna and others , journal=
-
[57]
Zhang, Fengji and Chen, Bei and Zhang, Yue and others , journal=
-
[58]
Liu, Tianyang and Xu, Canwen and McAuley, Julian , journal=
-
[59]
Zhuo, Terry Yue and others , journal=
-
[60]
Liu, Mingwei and others , journal=
-
[61]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Program Synthesis with Large Language Models
Program Synthesis with Large Language Models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
International Conference on Software Engineering , year=
Automated Program Repair in the Era of Large Pre-trained Language Models , author=. International Conference on Software Engineering , year=
-
[65]
Large Language Model-Based Agents for Software Engineering: A Survey
Large Language Model-Based Agents for Software Engineering: A Survey , author=. arXiv preprint arXiv:2409.02977 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
Han, Daniel and Han, Michael , year=
-
[67]
arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
Hobbhahn, Marius , year=
-
[69]
Advances in Neural Information Processing Systems , volume=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
Jain, Naman and Singh, Jaskirat and Shetty, Manish and Zheng, Liang and Sen, Koushik and Stoica, Ion , journal=
-
[71]
Supervising strong learners by amplifying weak experts
Supervising Strong Learners by Amplifying Weak Experts , author=. arXiv preprint arXiv:1810.08575 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
Proceedings of the 12th Annual Conference on Computer Graphics and Interactive Techniques , pages=
Animating Rotation with Quaternion Curves , author=. Proceedings of the 12th Annual Conference on Computer Graphics and Interactive Techniques , pages=
-
[73]
and Zhang, Hao and Stoica, Ion , booktitle=
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle=. Efficient Memory Management for Large Language Model Serving with
-
[74]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and others , journal=
-
[75]
2025 , howpublished=
2025
-
[76]
and Lu, Xinghua , journal=
Jin, Qiao and Dhingra, Bhuwan and Liu, Zhengping and Cohen, William W. and Lu, Xinghua , journal=
-
[77]
2026 , howpublished=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.