Transferring Information Across Interventions in Causal Bayesian Optimization
Pith reviewed 2026-06-28 16:46 UTC · model grok-4.3
The pith
Coupling different interventions through shared causal parameters allows evidence from one to improve estimates of others.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
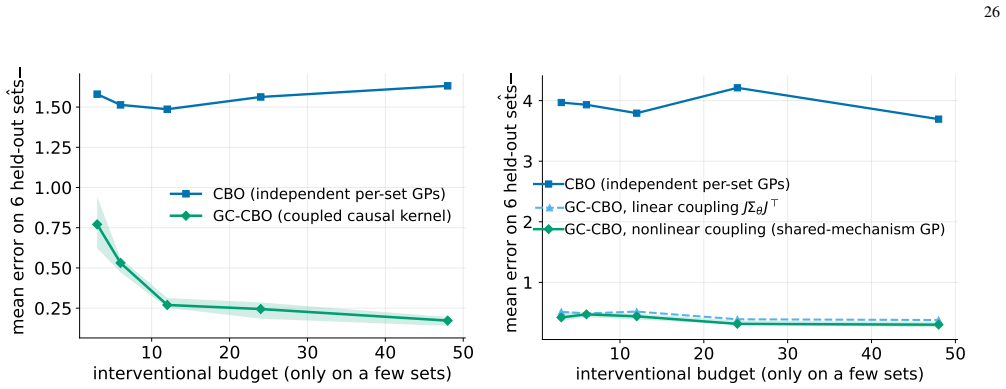
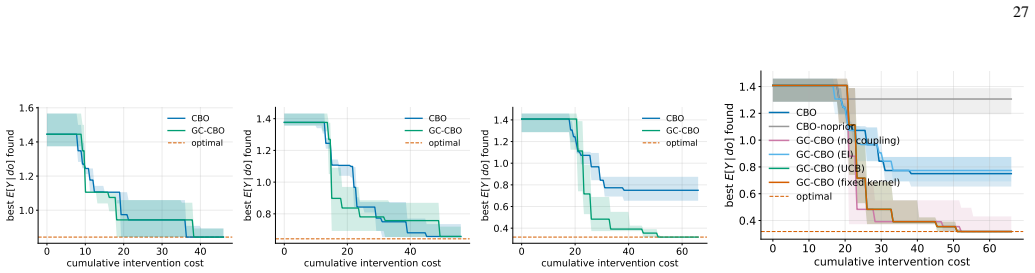
In identifiable linear Gaussian causal models, the proposed causal kernel has low rank, bounded by the number of shared parameters rather than the size of the intervention menu. This yields an information-gain bound that grows only logarithmically in the optimization horizon, and a regret bound that cleanly separates three sources of error: optimization, causal estimation, and the choice of which intervention sets to consider. Nonlinear and adaptive extensions are described.
What carries the argument
The graph-coupled causal kernel, which ties intervention effects together through uncertainty over a small set of shared causal parameters.
If this is right
- Information collected from one intervention improves estimates for related interventions.
- Information gain grows logarithmically with the optimization horizon rather than with the number of interventions.
- Regret bounds separate optimization error, causal estimation error, and errors from choosing intervention sets.
- Performance gains are clearest when direct interventions on target parents are unavailable and data must be reused across many candidate interventions.
Where Pith is reading between the lines
- The separation of error sources could help allocate resources between learning the causal model and optimizing the objective.
- This coupling might reduce the need for many direct interventions in systems with large intervention menus.
- Adaptive versions could dynamically update the shared parameters as more data arrives.
Load-bearing premise
A known causal graph is available together with observational data, and the system is an identifiable linear Gaussian causal model.
What would settle it
Observing that the information gain grows linearly with the number of interventions instead of logarithmically with the horizon in a linear Gaussian system would falsify the low-rank property of the kernel.
Figures


read the original abstract
Bayesian optimization is a popular way to optimize expensive systems, where every experiment, simulation, or intervention costs time or money. In its standard form, it treats the variables we control as plain inputs to a black box and cannot tell apart mere correlation from a real cause and effect. Causal Bayesian optimization closes part of this gap by using a known causal graph together with observational data to decide which variables are worth intervening on. Existing methods, however, learn the effect of each possible intervention almost in isolation, even though in a causal system these effects usually share the same underlying mechanisms. We propose graph-coupled causal Bayesian optimization, which ties the different intervention effects together through the uncertainty we have about a small set of shared causal parameters. The result is a causal kernel that lets evidence collected from one intervention improve our estimate of related interventions. For identifiable linear Gaussian causal models, we show that this kernel has low rank, bounded by the number of shared parameters rather than by the size of the intervention menu. This in turn yields an information-gain bound that grows only logarithmically in the optimization horizon, and a regret bound that cleanly separates three sources of error: optimization, causal estimation, and the choice of which intervention sets to consider. We also describe nonlinear and adaptive extensions. Across theory-aligned Gaussian systems, shared-mechanism stress tests, and standard causal optimization benchmarks, the method keeps the benefits of causal Bayesian optimization while transferring information across related interventions, with the clearest gains when direct interventions on the target's parents are unavailable and sparse interventional data must be reused across a large family of candidate interventions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce graph-coupled causal Bayesian optimization, which uses a causal kernel based on shared causal parameters to transfer information across interventions. For identifiable linear Gaussian causal models with known graph and observational data, the kernel has low rank bounded by the number of shared parameters, yielding logarithmic information-gain bounds in the optimization horizon and a regret bound separating optimization, causal estimation, and menu-selection errors. Nonlinear and adaptive extensions are described, with empirical gains on benchmarks especially when direct interventions on parents are unavailable.
Significance. If the results hold, this advances causal Bayesian optimization by enabling information transfer across interventions via shared mechanisms, leading to more efficient optimization in causal systems. The logarithmic bound and error decomposition are notable strengths, as is the focus on identifiable models. The empirical validation on theory-aligned systems and standard benchmarks adds practical value.
major comments (1)
- [§4.2] §4.2 (regret bound): the decomposition isolates causal estimation error from fixed observational data, but the paper must explicitly verify that the matrix A in the low-rank Gram matrix G = A Cov(θ) A^T remains independent of the adaptive intervention choices; otherwise the information-gain bound may not separate cleanly from menu-selection error.
minor comments (2)
- [Abstract] Abstract: the term 'graph-coupled causal Bayesian optimization' is introduced without a one-sentence definition or pointer to its formal definition in §3.
- [§5] §5 (experiments): the description of benchmark setups and any data exclusion rules should be expanded with explicit pseudocode or parameter values to support reproducibility of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recommendation of minor revision, and the helpful comment on the regret bound. We address the point below.
read point-by-point responses
-
Referee: [§4.2] §4.2 (regret bound): the decomposition isolates causal estimation error from fixed observational data, but the paper must explicitly verify that the matrix A in the low-rank Gram matrix G = A Cov(θ) A^T remains independent of the adaptive intervention choices; otherwise the information-gain bound may not separate cleanly from menu-selection error.
Authors: We agree that explicit verification of this independence is needed for a clean separation. In our construction the causal graph is known and fixed, the observational data are fixed, and the intervention menu (the finite set of candidate interventions) is chosen a priori and fixed. The matrix A is assembled from the known graph structure and the fixed menu; it encodes the linear mapping from the shared parameters θ to each intervention effect and therefore does not depend on the sequence of adaptively chosen interventions. Consequently G = A Cov(θ) A^T is a fixed low-rank kernel over the intervention space. The information-gain bound is taken with respect to this fixed kernel, while the regret decomposition isolates (i) optimization error arising from the BO acquisition procedure, (ii) causal estimation error arising from the fixed observational data, and (iii) menu-selection error arising from the a-priori choice of the intervention menu. We will add a short clarifying paragraph and a direct statement of A’s independence in §4.2. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper constructs a causal kernel by coupling intervention effects through a shared low-dimensional parameter vector θ in identifiable linear Gaussian models. The claimed low-rank property (rank bounded by dim(θ)) follows directly as a linear-algebra consequence of the kernel definition itself (Gram matrix of the form A Cov(θ) A^T). The subsequent information-gain bound (logarithmic in horizon) is obtained by applying standard results on maximum information gain for finite-rank kernels; the regret decomposition isolates optimization, causal-estimation, and menu-selection errors without any fitted parameter being renamed as a prediction or any self-citation serving as the sole justification. No self-definitional loop, fitted-input-as-prediction, or load-bearing self-citation appears in the derivation chain. The result is mathematically self-contained given the stated model class.
Axiom & Free-Parameter Ledger
free parameters (1)
- shared causal parameters
axioms (2)
- domain assumption Known causal graph is available
- domain assumption System is an identifiable linear Gaussian causal model
Reference graph
Works this paper leans on
-
[1]
Causal Bayesian optimization
Virginia Aglietti, Xiaoyu Lu, Andrei Paleyes, and Javier Gonz ´alez. Causal Bayesian optimization. InProceedings of the 23rd International Conference on Artificial Intelligence and Statistics, pages 3155–3164. PMLR, 2020
2020
-
[2]
Constrained causal Bayesian optimization
Virginia Aglietti, Alan Malek, Ira Ktena, and Silvia Chiappa. Constrained causal Bayesian optimization. InInternational Conference on Machine Learning, pages 304–321. PMLR, 2023
2023
-
[3]
Thinking inside the box: A tutorial on grey-box Bayesian optimization
Raul Astudillo and Peter I Frazier. Thinking inside the box: A tutorial on grey-box Bayesian optimization. In2021 Winter Simulation Conference (WSC), pages 1–15. IEEE, 2021
2021
-
[4]
Misspecified Gaussian process bandit optimization.Advances in neural information processing systems, 34:3004–3015, 2021
Ilija Bogunovic and Andreas Krause. Misspecified Gaussian process bandit optimization.Advances in neural information processing systems, 34:3004–3015, 2021
2021
-
[5]
Causal entropy optimiza- tion
Nicola Branchini, Virginia Aglietti, Neil Dhir, and Theodoros Damoulas. Causal entropy optimiza- tion. InInternational Conference on Artificial Intelligence and Statistics, pages 8586–8605. PMLR, 2023
2023
-
[6]
Differentiable expected hypervolume improvement for parallel multi-objective Bayesian optimization.Advances in neural information processing systems, 33:9851–9864, 2020
Samuel Daulton, Maximilian Balandat, and Eytan Bakshy. Differentiable expected hypervolume improvement for parallel multi-objective Bayesian optimization.Advances in neural information processing systems, 33:9851–9864, 2020
2020
-
[7]
Parallel Bayesian optimization of multiple noisy objectives with expected hypervolume improvement.Advances in neural information processing systems, 34:2187–2200, 2021
Samuel Daulton, Maximilian Balandat, and Eytan Bakshy. Parallel Bayesian optimization of multiple noisy objectives with expected hypervolume improvement.Advances in neural information processing systems, 34:2187–2200, 2021
2021
-
[8]
Multi-fidelity Bayesian optimization in engineering design.arXiv preprint arXiv:2311.13050, 2023
Bach Do and Ruda Zhang. Multi-fidelity Bayesian optimization in engineering design.arXiv preprint arXiv:2311.13050, 2023
arXiv 2023
-
[9]
High-dimensional Bayesian optimization with sparse axis- aligned subspaces
David Eriksson and Martin Jankowiak. High-dimensional Bayesian optimization with sparse axis- aligned subspaces. InUncertainty in artificial intelligence, pages 493–503. PMLR, 2021
2021
-
[10]
Peter I. Frazier. A tutorial on Bayesian optimization.arXiv preprint arXiv:1807.02811, 2018
Pith/arXiv arXiv 2018
-
[11]
Bayesian optimization for materials design
Peter I Frazier and Jialei Wang. Bayesian optimization for materials design. InInformation science for materials discovery and design, pages 45–75. Springer, 2015
2015
-
[12]
Cambridge University Press, 2023
Roman Garnett.Bayesian optimization. Cambridge University Press, 2023
2023
-
[13]
Functional causal Bayesian optimization
Limor Gultchin, Virginia Aglietti, Alexis Bellot, and Silvia Chiappa. Functional causal Bayesian optimization. InUncertainty in Artificial Intelligence, pages 756–765. PMLR, 2023. 31
2023
-
[14]
Regret bounds for expected improvement algorithms in Gaussian process bandit optimization
Sunil Gupta, Santu Rana, Svetha Venkatesh, et al. Regret bounds for expected improvement algorithms in Gaussian process bandit optimization. InInternational Conference on Artificial Intelligence and Statistics, pages 8715–8737. PMLR, 2022
2022
-
[15]
Anubis: Bayesian optimization with unknown feasibility constraints for scientific experimentation.Digital Discovery, 4(8):2104–2122, 2025
Riley J Hickman, Gary Tom, Yunheng Zou, Matteo Aldeghi, and Al ´an Aspuru-Guzik. Anubis: Bayesian optimization with unknown feasibility constraints for scientific experimentation.Digital Discovery, 4(8):2104–2122, 2025
2025
-
[16]
Horn and Charles R
Roger A. Horn and Charles R. Johnson.Matrix Analysis. Cambridge University Press, 2 edition, 2013
2013
-
[17]
Md Abir Hossen, Mohammad Ali Javidian, Vignesh Narayanan, Jason M O’Kane, and Pooyan Jamshidi. Multi-objective multi-fidelity Bayesian optimization with causal priors.arXiv preprint arXiv:2602.00788, 2026
arXiv 2026
-
[18]
Improved regret bounds for Gaussian process upper confidence bound in Bayesian optimization.Advances in Neural Information Processing Systems, 38:96922–96964, 2026
Shogo Iwazaki. Improved regret bounds for Gaussian process upper confidence bound in Bayesian optimization.Advances in Neural Information Processing Systems, 38:96922–96964, 2026
2026
-
[19]
Luuk Jacobs and Mohammad Ali Javidian. Extending multi-source Bayesian optimization with causality principles.arXiv preprint arXiv:2602.14791, 2026
arXiv 2026
-
[20]
Neural contextual bandits without regret
Parnian Kassraie and Andreas Krause. Neural contextual bandits without regret. InInternational Conference on Artificial Intelligence and Statistics, pages 240–278. PMLR, 2022
2022
-
[21]
Benchmarking the performance of Bayesian optimization across multiple experimental materials science domains.npj Computational Materials, 7(1):188, 2021
Qiaohao Liang, Aldair E Gongora, Zekun Ren, Armi Tiihonen, Zhe Liu, Shijing Sun, James R Deneault, Daniil Bash, Flore Mekki-Berrada, Saif A Khan, et al. Benchmarking the performance of Bayesian optimization across multiple experimental materials science domains.npj Computational Materials, 7(1):188, 2021
2021
-
[22]
Cambridge University Press, 2 edition, 2009
Judea Pearl.Causality: Models, Reasoning, and Inference. Cambridge University Press, 2 edition, 2009
2009
-
[23]
Yahpo gym-an efficient multi-objective multi-fidelity benchmark for hyperparameter optimization
Florian Pfisterer, Lennart Schneider, Julia Moosbauer, Martin Binder, and Bernd Bischl. Yahpo gym-an efficient multi-objective multi-fidelity benchmark for hyperparameter optimization. In International Conference on Automated Machine Learning, pages 3–1. PMLR, 2022
2022
-
[24]
Carl Edward Rasmussen and Christopher K. I. Williams.Gaussian Processes for Machine Learning. MIT Press, 2006
2006
-
[25]
Causal Bayesian optimization via exogenous distribution learning
Shaogang Ren and Xiaoning Qian. Causal Bayesian optimization via exogenous distribution learning. arXiv preprint arXiv:2402.02277, 2024
arXiv 2024
-
[26]
Causalbo: A python package for causal Bayesian optimization
Jeremy Roberts and Mohammad Ali Javidian. Causalbo: A python package for causal Bayesian optimization. InSoutheastCon 2024, pages 1370–1375. IEEE, 2024
2024
-
[27]
Learning bayesian networks with the bnlearn r package.Journal of statistical software, 35:1–22, 2010
Marco Scutari. Learning bayesian networks with the bnlearn r package.Journal of statistical software, 35:1–22, 2010
2010
-
[28]
Taking the human out of the loop: A review of Bayesian optimization.Proceedings of the IEEE, 104(1):148–175, 2015
Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P Adams, and Nando De Freitas. Taking the human out of the loop: A review of Bayesian optimization.Proceedings of the IEEE, 104(1):148–175, 2015
2015
-
[29]
Identification of joint interventional distributions in recursive semi- markovian causal models
Ilya Shpitser and Judea Pearl. Identification of joint interventional distributions in recursive semi- markovian causal models. InProceedings of the Twenty-First National Conference on Artificial Intelligence, 2006
2006
-
[30]
Kakade, and Matthias Seeger
Niranjan Srinivas, Andreas Krause, Sham M. Kakade, and Matthias Seeger. Information-theoretic regret bounds for Gaussian process optimization in the bandit setting.IEEE Transactions on Information Theory, 58(5):3250–3265, 2012
2012
-
[31]
Adversarial causal Bayesian optimization
Scott Sussex, Pier Giuseppe Sessa, Anastasia Makarova, and Andreas Krause. Adversarial causal Bayesian optimization. InInternational Conference on Learning Representations, volume 2024, pages 19332–19353, 2024
2024
-
[32]
On information gain and regret bounds in Gaussian process bandits
Sattar Vakili, Kia Khezeli, and Victor Picheny. On information gain and regret bounds in Gaussian process bandits. InProceedings of the 24th International Conference on Artificial Intelligence and Statistics. PMLR, 2021
2021
-
[33]
Cost-aware Bayesian 32 optimization via the pandora’s box gittins index.Advances in Neural Information Processing Systems, 37:115523–115562, 2024
Qian Xie, Raul Astudillo, Peter I Frazier, Ziv Scully, and Alexander Terenin. Cost-aware Bayesian 32 optimization via the pandora’s box gittins index.Advances in Neural Information Processing Systems, 37:115523–115562, 2024
2024
-
[34]
Yilin Xie, Shiqiang Zhang, Joel A. Paulson, and Calvin Tsay. Global optimization of Gaussian process acquisition functions using a piecewise-linear kernel approximation.arXiv preprint arXiv:2410.16893, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.