Hierarchical Online Prompt Mutation with Dual-Loop Feedback for Guardrailed Evidence Document Generation: A Production-Evaluation Case Study
Pith reviewed 2026-06-28 16:08 UTC · model grok-4.3
The pith
HOPM, a hierarchical online prompt mutation framework with dual feedback, raises evidence document win rates by 11 percentage points and quality scores by 1.22 points over static prompting in a 600-case production ablation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
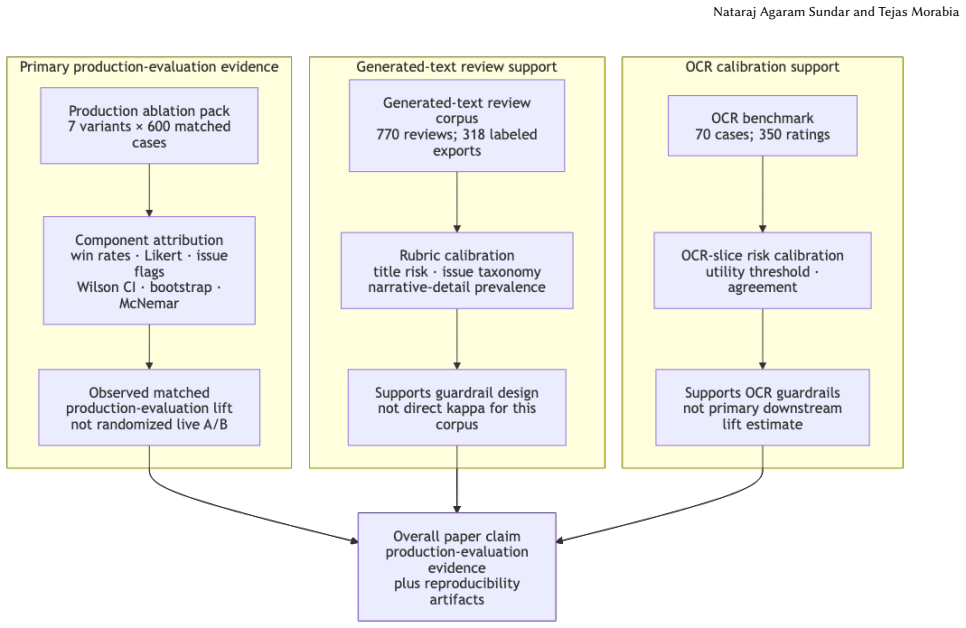
Full HOPM improves count win rate over a static control from 34.7% to 45.7% (+11.0 pp; paired McNemar p = 1.31e-11) and amount-weighted win rate from 22.3% to 41.4% (+19.1 pp; 95% paired bootstrap CI [10.3, 28.9] pp). It also increases mean Likert quality from 3.18 to 4.40 and reduces issue-flag rate from 15.3% to 5.2%. The evaluation uses a matched production ablation across seven variants on 600 cases.
What carries the argument
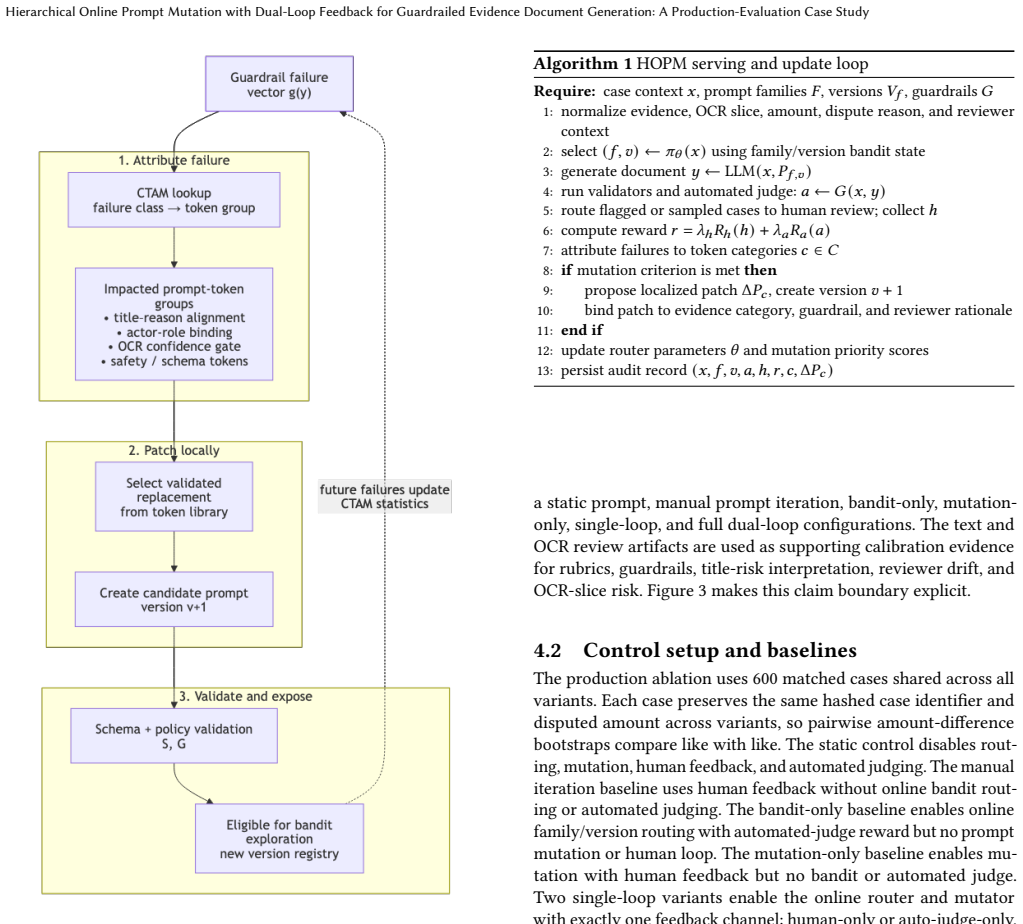
HOPM, the hierarchical online prompt mutation framework, which routes prompt families and versions, uses deterministic guardrails to attribute failures to mutable prompt-token categories, and applies dual feedback from human review and an automated judge to update both routing and mutation priorities.
If this is right
- Full dual-loop HOPM outperforms static prompting, manual iteration, bandit-only routing, mutation-only adaptation, and single-feedback variants on the same cases.
- Guardrail-based failure attribution enables targeted updates to specific prompt-token categories rather than entire prompts.
- The evaluation structure supports reproduction through provided pseudocode, schemas, rubrics, and guardrail taxonomies.
- Higher quality scores and fewer flags indicate improved auditability for evidence document generation in production.
Where Pith is reading between the lines
- The dual-loop structure could extend to other evidence-grounded generation tasks that require both adaptability and traceability.
- Ongoing mutation with feedback may reduce the frequency of full manual prompt overhauls in deployed systems.
- Pairing human and automated signals offers a way to trade off review cost against coverage in continuous monitoring.
Load-bearing premise
The 600 cases and the human-plus-automated judge feedback accurately represent ongoing production distribution and failure modes, such that improvements observed in the ablation will persist when the system is deployed without further manual recalibration of the guardrail taxonomy or router priorities.
What would settle it
Re-running the full ablation on a fresh set of 600 production cases collected after deployment would show no statistically significant improvement in win rates or quality if the claim does not hold.
Figures

read the original abstract
High-stakes production document-generation systems require language models to be adaptive, evidence-grounded, and auditable. We present HOPM, a hierarchical online prompt mutation framework evaluated on a real marketplace dispute-evidence workflow. HOPM treats prompts as online policies: a family/version router selects a prompt, deterministic guardrails attribute failures to mutable prompt-token categories, and dual feedback from human review and an automated judge updates both routing and mutation priorities. The primary evidence is an observed matched production-evaluation ablation: seven variants are evaluated on the same 600 cases each, enabling component comparisons against static prompting, manual iteration, bandit-only routing, mutation-only adaptation, human-only feedback, auto-judge-only feedback, and full dual-loop HOPM. Full HOPM improves count win rate over a static control from 34.7% to 45.7% (+11.0 pp; paired McNemar p = 1.31e-11) and amount-weighted win rate from 22.3% to 41.4% (+19.1 pp; 95% paired bootstrap CI [10.3, 28.9] pp). It also increases mean Likert quality from 3.18 to 4.40 and reduces issue-flag rate from 15.3% to 5.2%. Supporting review artifacts cover 770 generated-text reviews, 318 labeled reviewer exports, a 10-case/61-rating calibration slice, and a 70-case/350-rating OCR benchmark; these artifacts calibrate rubric, guardrail, title-risk, and OCR-risk interpretation rather than substituting for the production ablation. The paper includes control setup, sample sizes, confidence intervals, paired tests, prompt-token categories, pseudocode, schema, rubric, guardrail taxonomy, and a constructed example so the evaluation structure can be reproduced without exposing proprietary evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HOPM, a hierarchical online prompt mutation framework with dual-loop feedback (human review plus automated judge) for adaptive, guardrailed evidence document generation in a real marketplace dispute-evidence workflow. It reports a matched ablation across seven variants (static control, manual iteration, bandit-only, mutation-only, human-only, auto-judge-only, and full dual-loop HOPM) evaluated on the identical set of 600 cases, with full HOPM yielding a count win-rate increase from 34.7% to 45.7% (paired McNemar p=1.31e-11), amount-weighted win-rate increase from 22.3% to 41.4% (95% paired bootstrap CI [10.3, 28.9] pp), mean Likert quality rise from 3.18 to 4.40, and issue-flag rate drop from 15.3% to 5.2%. Supporting artifacts include 770 reviews, 318 labeled exports, calibration slices, an OCR benchmark, pseudocode, schemas, rubrics, and guardrail taxonomy.
Significance. If the reported ablation results hold, the work supplies a concrete, production-grounded demonstration of online policy adaptation for high-stakes LLM document generation, with explicit statistical controls and reproducibility aids. Credit is due for the matched design on fixed case sets, paired McNemar and bootstrap analyses, explicit calibration artifacts that support rubric and guardrail interpretation, and the inclusion of pseudocode, taxonomies, and a constructed example that permits reproduction of the evaluation structure without proprietary data exposure.
minor comments (3)
- [Abstract] Abstract: the seven-variant ablation is described at a high level; a one-sentence clarification of how 'bandit-only routing' differs from 'mutation-only adaptation' in the router/mutation priority update would improve immediate readability.
- The manuscript states that the 600 cases plus guardrail taxonomy capture the live failure-mode distribution; adding a short paragraph (e.g., in Discussion or Limitations) on monitoring signals that would trigger manual recalibration would address the transferability question without altering the case-study framing.
- The 10-case/61-rating calibration slice and 70-case/350-rating OCR benchmark are mentioned as supporting artifacts; explicitly cross-referencing each to the specific metric or guardrail claim it calibrates would reduce any residual ambiguity.
Simulated Author's Rebuttal
We thank the referee for their positive summary, recognition of the matched ablation design, statistical controls, and reproducibility artifacts, and for recommending minor revision. No major comments were listed in the report.
Circularity Check
No circularity: empirical ablation results are direct measurements
full rationale
The paper reports observed win rates, Likert scores, and issue rates from a fixed 600-case production ablation comparing seven prompt variants. These are measured quantities with paired statistical tests (McNemar, bootstrap CI) on the same cases; no equations, fitted parameters, or predictions are derived that reference the target metrics by construction. The evaluation structure (guardrail taxonomy, router, dual feedback) is described as setup for the ablation rather than a self-referential derivation. No self-citation load-bearing steps or ansatz smuggling appear in the reported chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Peter Auer, Nicolò Cesa-Bianchi, and Paul Fischer. 2002. Finite-time analysis of the multiarmed bandit problem.Machine Learning47, 2–3 (2002), 235–256
2002
-
[2]
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 2022. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, Vol. 33. 1877–1901
2020
-
[4]
Jacob Cohen. 1960. A coefficient of agreement for nominal scales.Educational and Psychological Measurement20, 1 (1960), 37–46
1960
-
[5]
Jacob Cohen. 1968. Weighted kappa: nominal scale agreement provision for scaled disagreement or partial credit.Psychological Bulletin70, 4 (1968), 213–220
1968
-
[6]
Tibshirani
Bradley Efron and Robert J. Tibshirani. 1993.An Introduction to the Bootstrap. Chapman and Hall/CRC
1993
-
[7]
Joseph L. Fleiss. 1971. Measuring nominal scale agreement among many raters. Psychological Bulletin76, 5 (1971), 378–382
1971
-
[8]
2020.Trustworthy Online Controlled Experi- ments: A Practical Guide to A/B Testing
Ron Kohavi, Diane Tang, and Ya Xu. 2020.Trustworthy Online Controlled Experi- ments: A Practical Guide to A/B Testing. Cambridge University Press
2020
-
[9]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, Vol. 33. 9459–9474
2020
-
[10]
Schapire
Lihong Li, Wei Chu, John Langford, and Robert E. Schapire. 2010. A contextual- bandit approach to personalized news article recommendation. InProceedings of the 19th International Conference on World Wide Web. 661–670
2010
-
[11]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
-
[12]
In Advances in Neural Information Processing Systems, Vol
Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, Vol. 35. 27730–27744
-
[13]
Thompson
William R. Thompson. 1933. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples.Biometrika25, 3/4 (1933), 285–294
1933
-
[14]
Edwin B. Wilson. 1927. Probable inference, the law of succession, and statistical inference.J. Amer. Statist. Assoc.22, 158 (1927), 209–212
1927
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.