THRD: A Training-Free Multi-Turn Defense Framework for Jailbreak Attacks on Large Language Models
Pith reviewed 2026-06-28 15:03 UTC · model grok-4.3
The pith
THRD defends large language models from multi-turn jailbreaks by tracking risk buildup across conversation turns without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
THRD is the first training-free framework that explicitly models temporal risk accumulation for multi-turn jailbreak defense by integrating a Turn-level Risk Assessor for instantaneous risk, a Historical Context Analyzer for cross-turn escalation, a Response Evaluator for facilitative outputs, and a Decision Module that combines the signals through time-evolving scoring with attenuation-based modulation and trend-aware adjustment.
What carries the argument
The Decision Module's time-evolving scoring mechanism that fuses signals from the other three modules with attenuation and trend-aware adjustment to produce defense decisions.
If this is right
- Reduces attack success rate to 0.2-4.0% against state-of-the-art methods including tree-search and multi-agent collaborative attacks.
- Limits utility degradation to within 1.5% on MMLU and GSM8K across two target models.
- Over 70% of multi-turn attacks first trigger rejection on turn 2 or later.
- Ablation studies show each module contributes non-redundantly and the approach generalizes stably across model architectures.
Where Pith is reading between the lines
- Future safety testing for language models should treat multi-turn trajectories as a required evaluation setting rather than an optional extension.
- The modular structure without training suggests the method could transfer to other sequential interaction settings where harmful patterns build over time.
- Attacks specifically tuned to the scoring rules and attenuation logic could still succeed even if the core modules remain in place.
Load-bearing premise
Safety behavior in multi-turn interactions is trajectory-dependent such that single-turn analysis is insufficient and the four modules combined via time-evolving scoring can capture accumulation without any training.
What would settle it
A new multi-turn jailbreak attack that maintains high success rates against THRD-protected models while the four modules fail to trigger rejection on the accumulated risk signals.
Figures

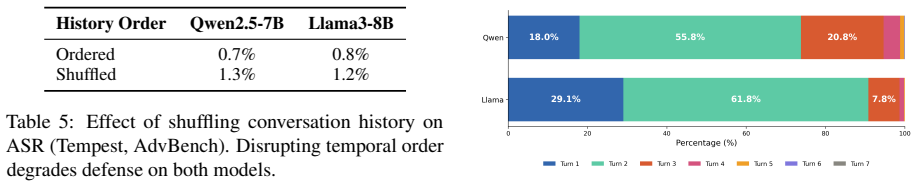
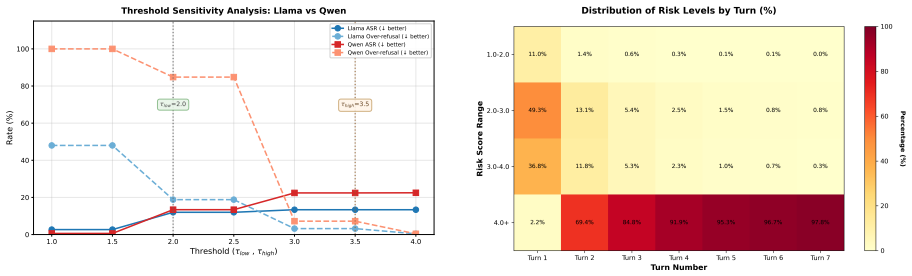
read the original abstract
Multi-turn jailbreak attacks pose a growing threat to LLMs by exploiting conversational dynamics such as gradual escalation and cross-turn coordination. Existing defenses either rely on costly retraining -- often degrading model utility -- or apply single-turn analysis independently at each turn, failing to capture how risk accumulates along interaction trajectories. We observe that safety behavior in multi-turn interaction is trajectory-dependent: dialogue history continuously reshapes the model's conditioning context, making it insufficient to evaluate each turn in isolation. Motivated by this insight, we present THRD, the first training-free framework that explicitly models temporal risk accumulation for multi-turn jailbreak defense. THRD integrates four modules: a Turn-level Risk Assessor (TRA) for instantaneous risk estimation, a Historical Context Analyzer (HCA) for cross-turn intent escalation detection, a Response Evaluator (RE) for identifying facilitative outputs, and a Decision Module that combines these signals through a time-evolving scoring mechanism with attenuation-based modulation and trend-aware adjustment. Experiments against state-of-the-art multi-turn attacks -- including tree-search-based and multi-agent collaborative methods -- across two target models show that THRD reduces ASR to 0.2--4.0% while preserving model utility within 1.5% degradation on MMLU and GSM8K. Ablation studies confirm non-redundant module contributions and stable cross-architecture generalization. Analysis of first rejection triggers reveals that over 70% of multi-turn attacks require Turn~2 or later to detect, validating the necessity of explicit temporal aggregation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces THRD, a training-free multi-turn defense framework for jailbreak attacks on LLMs. Motivated by the observation that safety behavior is trajectory-dependent, it integrates four modules—Turn-level Risk Assessor (TRA), Historical Context Analyzer (HCA), Response Evaluator (RE), and a Decision Module using time-evolving scoring with attenuation-based modulation and trend-aware adjustment—to model risk accumulation across turns. Experiments on state-of-the-art multi-turn attacks (including tree-search and multi-agent methods) across two target models report ASR reduced to 0.2–4.0% with <1.5% utility degradation on MMLU and GSM8K; ablations confirm non-redundant contributions, stable cross-architecture generalization, and that >70% of attacks require Turn 2 or later for detection.
Significance. If the empirical results hold, the work would be significant for LLM safety: it supplies the first explicit training-free mechanism for temporal risk aggregation in multi-turn settings, addressing a gap left by single-turn defenses and retraining-based methods. The reported low ASR, minimal utility impact, ablation evidence for module necessity, and cross-architecture results would constitute a practical and generalizable contribution.
major comments (2)
- [Abstract] Abstract: the central empirical claim (ASR reduced to 0.2–4.0% with <1.5% utility degradation on MMLU/GSM8K) is stated with specific numbers but without reference to any experimental section, table, baseline list, attack implementations, or statistical details, making it impossible to assess whether the data support the claim. This is load-bearing for the paper's primary contribution.
- [Abstract] Abstract (Decision Module description): the time-evolving scoring mechanism with attenuation-based modulation and trend-aware adjustment is described only at a high level; no equations, pseudocode, or parameter definitions are supplied, preventing verification that the four modules combined via this rule actually capture accumulation without training or that the ablation results isolate non-redundant contributions.
minor comments (1)
- [Abstract] The abstract would benefit from naming the two target models and the exact SOTA attack families used, even at high level, to allow immediate context for the reported ASR range.
Simulated Author's Rebuttal
We thank the referee for these constructive comments focused on the abstract. Both points identify areas where the abstract can be strengthened for better verifiability while remaining concise. We will revise the abstract accordingly in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (ASR reduced to 0.2–4.0% with <1.5% utility degradation on MMLU/GSM8K) is stated with specific numbers but without reference to any experimental section, table, baseline list, attack implementations, or statistical details, making it impossible to assess whether the data support the claim. This is load-bearing for the paper's primary contribution.
Authors: We agree that explicit pointers improve the abstract's utility. In the revision we will append concise references (e.g., “as detailed in Section 4, Tables 1–2, and the attack suite described in Section 4.1”) immediately after the reported ASR and utility figures, while preserving the abstract’s length limit. revision: yes
-
Referee: [Abstract] Abstract (Decision Module description): the time-evolving scoring mechanism with attenuation-based modulation and trend-aware adjustment is described only at a high level; no equations, pseudocode, or parameter definitions are supplied, preventing verification that the four modules combined via this rule actually capture accumulation without training or that the ablation results isolate non-redundant contributions.
Authors: The abstract intentionally remains high-level. The full equations, pseudocode, and parameter definitions for the Decision Module appear in Section 3.4. We will revise the abstract to add an explicit cross-reference (“see Section 3.4 for the time-evolving scoring equations”) so readers can locate the technical details that substantiate the training-free accumulation claim and the ablation results. revision: yes
Circularity Check
No significant circularity
full rationale
The abstract presents THRD as motivated by an observed insight on trajectory dependence, with four modules combined via a time-evolving scoring rule. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Central claims rest on empirical ASR reduction and utility preservation, which are externally falsifiable. The derivation is self-contained against benchmarks with no load-bearing step reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Safety behavior in multi-turn interaction is trajectory-dependent, making single-turn analysis insufficient
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[2]
34th USENIX Security Symposium (USENIX Security 25) , pages=
Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack , author=. 34th USENIX Security Symposium (USENIX Security 25) , pages=
-
[3]
Derail yourself: Multi-turn llm jailbreak attack through self-discovered clues , author=
-
[4]
2025 , url=
Andy Zhou and Ron Arel , booktitle=. 2025 , url=
2025
-
[5]
Reasoning-Augmented Conversation for Multi-Turn Jailbreak Attacks on Large Language Models
Ying, Zonghao and Zhang, Deyue and Jing, Zonglei and Xiao, Yisong and Zou, Quanchen and Liu, Aishan and Liang, Siyuan and Zhang, Xiangzheng and Liu, Xianglong and Tao, Dacheng. Reasoning-Augmented Conversation for Multi-Turn Jailbreak Attacks on Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.1865...
-
[6]
Second Conference on Language Modeling , year=
X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents , author=. Second Conference on Language Modeling , year=
-
[7]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[8]
International Conference on Machine Learning , pages=
Pretraining language models with human preferences , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[9]
Advances in Neural Information Processing Systems , volume=
Backdooralign: Mitigating fine-tuning based jailbreak attack with backdoor enhanced safety alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
SDGO : Self-Discrimination-Guided Optimization for Consistent Safety in Large Language Models
Ding, Peng and Sun, Wen and Li, Dailin and Zou, Wei and Wang, Jiaming and Chen, Jiajun and Huang, Shujian. SDGO : Self-Discrimination-Guided Optimization for Consistent Safety in Large Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.253
-
[11]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
MetaDefense: Defending Fine-tuning based Jailbreak Attack Before and During Generation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[12]
Why Not Act on What You Know? Unleashing Safety Potential of LLM s via Self-Aware Guard Enhancement
Ding, Peng and Kuang, Jun and Wang, ZongYu and Cao, Xuezhi and Cai, Xunliang and Chen, Jiajun and Huang, Shujian. Why Not Act on What You Know? Unleashing Safety Potential of LLM s via Self-Aware Guard Enhancement. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.325
-
[13]
arXiv preprint arXiv:2509.26345 , year=
SafeBehavior: Simulating Human-Like Multistage Reasoning to Mitigate Jailbreak Attacks in Large Language Models , author=. arXiv preprint arXiv:2509.26345 , year=
-
[14]
arXiv preprint arXiv:2508.14128 , year=
CCFC: Core & Core-Full-Core Dual-Track Defense for LLM Jailbreak Protection , author=. arXiv preprint arXiv:2508.14128 , year=
-
[15]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[16]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[17]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[18]
Forty-first International Conference on Machine Learning , year=
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal , author=. Forty-first International Conference on Machine Learning , year=
-
[19]
arXiv preprint arXiv:2307.15043 , year=
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
-
[20]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[21]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Xstest: A test suite for identifying exaggerated safety behaviours in large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[22]
SafeDecoding: Defending against jailbreak attacks via safety-aware decoding
Xu, Zhangchen and Jiang, Fengqing and Niu, Luyao and Jia, Jinyuan and Lin, Bill Yuchen and Poovendran, Radha. S afe D ecoding: Defending against Jailbreak Attacks via Safety-Aware Decoding. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.303
-
[23]
Training language models to follow instructions with human feedback , url =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F and Leike, Jan and Lowe,...
-
[24]
2025 , url=
Introducing GPT-5 , author=. 2025 , url=
2025
-
[25]
2025 , url=
Introducing Claude 4 , author=. 2025 , url=
2025
-
[26]
arXiv preprint arXiv:2209.07858 , year=
Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned , author=. arXiv preprint arXiv:2209.07858 , year=
-
[27]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[28]
Mitigating the alignment tax of RLHF
Lin, Yong and Lin, Hangyu and Xiong, Wei and Diao, Shizhe and Liu, Jianmeng and Zhang, Jipeng and Pan, Rui and Wang, Haoxiang and Hu, Wenbin and Zhang, Hanning and Dong, Hanze and Pi, Renjie and Zhao, Han and Jiang, Nan and Ji, Heng and Yao, Yuan and Zhang, Tong. Mitigating the Alignment Tax of RLHF. Proceedings of the 2024 Conference on Empirical Methods...
-
[29]
Conference on Parsimony and Learning (Proceedings Track) , year=
Investigating the Catastrophic Forgetting in Multimodal Large Language Model Fine-Tuning , author=. Conference on Parsimony and Learning (Proceedings Track) , year=
-
[30]
2024 , url=
Baseline Defenses for Adversarial Attacks Against Aligned Language Models , author=. 2024 , url=
2024
-
[31]
SELF - GUARD : Empower the LLM to Safeguard Itself
Wang, Zezhong and Yang, Fangkai and Wang, Lu and Zhao, Pu and Wang, Hongru and Chen, Liang and Lin, Qingwei and Wong, Kam-Fai. SELF - GUARD : Empower the LLM to Safeguard Itself. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:...
-
[32]
arXiv preprint arXiv:2310.06387 , year=
Jailbreak and guard aligned language models with only few in-context demonstrations , author=. arXiv preprint arXiv:2310.06387 , year=
-
[33]
arXiv preprint arXiv:2510.05052 , year=
Proactive defense against LLM Jailbreak , author=. arXiv preprint arXiv:2510.05052 , year=
-
[34]
arXiv preprint arXiv:2410.10014 , year=
Safety-aware fine-tuning of large language models , author=. arXiv preprint arXiv:2410.10014 , year=
-
[35]
Wang, Jiongxiao and Li, Jiazhao and Li, Yiquan and Qi, Xiangyu and Hu, Junjie and Li, Yixuan and McDaniel, Patrick and Chen, Muhao and Li, Bo and Xiao, Chaowei , booktitle =. BackdoorAlign: Mitigating Fine-tuning based Jailbreak Attack with Backdoor Enhanced Safety Alignment , url =. doi:10.52202/079017-0169 , editor =
-
[36]
arXiv preprint arXiv:2305.13860 , year=
Jailbreaking chatgpt via prompt engineering: An empirical study , author=. arXiv preprint arXiv:2305.13860 , year=
-
[37]
do anything now
" do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models , author=. Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , pages=
2024
-
[38]
Ding, Peng and Kuang, Jun and Ma, Dan and Cao, Xuezhi and Xian, Yunsen and Chen, Jiajun and Huang, Shujian. A Wolf in Sheep ' s Clothing: Generalized Nested Jailbreak Prompts can Fool Large Language Models Easily. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies ...
-
[39]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models , url =
Liu, Xiaogeng and Xu, Nan and Chen, Muhao and Xiao, Chaowei , booktitle =. AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models , url =
-
[40]
2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=
Jailbreaking black box large language models in twenty queries , author=. 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=. 2025 , organization=
2025
-
[41]
arXiv preprint arXiv:2309.10253 , year=
Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts , author=. arXiv preprint arXiv:2309.10253 , year=
-
[42]
Neurips Safe Generative AI Workshop 2024 , year=
DeepInception: Hypnotize Large Language Model to Be Jailbreaker , author=. Neurips Safe Generative AI Workshop 2024 , year=
2024
-
[43]
Ren, Qibing and Gao, Chang and Shao, Jing and Yan, Junchi and Tan, Xin and Lam, Wai and Ma, Lizhuang. C ode A ttack: Revealing Safety Generalization Challenges of Large Language Models via Code Completion. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.679
-
[44]
2025 , eprint=
ARMOR: Aligning Secure and Safe Large Language Models via Meticulous Reasoning , author=. 2025 , eprint=
2025
-
[45]
Xiaogeng Liu and Nan Xu and Muhao Chen and Chaowei Xiao , booktitle=. Auto. 2024 , url=
2024
-
[46]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.