LayerRoute: Input-Conditioned Adaptive Layer Skipping via LoRA Fine-Tuning for Agentic Language Models
Pith reviewed 2026-06-28 14:38 UTC · model grok-4.3
The pith
LayerRoute adds per-layer routers and LoRA adapters so agentic models skip more transformer blocks on tool calls than on planning steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
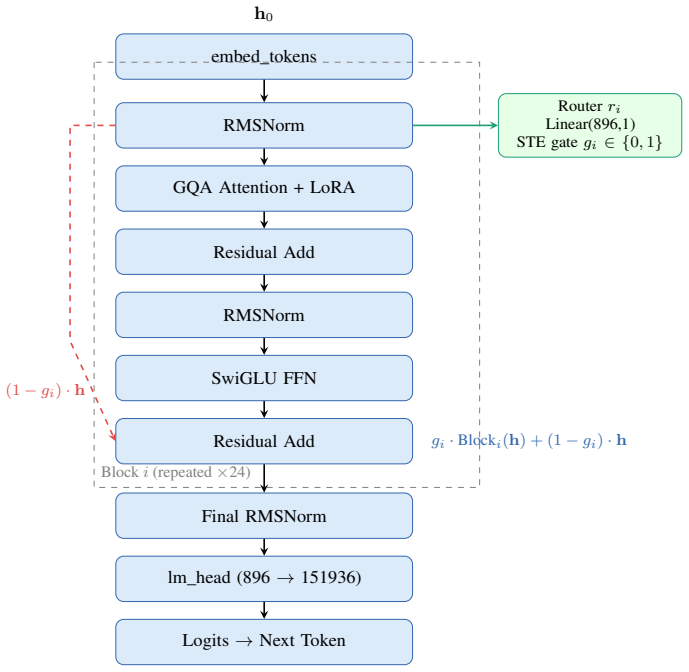
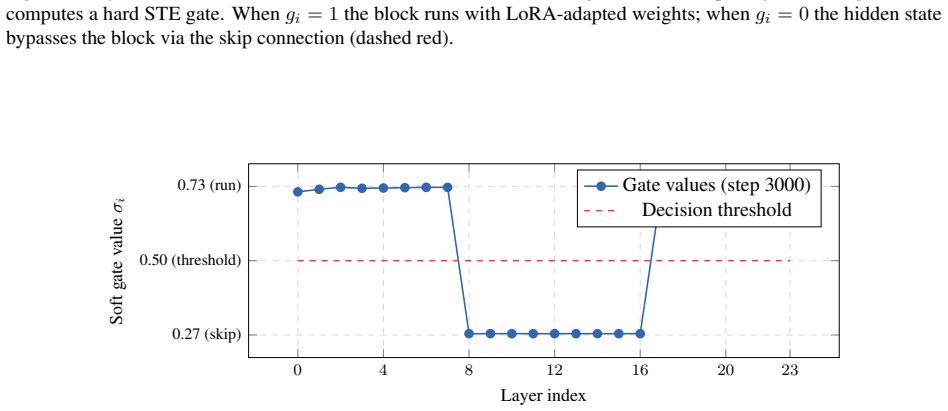
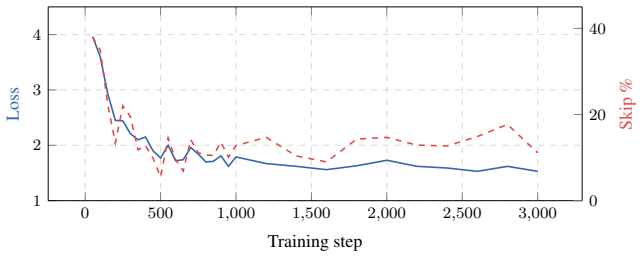
LayerRoute augments each of the 24 transformer blocks in Qwen2.5-0.5B-Instruct with a per-layer router that outputs a hard binary gate via the straight-through estimator and LoRA adapters on the Q/K/V/O attention projections. A single end-to-end training pass on agentic data with a gate regularisation term forces the system to discover which blocks are skippable per input type. After 3,000 steps, LayerRoute achieves a 12.91% skip differential with tool calls skipping 15.25% of FLOPs while planning steps skip only 2.34%, using 1.10M trainable parameters, and quality improves with perplexity deltas of -1.29 and -1.30 respectively.
What carries the argument
Per-layer router (~897 parameters) that outputs a hard binary gate via straight-through estimator, paired with rank-8 LoRA adapters (~1.08M parameters total) on attention projections, allowing the frozen backbone to skip blocks selectively based on input type.
If this is right
- Tool calls skip 15.25% of FLOPs while planning steps skip only 2.34%.
- Only 1.10M parameters need training, 0.22% of the 494M backbone.
- Perplexity improves by 1.29 points on tool calls and 1.30 points on planning steps.
- The differential skipping emerges after 3000 training steps on the agentic datasets.
Where Pith is reading between the lines
- Applying the same router design to larger agentic models could produce larger absolute savings on tool-calling workloads.
- The learned skip patterns might transfer to other step-type distinctions beyond tool calls and planning.
- Further regularization or auxiliary losses could be tested to increase the skip differential without harming quality.
Load-bearing premise
That training the routers end-to-end on the agentic datasets will produce skipping decisions that depend on input type and generalize beyond the training distribution rather than being driven only by the LoRA adapters.
What would settle it
Running the trained LayerRoute model on a fresh collection of agentic tasks and measuring whether the skip rate remains substantially higher for tool calls than for planning steps.
Figures

read the original abstract
Agentic language model systems alternate between two structurally distinct step types: structured tool calls (short, deterministic, low perplexity) and open-ended planning/reasoning steps (long, complex, high perplexity). Despite this heterogeneity, current inference systems apply identical compute to every step. We introduce LayerRoute, a lightweight adapter that learns to selectively skip transformer blocks on a per-input basis. LayerRoute augments each of the 24 transformer blocks in Qwen2.5-0.5B-Instruct with: (1) a per-layer router (~897 parameters, Linear(896,1)) that outputs a hard binary gate via the straight-through estimator, and (2) LoRA adapters (rank 8, ~1.08M parameters) on the Q/K/V/O attention projections. The backbone weights remain frozen. A single end-to-end training pass on agentic data (Hermes, Glaive, GSM8K, Turing) with a gate regularisation term forces the system to discover which blocks are skippable per input type. After 3,000 steps (6.4 minutes on an A100 40GB), LayerRoute achieves a 12.91% skip differential: tool calls skip 15.25% of FLOPs while planning steps skip only 2.34%, using only 1.10M trainable parameters (0.22% of the 494M backbone). Quality improves over the base model due to LoRA adaptation, with perplexity delta of -1.29 on tool calls and -1.30 on planning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LayerRoute, which augments each of the 24 blocks in Qwen2.5-0.5B-Instruct with a per-layer router (Linear(896,1) with straight-through estimator for hard binary gates) and LoRA adapters (rank 8) on attention projections. A single end-to-end training run on agentic datasets (Hermes, Glaive, GSM8K, Turing) with an unspecified gate regularization term is claimed to produce input-type-specific skipping, yielding a 12.91% skip differential (15.25% FLOPs skipped on tool calls vs. 2.34% on planning steps) after 3000 steps while using 1.10M trainable parameters (0.22% of the backbone) and improving perplexity by approximately -1.3 on both step types.
Significance. If the reported differential is shown to arise from learned input-conditioned policies rather than training artifacts or LoRA alone, the method would offer a practical, low-overhead route to heterogeneous compute allocation in agentic systems. The small parameter budget and short training time (6.4 min on A100) are concrete strengths of the presented design.
major comments (3)
- [Abstract] Abstract: the central claim of a 12.91% input-type-specific skip differential rests on aggregate FLOPs percentages alone; no per-input gate statistics, per-layer activation histograms, or within-category variance are supplied to demonstrate that routers produce statistically different decisions for tool-call versus planning inputs rather than a fixed or length-correlated pattern.
- [Abstract] Abstract: no ablation isolating the routers from the LoRA adapters is described, nor are baselines, error bars, or statistical tests provided for the perplexity deltas (-1.29 / -1.30); without these it is impossible to attribute quality gains or skipping behavior to the proposed mechanism.
- [Abstract] Abstract: the gate regularization term is invoked to force discovery of skippable blocks but its exact form, coefficient, and any sensitivity analysis are unspecified, leaving the mechanism that produces the reported differential unexamined.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which identify key areas where additional evidence is required to substantiate the input-conditioned nature of the skipping behavior. We address each major comment below and will incorporate revisions to provide the requested analyses, ablations, and specifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 12.91% input-type-specific skip differential rests on aggregate FLOPs percentages alone; no per-input gate statistics, per-layer activation histograms, or within-category variance are supplied to demonstrate that routers produce statistically different decisions for tool-call versus planning inputs rather than a fixed or length-correlated pattern.
Authors: We agree that aggregate FLOP percentages alone are insufficient to establish input-conditioned routing. In the revised manuscript we will add per-input gate activation rates (with standard deviations across samples), per-layer skip histograms separated by input type, and a controlled analysis showing the differential persists after matching for sequence length. These statistics were computed from the existing training runs and will be reported to demonstrate that the routers learn distinct policies rather than fixed or length-driven patterns. revision: yes
-
Referee: [Abstract] Abstract: no ablation isolating the routers from the LoRA adapters is described, nor are baselines, error bars, or statistical tests provided for the perplexity deltas (-1.29 / -1.30); without these it is impossible to attribute quality gains or skipping behavior to the proposed mechanism.
Authors: We acknowledge the absence of isolating ablations and statistical support. The revision will include a new ablation table comparing (i) LoRA only, (ii) routers only, and (iii) the combined LayerRoute model. Perplexity results will be reported with error bars from three independent runs and accompanied by paired t-tests to establish significance of the observed deltas. This will allow clearer attribution of effects to the router mechanism. revision: yes
-
Referee: [Abstract] Abstract: the gate regularization term is invoked to force discovery of skippable blocks but its exact form, coefficient, and any sensitivity analysis are unspecified, leaving the mechanism that produces the reported differential unexamined.
Authors: The referee is correct that the regularization term requires explicit specification. We will expand the methods section to state the precise formulation (an L1 penalty on the expected gate activation), the coefficient value employed during the 3000-step training, and a sensitivity plot varying the coefficient to verify that the 12.91% skip differential remains stable. These details will be added to the revised manuscript. revision: yes
Circularity Check
No circularity; results are empirical training outcomes
full rationale
The manuscript describes an end-to-end training procedure on agentic datasets that produces observed skip rates and perplexity deltas after 3000 steps. No equations, first-principles derivations, or load-bearing self-citations are present that reduce the reported 12.91% differential or per-input-type behavior to fitted constants or prior author results by construction. The central claims rest on measured post-training statistics rather than any self-referential prediction step.
Axiom & Free-Parameter Ledger
free parameters (1)
- gate regularization coefficient
axioms (1)
- domain assumption The straight-through estimator supplies usable gradients for training the binary skip gates.
invented entities (1)
-
per-layer router (Linear(896,1))
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
[Bengio et al.(2013)] Bengio, Y ., Léonard, N., and Courville, A. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432,
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[2]
FlashAttention: Fast and memory-efficient exact attention with IO-awareness.NeurIPS,
7 [Dao et al.(2022)] Dao, T., Fu, D., Ermon, S., Rudra, A., and Ré, C. FlashAttention: Fast and memory-efficient exact attention with IO-awareness.NeurIPS,
2022
-
[3]
Transformer feed-forward layers are key-value memories.EMNLP,
[Geva et al.(2021)] Geva, M., Schuster, R., Berant, J., and Levy, O. Transformer feed-forward layers are key-value memories.EMNLP,
2021
-
[4]
J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., and Chen, W
[Hu et al.(2022)] Hu, E. J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., and Chen, W. LoRA: Low-rank adaptation of large language models.ICLR,
2022
-
[5]
H., Gonzalez, J., Zhang, H., and Stoica, I
[Kwon et al.(2023)] Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C. H., Gonzalez, J., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with PagedAttention.SOSP,
2023
-
[6]
Fast inference from transformers via speculative decoding.ICML,
[Leviathan et al.(2023)] Leviathan, Y ., Kalman, M., and Matias, Y . Fast inference from transformers via speculative decoding.ICML,
2023
-
[7]
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
[Raposo et al.(2024)] Raposo, D., Ritter, S., Richards, B., Lillicrap, T., Humphreys, P. C., and Santoro, A. Mixture- of-depths: Dynamically allocating compute in transformer language models.arXiv preprint arXiv:2404.02258,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Toolformer: Language models can teach themselves to use tools.NeurIPS,
[Schick et al.(2023)] Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., and Scialom, T. Toolformer: Language models can teach themselves to use tools.NeurIPS,
2023
-
[9]
SkipBERT: Efficient inference with shallow layer skipping.ACL,
[Tang et al.(2023)] Tang, J., Wang, Q., Zhang, Y ., Wei, F., and Huang, X. SkipBERT: Efficient inference with shallow layer skipping.ACL,
2023
-
[10]
DeeBERT: Dynamic early exiting for accelerating BERT inference.ACL,
[Xin et al.(2020)] Xin, J., Tang, R., Lee, J., Yu, Y ., and Lin, J. DeeBERT: Dynamic early exiting for accelerating BERT inference.ACL,
2020
-
[11]
ReAct: Synergizing reasoning and acting in language models.ICLR,
[Yao et al.(2023)] Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y . ReAct: Synergizing reasoning and acting in language models.ICLR,
2023
-
[12]
BERT loses patience: Fast and robust inference with early exit.NeurIPS,
[Zhou et al.(2020)] Zhou, W., Xu, C., Ge, T., McAuley, J., Xu, K., and Wei, F. BERT loses patience: Fast and robust inference with early exit.NeurIPS,
2020
-
[13]
AgenticQwen: Training small language models for agentic tasks.arXiv preprint,
[Alibaba(2026)] Alibaba Cloud. AgenticQwen: Training small language models for agentic tasks.arXiv preprint,
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.