InfoMerge: Information-aware Token Compression for Efficient Video Large Language Models
Pith reviewed 2026-06-28 15:03 UTC · model grok-4.3
The pith
InfoMerge reduces visual tokens in video LLMs by 85 percent while retaining 98.8 percent of original performance through segment-level redundancy estimation and entropy-driven allocation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
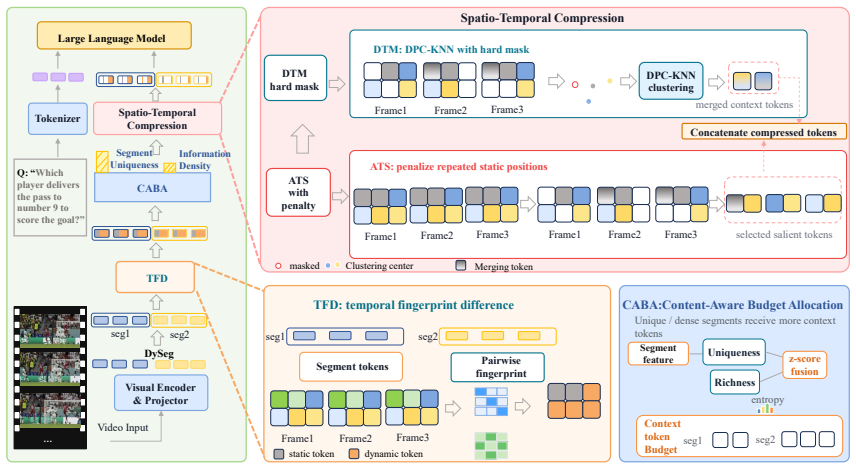
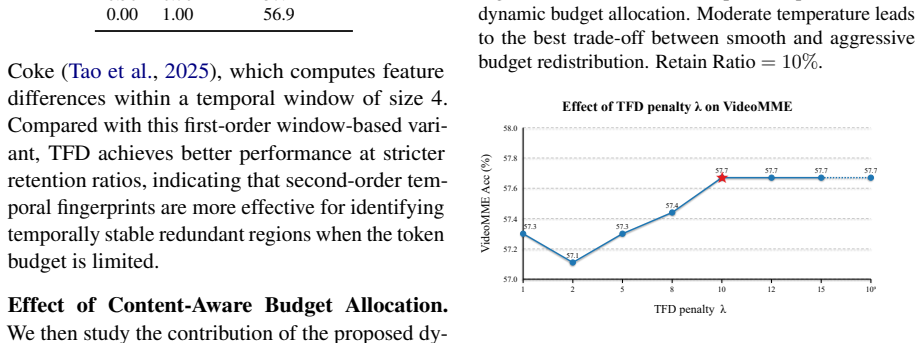
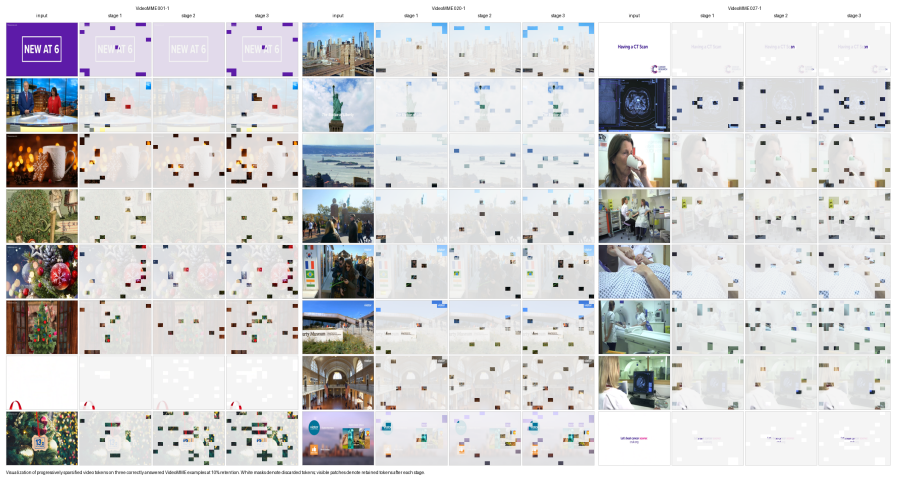
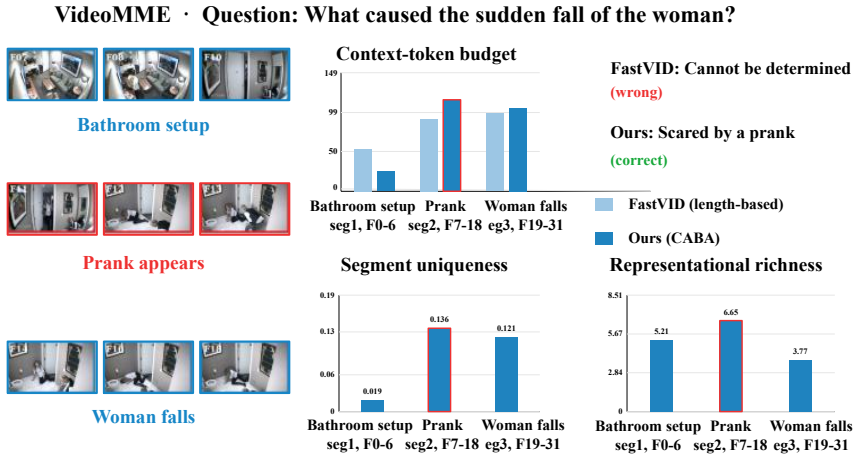
InfoMerge is a training-free method that first computes Temporal Fingerprint Difference within each video segment to capture how tokens at the same spatial locations change over time in a second-order sense, then applies Content-Aware Budget Allocation that scores segments by their spectral-entropy richness and uniqueness so that more tokens are kept in informative parts and fewer in static or repeated regions. On LLaVA-OneVision-7B this yields 85 percent token reduction, 4.24 times faster prefill, and 98.8 percent retention of average benchmark performance, with the gains widening at aggressive compression rates across multiple backbones.
What carries the argument
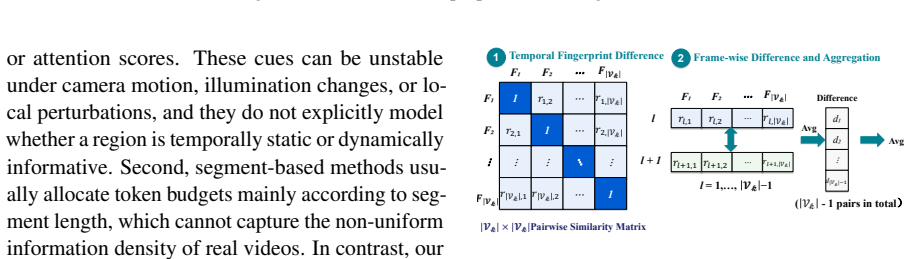
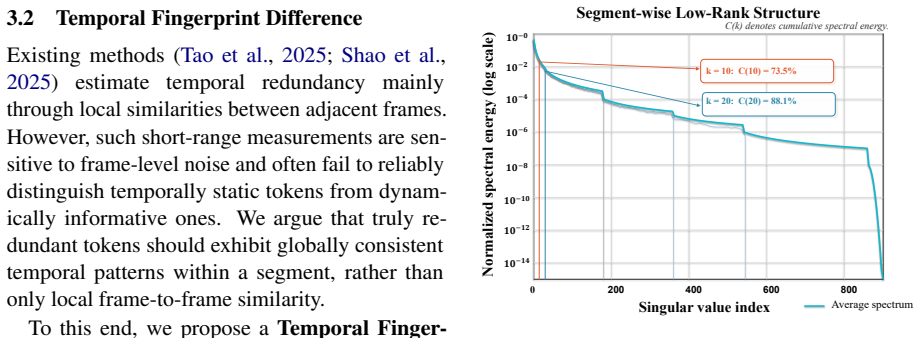
Temporal Fingerprint Difference, a segment-level second-order temporal redundancy estimator that models similarity structure of same-position tokens across frames inside each segment, paired with Content-Aware Budget Allocation that distributes token quotas by spectral-entropy representational richness and segment uniqueness.
If this is right
- Under 85 percent token reduction the method still keeps 98.8 percent average accuracy on standard video-understanding benchmarks.
- Prefill-stage inference speeds up by a factor of 4.24 on the 7B LLaVA-OneVision backbone.
- Advantages become larger when the allowed token budget is made even smaller.
- The same compression pipeline transfers to other Video-LLM backbones without retraining.
Where Pith is reading between the lines
- The same fingerprint-plus-entropy logic could be applied to compress audio tokens in multimodal models that handle both video and sound.
- If the method scales, real-time video chat systems could process minute-long clips on consumer GPUs without dropping frames.
- The approach suggests that information-aware allocation might also improve efficiency when compressing image tokens inside static vision-language models.
Load-bearing premise
That segment-level second-order fingerprint differences and spectral-entropy scores give a reliable, noise-resistant measure of information content that works across videos and model backbones without any extra tuning.
What would settle it
A controlled test set of videos where static background noise is added that changes pixel values but leaves semantic content unchanged; if InfoMerge then drops performance more sharply than length-based or frame-similarity baselines, the redundancy estimator is not robust.
Figures

read the original abstract
Video Large Language Models (Video-LLMs) achieve strong performance in video understanding, but their excessive visual tokens bring substantial computational overhead. Existing training-free compression methods improve inference efficiency by reducing visual tokens, yet they often rely on local adjacent-frame similarity for temporal redundancy estimation or allocate token budgets mainly according to segment length. Such designs are sensitive to frame-level noise and fail to capture the non-uniform information distribution of real-world videos. To address these challenges, we propose InfoMerge, a training-free visual token compression method that improves token utilization through robust redundancy estimation and content-aware budget allocation. Specifically, we propose the Temporal Fingerprint Difference: a segment-level second-order temporal redundancy estimation strategy, which models the temporal similarity structure of tokens at the same spatial positions within each segment. We further introduce Content-Aware Budget Allocation (CABA), which dynamically allocates segment-level token budgets based on segment uniqueness and spectral-entropy-based representational richness. By reducing repeated preservation of redundant static regions and allocating more tokens to informative segments, InfoMerge makes better use of the limited token budget while maintaining strong performance. Extensive experiments show that InfoMerge achieves strong efficiency--accuracy trade-offs across multiple benchmarks and backbones, with more pronounced advantages under aggressive compression. On LLaVA-OneVision-7B, InfoMerge retains 98.8\% of the original average performance while reducing 85\% of visual tokens and achieving a 4.24-fold speedup in the prefill stage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces InfoMerge, a training-free visual token compression method for Video-LLMs. It proposes Temporal Fingerprint Difference, a segment-level second-order temporal redundancy estimator operating on per-position token sequences, and Content-Aware Budget Allocation (CABA) that distributes token budgets according to segment uniqueness combined with spectral-entropy richness. On LLaVA-OneVision-7B the method is reported to retain 98.8% of baseline average performance while discarding 85% of visual tokens and delivering a 4.24-fold prefill speedup.
Significance. If the proposed metrics prove robust, the work would offer a practical, training-free route to higher token efficiency in video understanding models, directly addressing the quadratic cost of long visual sequences. The emphasis on non-uniform information distribution and the absence of any learned parameters are positive features.
major comments (2)
- [Abstract and §3] Abstract and §3 (method description): the central performance claim (98.8% retention at 85% reduction) rests on the assumption that segment-level second-order Temporal Fingerprint Difference and spectral-entropy CABA reliably quantify information content; no ablation isolating sensitivity to camera motion, lighting variation, or encoder-specific token statistics is presented, leaving the robustness assumption load-bearing and untested.
- [§4] §4 (experiments): the reported benchmarks are confined to standard video QA and captioning suites; cross-backbone or cross-domain tests that would verify whether the second-order fingerprint and entropy metrics generalize without model-specific calibration are absent, directly affecting the generalization statement.
minor comments (2)
- Table captions should explicitly state the number of runs and any variance reported for the 98.8% retention figure.
- Notation for the second-order difference operator should be introduced with a short equation in §3.1 rather than only in prose.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of our metrics' robustness and generalization. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): the central performance claim (98.8% retention at 85% reduction) rests on the assumption that segment-level second-order Temporal Fingerprint Difference and spectral-entropy CABA reliably quantify information content; no ablation isolating sensitivity to camera motion, lighting variation, or encoder-specific token statistics is presented, leaving the robustness assumption load-bearing and untested.
Authors: We agree that dedicated ablations isolating sensitivity to camera motion, lighting variation, and encoder-specific token statistics would strengthen the robustness claims for Temporal Fingerprint Difference and CABA. While the second-order design of the fingerprint metric is intended to reduce sensitivity to first-order perturbations such as lighting changes by modeling per-position temporal similarity structures, this remains an assumption without direct testing. We will add a new ablation subsection in the revised §4 with controlled experiments on videos exhibiting varying motion speeds, lighting conditions, and across different visual encoders to directly address this concern. revision: yes
-
Referee: [§4] §4 (experiments): the reported benchmarks are confined to standard video QA and captioning suites; cross-backbone or cross-domain tests that would verify whether the second-order fingerprint and entropy metrics generalize without model-specific calibration are absent, directly affecting the generalization statement.
Authors: The manuscript already reports results across multiple backbones (as noted in the abstract and §4) to support applicability beyond a single model. However, we acknowledge that the current experiments do not include explicit cross-domain tests on non-standard video distributions or direct verification that the metrics require no model-specific calibration. We will expand the experimental section with additional cross-backbone and cross-domain results in the revision to better substantiate the generalization statement. revision: partial
Circularity Check
No circularity: new metrics and allocation are defined independently of results
full rationale
The paper defines Temporal Fingerprint Difference as a segment-level second-order difference on per-position token sequences and CABA as a dynamic allocation using uniqueness plus spectral entropy; neither quantity is fitted to the target performance metric nor derived from a self-citation chain. The 98.8% retention claim is an empirical outcome on benchmarks, not a quantity that reduces to the input definitions by construction. No load-bearing self-citation, ansatz smuggling, or renaming of known results appears in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world videos exhibit non-uniform information distribution across segments and are sensitive to frame-level noise in local similarity measures.
Reference graph
Works this paper leans on
-
[3]
Science China Information Sciences , volume=
Videochat: Chat-centric video understanding , author=. Science China Information Sciences , volume=. 2025 , publisher=
2025
-
[7]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Visionzip: Longer is better but not necessary in vision language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[8]
European Conference on Computer Vision , pages=
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[9]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Dycoke: Dynamic compression of tokens for fast video large language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[10]
Advances in Neural Information Processing Systems , volume=
Fastvid: Dynamic density pruning for fast video large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
D ^2 Pruner: Debiased Importance and Structural Diversity for MLLM Token Pruning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Mmg-vid: Maximizing marginal gains at segment-level and token-level for efficient video llms , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[15]
2007 15th European signal processing conference , pages=
The effective rank: A measure of effective dimensionality , author=. 2007 15th European signal processing conference , pages=. 2007 , organization=
2007
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Vila: On pre-training for visual language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Nvila: Efficient frontier visual language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[21]
International Conference on Learning Representations , volume=
Tempme: Video temporal token merging for efficient text-video retrieval , author=. International Conference on Learning Representations , volume=
-
[22]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Prunevid: Visual token pruning for efficient video large language models , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[23]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
-
[24]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mvbench: A comprehensive multi-modal video understanding benchmark , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mlvu: Benchmarking multi-task long video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
Advances in Neural Information Processing Systems , volume=
Longvideobench: A benchmark for long-context interleaved video-language understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[29]
Lmms-eval: Accelerating the development of large multimoal models , volume=
Xinrun du, yuhao dong, haotian liu, yuanhan zhang, ge zhang, chunyuan li, and ziwei liu , author=. Lmms-eval: Accelerating the development of large multimoal models , volume=
-
[30]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Lmms-eval: Reality check on the evaluation of large multimodal models , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[31]
IEEE transactions on pattern analysis and machine intelligence , volume=
On perfect clustering of high dimension, low sample size data , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2019 , publisher=
2019
-
[32]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, and 1 others. 2025. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. 2022. Token merging: Your vit but faster. arXiv preprint arXiv:2210.09461
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. 2024. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In European Conference on Computer Vision, pages 19--35. Springer
2024
-
[35]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and 1 others. 2024. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [36]
-
[37]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, and 1 others. 2025. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108--24118
2025
-
[38]
Xiaohu Huang, Hao Zhou, and Kai Han. 2025. Prunevid: Visual token pruning for efficient video large language models. In Findings of the Association for Computational Linguistics: ACL 2025, pages 19959--19973
2025
-
[39]
Bo Li. 2024. Xinrun du, yuhao dong, haotian liu, yuanhan zhang, ge zhang, chunyuan li, and ziwei liu. Lmms-eval: Accelerating the development of large multimoal models, 6
2024
-
[40]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and 1 others. 2024 a . Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. 2024 b . Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. 2025. Videochat: Chat-centric video understanding. Science China Information Sciences, 68(10):200102
2025
-
[43]
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. 2024. Vila: On pre-training for visual language models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26689--26699
2024
-
[44]
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, and 1 others. 2025. Nvila: Efficient frontier visual language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4122--4134
2025
-
[45]
Junpeng Ma, Qizhe Zhang, Ming Lu, Zhibin Wang, Qiang Zhou, Jun Song, and Shanghang Zhang. 2026. Mmg-vid: Maximizing marginal gains at segment-level and token-level for efficient video llms. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 24253--24261
2026
-
[46]
Soham Sarkar and Anil K Ghosh. 2019. On perfect clustering of high dimension, low sample size data. IEEE transactions on pattern analysis and machine intelligence, 42(9):2257--2272
2019
- [47]
-
[48]
Leqi Shen, Guoqiang Gong, Tao He, Yifeng Zhang, Pengzhang Liu, Sicheng Zhao, and 1 others. 2026. Fastvid: Dynamic density pruning for fast video large language models. Advances in Neural Information Processing Systems, 38:123553--123581
2026
-
[49]
Leqi Shen, Tianxiang Hao, Tao He, Sicheng Zhao, Yifeng Zhang, Yongjun Bao, Guiguang Ding, and 1 others. 2025. Tempme: Video temporal token merging for efficient text-video retrieval. In International Conference on Learning Representations, volume 2025, pages 60839--60860
2025
-
[50]
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. 2025. Dycoke: Dynamic compression of tokens for fast video large language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 18992--19001
2025
-
[51]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30
2017
-
[52]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, and 1 others. 2024. Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, and 1 others. 2025. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. 2024. Longvideobench: A benchmark for long-context interleaved video-language understanding. Advances in Neural Information Processing Systems, 37:28828--28857
2024
-
[55]
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. 2025. Visionzip: Longer is better but not necessary in vision language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19792--19802
2025
-
[56]
Evelyn Zhang, Fufu Yu, Aoqi Wu, Zichen Wen, Ke Yan, Shouhong Ding, Biqing Qi, and Linfeng Zhang. 2026. D ^2 pruner: Debiased importance and structural diversity for mllm token pruning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 12412--12420
2026
-
[57]
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, and 1 others. 2025. Lmms-eval: Reality check on the evaluation of large multimodal models. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 881--916
2025
-
[58]
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. 2024. Llava-video: Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, and 1 others. 2025. Mlvu: Benchmarking multi-task long video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13691--13701
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.