AgentCL: Toward Rigorous Evaluation of Continual Learning in Language Agents
Pith reviewed 2026-06-28 14:50 UTC · model grok-4.3
The pith
Controlled compositional streams distinguish memory plasticity in language agents where naive streams fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
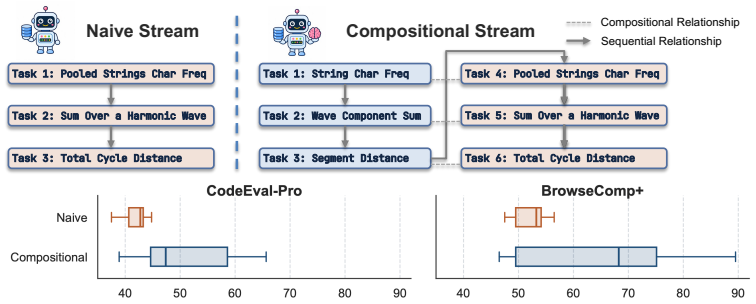
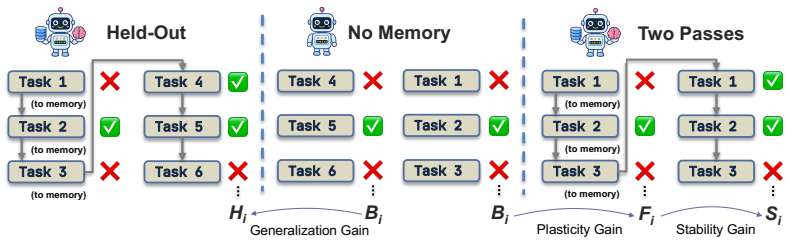
AgentCL constructs compositional streams where sub-solutions from earlier tasks are reusable in later ones and shows through empirical analysis that these streams distinguish memory designs' plasticity and stable reuse more effectively than naive streams, which often yield limited gains and can reveal memory-induced degradation.
What carries the argument
Compositional task streams that intentionally link reusable sub-solutions across tasks, together with the MemProbe method that stores interactions, insights, and skills while filtering unreliable experiences during consolidation.
If this is right
- Memory designs must balance the capacity to incorporate new experiences with the stable retention of reusable prior workflows.
- Non-parametric memories can be diagnosed for consolidation failures by tracking which experiences are retained or filtered.
- Benchmarks that rely only on naive or held-out task sequences are likely to underestimate both the potential and the risks of continual learning.
- Stronger memory mechanisms are needed that maintain reuse without interference when tasks share substructure.
Where Pith is reading between the lines
- Adoption of controlled streams could shift agent training toward explicit modeling of workflow reuse rather than isolated task performance.
- The same construction method might be extended to multi-turn conversations or embodied environments where sub-skills recur.
- If the streams generalize, they could serve as a diagnostic for whether current large language models already exhibit implicit continual learning or require external memory.
Load-bearing premise
The intentionally constructed compositional streams accurately capture the cross-task reusability relationships that arise in real agent usage.
What would settle it
A memory design that shows identical transfer gains and degradation rates on both controlled compositional streams and naive streams would falsify the claim that controlled streams are required to distinguish plasticity.
Figures


read the original abstract
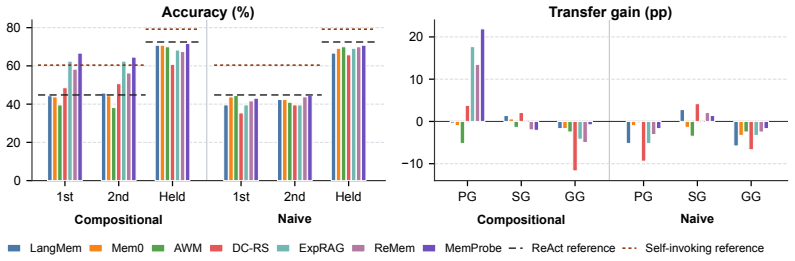
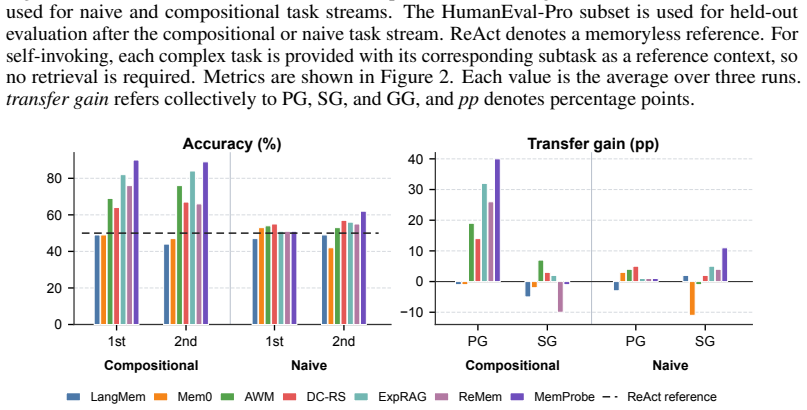
Language agents spend substantial inference time solving individual tasks, yet the experience acquired in one episode is often underutilized in future episodes. Continual learning expects an agent to accumulate reusable experience across a stream of tasks, improve over time, and avoid interference from irrelevant experiences. Unfortunately, existing benchmarks struggle to evaluate continual learning in language agents rigorously. Most efforts focus on retrieval and reasoning over long-context conversations or documents, while recent lifelong-adaptation benchmarks often rely on naive task streams with limited analysis of cross-task relationships, making it difficult to understand what an agent learns and reuses over time. This paper presents an evaluation framework AgentCL for continual learning in agents, centered on controlled task streams and metrics for transfer gains. AgentCL constructs compositional streams where earlier sub-solutions, evidence, or workflows are intentionally reusable in later tasks, and contrasts them with naive streams where such reusability is not guaranteed. We use the benchmark to evaluate non-parametric memory designs for continual learning. To diagnose how memory design choices affect continual learning, we develop MemProbe, a probing method that stores interactions, insights, and skills, while filtering unreliable experiences during consolidation. Empirical analysis across coding, deep research, and language understanding/reasoning tasks shows that naive streams offer limited ability to distinguish memory designs, whereas controlled streams more clearly distinguish their plasticity. Meanwhile, naive and held-out settings often yield limited gains and can expose memory-induced degradation. These results highlight the need for stronger memory designs that balance plasticity and stable reuse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the AgentCL evaluation framework for continual learning in language agents. It constructs controlled compositional task streams in which earlier sub-solutions, evidence, or workflows are deliberately reusable in later tasks, contrasts these with naive streams lacking guaranteed reusability, and evaluates non-parametric memory designs via a new MemProbe probing method that stores interactions, insights, and skills while filtering unreliable experiences. Empirical results across coding, deep research, and language tasks indicate that controlled streams distinguish memory plasticity more clearly than naive streams, while naive and held-out settings often produce limited gains or memory-induced degradation, motivating stronger memory designs that balance plasticity and stable reuse.
Significance. If the engineered reusability relationships in the controlled streams correspond to cross-task structure that arises in deployed agents, the framework would supply a more diagnostic benchmark than existing naive lifelong-adaptation suites and could guide development of memory mechanisms that accumulate reusable experience without interference. The introduction of MemProbe as a diagnostic tool for memory consolidation is a concrete methodological contribution that could be adopted more broadly.
major comments (2)
- [Benchmark construction] Benchmark construction (Abstract and the section describing controlled compositional streams): the central claim that controlled streams 'more clearly distinguish' memory plasticity rests on the streams being deliberately engineered for reusability; without an independent validation (e.g., comparison against naturally occurring task sequences from real agent logs or a quantitative measure of how well the engineered overlaps match observed reuse patterns), the reported superiority of controlled streams over naive streams remains conditional on the benchmark's internal construction rather than demonstrating a more rigorous or realistic evaluation.
- [Empirical analysis] Empirical analysis (the section reporting results on naive vs. controlled streams): the abstract states that 'naive streams offer limited ability to distinguish memory designs' and that 'naive and held-out settings often yield limited gains and can expose memory-induced degradation,' yet the provided abstract supplies no quantitative metrics, error bars, statistical tests, or exclusion criteria; if the full manuscript likewise lacks these details or does not report effect sizes for the plasticity distinctions, the load-bearing empirical contrast cannot be verified.
minor comments (1)
- [Abstract] The abstract refers to 'non-parametric memory designs' and 'MemProbe' without a brief parenthetical definition or pointer to the methods section; adding one sentence would improve accessibility for readers unfamiliar with the specific memory variants under test.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below, clarifying our design choices and empirical reporting while outlining planned revisions.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (Abstract and the section describing controlled compositional streams): the central claim that controlled streams 'more clearly distinguish' memory plasticity rests on the streams being deliberately engineered for reusability; without an independent validation (e.g., comparison against naturally occurring task sequences from real agent logs or a quantitative measure of how well the engineered overlaps match observed reuse patterns), the reported superiority of controlled streams over naive streams remains conditional on the benchmark's internal construction rather than demonstrating a more rigorous or realistic evaluation.
Authors: The core contribution of AgentCL is a controlled evaluation framework that deliberately engineers known reusability relationships to isolate and diagnose memory plasticity effects, which naive streams do not permit. This design choice enables clearer distinctions in our experiments precisely because overlaps are measurable and intentional, supporting rigorous analysis of transfer versus interference. We do not claim equivalence to real-world logs; rather, the framework provides a diagnostic benchmark for memory mechanisms. We will add explicit discussion of this motivation and its trade-offs in the introduction and a new limitations subsection. revision: partial
-
Referee: [Empirical analysis] Empirical analysis (the section reporting results on naive vs. controlled streams): the abstract states that 'naive streams offer limited ability to distinguish memory designs' and that 'naive and held-out settings often yield limited gains and can expose memory-induced degradation,' yet the provided abstract supplies no quantitative metrics, error bars, statistical tests, or exclusion criteria; if the full manuscript likewise lacks these details or does not report effect sizes for the plasticity distinctions, the load-bearing empirical contrast cannot be verified.
Authors: The full manuscript reports quantitative results across tasks, including performance deltas, error bars from multiple runs, and statistical comparisons in the empirical analysis section. The abstract summarizes findings at a high level due to space limits. We will revise the abstract to include representative quantitative metrics and effect sizes for the controlled versus naive distinctions. revision: yes
Circularity Check
No significant circularity; empirical benchmark evaluation is self-contained
full rationale
The paper introduces AgentCL as an evaluation framework that explicitly constructs compositional task streams with engineered reusability and contrasts them against naive streams. It then reports empirical results from running memory designs on these streams, showing clearer distinctions in plasticity for controlled streams. No equations, fitted parameters, or derivations are present that reduce claims to self-definition or input renaming. The central distinction follows directly from the transparent benchmark construction and external experimental outcomes rather than any load-bearing self-citation or ansatz. This matches the default case of a non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
Sandhini Agarwal et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
Pith/arXiv arXiv 2025
-
[2]
Memorybench: A benchmark for memory and continual learning in LLM systems.CoRR, abs/2510.17281, 2025
Qingyao Ai, Yichen Tang, Changyue Wang, Jianming Long, Weihang Su, and Yiqun Liu. Memorybench: A benchmark for memory and continual learning in LLM systems.CoRR, abs/2510.17281, 2025
Pith/arXiv arXiv 2025
-
[3]
Gonzalez
Parth Asawa, Chris Glaze, Gabe Orlanski, Ramya Ramakrishnan, Benji Xu, Asim Biswal, Vincent Sunn Chen, Frederic Sala, Matei Zaharia, and Joseph E. Gonzalez. Continual learn- ing bench. https://continual-learning-bench.com/docs/, 2026. Documentation, accessed 2026-05-04
2026
-
[4]
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, Sahel Sharifymoghaddam, Yanxi Li, Haoran Hong, Xinyu Shi, Xuye Liu, Nandan Thakur, Crystina Zhang, Luyu Gao, Wenhu Chen, and Jimmy Lin. Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent.CoRR, a...
arXiv 2025
-
[5]
Mem0: Building production-ready AI agents with scalable long-term memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory. In Inês Lynce, Nello Murano, Mauro Vallati, Serena Villata, Federico Chesani, Michela Milano, Andrea Omicini, and Mehdi Dastani, editors,ECAI 2025 - 28th European Conference on Artificial Intelligence, 25-...
2025
-
[6]
A survey of self-evolving agents: What, when, how, and where to evolve on the path to artificial super intelligence.Trans
Huan-ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Qihan Ren, Yiran Wu, Hongru Wang, Han Xiao, Yuhang Zhou, Shaokun Zhang, Jiayi Zhang, Jinyu Xiang, Yixiong Fang, Qiwen Zhao, Dongrui Liu, Cheng Qian, Zhenhailong Wang, Minda Hu, Huazheng Wang, Qingyun Wu, Heng Ji, and Mengdi Wang. A survey of se...
2026
-
[7]
Yuanzhe Hu, Yu Wang, and Julian J. McAuley. Evaluating memory in LLM agents via incremental multi-turn interactions.CoRR, abs/2507.05257, 2025. 10
Pith/arXiv arXiv 2025
-
[8]
Swe-bench-cl: Continual learning for coding agents.CoRR, abs/2507.00014, 2025
Thomas Joshi, Shayan Chowdhury, and Fatih Uysal. Swe-bench-cl: Continual learning for coding agents.CoRR, abs/2507.00014, 2025
arXiv 2025
-
[9]
Langmem, 2026
LangChain AI. Langmem, 2026. GitHub repository
2026
-
[10]
Agentboard: An analytical evaluation board of multi-turn LLM agents
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. Agentboard: An analytical evaluation board of multi-turn LLM agents. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Syst...
2024
-
[11]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thaila...
2024
-
[12]
Introducing gpt-5.2
OpenAI. Introducing gpt-5.2. https://openai.com/index/introducing-gpt-5-2/ , De- cember 2025
2025
-
[13]
Qwen3.5-35b-a3b
Qwen Team. Qwen3.5-35b-a3b. Hugging Face model card, March 2026
2026
-
[14]
Language agents: Foundations, prospects, and risks
Yu Su, Diyi Yang, Shunyu Yao, and Tao Yu. Language agents: Foundations, prospects, and risks. In Junyi Jessy Li and Fei Liu, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: EMNLP 2024 - Tutorial Abstracts, Miami, Florida, USA, November 12-16, 2024, pages 17–24. Association for Computational Linguistics, 2024
2024
-
[15]
Dynamic cheatsheet: Test-time learning with adaptive memory
Mirac Suzgun, Mert Yüksekgönül, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory. In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors,Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2026 - Volume 1: Long Papers, Rabat, Morocco,...
2026
-
[16]
A comprehensive survey of continual learning: Theory, method and application.IEEE Trans
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE Trans. Pattern Anal. Mach. Intell., 46(8):5362– 5383, 2024
2024
-
[17]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela ...
2024
-
[18]
Agent workflow memory
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025, Proceedings of Machine L...
2025
-
[19]
Browsecomp: A simple yet challenging benchmark for browsing agents.CoRR, abs/2504.12516, 2025
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.CoRR, abs/2504.12516, 2025
Pith/arXiv arXiv 2025
-
[20]
Chi, Chi Wang, Shuo Chen, Fernando Pereira, Wang-Cheng Kang, and Derek Zhiyuan Cheng
Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li, Jingrui He, Ed H. Chi, Chi Wang, Shuo Chen, Fernando Pereira, Wang-Cheng Kang, and Derek Zhiyuan Cheng. Evo-memory: Benchmarking LLM agent test-time learning with self-evolving memory.CoRR, abs/2511.20857, 2025. 11
Pith/arXiv arXiv 2025
-
[21]
Stream- bench: Towards benchmarking continuous improvement of language agents
Cheng-Kuang Wu, Zhi Rui Tam, Chieh-Yen Lin, Yun-Nung Chen, and Hung-yi Lee. Stream- bench: Towards benchmarking continuous improvement of language agents. In Amir Glober- sons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: Annual Confer- ence on...
2024
-
[22]
Long- memeval: Benchmarking chat assistants on long-term interactive memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[23]
OpenReview.net, 2025
2025
-
[24]
Zheng Wu, Xingyu Lou, Xinbei Ma, Yansi Li, Weiwen Liu, Weinan Zhang, Jun Wang, and Zhuosheng Zhang. Agent-dice: Disentangling knowledge updates via geometric consensus for agent continual learning.CoRR, abs/2601.03641, 2026
Pith/arXiv arXiv 2026
-
[25]
A-MEM: agentic memory for LLM agents.CoRR, abs/2502.12110, 2025
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: agentic memory for LLM agents.CoRR, abs/2502.12110, 2025
Pith/arXiv arXiv 2025
-
[26]
Autonomous continual learning of computer-use agents for environment adaptation, 2026
Tianci Xue, Zeyi Liao, Tianneng Shi, Zilu Wang, Kai Zhang, Dawn Song, Yu Su, and Huan Sun. Autonomous continual learning of computer-use agents for environment adaptation, 2026
2026
-
[27]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
2023
-
[28]
OpenReview.net, 2023
2023
-
[29]
CGL: advancing continual GUI learning via reinforcement fine-tuning
Zhenquan Yao, Zitong Huang, Yihan Zeng, Jianhua Han, Hang Xu, Chun-Mei Feng, Jianwei Ma, and Wangmeng Zuo. CGL: advancing continual GUI learning via reinforcement fine-tuning. CoRR, abs/2603.02951, 2026
arXiv 2026
-
[30]
Humaneval pro and MBPP pro: Evaluating large language models on self-invoking code generation task
Zhaojian Yu, Yilun Zhao, Arman Cohan, and Xiaoping Zhang. Humaneval pro and MBPP pro: Evaluating large language models on self-invoking code generation task. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025,...
2025
-
[31]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embed- ding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
Pith/arXiv arXiv 2025
-
[32]
Lifelongagentbench: Evaluating LLM agents as lifelong learners.CoRR, abs/2505.11942, 2025
Junhao Zheng, Xidi Cai, Qiuke Li, Duzhen Zhang, Zhong-Zhi Li, Yingying Zhang, Le Song, and Qianli Ma. Lifelongagentbench: Evaluating LLM agents as lifelong learners.CoRR, abs/2505.11942, 2025. 12 Appendix Contents A Limitations 14 B Experimental Setting and Details 14 B.1 Examples of Compositionality . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.