AFUN: Towards an Affordance Foundation Model for Functionality Understanding
Pith reviewed 2026-06-28 14:11 UTC · model grok-4.3
The pith
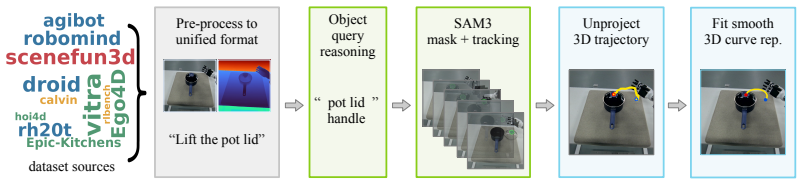
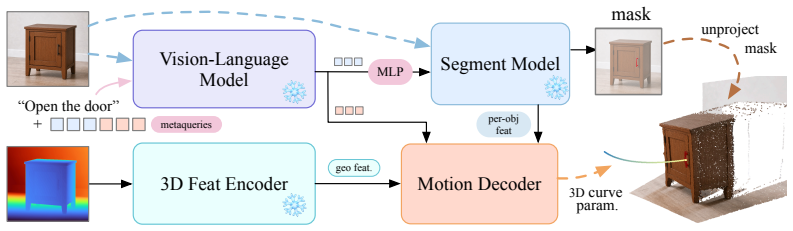
AFUN predicts task-conditional functional masks and 3D post-contact motion curves from one RGB-D view plus language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
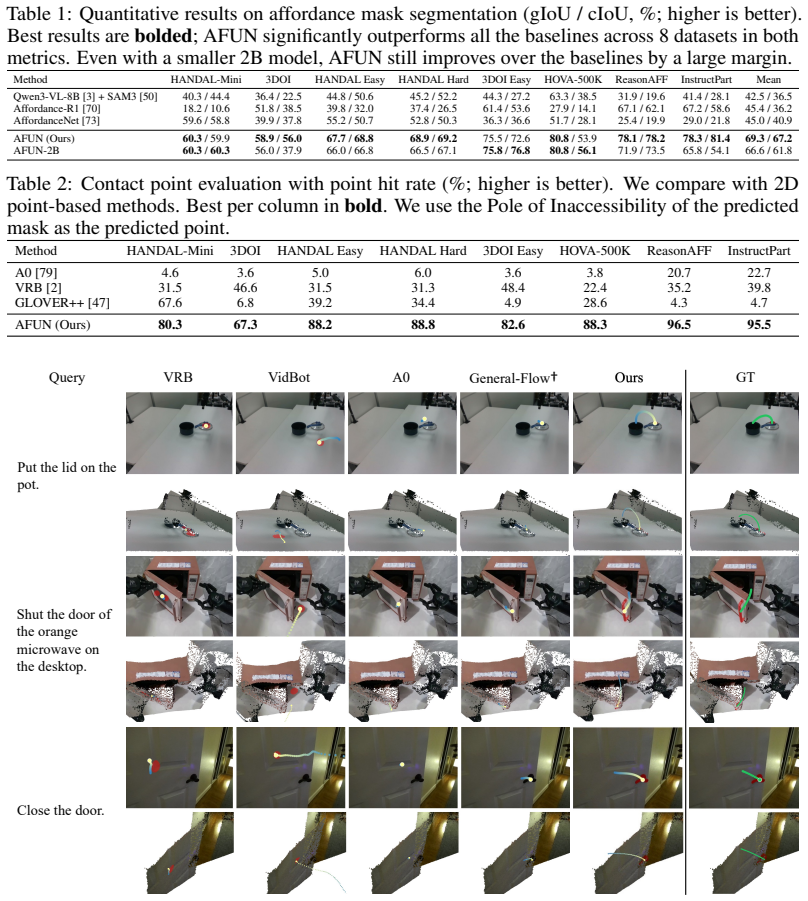
From a single RGB-D observation and a language task description, AFUN outputs a task-conditional functional mask that marks where interaction should occur and an object-centric 3D post-contact motion curve that specifies how the interaction should proceed. The model is trained on a large-scale data pipeline that converts robot, human, simulation, and scan data into one shared schema of language labels, masks, and 3D motion annotations. On affordance segmentation across eight test sets the model improves mean gIoU and cIoU by 23.9 and 26.3 points over prior methods; it also records higher contact-point hit rates and superior 3D motion accuracy on three separate test collections. The same weig
What carries the argument
Task-conditional functional mask paired with object-centric 3D post-contact motion curve, produced by a model trained on a unified affordance schema that merges heterogeneous data sources.
If this is right
- A single set of weights handles affordance segmentation, contact prediction, and motion forecasting across multiple benchmarks.
- Real-robot manipulation succeeds without per-embodiment retraining or task-specific rules.
- Open-world tasks become feasible because the same model adapts to varied objects and instructions from the unified schema.
- Contact-point accuracy improves by 12.7 to 61.3 percent over the strongest baseline on the evaluated sets.
Where Pith is reading between the lines
- The unified schema could be reused by other researchers to train models that combine affordance output with higher-level planners.
- If the motion curves are accurate enough, they might serve as direct inputs to low-level controllers without intermediate trajectory optimization.
- Extending the pipeline to include more sensor types, such as tactile data, would test whether the same schema remains stable.
- The separation of mask and motion outputs might allow independent debugging or replacement of either component in future systems.
Load-bearing premise
Heterogeneous robot, human, simulation, and scan data can be converted into one consistent set of language, mask, and 3D motion labels that supports generalization without embodiment-specific fine-tuning.
What would settle it
The model fails to produce usable masks or motion curves on a new object category or robot embodiment without any additional training data or fine-tuning.
Figures

















read the original abstract
Affordance understanding bridges visual perception and physical action, serving as an explainable interface for robot manipulation in open and unstructured real-world environments. Yet, building an affordance foundation model that not only understands where and how the interaction should happen, but also generalizes across diverse environments, objects, and tasks, remains a long-standing research challenge. Existing methods typically address only part of this challenge, either localizing task-relevant regions without specifying executable motion, or predicting motion but with limited scalability. In this paper, we present ourmodel, a step towards an affordance foundation model for functionality understanding. From a single RGB-D observation and a language task description, ourmodel predicts a task-conditional functional mask (where to interact) and a 3D post-contact motion curve (how to interact). To support open-world generalization, we build a large-scale standardized data pipeline that converts heterogeneous robot, human, simulation, and real-world scan data into a shared affordance schema with language, masks, and object-centric 3D motion labels. We evaluate ourmodel from three aspects: for affordance segmentation, ourmodel outperforms all baselines by a large margin across 8 test sets from 4 benchmarks, improving mean gIoU/cIoU by +23.9/+26.3; for contact-point prediction, it predicts substantially more accurate points, with a 12.7--61.3% hit-rate gain over the best baseline; and for 3D motion, it achieves the best performance on all three test sets. ourmodel can be deployed for real-world robot manipulation without finetuning for robot embodiment or using task-specific heuristics, demonstrating the ability to adapt to open-world affordance tasks. Project page: https://www.zhaoningwang.com/AFUN
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AFUN, a model that takes a single RGB-D image and language task description as input and outputs a task-conditional functional mask (where to interact) together with a 3D post-contact motion curve (how to interact). A large-scale data pipeline is presented that unifies robot, human, simulation, and real-world scan data into a shared affordance schema with consistent language, mask, and object-centric 3D motion labels. Experiments report large gains over baselines on affordance segmentation (+23.9/+26.3 mean gIoU/cIoU across 8 test sets), contact-point hit-rate (12.7–61.3 % improvement), and 3D motion prediction on three test sets, with zero-shot real-robot deployment claimed.
Significance. If the data pipeline truly yields embodiment-agnostic, consistent functional labels, the work would constitute a meaningful step toward scalable affordance foundation models that jointly address localization and executable motion. The reported cross-benchmark gains and real-world transfer without embodiment-specific fine-tuning would be notable contributions to robot manipulation research.
major comments (2)
- [Data pipeline / Methods] Data pipeline section (exact section number not visible in provided text but referenced in abstract): the central generalization claim rests on the assertion that heterogeneous sources are converted into a shared schema with consistent object-centric 3D motion curves. No quantitative checks (e.g., inter-source variance on matched tasks, alignment error statistics, or ablation removing source-specific normalization) are described, leaving open the possibility that learned representations encode source biases rather than pure functionality.
- [Experiments / Results] Results tables (affordance segmentation and 3D motion sections): while aggregate gains are reported, the manuscript does not provide per-source breakdowns or controls that isolate the contribution of the unified labeling scheme versus model architecture; without these, attribution of the +23.9/+26.3 gIoU/cIoU improvement to the pipeline remains under-supported.
minor comments (2)
- [Abstract] Abstract contains repeated instances of the token "ourmodel" instead of the model name or "AFUN"; this should be corrected for readability.
- [Method] Notation for the 3D motion curve (contact parameterization, coordinate frame, trajectory representation) is introduced but not given an explicit equation or diagram reference in the provided abstract; a clear definition would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the data pipeline and experimental attribution. We address each point below and will revise the manuscript to include the requested quantitative checks and breakdowns.
read point-by-point responses
-
Referee: [Data pipeline / Methods] Data pipeline section (exact section number not visible in provided text but referenced in abstract): the central generalization claim rests on the assertion that heterogeneous sources are converted into a shared schema with consistent object-centric 3D motion curves. No quantitative checks (e.g., inter-source variance on matched tasks, alignment error statistics, or ablation removing source-specific normalization) are described, leaving open the possibility that learned representations encode source biases rather than pure functionality.
Authors: We agree that explicit quantitative validation of cross-source consistency would strengthen the generalization argument. The pipeline enforces a shared schema for language, masks, and object-centric 3D motion, and the large gains across diverse benchmarks provide supporting evidence of effective unification. To directly address the concern, the revised manuscript will add inter-source variance statistics on matched tasks, alignment error metrics, and an ablation removing source-specific normalization steps. revision: yes
-
Referee: [Experiments / Results] Results tables (affordance segmentation and 3D motion sections): while aggregate gains are reported, the manuscript does not provide per-source breakdowns or controls that isolate the contribution of the unified labeling scheme versus model architecture; without these, attribution of the +23.9/+26.3 gIoU/cIoU improvement to the pipeline remains under-supported.
Authors: We thank the referee for this observation. Current tables report aggregate results across eight test sets drawn from four benchmarks to highlight broad applicability. To better isolate the unified labeling scheme from architectural contributions, the revision will add per-source performance breakdowns together with controls that compare the full pipeline against variants trained without the cross-source unification step. revision: yes
Circularity Check
No circularity; empirical model with independent benchmark evaluation
full rationale
The paper presents an empirical ML system: a data pipeline unifies heterogeneous sources into labels, a model is trained to predict masks and motion curves from RGB-D + language, and performance is measured via gIoU/cIoU, hit-rate, and 3D metrics against external baselines on 8 test sets. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described claims. The central results are falsifiable via held-out benchmarks and do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AgiBot-World-Contributors, Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xu Huang, et al. AgiBot World Colosseo: A large- scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
Pith/arXiv arXiv 2025
-
[2]
Affordances from human videos as a versatile representation for robotics
Shikhar Bahl, Russell Mendonca, Lili Chen, Unnat Jain, and Deepak Pathak. Affordances from human videos as a versatile representation for robotics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[3]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
Pith/arXiv arXiv 2025
-
[4]
HOT3D: Hand and object tracking in 3D from egocentric multi-view videos
Prithviraj Banerjee, Sindi Shkodrani, Pierre Moulon, Shreyas Hampali, Shangchen Han, Fan Zhang, Linguang Zhang, Jade Fountain, Edward Miller, Selen Basol, Richard Newcombe, Robert Wang, Jakob Julian Engel, and Tomas Hodan. HOT3D: Hand and object tracking in 3D from egocentric multi-view videos. InProceedings of the IEEE/CVF Conference on Computer Vision a...
2025
-
[5]
Track2Act: Predicting point tracks from internet videos enables generalizable robot manipulation
Homanga Bharadhwaj, Roozbeh Mottaghi, Abhinav Gupta, and Shubham Tulsiani. Track2Act: Predicting point tracks from internet videos enables generalizable robot manipulation. In European Conference on Computer Vision (ECCV). Springer, 2024
2024
-
[6]
Worldafford: Affordance grounding based on natural language instructions
Changmao Chen, Yuren Cong, and Zhen Kan. Worldafford: Affordance grounding based on natural language instructions. In36th IEEE International Conference on Tools with Artificial Intelligence, ICTAI 2024, Herndon, VA, USA, October 28-30, 2024, pages 822–828. IEEE, 2024. doi: 10.1109/ICTAI62512.2024.00120. URL https://doi.org/10.1109/ICTAI62512. 2024.00120
-
[7]
VidBot: Learning generalizable 3D actions from in-the-wild 2D human videos for zero-shot robotic manipulation
Hanzhi Chen, Boyang Sun, Anran Zhang, Marc Pollefeys, and Stefan Leutenegger. VidBot: Learning generalizable 3D actions from in-the-wild 2D human videos for zero-shot robotic manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27661–27672, 2025
2025
-
[8]
G3Flow: Generative 3D semantic flow for pose-aware and generalizable object manipulation
Tianxing Chen, Yao Mu, Zhixuan Liang, Zanxin Chen, Shijia Peng, Qiangyu Chen, Mingkun Xu, Ruizhen Hu, Hongyuan Zhang, Xuelong Li, and Ping Luo. G3Flow: Generative 3D semantic flow for pose-aware and generalizable object manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1735–1744, June 2025
2025
-
[9]
3d-affordancellm: Harnessing large language models for open-vocabulary affordance detection in 3d worlds
Hengshuo Chu, Xiang Deng, Qi Lv, Xiaoyang Chen, Yinchuan Li, Jianye Hao, and Liqiang Nie. 3d-affordancellm: Harnessing large language models for open-vocabulary affordance detection in 3d worlds. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview. net...
2025
-
[10]
GanHand: Predicting human grasp affordances in multi-object scenes
Enric Corona, Albert Pumarola, Guillem Alenya, Francesc Moreno-Noguer, and Grégory Rogez. GanHand: Predicting human grasp affordances in multi-object scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5031–5041, 2020
2020
-
[11]
Rescaling egocentric vision: Collection, pipeline and challenges for EPIC-KITCHENS-100
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Jian Ma, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Rescaling egocentric vision: Collection, pipeline and challenges for EPIC-KITCHENS-100. International Journal of Computer Vision (IJCV), 130(1):33–55, 2022. 11
2022
-
[12]
SceneFun3D: Fine-grained functionality and affordance understanding in 3D scenes
Alexandros Delitzas, Ayça Takmaz, Federico Tombari, Robert Sumner, Marc Pollefeys, and Francis Engelmann. SceneFun3D: Fine-grained functionality and affordance understanding in 3D scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[13]
3d affordancenet: A benchmark for visual object affordance understanding
Shengheng Deng, Xun Xu, Chaozheng Wu, Ke Chen, and Kui Jia. 3d affordancenet: A benchmark for visual object affordance understanding. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2021
2021
-
[14]
Affordancenet: An end-to-end deep learning ap- proach for object affordance detection
Thanh-Toan Do, Anh Nguyen, and Ian Reid. Affordancenet: An end-to-end deep learning ap- proach for object affordance detection. InInternational Conference on Robotics and Automation (ICRA), 2018
2018
-
[16]
FlowBot3D: Learning 3D articulation flow to manipulate articulated objects
Ben Eisner, Harry Zhang, and David Held. FlowBot3D: Learning 3D articulation flow to manipulate articulated objects. InProceedings of Robotics: Science and Systems, New York City, NY , USA, June 2022. doi: 10.15607/RSS.2022.XVIII.018
-
[17]
Hao-Shu Fang, Hongjie Fang, Zhenyu Tang, Jirong Liu, Junbo Wang, Haoyi Zhu, and Cewu Lu. RH20T: A comprehensive robotic dataset for learning diverse skills in one-shot.arXiv preprint arXiv:2307.00595, 2023
arXiv 2023
-
[18]
Hao-Shu Fang, Chenxi Wang, Hongjie Fang, Minghao Gou, Jirong Liu, Hengxu Yan, Wenhai Liu, Yichen Xie, and Cewu Lu. Anygrasp: Robust and efficient grasp perception in spatial and temporal domains.IEEE Transactions on Robotics, 2023. doi: 10.1109/TRO.2023.3281153
-
[19]
Daniel Garcia-Castellanos and Umberto Lombardo. Poles of inaccessibility: A calculation algorithm for the remotest places on earth.Scottish Geographical Journal, 123(3):227–233, September 2007. ISSN 1751-665X. doi: 10.1080/14702540801897809. URL http://dx. doi.org/10.1080/14702540801897809
-
[20]
Gibson.The Ecological Approach to Visual Perception
James J. Gibson.The Ecological Approach to Visual Perception. Houghton Mifflin, 1979
1979
-
[21]
Ego4D: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4D: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18995–19012, 2022
2022
-
[22]
Yifan Han, Yichuan Peng, Pengfei Yi, Junyan Li, Hanqing Wang, Gaojing Zhang, Qi Peng Liu, and Wenzhao Lian. Fsag: Enhancing human-to-dexterous-hand finger-specific affordance grounding via diffusion models, 2026. URLhttps://arxiv.org/abs/2601.08246
arXiv 2026
-
[23]
Xiaoshuai Hao, Yingbo Tang, Lingfeng Zhang, Yanbiao Ma, Yunfeng Diao, Ziyu Jia, Wenbo Ding, Hangjun Ye, and Long Chen. Roboafford++: A generative ai-enhanced dataset for multimodal affordance learning in robotic manipulation and navigation.arXiv preprint arXiv:2511.12436, 2025
arXiv 2025
-
[24]
2handedafforder: Learning precise actionable bimanual affordances from human videos
Marvin Heidinger, Snehal Jauhri, Vignesh Prasad, and Georgia Chalvatzaki. 2handedafforder: Learning precise actionable bimanual affordances from human videos. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 14743–14753, October 2025
2025
-
[25]
Chengkai Hou, Kun Wu, Jiaming Liu, Zhengping Che, Di Wu, Fei Liao, Guangrun Li, Jingyang He, Qiuxuan Feng, Zhao Jin, et al. RoboMIND 2.0: A multimodal, bimanual mobile ma- nipulation dataset for generalizable embodied intelligence.arXiv preprint arXiv:2512.24653, 2025
arXiv 2025
-
[26]
a fer, Andrew Wing Keung To, Kuan-Ho Lao, Murat Cubuktepe, Matthew Haley, Peter B \
Siyuan Huang, Iaroslav Ponomarenko, Zhengkai Jiang, Xiaoqi Li, Xiaobin Hu, Peng Gao, Hongsheng Li, and Hao Dong. Manipvqa: Injecting robotic affordance and physically grounded information into multi-modal large language models. InIEEE/RSJ International Conference 12 on Intelligent Robots and Systems, IROS 2024, Abu Dhabi, United Arab Emirates, October 14-...
-
[27]
Cruise: Cooperative reconstruction and editing in v2x scenarios using gaussian splatting
Yizhou Huang, Fan Yang, Guoliang Zhu, Gen Li, Hao Shi, Yukun Zuo, Wenrui Chen, Zhiyong Li, and Kailun Yang. Resource-efficient affordance grounding with complementary depth and semantic prompts. InIEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2025, Hangzhou, China, October 19-25, 2025, pages 7788–7795. IEEE, 2025. doi: 10.1109/...
-
[28]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J. Davison. RLBench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters (RA-L), 5(2):3019–3026, 2020
2020
-
[29]
INTRA: Interaction relationship-aware weakly supervised affordance grounding
Ji Ha Jang, Hoigi Seo, and Se Young Chun. INTRA: Interaction relationship-aware weakly supervised affordance grounding. InEuropean Conference on Computer Vision (ECCV), pages 18–34. Springer, 2024
2024
-
[30]
Affordancesam: Segment anything once more in affordance grounding, 2025
Dengyang Jiang, Zanyi Wang, Hengzhuang Li, Sizhe Dang, Teli Ma, Wei Wei, Guang Dai, Lei Zhang, and Mengmeng Wang. Affordancesam: Segment anything once more in affordance grounding, 2025. URLhttps://arxiv.org/abs/2504.15650
arXiv 2025
-
[31]
Hanxiao Jiang, Yongsen Mao, Manolis Savva, and Angel X. Chang. OPD: Single-view 3d openable part detection. InEuropean Conference on Computer Vision (ECCV), 2022
2022
-
[32]
Robo- abc: Affordance generalization beyond categories via semantic correspondence for robot manipulation
Yuanchen Ju, Kaizhe Hu, Guowei Zhang, Gu Zhang, Mingrun Jiang, and Huazhe Xu. Robo- abc: Affordance generalization beyond categories via semantic correspondence for robot manipulation. InEuropean Conference on Computer Vision, pages 222–239. Springer, 2024
2024
-
[33]
DROID: A large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. DROID: A large-scale in-the-wild robot manipulation dataset. InProceedings of Robotics: Science and Systems (RSS), 2024. arXiv:2403.12945
Pith/arXiv arXiv 2024
-
[34]
Shamma, Michael S
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Li Fei-Fei. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision (IJCV), 123(1):32–73, 2017
2017
-
[35]
RAM: Retrieval-based affordance transfer for generalizable zero- shot robotic manipulation
Yuxuan Kuang, Junjie Ye, Haoran Geng, Jiageng Mao, Congyue Deng, Leonidas Guibas, He Wang, and Yue Wang. RAM: Retrieval-based affordance transfer for generalizable zero- shot robotic manipulation. InProceedings of The 8th Conference on Robot Learning (CoRL), volume 270 ofProceedings of Machine Learning Research, pages 547–565. PMLR, 2024. URL https://proc...
2024
-
[36]
LISA: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. LISA: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9579–9589, 2024
2024
-
[37]
Locate: Localize and transfer object parts for weakly supervised affordance grounding
Gen Li, Varun Jampani, Deqing Sun, and Laura Sevilla-Lara. Locate: Localize and transfer object parts for weakly supervised affordance grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[38]
Learning precise affordances from egocentric videos for robotic manipulation
Gen Li, Nikolaos Tsagkas, Jifei Song, Ruaridh Mon-Williams, Sethu Vijayakumar, Kun Shao, and Laura Sevilla-Lara. Learning precise affordances from egocentric videos for robotic manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[39]
Locate n’ Rotate: Two-stage openable part detection with geometric foundation model priors
Siqi Li, Xiaoxue Chen, Haoyu Cheng, Guyue Zhou, Hao Zhao, and Guanzhong Tian. Locate n’ Rotate: Two-stage openable part detection with geometric foundation model priors. In Minsu Cho, Ivan Laptev, Du Tran, Angela Yao, and Hongbin Zha, editors,Computer Vision - ACCV 2024 - 17th Asian Conference on Computer Vision, Hanoi, Vietnam, December 8-12, 2024, 13 Pr...
-
[40]
Xiaoqi Li, Mingxu Zhang, Yiran Geng, Haoran Geng, Yuxing Long, Yan Shen, Renrui Zhang, Jiaming Liu, and Hao Dong. Manipllm: Embodied multimodal large language model for object-centric robotic manipulation. InIEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 18061–18070. IEEE, 2024. doi: ...
-
[41]
Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Junhao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[42]
Fast interactive object annotation with Curve-GCN
Huan Ling, Jun Gao, Amlan Kar, Wenzheng Chen, and Sanja Fidler. Fast interactive object annotation with Curve-GCN. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[43]
Joint hand motion and interaction hotspots prediction from egocentric videos
Shaowei Liu, Subarna Tripathi, Somdeb Majumdar, and Xiaolong Wang. Joint hand motion and interaction hotspots prediction from egocentric videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[44]
a fer, Andrew Wing Keung To, Kuan-Ho Lao, Murat Cubuktepe, Matthew Haley, Peter B \
Zhiyang Liu, Ruiteng Zhao, Lei Zhou, Chengran Yuan, Yuwei Wu, Sheng Guo, Zhengshen Zhang, Chenchen Liu, Marcelo H. Ang, and Francis E. H. Tay. 3d affordance keypoint detection for robotic manipulation. InIEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2024, Abu Dhabi, United Arab Emirates, October 14-18, 2024, pages 7528–7534. IE...
-
[45]
Geal: Generalizable 3d affordance learning with cross-modal consistency
Dongyue Lu, Lingdong Kong, Tianxin Huang, and Gim Hee Lee. Geal: Generalizable 3d affordance learning with cross-modal consistency. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1680–1690, June 2025
2025
-
[46]
Learning affordance grounding from exocentric images
Hongchen Luo, Wei Zhai, Jing Zhang, Yang Cao, and Dacheng Tao. Learning affordance grounding from exocentric images. InCVPR, 2022
2022
-
[47]
GLOVER++: Unleashing the potential of affordance learning from human behaviors for robotic manipulation
Teli Ma, Jia Zheng, Zifan Wang, Ziyao Gao, Jiaming Zhou, and Junwei Liang. GLOVER++: Unleashing the potential of affordance learning from human behaviors for robotic manipulation. InProceedings of The 9th Conference on Robot Learning (CoRL), volume 305 ofProceedings of Machine Learning Research, pages 3972–3994. PMLR, 2025. URL https://proceedings. mlr.pr...
2025
-
[48]
Vagnet: Grounding 3d affordance from human-object interactions in videos, 2026
Aihua Mao, Kaihang Huang, Yong-Jin Liu, Chee Seng Chan, and Ying He. Vagnet: Grounding 3d affordance from human-object interactions in videos, 2026. URL https://arxiv.org/ abs/2602.20608
arXiv 2026
-
[49]
CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters (RA-L), 7(3):7327–7334, 2022
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters (RA-L), 7(3):7327–7334, 2022
2022
-
[50]
SAM 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Meta AI Research. SAM 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[51]
Microsoft VITRA Team. VITRA: Scalable vision-language-action model pretraining for robotic manipulation with real-life human activity videos.arXiv preprint arXiv:2510.21571, 2025
arXiv 2025
-
[52]
Where2act: From pixels to actions for articulated 3d objects
Kaichun Mo, Leonidas Guibas, Mustafa Mukadam, Abhinav Gupta, and Shubham Tulsiani. Where2act: From pixels to actions for articulated 3d objects. InInternational Conference on Computer Vision (ICCV), 2021
2021
-
[53]
Teo, Cornelia Fermüller, and Yiannis Aloimonos
Austin Myers, Ching L. Teo, Cornelia Fermüller, and Yiannis Aloimonos. Affordance detection of tool parts from geometric features. InICRA, 2015. 14
2015
-
[55]
Object-based affordances detection with convolutional neural networks and dense conditional random fields
Anh Nguyen, Dimitrios Kanoulas, Darwin G Caldwell, and Nikos G Tsagarakis. Object-based affordances detection with convolutional neural networks and dense conditional random fields. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017
2017
-
[56]
Open-vocabulary affordance detection in 3D point clouds
Toan Nguyen, Minh Nhat Vu, An Vuong, Dzung Nguyen, Thieu V o, Ngan Le, and Anh Nguyen. Open-vocabulary affordance detection in 3D point clouds. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023
2023
-
[57]
Transfer between modalities with MetaQueries.arXiv preprint arXiv:2504.06256, 2025
Xichen Pan, Satya Narayan Shukla, Aashu Singh, Zhuokai Zhao, Shlok Kumar Mishra, Jialiang Wang, Zhiyang Xu, Jiuhai Chen, Kunpeng Li, Felix Juefei-Xu, Ji Hou, and Saining Xie. Transfer between modalities with MetaQueries.arXiv preprint arXiv:2504.06256, 2025
Pith/arXiv arXiv 2025
-
[58]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp 3347–3356
Shengyi Qian, Weifeng Chen, Min Bai, Xiong Zhou, Zhuowen Tu, and Li Erran Li. Affor- dancellm: Grounding affordance from vision language models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024 - Workshops, Seattle, WA, USA, June 17-18, 2024, pages 7587–7597. IEEE, 2024. doi: 10.1109/CVPRW63382.2024.00754. URL https://doi.org/10...
-
[59]
ToolFlowNet: Robotic manipulation with tools via predicting tool flow from point clouds
Daniel Seita, Yufei Wang, Sarthak Shetty, Edward Li, Zackory Erickson, and David Held. ToolFlowNet: Robotic manipulation with tools via predicting tool flow from point clouds. In Conference on Robot Learning (CoRL), 2022
2022
-
[60]
GREAT: Geometry-intention collaborative inference for open-vocabulary 3D object affordance grounding
Yawen Shao, Wei Zhai, Yuhang Yang, Hongchen Luo, Yang Cao, and Zheng-Jun Zha. GREAT: Geometry-intention collaborative inference for open-vocabulary 3D object affordance grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17326–17336, 2025
2025
-
[61]
Xiaohao Sun, Hanxiao Jiang, Manolis Savva, and Angel X. Chang. OPDMulti: Openable part detection for multiple objects. InInternational Conference on 3D Vision, 3DV 2024, Davos, Switzerland, March 18-21, 2024, pages 169–178. IEEE, 2024. doi: 10.1109/3DV62453.2024. 00100. URLhttps://doi.org/10.1109/3DV62453.2024.00100
-
[62]
Masked depth modeling for spatial perception.arXiv preprint arXiv:2601.17895, 2026
Bin Tan, Changjiang Sun, Xiage Qin, Hanat Adai, Zelin Fu, Tianxiang Zhou, Han Zhang, Yinghao Xu, Xing Zhu, Yujun Shen, and Nan Xue. Masked depth modeling for spatial perception.arXiv preprint arXiv:2601.17895, 2026
arXiv 2026
-
[63]
UAD: Unsupervised affordance distillation for generalization in robotic manipulation
Yihe Tang, Wenlong Huang, Yingke Wang, Chengshu Li, Roy Yuan, Ruohan Zhang, Jiajun Wu, and Li Fei-Fei. UAD: Unsupervised affordance distillation for generalization in robotic manipulation. InIEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[64]
Roboafford: A dataset and benchmark for enhancing object and spatial affordance learning in robot ma- nipulation
Yingbo Tang, Lingfeng Zhang, Shuyi Zhang, Yinuo Zhao, and Xiaoshuai Hao. Roboafford: A dataset and benchmark for enhancing object and spatial affordance learning in robot ma- nipulation. InProceedings of the 33rd ACM International Conference on Multimedia, pages 12706–12713, 2025
2025
-
[65]
Cruise: Cooperative reconstruction and editing in v2x scenarios using gaussian splatting
Yingbo Tang, Shuaike Zhang, Xiaoshuai Hao, Pengwei Wang, Jianlong Wu, Zhongyuan Wang, and Shanghang Zhang. Affordgrasp: In-context affordance reasoning for open-vocabulary task- oriented grasping in clutter. InIEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2025, Hangzhou, China, October 19-25, 2025, pages 9433–9439. IEEE, 2025. ...
-
[66]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[67]
URLhttps://qwen.ai/blog?id=qwen3.5
-
[68]
O3afford: One-shot 3d object-to-object affordance grounding for generalizable robotic manipulation
Tongxuan Tian, Xuhui Kang, and Yen-Ling Kuo. O3afford: One-shot 3d object-to-object affordance grounding for generalizable robotic manipulation. 2025. 15
2025
-
[69]
InstructPart: Task-oriented part segmentation with instruction reasoning
Zifu Wan, Yaqi Xie, Ce Zhang, Zhiqiu Lin, Zihan Wang, Simon Stepputtis, Deva Ramanan, and Katia Sycara. InstructPart: Task-oriented part segmentation with instruction reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025
2025
-
[70]
Videoafford: Grounding 3d affordance from human-object-interaction videos via multimodal large language model,
Hanqing Wang, Mingyu Liu, Xiaoyu Chen, Chengwei Ma, Yiming Zhong, Wenti Yin, Yuhao Liu, Zhiqing Cui, Jiahao Yuan, Lu Dai, Zhiyuan Ma, and Hui Xiong. Videoafford: Grounding 3d affordance from human-object-interaction videos via multimodal large language model,
-
[71]
URLhttps://arxiv.org/abs/2602.09638
-
[72]
Affordance-R1: Reinforcement learning for generalizable affordance reasoning in multimodal large language models
Hanqing Wang, Shaoyang Wang, Yiming Zhong, Zemin Yang, Jiamin Wang, Zhiqing Cui, Jiahao Yuan, Yifan Han, Mingyu Liu, and Yuexin Ma. Affordance-R1: Reinforcement learning for generalizable affordance reasoning in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2026
2026
-
[73]
AffordBot: 3D fine-grained embodied reasoning via multimodal large language models
Xinyi Wang, Xun Yang, Yanlong Xu, Yuchen Wu, Zhen Li, and Na Zhao. AffordBot: 3D fine-grained embodied reasoning via multimodal large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[74]
AffordDexGrasp: Open-set language-guided dexterous grasp with generalizable- instructive affordance
Yi-Lin Wei, Mu Lin, Yuhao Lin, Jian-Jian Jiang, Xiao-Ming Wu, Ling-An Zeng, and Wei- Shi Zheng. AffordDexGrasp: Open-set language-guided dexterous grasp with generalizable- instructive affordance. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[75]
RAGNet: Large-scale reasoning-based affordance segmentation benchmark towards general grasping
Dongming Wu, Yanping Fu, Saike Huang, Yingfei Liu, Fan Jia, Nian Liu, Feng Dai, Tiancai Wang, Rao Muhammad Anwer, Fahad Shahbaz Khan, and Jianbing Shen. RAGNet: Large-scale reasoning-based affordance segmentation benchmark towards general grasping. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[76]
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Yang, Meng Li, Yinuo Zhao, Zhiyuan Xu, Guang Yang, et al. RoboMIND: Benchmark on multi-embodiment intelligence normative data for robot manipulation.arXiv preprint arXiv:2412.13877, 2024
Pith/arXiv arXiv 2024
-
[77]
V AT-mart: Learning visual action trajectory proposals for manipulating 3d ARTiculated objects
Ruihai Wu, Yan Zhao, Kaichun Mo, Zizheng Guo, Yian Wang, Tianhao Wu, Qingnan Fan, Xuelin Chen, Leonidas Guibas, and Hao Dong. V AT-mart: Learning visual action trajectory proposals for manipulating 3d ARTiculated objects. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=iEx3PiooLy
2022
-
[78]
AffordDP: Generalizable diffusion policy with transferable affordance
Shijie Wu, Yihang Zhu, Yunao Huang, Kaizhen Zhu, Jiayuan Gu, Jingyi Yu, Ye Shi, and Jingya Wang. AffordDP: Generalizable diffusion policy with transferable affordance. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 6971–6980, 2025
2025
-
[79]
Sonata: Self-supervised learning of reliable point representations
Xiaoyang Wu, Daniel DeTone, Duncan Frost, Tianwei Shen, Chris Xie, Nan Yang, Jakob Engel, Richard Newcombe, Hengshuang Zhao, and Julian Straub. Sonata: Self-supervised learning of reliable point representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[80]
Weakly-supervised affordance grounding guided by part-level semantic priors
Peiran Xu and Yadong MU. Weakly-supervised affordance grounding guided by part-level semantic priors. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=0823rvTIhs
2025
-
[81]
A0: An affordance-aware hierarchical model for general robotic manipulation
Rongtao Xu, Jian Zhang, Minghao Guo, Youpeng Wen, Haoting Yang, Min Lin, Jianzheng Huang, Zhe Li, Kaidong Zhang, Liqiong Wang, Yuxuan Kuang, Meng Cao, Feng Zheng, and Xiaodan Liang. A0: An affordance-aware hierarchical model for general robotic manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[82]
Ground- ing 3d object affordance from 2d interactions in images
Yuhang Yang, Wei Zhai, Hongchen Luo, Yang Cao, Jiebo Luo, and Zheng-Jun Zha. Ground- ing 3d object affordance from 2d interactions in images. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10905–10915, October 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.