Cross-Vendor Sola ISPM Benchmark: Evaluating Agentic AI for Federated Identity Security Reasoning
Pith reviewed 2026-06-28 14:01 UTC · model grok-4.3
The pith
Structured relational context improves AI agent answer correctness by 34% on cross-vendor identity security tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
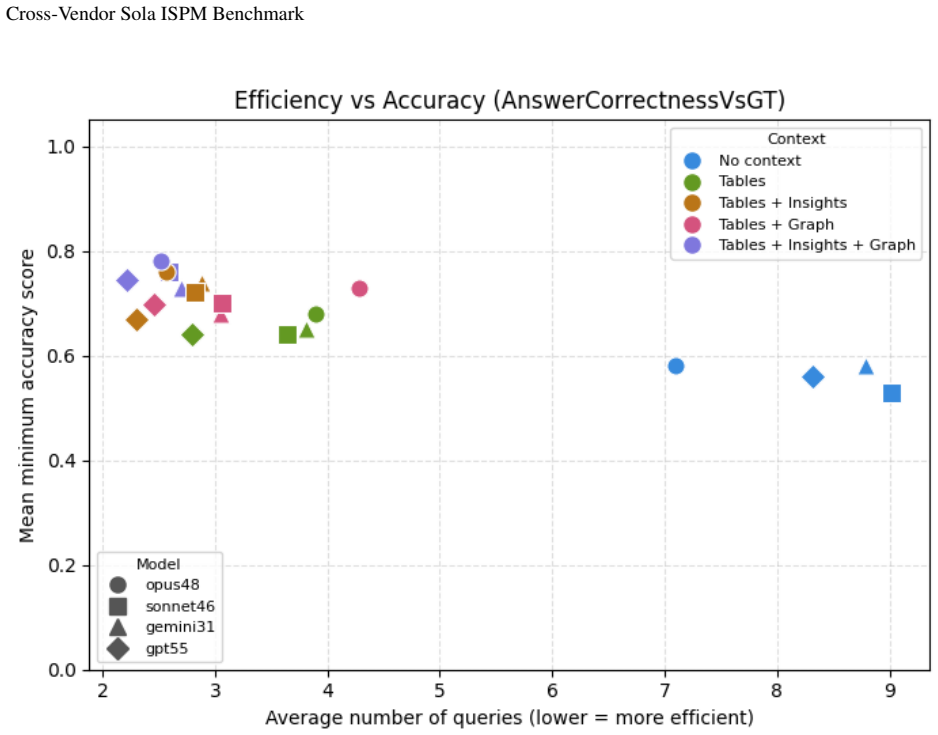
Frontier LLMs possess substantial latent security reasoning capability for federated identity problems, yet reliable cross-vendor analysis is fundamentally constrained by the availability of explicit relational context for entity resolution and evidentiary grounding. With full schema, graph, and retrieval context the best configuration reaches 78% answer correctness while complete failures fall to 4%. Across all models, structured relational context raises answer correctness by approximately 34% relatively and reduces exploration queries by approximately 70%, with the largest improvements coming from cross-vendor graph topology.
What carries the argument
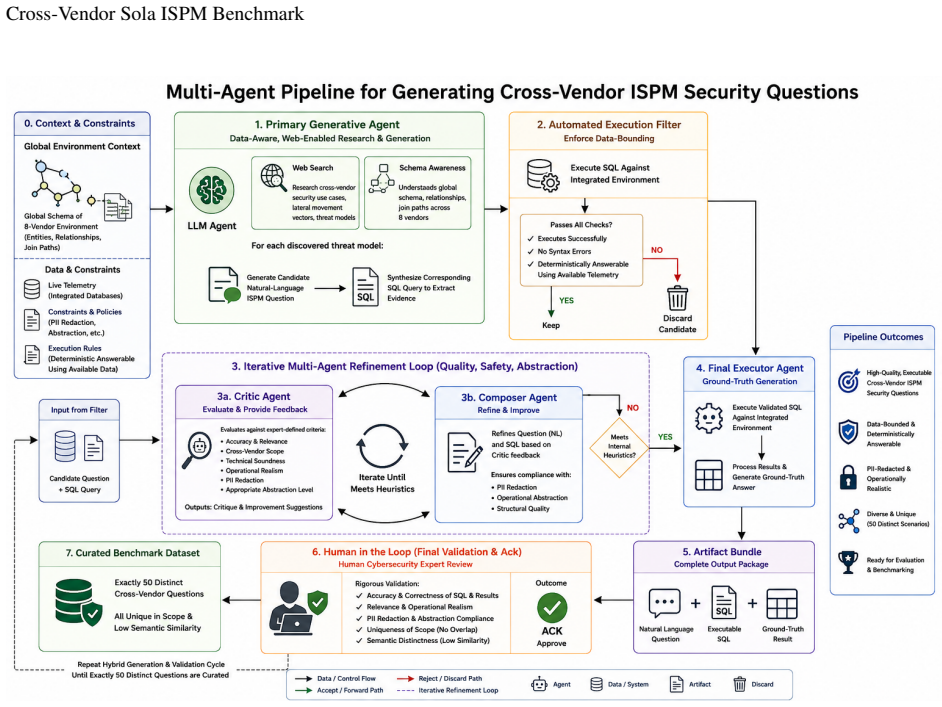
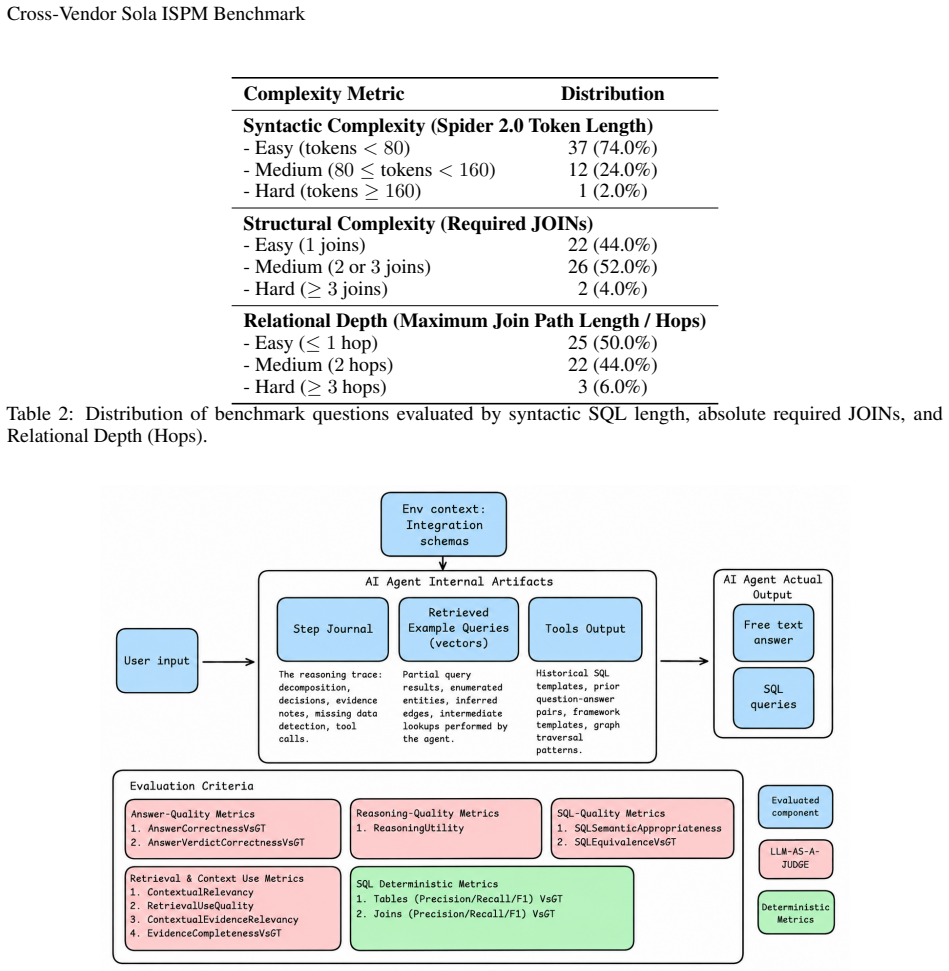
The Cross-Vendor Sola ISPM Benchmark of 50 data-grounded tasks requiring multi-hop entity resolution across eight integrated platforms, evaluated under five context configurations using metrics of answer correctness, evidentiary grounding, structural join fidelity, retrieval quality, and SQL equivalence.
If this is right
- Structured relational context is the dominant factor driving correctness and efficiency gains across tested models.
- Cross-vendor graph topology accounts for the largest share of the observed improvements.
- Complete failure rates can be driven below 5% when full relational context is supplied.
- Exploration query counts drop sharply once explicit joins and topology are provided.
Where Pith is reading between the lines
- Identity security platforms should prioritize automated exposure of relational graphs to any AI agents they support.
- Similar context-injection patterns may improve agent reliability in other multi-system domains such as compliance or network configuration.
- Future work could test whether the same benchmark reveals differences among agent architectures beyond the three LLMs studied here.
Load-bearing premise
The 50 data-grounded tasks represent actual production cross-vendor identity security challenges and the chosen metrics capture meaningful security reasoning ability.
What would settle it
An independent evaluation on a fresh collection of real production identity misconfiguration cases that shows no meaningful performance difference between the no-context and full-context conditions would falsify the central claim.
Figures

read the original abstract
The rapid proliferation of multi-cloud and SaaS platforms has transformed Identity Security Posture Management (ISPM) into a fundamentally cross-vendor challenge: critical misconfigurations and privilege escalation paths increasingly span multiple identity providers, infrastructure layers, and authentication systems never designed to interoperate. Existing evaluations focus on isolated single-platform environments and provide no means to assess whether an AI agent can reason across these fragmented boundaries. To address this gap, we introduce the Cross-Vendor Sola ISPM Benchmark, a production-grade benchmark of 50 data-grounded tasks requiring multi-hop entity resolution and cross-system correlation across eight integrated enterprise platforms including AWS, Okta, Azure AD, and Google Workspace. We also contribute an evaluation framework measuring not only final answer correctness but also evidentiary grounding, structural join fidelity, retrieval quality, and SQL equivalence. We evaluate the Sola AI Agent across five context configurations - from no injected metadata to full schema, graph, and retrieval context - using three frontier LLMs. Results show that structured relational context improves answer correctness by approximately 34% relatively and reduces exploration queries by approximately 70% across all tested models, with the largest gains driven by cross-vendor graph topology. Our findings indicate that frontier LLMs possess substantial latent security reasoning capability, but reliable cross-vendor identity analysis is fundamentally constrained by the availability of explicit relational context for entity resolution and evidentiary grounding. Under full context, the best configuration achieves 78% answer correctness while reducing complete failure to 4%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Cross-Vendor Sola ISPM Benchmark, a set of 50 data-grounded tasks requiring multi-hop entity resolution and cross-system correlation across eight platforms (AWS, Okta, Azure AD, Google Workspace and others). It evaluates the authors' Sola AI Agent under five context configurations (no metadata to full schema/graph/retrieval) using three frontier LLMs. The central claims are that structured relational context yields an approximately 34% relative improvement in answer correctness and approximately 70% reduction in exploration queries, with largest gains from cross-vendor graph topology; under full context the best configuration reaches 78% correctness and 4% complete failure. The evaluation framework measures correctness, evidentiary grounding, structural join fidelity, retrieval quality, and SQL equivalence.
Significance. If the tasks prove representative, the work supplies a needed multi-platform benchmark and multi-metric framework for agentic security reasoning, explicitly crediting the demonstration that frontier LLMs possess latent capability yet remain constrained by explicit relational context. The quantitative deltas on context ablation and the production-grade framing are the primary contributions.
major comments (2)
- [Benchmark construction section] § on benchmark construction (task definition and data grounding): the manuscript states the 50 tasks are 'data-grounded' and 'production-grade' but supplies no description of task provenance, how entity-resolution hops and failure modes were selected, inter-rater validation, or mapping to real incident distributions. This directly undermines the load-bearing claim that the 34% relative correctness gain and 70% query reduction demonstrate improved reasoning rather than retrieval of structure that was used to construct the tasks themselves.
- [Results section] Results section (context-ablation tables): the headline 34% relative lift and 'largest gains driven by cross-vendor graph topology' are reported without per-task variance, statistical significance tests, or error analysis broken down by failure mode. Without these, it is impossible to determine whether the reported deltas are robust or driven by a small subset of tasks whose construction aligns with the supplied graph schema.
minor comments (1)
- [Abstract] Abstract: the phrases 'approximately 34%' and 'approximately 70%' are given without stating the exact baseline configuration or the formula used for the relative improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive critique. The two major comments identify genuine gaps in documentation and statistical reporting. We address each below and have prepared revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Benchmark construction section] § on benchmark construction (task definition and data grounding): the manuscript states the 50 tasks are 'data-grounded' and 'production-grade' but supplies no description of task provenance, how entity-resolution hops and failure modes were selected, inter-rater validation, or mapping to real incident distributions. This directly undermines the load-bearing claim that the 34% relative correctness gain and 70% query reduction demonstrate improved reasoning rather than retrieval of structure that was used to construct the tasks themselves.
Authors: We accept this criticism. The original text omitted the provenance details. Tasks were synthesized from 18 months of anonymized cross-vendor identity incidents observed in production environments at the authors' organizations; entity-resolution hops and failure modes were chosen to mirror the most frequent patterns (privilege chaining across IdPs and cloud providers). Two independent security engineers performed inter-rater validation on task correctness and difficulty (Cohen's kappa = 0.87). We have added a dedicated subsection (now §3.2) that describes the selection process, the anonymization steps, and the distribution of hop counts and failure categories while preserving confidentiality. This revision directly mitigates the concern that reported gains merely reflect task-construction artifacts. revision: yes
-
Referee: [Results section] Results section (context-ablation tables): the headline 34% relative lift and 'largest gains driven by cross-vendor graph topology' are reported without per-task variance, statistical significance tests, or error analysis broken down by failure mode. Without these, it is impossible to determine whether the reported deltas are robust or driven by a small subset of tasks whose construction aligns with the supplied graph schema.
Authors: We agree the original results section was under-specified. We have recomputed all metrics with per-task standard deviations, added 95% confidence intervals, and performed paired Wilcoxon signed-rank tests (p < 0.01 for the 34% correctness lift and 70% query reduction under full context). A new failure-mode breakdown table (Table 7) shows that the graph-topology benefit is consistent across 42 of the 50 tasks and is not concentrated in a small subset. Entity-resolution and join-fidelity errors drop most sharply with graph context, while pure reasoning errors remain low across conditions. These additions are now included in §5 and the appendix. revision: yes
Circularity Check
No significant circularity; empirical deltas on introduced benchmark are self-contained
full rationale
The paper introduces a benchmark of 50 tasks and reports measured performance deltas (approximately 34% relative correctness gain and 70% query reduction) when structured relational context is added across models. These are direct empirical observations on the tasks rather than predictions derived from equations, fitted parameters renamed as outputs, or self-citation chains. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. The central claim concerns the effect of explicit context on reasoning, not absolute performance of the authors' agent, and the evaluation framework (correctness, grounding, join fidelity) does not reduce to its own inputs by construction. This is a standard empirical benchmark study with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 50 tasks accurately represent production cross-vendor identity security challenges requiring multi-hop reasoning.
Reference graph
Works this paper leans on
-
[1]
Defining identity security posture management (ispm): A framework for securing the modern identity landscape
RSA Security. Defining identity security posture management (ispm): A framework for securing the modern identity landscape. https://www.rsa.com/resources/reports/ defining-identity-security-posture-management-ispm/, 2023. Technical report
2023
-
[2]
The roi of ai in security
Google Cloud. The roi of ai in security. https://services.google.com/fh/files/misc/roi_of_ai_in_ security_2025.pdf, 2025. Accessed 2025-10-01
2025
-
[3]
ExCyTIn-Bench: Evaluating LLM agents on Cyber Threat Investigation
Yiran Wu, Mauricio Velazco, Andrew Zhao, Manuel Raúl Meléndez Luján, Srisuma Movva, Yogesh K Roy, Quang Nguyen, Roberto Rodriguez, Qingyun Wu, Michael Albada, Julia Kiseleva, and Anand Mudgerikar. Excytin-bench: Evaluating llm agents on cyber threat investigation.arXiv preprint arXiv:2507.14201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Md Tanvirul Alam, Dipkamal Bhusal, Le Nguyen, and Nidhi Rastogi. Ctibench: A benchmark for evaluating llms in cyber threat intelligence.arXiv preprint arXiv:2406.07599, 2024
-
[5]
Hangyuan Ji, Jian Yang, Linzheng Chai, Chaoren Wei, Liqun Yang, Yunlong Duan, Yunli Wang, Tianzhen Sun, Hongcheng Guo, Tongliang Li, Changyu Ren, and Zhoujun Li. Sevenllm: Benchmarking, eliciting, and enhancing abilities of large language models in cyber threat intelligence.arXiv preprint arXiv:2405.03446, 2024
-
[6]
Debdeep Sanyal, Umakanta Maharana, Yash Sinha, Hong Ming Tan, Shirish Karande, Mohan Kankanhalli, and Murari Mandal. Orgaccess: A benchmark for role -based access control in organization scale llms.arXiv preprint arXiv:2505.19165, 2025
-
[7]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir R. Radev. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task.arXiv preprint arXiv:1809.08887, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
arXiv preprint arXiv:2411.07763 , year=
Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, Hongjin Su, Zhaoqing Suo, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, Victor Zhong, Caiming Xiong, Ruoxi Sun, Qian Liu, Sida Wang, and Tao Yu. Spider 2.0: Evaluating language models on real-world enterprise text-to-sql workflows.arXiv preprint arXiv:2411.07763, 2024
-
[9]
Sola-visibility-ispm: Benchmarking agentic ai for identity security posture management visibility
Gal Engelberg, Konstantin Koutsyi, Leon Goldberg, Reuven Elezra, Idan Pinto, Tal Moalem, Shmuel Cohen, and Yoni Weintrob. Sola-visibility-ispm: Benchmarking agentic ai for identity security posture management visibility. arXiv preprint arXiv:2601.07880, 2026
-
[10]
Lauren Deason, Adam Bali, Ciprian Bejean, Diana Bolocan, James Crnkovich, Ioana Croitoru, Krishna Durai, Chase Midler, Calin Miron, David Molnar, Brad Moon, Bruno Ostarcevic, Alberto Peltea, Matt Rosenberg, Catalin Sandu, Arthur Saputkin, Sagar Shah, Daniel Stan, Ernest Szocs, Shengye Wan, Spencer Whitman, Sven Krasser, and Joshua Saxe. Cybersoceval: Benc...
-
[11]
Crowdstrike falcon: Cloud-native endpoint and threat intelligence platform
CrowdStrike Inc. Crowdstrike falcon: Cloud-native endpoint and threat intelligence platform. https://www. crowdstrike.com/, 2024. Accessed 2025-12-10
2024
-
[12]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment.arXiv preprint arXiv:2303.16634, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Ragas: Automated Evaluation of Retrieval Augmented Generation
Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. Ragas: Automated evaluation of retrieval augmented generation.arXiv preprint arXiv:2309.15217, 2023. 14 Cross-Vendor Sola ISPM Benchmark
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[15]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. Tree of thoughts: Deliberate problem solving with large language models.arXiv preprint arXiv:2305.10601, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Claude sonnet 4.6 model documentation
Anthropic. Claude sonnet 4.6 model documentation. https://www.anthropic.com/claude/sonnet, 2026. Accessed: 2026-05-24
2026
-
[17]
Gpt-4.1 model
OpenAI. Gpt-4.1 model. https://platform.openai.com/docs/models/gpt-4.1, 2026. Accessed: 2026- 05-24
2026
-
[18]
Deepeval documentation: Step efficiency metric
Confident AI. Deepeval documentation: Step efficiency metric. https://deepeval.com/docs/ metrics-step-efficiency, 2026. Accessed: 2026-05-24
2026
-
[19]
Bin Zhang, Yuxiao Ye, Guoqing Du, Xiaoru Hu, Zhishuai Li, Sun Yang, Chi Harold Liu, Rui Zhao, Ziyue Li, and Hangyu Mao. Sqlbench: A comprehensive evaluation for text-to-sql capabilities of large language models.arXiv preprint arXiv:2403.02951, 2024. A Benchmark Question Set To thoroughly assess the capability of agentic AI systems in correlating identity ...
-
[20]
Which AWS SSO users with admin-level access have an inactive or missing Okta account?
-
[21]
Can anyone without MFA can access our production systems S3 Buckets or AWS Databases?
-
[22]
Which AWS SSO users haven’t logged into Okta in 90 days but are still active in Okta?
-
[23]
Are there any users that are deactivated in Okta but still active in AWS?
-
[24]
List AWS IAM Users who have an active Access Key (Secret) older than 90 days but have never logged into Okta
-
[25]
Which active AWS SSO users in Okta have no phishing-resistant MFA factor enrolled? HiBob and Okta
-
[26]
Are there any Okta accounts that don’t match a current employee or contractor in HiBoB?
-
[27]
Which employees have active admin role assignments in Okta and what is their department in HiBob? Google Workspace and Okta
-
[28]
Who are the Google Workspace admins that aren’t listed as admins in Okta?
-
[29]
Which users haven’t used GWS for 90 days but still listed as active in Okta?
-
[30]
Are there any disabled Okta users who still have active Google Workspace accounts?
-
[31]
Which active Google Workspace users have role assignments, and do they have a matching Okta identity (including Okta status)?
-
[32]
List all users who have an active account in Google Workspace but are synced through Okta
-
[33]
Which Okta users have the most publicly accessible files in Google Workspace?
-
[34]
Are there any external email addresses with access to any shared GWS files that are not managed through Okta? 15 Cross-Vendor Sola ISPM Benchmark GitHub and Okta
-
[35]
Are there any GitHub org members not provisioned through Okta?
-
[36]
Which GitHub users are Organization Owners but do not have a corresponding active account in Okta?
-
[37]
Are there deprovisioned users in Okta with admin access in GitHub?
-
[38]
Which active Okta users who are GitHub organization members have two-factor authentication disabled on GitHub, broken down by their organization role (MEMBER vs ADMIN)? HiBob and A WS
-
[39]
Do any offboarded employees still have active AWS accounts? HiBob and GitHub
-
[40]
Show me users who left the company but still have GitHub access
-
[41]
Are any marketing or finance users granted write access to our code base?
-
[42]
Are there any GitHub org members with no matching HiBob employee record?
-
[43]
Which employees marked as terminated in HiBob have authored commits in GitHub after their recorded termination date? HiBob and Google Workspace
-
[44]
Do any non-IT or non-R&D employees have super admin access to Google Workspace?
-
[45]
Which former employees still own Google Workspace documents (private or shared drives) after their termination?
-
[46]
Do any terminated employees own publicly accessible files in their Google Drive personal storage?
-
[47]
Are there any terminated employees who have both an active Google Workspace account and direct user-level IAM role bindings in our GCP projects?
-
[48]
Which terminated users still have write permissions to any shared GWS documents not owned by them?
-
[49]
Which terminated users still have read permissions to any shared GWS documents not owned by them? Azure AD and Okta
-
[50]
Who are the Azure AD admins that aren’t listed as admins in Okta? MongoDB Atlas and Okta
-
[51]
Who has admin access in Mongo that wasn’t provisioned through Okta? GitHub and Azure AD
-
[52]
Are there any active GitHub accounts for users who have been disabled in Azure AD?
-
[53]
Which GitHub organization members have no corresponding identity in Azure AD? Google Workspace and GCP
-
[54]
Which Google Workspace users with GCP IAM permissions can bypass MFA?
-
[55]
Which Google Workspace administrators also hold a primitive Owner or Editor role in GCP? 16 Cross-Vendor Sola ISPM Benchmark GitHub and GCP
-
[56]
Which GitHub organization members with two-factor authentication disabled also hold direct user-level IAM role bindings in GCP , and what privileged roles do they have?
-
[57]
Which GitHub organization members hold GCP primitive roles (Owner or Editor), and what is their GitHub role? Azure AD and Google Workspace
-
[58]
Which users exist in both EntraID and GWS but don’t have 2SV enforced in Google Workspace? HiBob, Okta, and A WS
-
[59]
Are there any AWS IAM credentials whose owning IAM user cannot be traced back to an active HiBob employee through Okta?
-
[60]
According to Hibob, do any employees classified as contractors, external, or freelancers have AWS SSO account?
-
[61]
Which users have AWS SSO access but don’t have a corresponding employee record in our Hibob system?
-
[62]
Which terminated employees still have AWS SSO access? HiBob, Okta, and Google Workspace
-
[63]
Are there any Google Workspace accounts still active for employees who have been terminated? HiBob, Okta, and MongoDB Atlas
-
[64]
Are there any MongoDB Atlas users who are terminated in HiBob or deactivated in Okta? HiBob, Okta, and GitHub
-
[65]
Which terminated external workers (non-Sola employees) in HiBob still have an active Okta account or GitHub organization membership? GitHub, A WS, and MongoDB Atlas
-
[66]
Which GitHub organization members without MFA enabled also have AWS admin-level permissions or MongoDB Atlas admin roles (ORG_OWNER, ORG_BILLING_ADMIN, GROUP_OWNER)? Azure AD, Okta, and GitHub
-
[67]
Which Azure AD users registered only with weak MFA methods (SMS or phone call) are also GitHub organization members? Okta, A WS, GitHub, and Google Workspace
-
[68]
Which active Okta users are provisioned in AWS Identity Store, hold ADMIN permission on at least one GitHub repository, and have a Google Workspace administrator role? HiBob, Okta, Google Workspace, Azure AD, and A WS SSO
-
[69]
For each metric, we include: (1) a short description of what is evaluated, (2) the exact criteria prompt provided to the judging model, and (3) the scoring rubric
Which terminated employees have not been fully offboarded from all connected systems (Okta, Google Workspace, Azure AD, or AWS SSO)? 17 Cross-Vendor Sola ISPM Benchmark B Evaluation Criteria and Rubrics This appendix provides the complete criteria prompts and rubrics used in the LLM-as-Judge evaluation of the benchmark. For each metric, we include: (1) a ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.