Adaptive Latent Agentic Reasoning
Pith reviewed 2026-06-28 14:22 UTC · model grok-4.3
The pith
ALAR lets LLM agents default to compact latent reasoning for routine steps and use explicit CoT only when needed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
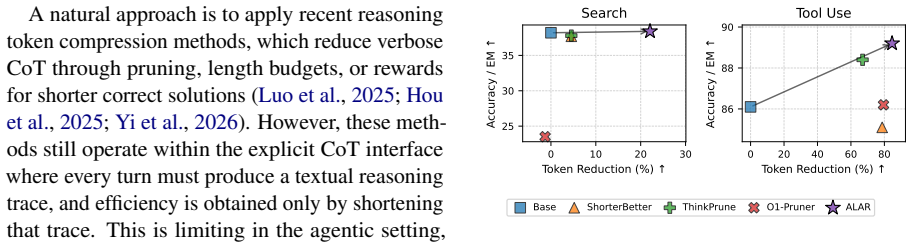
The central claim is that a latent reasoning mode, trained with final actions as supervision, can replace explicit chain-of-thought on most decision steps while an adaptive policy reserves explicit deliberation for harder turns, producing comparable or better task success at far lower token cost.
What carries the argument
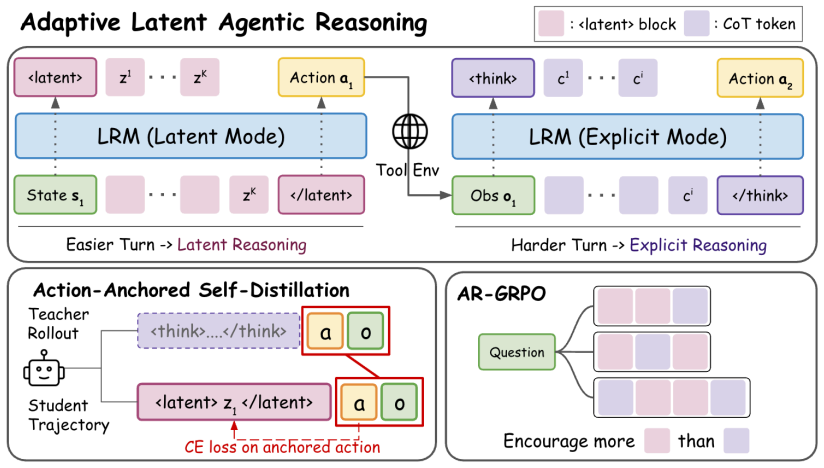
The dual-mode ALAR framework that learns compact latent reasoning representations from action supervision and selectively escalates to explicit CoT based on sufficiency for task success.
Load-bearing premise
The agent's final actions supply enough supervision to train a latent representation that contains all information required for correct routine decisions.
What would settle it
A controlled test in which forcing the agent into latent mode on a set of turns that were previously handled correctly produces a measurable drop in final task accuracy would falsify the claim.
Figures

read the original abstract
Large reasoning models improve performance by generating extended chain-of-thought (CoT) reasoning, but this behavior becomes inefficient when applied to LLM agents. Current LLM agents often generate verbose textual reasoning at every decision step and allocate reasoning effort nearly uniformly across turns, leading to substantial inefficiency in multi-turn agentic trajectories. We propose Adaptive Latent Agentic Reasoning (ALAR), a dual-mode framework that uses compact latent reasoning for routine turns and selectively escalates to explicit chain-of-thought when deeper deliberation is needed. ALAR learns latent reasoning by using the agent's actions as supervision anchors and is further optimized to use latent reasoning when it is sufficient for task success and reserve explicit CoT for harder decisions. Experiments on agentic search and tool-use benchmarks show that ALAR maintains comparable or better task accuracy while substantially reducing generated tokens by up to 43.6% in search and 84.6% in tool use. These results demonstrate that ALAR improves the accuracy-efficiency trade-off of LLM agents by reducing unnecessary textual reasoning while preserving explicit deliberation for harder decision steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adaptive Latent Agentic Reasoning (ALAR), a dual-mode framework for LLM agents. It uses compact latent reasoning for routine decision turns (trained via final-action supervision anchors) and selectively escalates to explicit chain-of-thought for harder steps. The central empirical claim is that this maintains or improves task accuracy on agentic search and tool-use benchmarks while reducing generated tokens by up to 43.6% (search) and 84.6% (tool use).
Significance. If the empirical results hold under rigorous controls, the work would demonstrate a practical route to improving the accuracy-efficiency frontier for multi-turn LLM agents by avoiding uniform explicit CoT. The use of action-based supervision for latent mode training is a concrete, falsifiable design choice that could be tested on other agent benchmarks.
major comments (2)
- [Method description (training of latent mode)] The central claim (comparable/better accuracy at large token savings) depends on the dual-mode policy correctly routing routine turns to latent reasoning without loss of decision-critical information. The manuscript provides no independent verification (e.g., reconstruction error, mutual information between latent state and explicit-CoT decisions, or ablation on held-out intermediate factors) that final-action supervision recovers all information needed for correct routine decisions; this is load-bearing for the reported token reductions.
- [Experiments section] No statistical tests, variance estimates across seeds, or details on post-hoc optimization choices (mentioned in the reader's summary) are reported for the benchmark results. Without these, it is impossible to assess whether the accuracy parity and token savings are robust or could be explained by benchmark-specific tuning.
minor comments (2)
- Notation for the escalation trigger and latent state update is introduced without a compact equation or pseudocode block, making the routing logic hard to follow precisely.
- The abstract states 'up to' token reductions; the main text should report per-benchmark means, standard deviations, and the exact fraction of turns routed to each mode.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive suggestions. We address the major comments below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Method description (training of latent mode)] The central claim (comparable/better accuracy at large token savings) depends on the dual-mode policy correctly routing routine turns to latent reasoning without loss of decision-critical information. The manuscript provides no independent verification (e.g., reconstruction error, mutual information between latent state and explicit-CoT decisions, or ablation on held-out intermediate factors) that final-action supervision recovers all information needed for correct routine decisions; this is load-bearing for the reported token reductions.
Authors: The primary evidence for the sufficiency of latent reasoning is the maintained or improved task accuracy on the benchmarks. If the final-action supervision failed to capture decision-critical information, this would result in degraded performance, which is not observed. We recognize that additional probes could further substantiate this and will add an analysis section discussing the correlation between latent states and key decision variables, along with any relevant ablations, in the revised manuscript. revision: partial
-
Referee: [Experiments section] No statistical tests, variance estimates across seeds, or details on post-hoc optimization choices (mentioned in the reader's summary) are reported for the benchmark results. Without these, it is impossible to assess whether the accuracy parity and token savings are robust or could be explained by benchmark-specific tuning.
Authors: We agree that including statistical tests and variance estimates would improve the rigor of the experimental results. The reported numbers are based on multiple evaluation runs, and we will incorporate error bars, standard deviations across seeds, and appropriate statistical tests in the updated experiments section. We will also provide a detailed description of any optimization procedures to clarify that they are not the result of benchmark-specific tuning. revision: yes
Circularity Check
No circularity; method and claims are self-contained against external benchmarks
full rationale
The paper describes an empirical method (dual-mode latent vs. explicit reasoning) trained via standard action supervision and evaluated on external agentic benchmarks. No equations, derivations, or first-principles results are presented that reduce any claimed improvement to a fitted quantity or self-defined input by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing for the core accuracy-efficiency claims. The training signal (final actions) is an independent supervision source, not a tautological redefinition of the latent representation's completeness. This is the normal case of a non-circular empirical ML paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
s1: Simple test-time scaling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[4]
arXiv preprint arXiv:2501.04682 , year=
Towards system 2 reasoning in llms: Learning how to think with meta chain-of-thought , author=. arXiv preprint arXiv:2501.04682 , year=
-
[5]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Training Large Language Models to Reason in a Continuous Latent Space
Training large language models to reason in a continuous latent space , author=. arXiv preprint arXiv:2412.06769 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Codi: Compressing chain-of-thought into continuous space via self-distillation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[8]
Learning Adaptive Reasoning Paths for Efficient Visual Reasoning
Learning Adaptive Reasoning Paths for Efficient Visual Reasoning , author=. arXiv preprint arXiv:2604.14568 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Advances in neural information processing systems , volume=
Arm: Adaptive reasoning model , author=. Advances in neural information processing systems , volume=
-
[10]
Agentic Reasoning for Large Language Models
Agentic reasoning for large language models , author=. arXiv preprint arXiv:2601.12538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning , author=. arXiv preprint arXiv:2501.12570 , year=
-
[12]
ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning
Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning , author=. arXiv preprint arXiv:2504.01296 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Advances in Neural Information Processing Systems , volume=
Shorterbetter: Guiding reasoning models to find optimal inference length for efficient reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
2024 , eprint=
The Faiss library , author=. 2024 , eprint=
2024
-
[15]
Transactions of the Association for Computational Linguistics , volume=
MuSiQue: Multi-hop Questions via Single-hop Question Composition , author=. Transactions of the Association for Computational Linguistics , volume=
-
[16]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Measuring and narrowing the compositionality gap in language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[17]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[18]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
2018
-
[19]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[20]
Transactions of the Association for Computational Linguistics , volume=
Natural Questions: A Benchmark for Question Answering Research , author=. Transactions of the Association for Computational Linguistics , volume=
-
[21]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[22]
arXiv preprint arXiv:2511.15718 , year=
ToolMind Technical Report: A Large-Scale, Reasoning-Enhanced Tool-Use Dataset , author=. arXiv preprint arXiv:2511.15718 , year=
-
[23]
International Conference on Machine Learning , pages=
The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[24]
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
Compressed chain of thought: Efficient reasoning through dense representations , author=. arXiv preprint arXiv:2412.13171 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2510.05069 , year=
SwiReasoning: Switch-Thinking in Latent and Explicit for Pareto-Superior Reasoning LLMs , author=. arXiv preprint arXiv:2510.05069 , year=
-
[26]
Token assorted: Mixing latent and text tokens for improved language model reasoning , author=. arXiv preprint arXiv:2502.03275 , year=
-
[27]
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
From explicit cot to implicit cot: Learning to internalize cot step by step , author=. arXiv preprint arXiv:2405.14838 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Advances in Neural Information Processing Systems , volume=
Hybrid latent reasoning via reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
arXiv preprint arXiv:2602.11683 , year=
ThinkRouter: Efficient Reasoning via Routing Thinking between Latent and Discrete Spaces , author=. arXiv preprint arXiv:2602.11683 , year=
-
[30]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Do not think that much for 2+ 3=? on the overthinking of o1-like llms , author=. arXiv preprint arXiv:2412.21187 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning
L1: Controlling how long a reasoning model thinks with reinforcement learning , author=. arXiv preprint arXiv:2503.04697 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
arXiv preprint arXiv:2506.14755 , year=
Optimizing length compression in large reasoning models , author=. arXiv preprint arXiv:2506.14755 , year=
-
[33]
Advances in Neural Information Processing Systems , volume=
Training language models to reason efficiently , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
Dast: Difficulty-adaptive slow-thinking for large reasoning models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2025
-
[35]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Stop overthinking: A survey on efficient reasoning for large language models , author=. arXiv preprint arXiv:2503.16419 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[39]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.