Depth from Dual Differential Defocus and Stereo Consensus
Pith reviewed 2026-06-28 11:56 UTC · model grok-4.3
The pith
D^3S combines dual differential defocus and stereo consensus to estimate depth accurately with a 10 times smaller baseline than prior triangulation systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given dual-defocus stereo images, the method computes depths from both Dual Differential Defocus and stereo, then selects the estimate that enforces consensus between the two cues; this rejects unreliable predictions and yields depth maps with 1 cm mean absolute error over 0.3-1.64 m using only a 4 mm baseline.
What carries the argument
The consensus step that retains only the depth prediction showing agreement between the DfD-derived and stereo-derived estimates.
If this is right
- Achieves a comparable working range at the same error tolerance with a 10 times smaller baseline than previous triangulation-based depth systems.
- Enables compact passive binocular rangefinders with substantially smaller form factors than conventional stereo or DfD designs.
- Produces up to 900 by 1800 pixel depth maps from a single snapshot acquisition.
- Surpasses the reported accuracy of some commercially available stereo cameras that use much larger baselines.
Where Pith is reading between the lines
- The snapshot nature of the acquisition opens a route to video-rate depth maps if the same consensus logic can be applied across frames.
- Small-baseline operation could allow depth sensing to be added to space-constrained platforms such as phones or small robots without active illumination.
- Because the two cues are physically independent, the consensus filter may improve robustness in scenes that contain textureless regions or depth discontinuities.
- The same fusion idea could be tested with other pairs of passive cues, such as focus and polarization, to further shrink sensor size.
Load-bearing premise
The consensus step between DfD-derived depths and stereo-derived depths can reliably keep accurate estimates and discard unreliable ones without introducing systematic bias or losing coverage.
What would settle it
Ground-truth depth measurements on scenes engineered so that defocus and stereo cues disagree on the same points; check whether the consensus rule still returns the correct value or instead selects an erroneous depth when both cues err.
Figures







read the original abstract
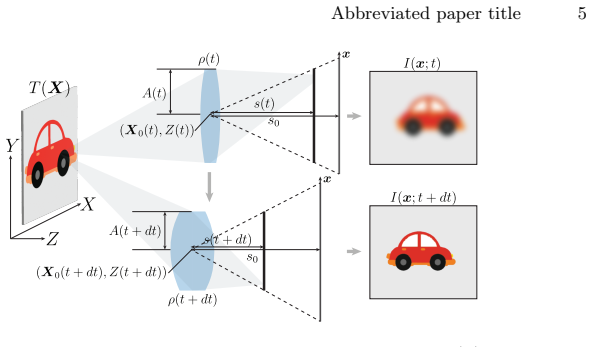
We introduce D^3S Consensus, a physics-based, closed-form algorithm that unifies depth-from-defocus (DfD) and stereo to achieve highly accurate depth estimation throughout an extended working range beyond the depth-of-field (DoF) of cameras. Given a pair of dual-defocus stereo images, the method estimates an overdetermined set of depth using a novel DfD theory, Dual Differential Defocus (D^3), and (S)tereo in a coupled fashion. It then picks the most confident depth prediction from the set by enforcing consensus between these physically independent cues to reject unreliable estimates. Analysis shows that D^3S achieves a comparable working range under the same error tolerance with 10x smaller baseline than previous triangulation-based depth estimation systems. This enables compact passive binocular rangefinders with substantially smaller form factors than conventional stereo and DfD designs. We demonstrate the first D^3S prototype with only 4 mm baseline and 12 mm EFL. It generates up to 900 x 1800-pixel depth maps with 1-cm mean absolute error over 0.3-1.64 m from a snapshot acquisition. This has surpassed the reported accuracy of certain commercially available stereo cameras with much larger form factors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
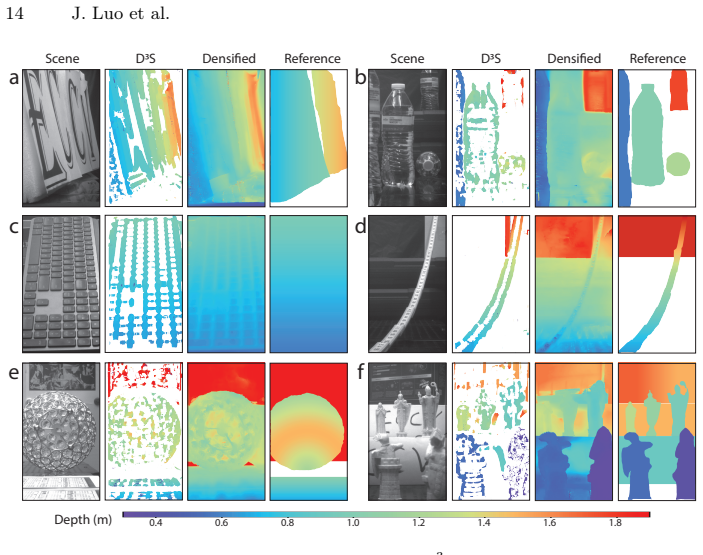
Summary. The paper introduces D^3S Consensus, a physics-based closed-form algorithm that unifies Dual Differential Defocus (D^3) and stereo cues from a pair of dual-defocus stereo images. It computes an overdetermined set of depth estimates and selects the most confident value by enforcing consensus between the physically independent cues, thereby rejecting unreliable estimates. The central claim is that this yields a comparable working range under the same error tolerance with a 10x smaller baseline than prior triangulation-based systems; a prototype with 4 mm baseline and 12 mm EFL is reported to produce up to 900 x 1800-pixel depth maps with 1 cm MAE over 0.3-1.64 m from a single snapshot.
Significance. If the independence of the D^3 and stereo cues and the unbiased filtering property of the consensus rule hold, the result would enable compact passive depth sensors with substantially reduced form factors while extending usable range beyond the camera DoF; this would be a meaningful advance for applications requiring small-baseline binocular rangefinders.
major comments (2)
- [Abstract] Abstract: the assertion that 'analysis shows' a 10x baseline reduction rests on an unshown derivation of how the closed-form consensus step preserves working range under fixed error tolerance when the stereo cue is weakened by the 4 mm baseline; the manuscript must supply the explicit equations or bounds that establish this scaling without introducing systematic retention of outliers.
- [Consensus step] Consensus step (described in abstract): the load-bearing assumption that the consensus metric reliably retains only estimates whose error lies below tolerance, without coverage loss or bias when cues share error modes (textureless patches, DoF boundaries, or common illumination), is not yet supported by the provided text; a concrete test or counter-example analysis is required to substantiate the 10x claim.
minor comments (1)
- [Prototype results] Prototype results paragraph: specify the exact functional form of the consensus metric and the threshold used to select the final depth value.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and will revise the paper to incorporate the requested material.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'analysis shows' a 10x baseline reduction rests on an unshown derivation of how the closed-form consensus step preserves working range under fixed error tolerance when the stereo cue is weakened by the 4 mm baseline; the manuscript must supply the explicit equations or bounds that establish this scaling without introducing systematic retention of outliers.
Authors: We agree the abstract claim requires explicit support. The manuscript contains a theoretical analysis of the consensus step, but we acknowledge the scaling derivation with respect to baseline is not presented with sufficient detail or bounds. In the revised version we will add the explicit equations and error-tolerance bounds in the theory section, showing how consensus preserves range at the 4 mm baseline while excluding systematic outlier retention. revision: yes
-
Referee: [Consensus step] Consensus step (described in abstract): the load-bearing assumption that the consensus metric reliably retains only estimates whose error lies below tolerance, without coverage loss or bias when cues share error modes (textureless patches, DoF boundaries, or common illumination), is not yet supported by the provided text; a concrete test or counter-example analysis is required to substantiate the 10x claim.
Authors: The consensus rule is predicated on the physical independence of the D^3 and stereo cues. We recognize that the current text does not supply explicit validation against shared error modes. The revised manuscript will add a dedicated analysis subsection containing concrete tests and counter-example evaluations on textureless patches, DoF boundaries, and common illumination variations to demonstrate retention of estimates within tolerance and to support the 10x baseline result. revision: yes
Circularity Check
No circularity: derivation relies on independent physical cues and external analysis
full rationale
The abstract and description present D^3 as a novel DfD theory combined with stereo via a consensus step on physically independent cues. The 10x baseline claim is stated to follow from analysis of the overdetermined set, with no quoted equations or steps showing that any prediction reduces by construction to a fitted input, self-citation chain, or renamed ansatz. The method is benchmarked against external systems and prototypes, satisfying the self-contained criterion. No load-bearing step matches the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dual Differential Defocus and stereo provide physically independent depth cues whose agreement can be used to reject unreliable estimates.
Reference graph
Works this paper leans on
-
[1]
FirstName LastName , title =
-
[2]
FirstName Alpher , title =
-
[3]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[4]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[5]
FirstName Alpher and FirstName Gamow , title =
-
[6]
2019 , publisher =
A theory of depth from differential defocus , author =. 2019 , publisher =
2019
-
[7]
Proceedings of the IEEE international conference on computer vision , pages=
Focal track: Depth and accommodation with oscillating lens deformation , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[8]
Computer Vision--ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III 14 , pages=
Focal flow: Measuring distance and velocity with defocus and differential motion , author=. Computer Vision--ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III 14 , pages=. 2016 , organization=
2016
-
[9]
International Journal of Computer Vision , volume=
Focal flow: Velocity and depth from differential defocus through motion , author=. International Journal of Computer Vision , volume=. 2018 , publisher=
2018
-
[10]
Proceedings of the National Academy of Sciences , volume=
Compact single-shot metalens depth sensors inspired by eyes of jumping spiders , author=. Proceedings of the National Academy of Sciences , volume=. 2019 , publisher=
2019
-
[11]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Focal Split: Untethered Snapshot Depth from Differential Defocus , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[12]
Luo et al
Depth from Coupled Optical Differentiation: J. Luo et al. , author=. International Journal of Computer Vision , pages=. 2025 , publisher=
2025
-
[13]
Computer vision , pages=
Photon, poisson noise , author=. Computer vision , pages=. 2014 , publisher=
2014
-
[14]
Acs Photonics , volume=
3D imaging using extreme dispersion in optical metasurfaces , author=. Acs Photonics , volume=. 2021 , publisher=
2021
-
[15]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Single image depth estimation trained via depth from defocus cues , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[16]
2021 IEEE International Conference on Computational Photography (ICCP) , pages=
Depth from defocus with learned optics for imaging and occlusion-aware depth estimation , author=. 2021 IEEE International Conference on Computational Photography (ICCP) , pages=. 2021 , organization=
2021
-
[17]
IEEE Transactions on Image Processing , volume=
Joint depth and defocus estimation from a single image using physical consistency , author=. IEEE Transactions on Image Processing , volume=. 2021 , publisher=
2021
-
[18]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Fully self-supervised depth estimation from defocus clue , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[19]
Machine vision and applications , volume=
Deblur and deep depth from single defocus image , author=. Machine vision and applications , volume=. 2021 , publisher=
2021
-
[20]
IEEE Transactions on Computational Imaging , volume=
Depth estimation and image restoration by deep learning from defocused images , author=. IEEE Transactions on Computational Imaging , volume=. 2023 , publisher=
2023
-
[21]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Learned Binocular-Encoding Optics for RGBD Imaging Using Joint Stereo and Focus Cues , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[22]
Ou et al
Learning RGBD imaging via asymmetrically focused stereo cameras: L. Ou et al. , author=. The Visual Computer , pages=. 2025 , publisher=
2025
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Codedstereo: Learned phase masks for large depth-of-field stereo , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[24]
European Conference on Computer Vision , pages=
Low-Cost Stereoscopic Optical-Coding Design for Depth Estimation Using End-to-End Optimization , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[25]
International Conference on Computer Vision Theory and Applications , volume=
Coded aperture stereo-for extension of depth of field and refocusing , author=. International Conference on Computer Vision Theory and Applications , volume=. 2012 , organization=
2012
-
[26]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Depth from defocus in the wild , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[27]
Journal of Electronic Imaging , volume=
Dual-focus stereo imaging , author=. Journal of Electronic Imaging , volume=. 2010 , publisher=
2010
-
[28]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Fusing depth from defocus and stereo with coded apertures , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[29]
ACM Transactions on Applied Perception (TAP) , volume=
Depth of field affects perceived depth in stereographs , author=. ACM Transactions on Applied Perception (TAP) , volume=. 2014 , publisher=
2014
-
[30]
ACM Transactions on Graphics (TOG) , volume=
Split-aperture 2-in-1 computational cameras , author=. ACM Transactions on Graphics (TOG) , volume=. 2024 , publisher=
2024
-
[31]
International Journal of Computer Vision , volume=
Rational filters for passive depth from defocus , author=. International Journal of Computer Vision , volume=. 1998 , publisher=
1998
-
[32]
Journal of the Optical Society of America A , volume=
Range estimation by optical differentiation , author=. Journal of the Optical Society of America A , volume=. 1998 , publisher=
1998
-
[33]
The international journal of robotics research , volume=
Vision meets robotics: The kitti dataset , author=. The international journal of robotics research , volume=. 2013 , publisher=
2013
-
[34]
German conference on pattern recognition , pages=
High-resolution stereo datasets with subpixel-accurate ground truth , author=. German conference on pattern recognition , pages=. 2014 , organization=
2014
-
[35]
IEEE transactions on pattern analysis and machine intelligence , number=
A new sense for depth of field , author=. IEEE transactions on pattern analysis and machine intelligence , number=. 1987 , publisher=
1987
-
[36]
stereo: How different really are they? , author=
Depth from defocus vs. stereo: How different really are they? , author=. International Journal of Computer Vision , volume=. 2000 , publisher=
2000
-
[37]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
BridgeDepth: Bridging Monocular and Stereo Reasoning with Latent Alignment , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[38]
Advances in Neural Information Processing Systems , volume=
Depth anything v2 , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Repurposing diffusion-based image generators for monocular depth estimation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[40]
International Journal of computer vision , volume=
Depth from defocus: A spatial domain approach , author=. International Journal of computer vision , volume=. 1994 , publisher=
1994
-
[41]
2009 IEEE 12th international conference on computer vision , pages=
Coded aperture pairs for depth from defocus , author=. 2009 IEEE 12th international conference on computer vision , pages=. 2009 , organization=
2009
-
[42]
2003 , publisher=
Multiple view geometry in computer vision , author=. 2003 , publisher=
2003
-
[43]
2008 IEEE conference on computer vision and pattern recognition , pages=
Variable baseline/resolution stereo , author=. 2008 IEEE conference on computer vision and pattern recognition , pages=. 2008 , organization=
2008
-
[44]
Robotics and Autonomous Systems , volume=
Depth accuracy analysis of the ZED 2i Stereo Camera in an indoor Environment , author=. Robotics and Autonomous Systems , volume=. 2024 , publisher=
2024
-
[45]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Marigold-dc: Zero-shot monocular depth completion with guided diffusion , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[46]
2022 , publisher=
Computer vision: algorithms and applications , author=. 2022 , publisher=
2022
-
[47]
Intel RealSenseTM Depth Camera D435 , publisher=
Intel realsenseTM depth camera D435 , url=. Intel RealSenseTM Depth Camera D435 , publisher=
-
[48]
IEEE Access , year=
Empirical comparison of four stereoscopic depth sensing cameras for robotics applications , author=. IEEE Access , year=
-
[49]
Intel realsenseTM depth camera D455 , publisher=
-
[50]
Zed 2 - AI stereo camera , publisher=
-
[51]
2019 IEEE International Conference on Computational Photography (ICCP) , pages=
Phasecam3d—learning phase masks for passive single view depth estimation , author=. 2019 IEEE International Conference on Computational Photography (ICCP) , pages=. 2019 , organization=
2019
-
[52]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Deep optics for monocular depth estimation and 3d object detection , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[53]
2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05) , volume=
Accurate and efficient stereo processing by semi-global matching and mutual information , author=. 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR'05) , volume=. 2005 , organization=
2005
-
[54]
Microsoft Research Technical Report , year=
Micro-baseline stereo , author=. Microsoft Research Technical Report , year=
-
[55]
ACM Transactions on Graphics (ToG) , volume=
Fast depth densification for occlusion-aware augmented reality , author=. ACM Transactions on Graphics (ToG) , volume=. 2018 , publisher=
2018
-
[56]
ACM transactions on graphics (TOG) , volume=
Image and depth from a conventional camera with a coded aperture , author=. ACM transactions on graphics (TOG) , volume=. 2007 , publisher=
2007
-
[57]
European conference on computer vision , pages=
The fast bilateral solver , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[58]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Blurry-Edges: Photon-Limited Depth Estimation from Defocused Boundaries , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[59]
2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Depth coefficients for depth completion , author=. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2019 , organization=
2019
-
[60]
2018 IEEE international conference on robotics and automation (ICRA) , pages=
Sparse-to-dense: Depth prediction from sparse depth samples and a single image , author=. 2018 IEEE international conference on robotics and automation (ICRA) , pages=. 2018 , organization=
2018
-
[61]
IEEE Transactions on Image Processing , volume=
Learning guided convolutional network for depth completion , author=. IEEE Transactions on Image Processing , volume=. 2020 , publisher=
2020
-
[62]
arXiv preprint arXiv:2207.14780 , year=
D-flat: A differentiable flat-optics framework for end-to-end metasurface visual sensor design , author=. arXiv preprint arXiv:2207.14780 , year=
-
[63]
To appear in Proceedings of the Computer Vision and Pattern Recognition Conference , year=
SpiderCam: Low-Power Snapshot Depth from Differential Defocus , author=. To appear in Proceedings of the Computer Vision and Pattern Recognition Conference , year=
-
[64]
IEICE TRANSACTIONS on Information and Systems , volume=
Depth from defocus technique based on cross reblurring , author=. IEICE TRANSACTIONS on Information and Systems , volume=. 2019 , publisher=
2019
-
[65]
CUReT: Columbia Utrecht reflectance and texture database , author=
-
[66]
International journal of computer vision , volume=
Distinctive image features from scale-invariant keypoints , author=. International journal of computer vision , volume=. 2004 , publisher=
2004
-
[67]
In: European conference on computer vision, Springer (2014) 740–755
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision, Springer (2014) 740–755
2014
-
[68]
In: European conference on computer vision, Springer (2014) 54–70
Crowley, E.J., Zisserman, A.: In search of art. In: European conference on computer vision, Springer (2014) 54–70
2014
-
[69]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Mayer, N., Ilg, E., Hausser, P., Fischer, P., Cremers, D., Dosovitskiy, A., Brox, T.: A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. (2016) 4040–4048
2016
-
[70]
Science China Information Sciences 63(11) (2020) 212101
Bao, W., Wang, W., Xu, Y., Guo, Y., Hong, S., Zhang, X.: Instereo2k: a large real dataset for stereo matching in indoor scenes. Science China Information Sciences 63(11) (2020) 212101
2020
-
[71]
In: 2007 IEEE conference on computer vision and pattern recognition, IEEE (2007) 1–8
Hirschmuller, H., Scharstein, D.: Evaluation of cost functions for stereo matching. In: 2007 IEEE conference on computer vision and pattern recognition, IEEE (2007) 1–8
2007
-
[72]
In: Soft Materials 18(2-3), Taylor & Francis (2020) 215--227
Terao, T.: A machine learning approach to analyze the structural formation of soft matter via image recognition. In: Soft Materials 18(2-3), Taylor & Francis (2020) 215--227
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.