A²: Smaller Self-Supervised ViTs Localize Better than Larger Ones
Pith reviewed 2026-06-28 11:12 UTC · model grok-4.3
The pith
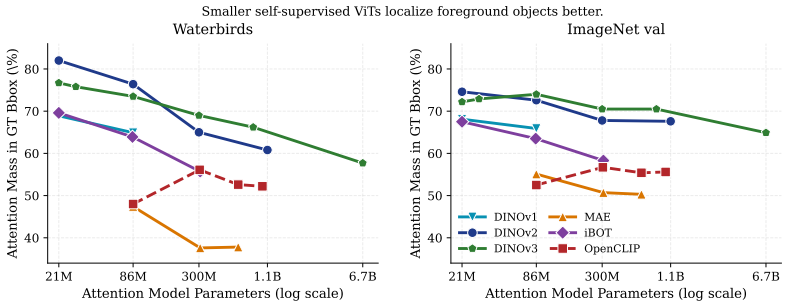
Smaller self-supervised vision transformers localize foreground objects better with their attention maps than larger ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
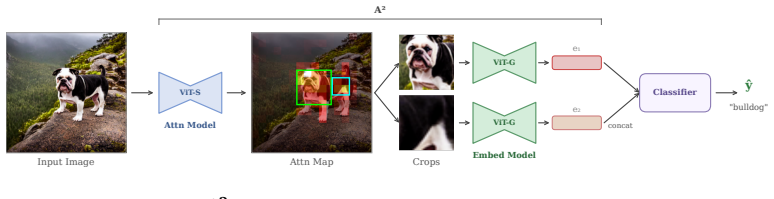
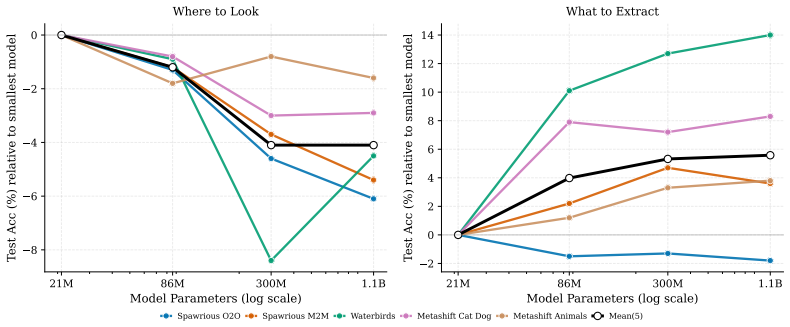
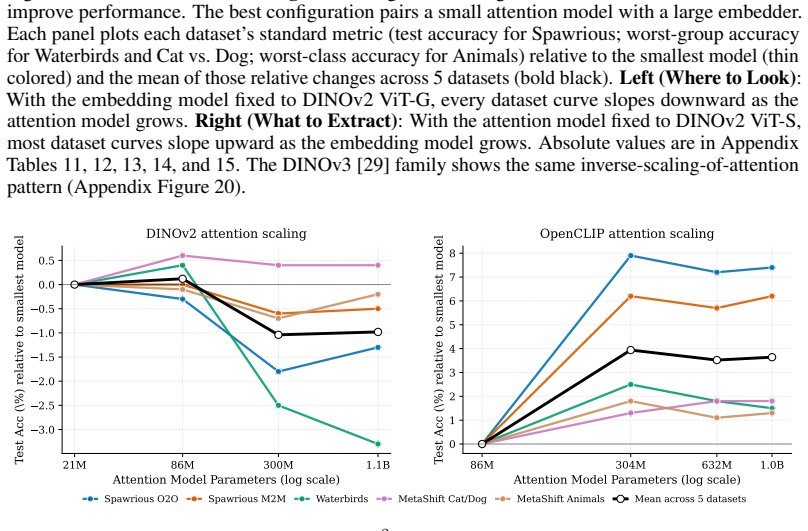
The central claim is that smaller self-supervised ViTs produce attention maps that localize foreground objects better than larger ViTs. A² exploits this inverse scaling by decoupling localization (via attention peaks from a small pretrained ViT) from representation extraction (via a larger pretrained ViT that embeds the cropped regions), yielding competitive results across benchmarks without any per-dataset training or group labels.
What carries the argument
A², the method that crops images around attention peaks from a small self-supervised ViT and embeds the crops with a larger ViT to separate localization from feature richness.
If this is right
- A² matches the accuracy of backbone-matched loss-level methods like DFR across five benchmarks.
- It outperforms end-to-end attention training when distribution shifts become stronger.
- The method works with any pair of pretrained small and large self-supervised ViTs and requires no extra optimization.
- Robustness gains come from improved foreground focus without retraining either model.
Where Pith is reading between the lines
- The same small-to-large cropping pattern could be tested on other localization-heavy tasks such as detection or segmentation to check whether the inverse scaling holds beyond classification.
- If the localization advantage of smaller models persists across different self-supervised objectives, it might indicate that model capacity trades off global structure against local texture detail in attention.
- Practitioners could explore using an ensemble of small models for more stable attention peaks before feeding crops to the large embedder.
Load-bearing premise
That attention peaks from the small model reliably mark regions containing the main object so that cropping them lets the large model extract useful representations without losing essential context or introducing bad crops.
What would settle it
On images with ground-truth object bounding boxes, if the attention-based crops from the small model consistently exclude the primary object or cut away too much surrounding context, performance with the large model would drop below that of embedding the full uncropped image.
Figures




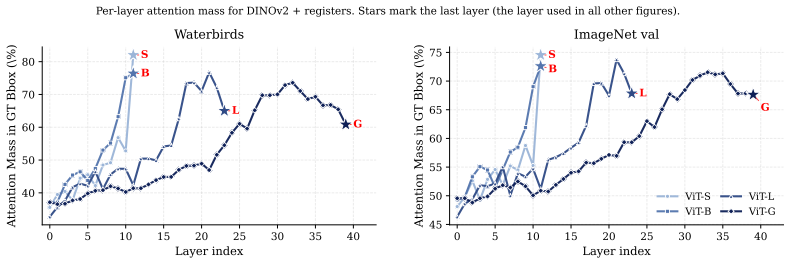
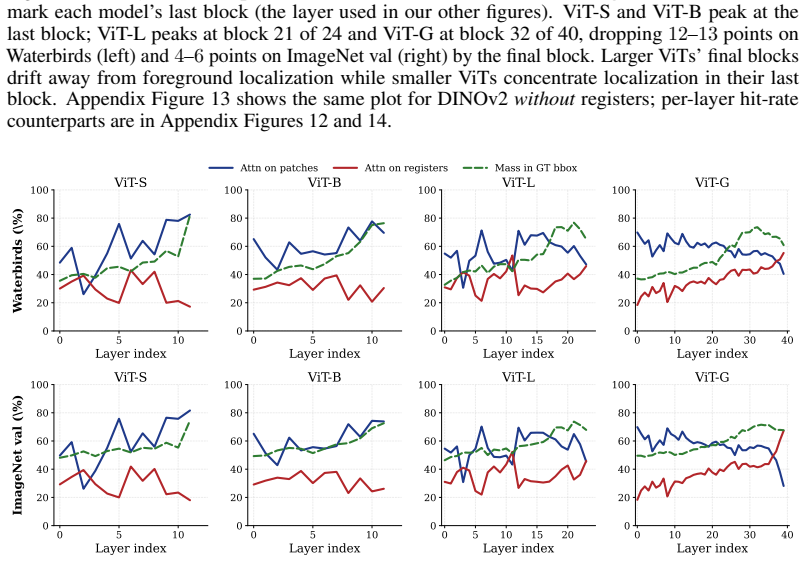








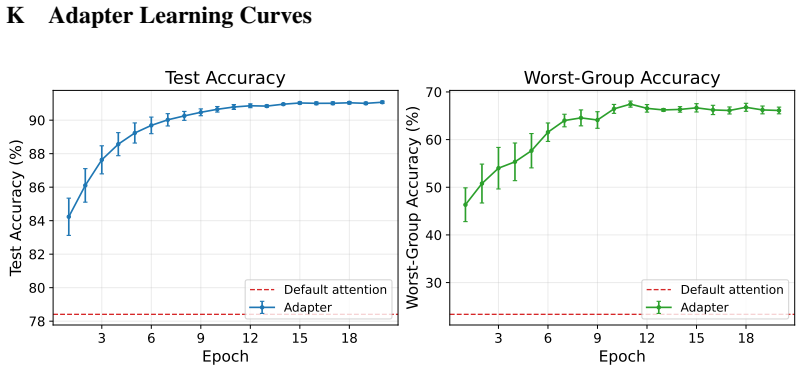
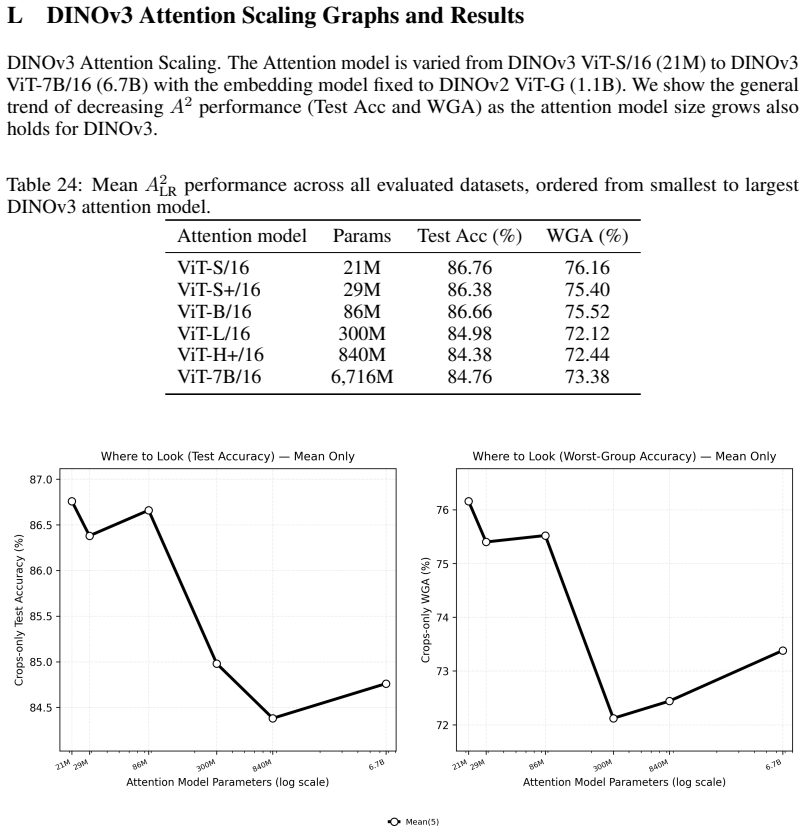


read the original abstract
Robust visual classification often depends on localizing the main foreground objects in an image while ignoring contextual distractors. Surprisingly, we find that the attention maps of smaller self-supervised ViTs localize foreground objects better than those of larger ViTs. However, we still need large ViTs, because they extract richer representations from each patch. To get the best of both worlds, good localization and rich representations, we propose $A^2$, a simple method that leverages this inverse scaling finding by decoupling where to look (a small attention model) from what to extract (a large embedding model): we crop around the attention peaks of a small model and embed the crops with a larger model. $A^2$ uses entirely pretrained features, requires no group labels, and does not require per-dataset attention or backbone training. Across 5 benchmarks, $A^2$ is competitive with backbone-matched loss-level methods like DFR, and outperforms end-to-end attention training under stronger distribution shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that smaller self-supervised Vision Transformers produce attention maps that localize foreground objects better than those from larger ViTs (an inverse scaling effect), and proposes the A² method to exploit this by using a small model's attention peaks to crop images and a large model's embeddings on those crops. A² requires no additional training, group labels, or per-dataset fitting and is reported competitive with methods like DFR on five benchmarks while outperforming end-to-end attention training under strong distribution shifts.
Significance. If the inverse scaling finding on localization holds, the result would provide a practical, training-free way to combine the localization strengths of small SSL ViTs with the representation richness of large ones, potentially improving robustness to distribution shifts without the overhead of group-robust training or attention fine-tuning. The use of entirely off-the-shelf pretrained models and the decoupling of localization from embedding are notable strengths that could generalize to other vision tasks.
major comments (2)
- [Experiments] Experiments section: The central claim that smaller SSL ViTs localize foreground objects better is supported only indirectly by A²'s downstream benchmark performance; no direct localization metrics (e.g., IoU with ground-truth boxes or pointing-game accuracy) are reported on datasets equipped with bounding-box annotations such as ImageNet-1k validation or COCO. This leaves open whether attention peaks align with main objects or simply yield crop sizes that benefit the tested shifts.
- [§3] §3 (Method) and abstract: The description of how attention maps from the small model are converted into crops (peak selection, thresholding, crop sizing) lacks sufficient detail to verify that the localization step is the operative factor, which is load-bearing for attributing gains to the claimed inverse scaling rather than other aspects of the pipeline.
minor comments (2)
- [Abstract] Abstract: The notation $A^2$ is introduced without an explicit expansion or definition on first use.
- The manuscript would benefit from a table or figure explicitly comparing localization quality metrics (even if added in revision) alongside the downstream results to make the core finding directly falsifiable.
Simulated Author's Rebuttal
Thank you for your review and the recommendation for major revision. We appreciate the feedback highlighting areas where additional evidence and clarity would strengthen the paper. We plan to address both major comments through revisions to the experiments and method sections.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The central claim that smaller SSL ViTs localize foreground objects better is supported only indirectly by A²'s downstream benchmark performance; no direct localization metrics (e.g., IoU with ground-truth boxes or pointing-game accuracy) are reported on datasets equipped with bounding-box annotations such as ImageNet-1k validation or COCO. This leaves open whether attention peaks align with main objects or simply yield crop sizes that benefit the tested shifts.
Authors: We acknowledge that direct quantitative evaluation of localization quality would provide stronger evidence for the inverse scaling claim. The current manuscript relies on the downstream task performance as a proxy, which demonstrates the practical benefit but does not directly measure alignment with ground-truth objects. In the revision, we will add direct localization metrics, such as pointing game accuracy or IoU on the ImageNet validation set (which has bounding box annotations), to directly support the claim that smaller models localize better. revision: yes
-
Referee: [§3] §3 (Method) and abstract: The description of how attention maps from the small model are converted into crops (peak selection, thresholding, crop sizing) lacks sufficient detail to verify that the localization step is the operative factor, which is load-bearing for attributing gains to the claimed inverse scaling rather than other aspects of the pipeline.
Authors: We agree that more details are needed in the method description. In the revised version, we will expand the description in §3 to specify the exact procedure: how the attention map is processed (e.g., averaging over heads if applicable), peak selection (e.g., selecting the highest attention location), thresholding if used, and how the crop is determined from the peak (e.g., fixed size centered on the peak or adaptive based on attention values). This will allow readers to verify the localization mechanism. revision: yes
Circularity Check
No circularity: empirical observation on pretrained models
full rationale
The paper reports an empirical finding that smaller self-supervised ViTs yield superior attention localization, then applies this observation via a simple cropping procedure (A²) that decouples a small attention model from a large embedding model. All components rely on off-the-shelf pretrained weights with no new parameter fitting, no self-referential predictions, and no load-bearing self-citations that justify the core claim. The derivation chain consists of direct experimental comparison and downstream benchmark evaluation rather than any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained self-supervised ViTs produce usable attention maps and embeddings without additional per-dataset training or labels.
Reference graph
Works this paper leans on
-
[1]
Zero-Shot Robustification of Zero-Shot Models.arXiv e-prints, art
Dyah Adila, Changho Shin, Linrong Cai, and Frederic Sala. Zero-Shot Robustification of Zero-Shot Models.arXiv e-prints, art. arXiv:2309.04344, September 2023. doi: 10.48550/ arXiv.2309.04344
arXiv 2023
-
[2]
Dantas, Dino Ienco, and Diego Marcos
Ananthu Aniraj, Cassio F. Dantas, Dino Ienco, and Diego Marcos. Two-stage vision transformers and hard masking offer robust object representations. InInternational Conference on Pattern Recognition (ICPR), 2026
2026
-
[3]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.16719 2025
-
[4]
Emerging Properties in Self-Supervised Vision Transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging Properties in Self-Supervised Vision Transformers.arXiv e-prints, art. arXiv:2104.14294, April 2021. doi: 10.48550/arXiv.2104.14294
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2104.14294 2021
-
[5]
Reproducible scaling laws for contrastive language-image learning.arXiv e-prints, art
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning.arXiv e-prints, art. arXiv:2212.07143, December 2022. doi: 10.48550/arXiv.2212.07143
-
[6]
Invariant Causal Mechanisms through Distribution Matching.arXiv e-prints, art
Mathieu Chevalley, Charlotte Bunne, Andreas Krause, and Stefan Bauer. Invariant Causal Mechanisms through Distribution Matching.arXiv e-prints, art. arXiv:2206.11646, June 2022. doi: 10.48550/arXiv.2206.11646
-
[7]
Differentiable patch selection for image recognition
Jean-Baptiste Cordonnier, Aravindh Mahendran, Alexey Dosovitskiy, Dirk Weissenborn, Jakob Uszkoreit, and Thomas Unterthiner. Differentiable patch selection for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2351–2360, 2021
2021
-
[8]
Vision transformers need registers
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=2dnO3LLiJ1
2024
-
[9]
Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, Rodolphe Jenatton, Lucas Beyer, Michael Tschannen, Anurag Arnab, Xiao Wang, Carlos Riquelme Ruiz, Matthias Minderer, Joan Puigcerver, Utku Evci, Manoj Kumar, Sjoerd Van 11 Steenkiste,...
2023
-
[10]
ImageNet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. doi: 10.1109/CVPR.2009.5206848
-
[11]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.arXiv e-prints, art
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.arXiv e-prints, art. arXiv:2010.11929, October 2020. doi: 10.48550/ arXiv...
Pith/arXiv arXiv 2010
-
[12]
Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A. Wichmann, and Wieland Brendel. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness.arXiv e-prints, art. arXiv:1811.12231, November 2018. doi: 10.48550/arXiv.1811.12231
-
[13]
Zemel, Wieland Brendel, Matthias Bethge, and Felix A
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. Shortcut Learning in Deep Neural Networks.arXiv e-prints, art. arXiv:2004.07780, April 2020. doi: 10.48550/arXiv.2004.07780
-
[14]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[15]
Supervised Contrastive Learning.arXiv e-prints, art
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised Contrastive Learning.arXiv e-prints, art. arXiv:2004.11362, April 2020. doi: 10.48550/arXiv.2004.11362
-
[16]
Polina Kirichenko, Pavel Izmailov, and Andrew Gordon Wilson. Last layer re-training is sufficient for robustness to spurious correlations.arXiv preprint arXiv:2204.02937, 2022
arXiv 2022
-
[17]
Register and [cls] tokens induce a decoupling of local and global features in large vits
Alexander Lappe and Martin Giese. Register and [cls] tokens induce a decoupling of local and global features in large vits. In D. Belgrave, C. Zhang, H. Lin, R. Pas- canu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Advances in Neural Infor- mation Processing Systems, volume 38, pages 1009–1029. Curran Associates, Inc.,
-
[18]
URL https://proceedings.neurips.cc/paper_files/paper/2025/file/ 01bcbd34b02f3da9700a3ddd0480c156-Paper-Conference.pdf
2025
-
[19]
Weixin Liang and James Zou. MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts.arXiv e-prints, art. arXiv:2202.06523, February
-
[20]
doi: 10.48550/arXiv.2202.06523
-
[21]
Just train twice: Improving group robustness without training group information
Evan Z Liu, Behzad Haghgoo, Annie S Chen, Aditi Raghunathan, Pang Wei Koh, Shiori Sagawa, Percy Liang, and Chelsea Finn. Just train twice: Improving group robustness without training group information. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning ...
2021
-
[22]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of International Conference on Computer Vision (ICCV), December 2015
2015
-
[23]
Think twice: Test-time reasoning for robust clip zero-shot classification
Shenyu Lu, Zhaoying Pan, and Xiaoqian Wang. Think twice: Test-time reasoning for robust clip zero-shot classification. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2919–2929, October 2025. 12
2025
-
[24]
Spawrious: A benchmark for fine control of spurious correlation biases, 2023
Aengus Lynch, Gbètondji J-S Dovonon, Jean Kaddour, and Ricardo Silva. Spawrious: A benchmark for fine control of spurious correlation biases, 2023
2023
-
[25]
Intriguing properties of vision transformers
Muzammal Naseer, Kanchana Ranasinghe, Salman Khan, Munawar Hayat, Fahad Khan, and Ming-Hsuan Yang. Intriguing properties of vision transformers. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems,
-
[26]
URLhttps://openreview.net/forum?id=o2mbl-Hmfgd
-
[27]
Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[28]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision.arXiv e-prints, art. arXiv:2103.00020, February 2021. doi: 10.48550/arXiv.2103.00020
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.00020 2021
-
[29]
Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.007...
Pith/arXiv arXiv 2024
-
[30]
Shiori Sagawa, Pang Wei Koh, Tatsunori B. Hashimoto, and Percy Liang. Distributionally Robust Neural Networks for Group Shifts: On the Importance of Regularization for Worst-Case Generalization.arXiv e-prints, art. arXiv:1911.08731, November 2019. doi: 10.48550/arXiv. 1911.08731
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 1911
-
[31]
When Do We Not Need Larger Vision Models?arXiv e-prints, art
Baifeng Shi, Ziyang Wu, Maolin Mao, Xin Wang, and Trevor Darrell. When Do We Not Need Larger Vision Models?arXiv e-prints, art. arXiv:2403.13043, March 2024. doi: 10.48550/ arXiv.2403.13043
arXiv 2024
-
[32]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10104 2025
-
[33]
Deep CORAL: Correlation Alignment for Deep Domain Adaptation
Baochen Sun and Kate Saenko. Deep CORAL: Correlation Alignment for Deep Domain Adaptation.arXiv e-prints, art. arXiv:1607.01719, July 2016. doi: 10.48550/arXiv.1607.01719
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1607.01719 2016
-
[34]
Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization,
Chen Sun, Abhinav Shrivastava, Saurabh Singh, and Abhinav Gupta. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era . In2017 IEEE International Conference on Computer Vision (ICCV), pages 843–852, Los Alamitos, CA, USA, October 2017. IEEE Computer Society. doi: 10.1109/ICCV .2017.97. URLhttps://doi.ieeecomputersociety. org/10.1109/ICCV.2017.97
-
[35]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need.arXiv e-prints, art. arXiv:1706.03762, June 2017. doi: 10.48550/arXiv.1706.03762
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762 2017
-
[36]
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.arXiv e-prints, art
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard Zemel, and Yoshua Bengio. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.arXiv e-prints, art. arXiv:1502.03044, February 2015. doi: 10.48550/ arXiv.1502.03044
Pith/arXiv arXiv 2015
-
[37]
Mitigating Spurious Correlations in Multi-modal Models during Fine-tuning.arXiv e-prints, art
Yu Yang, Besmira Nushi, Hamid Palangi, and Baharan Mirzasoleiman. Mitigating Spurious Correlations in Multi-modal Models during Fine-tuning.arXiv e-prints, art. arXiv:2304.03916, April 2023. doi: 10.48550/arXiv.2304.03916
-
[38]
Scaling vision transform- ers
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transform- ers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12104–12113, June 2022. 13
2022
-
[39]
Michael Zhang, Nimit S. Sohoni, Hongyang R. Zhang, Chelsea Finn, and Christopher Ré. Correct-N-Contrast: A Contrastive Approach for Improving Robustness to Spurious Correla- tions.arXiv e-prints, art. arXiv:2203.01517, March 2022. doi: 10.48550/arXiv.2203.01517
-
[40]
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. ibot: Image bert pre-training with online tokenizer.International Conference on Learning Representations (ICLR), 2022. 14 A Attention Localization and Hit Rate across model families Table 3: Attention localization vs. ground-truth bounding boxes across six pretraining fam...
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.