Grasp-Then-Plan with Failure Attribution: A Closed Two-Stage Framework for Precise and Generalizable Robotic Manipulation
Pith reviewed 2026-06-28 09:35 UTC · model grok-4.3
The pith
A grasp-then-plan framework with failure attribution raises robotic manipulation success by diagnosing errors separately in each stage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
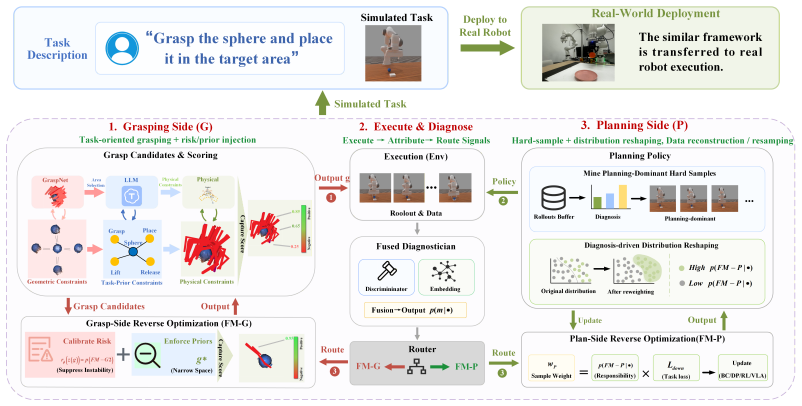
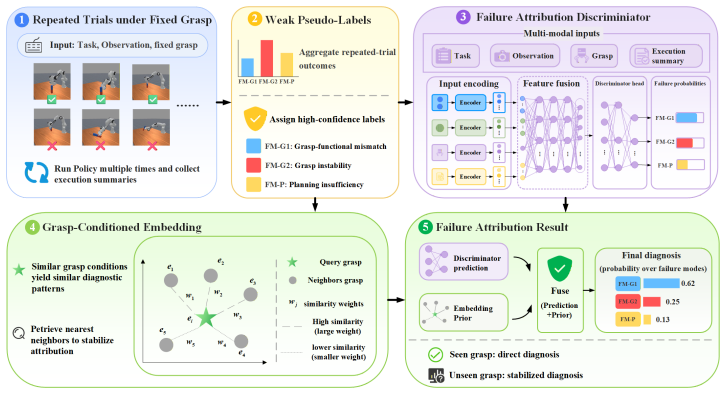
GTP-FA generates grasp candidates and performs downstream motion planning conditioned on the selected grasp; given failed trajectories it learns a failure attribution model that generalizes to unseen grasps and yields a stable distribution over failure modes, enabling diagnosis-driven optimization that injects task-level priors and risk penalties into grasping while targeting high-risk initial states in planning, thereby improving overall task success rates across multiple base learners.
What carries the argument
The failure attribution model that generalizes to unseen grasps and produces a stable distribution over failure modes to guide separate optimization of grasping and planning stages.
If this is right
- Grasping modules receive injected task-level priors and risk penalties that suppress unstable or task-incompatible candidates.
- Planning modules are fine-tuned on data collected from high-risk initial states that expose genuine planning bottlenecks.
- Base learners from RL, imitation learning, diffusion-policy, and VLA settings each record substantially higher overall task success rates.
- The same two-stage structure and attribution process operates in both simulation and real-robot experiments.
Where Pith is reading between the lines
- The same attribution-driven separation could be tested on other sequential robotic skills such as pushing followed by grasping.
- If failure-mode distributions prove stable across environments, the method might reduce the need for full retraining when only one stage changes.
- Extending the framework to three or more coupled stages would require checking whether attribution remains reliable when more than two modules interact.
Load-bearing premise
The failure attribution model generalizes to unseen grasps and produces a stable distribution over failure modes for diagnosis-guided optimization.
What would settle it
Apply the trained failure attribution model to a set of previously unseen but similar grasps in a held-out manipulation task and check whether the assigned failure-mode distributions remain consistent and correctly predict which stage caused the observed failure; large inconsistency or poor predictive match would falsify the claim that attribution enables reliable separate optimization.
Figures

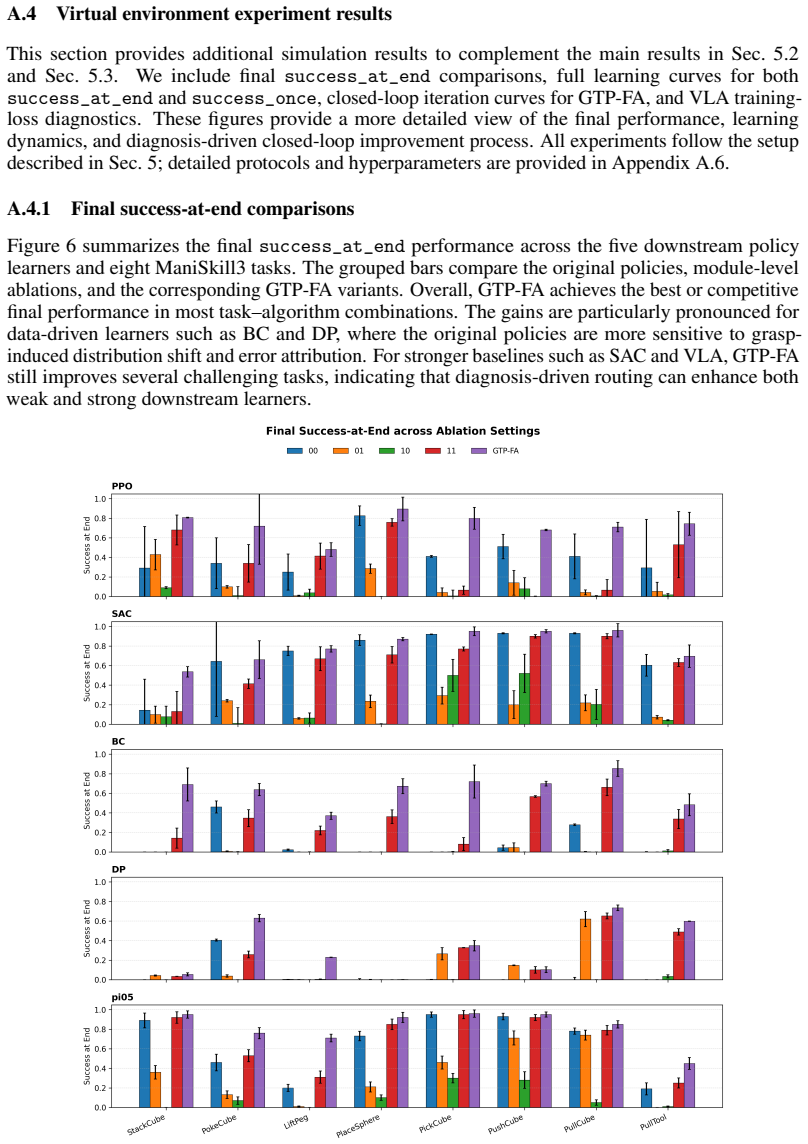
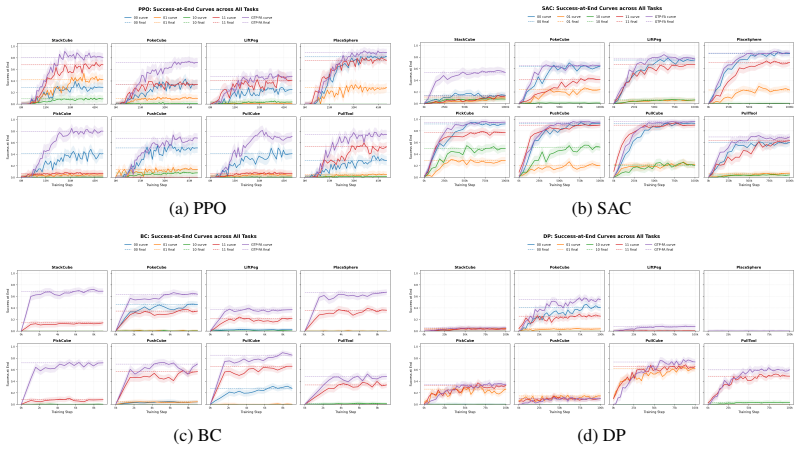
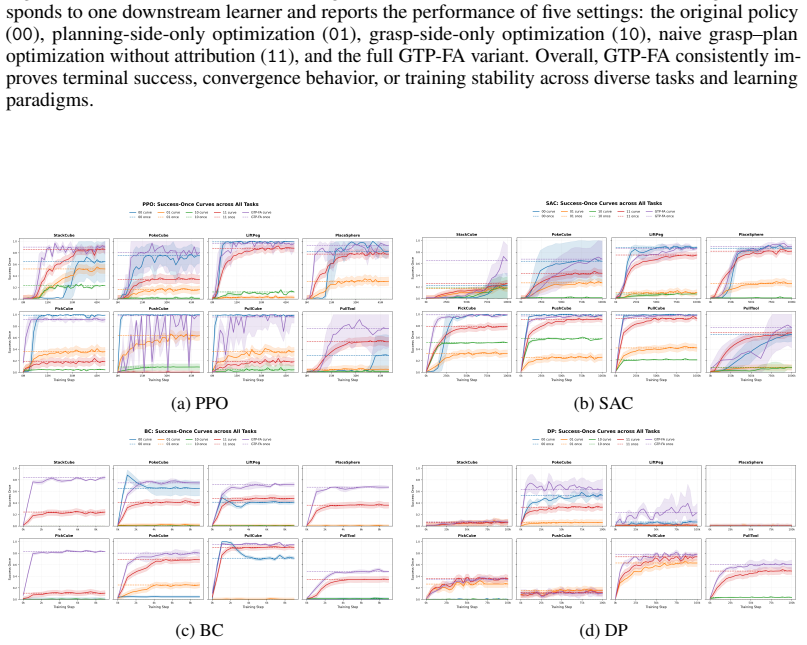
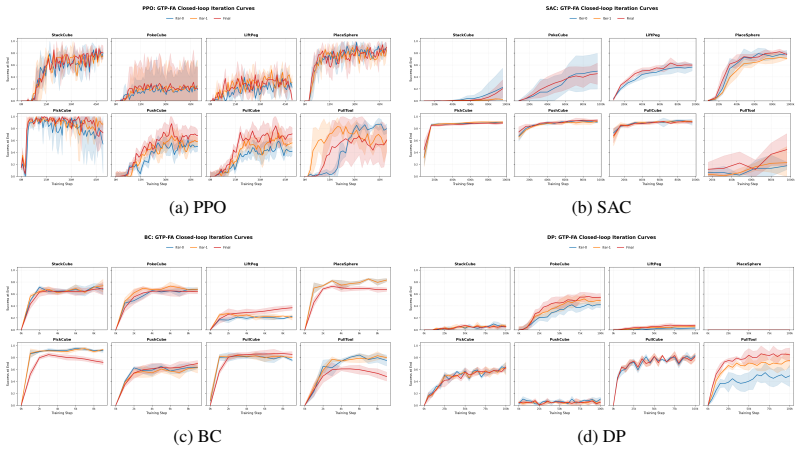
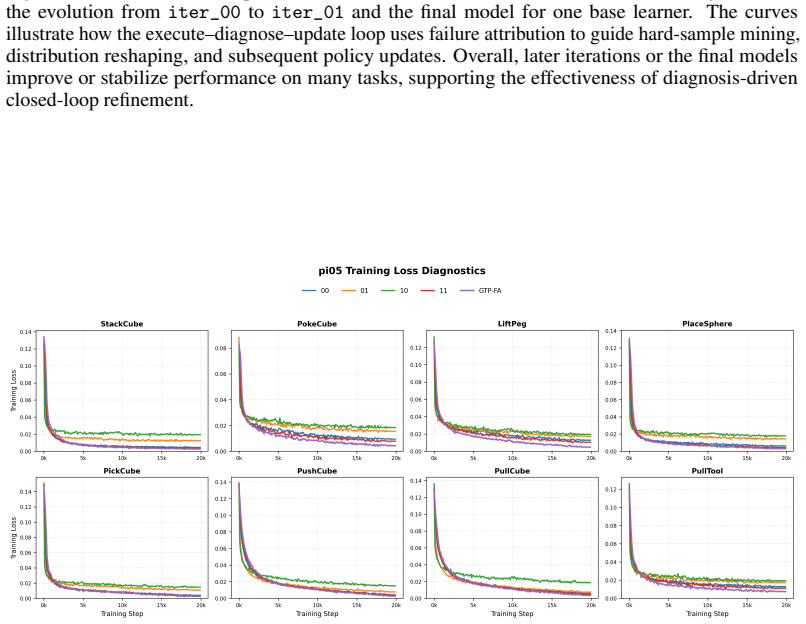

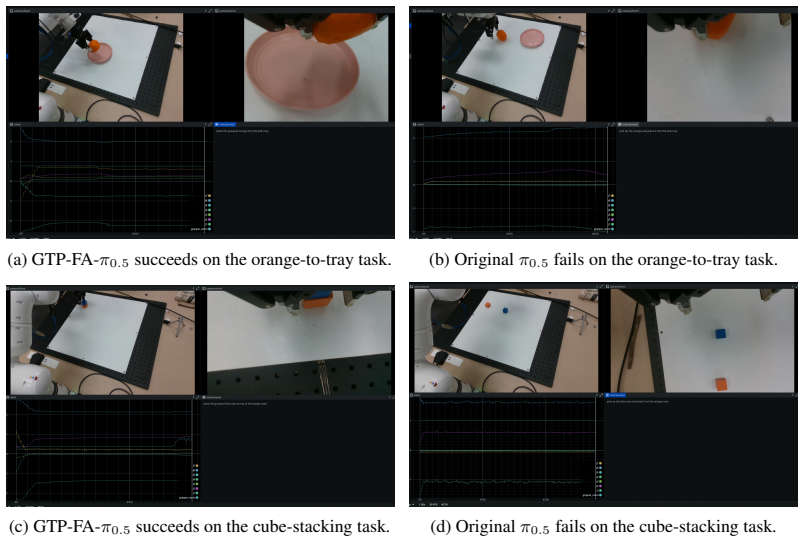
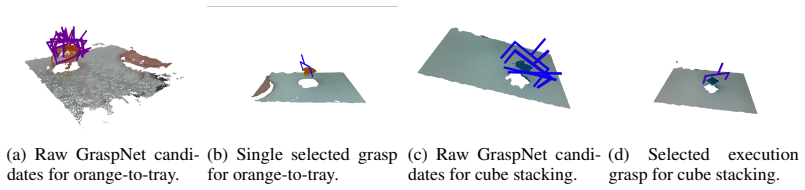




read the original abstract
In robotic manipulation, the tight coupling between grasping and motion planning often obscures the true source of failure, leading to inefficient trial-and-error. To enable efficient long-horizon manipulation, we propose GTP-FA (Grasp-Then-Plan with Failure Attribution), a task-oriented two-stage grasp-then-plan framework that generates grasp candidates and performs downstream motion planning conditioned on the selected grasp. Given a failed manipulation trajectory, we learn a failure attribution model that generalizes to unseen grasps and produces a stable distribution over failure modes for diagnosis-guided optimization. Based on these attribution results, we then optimize both modules in a diagnosis-driven manner: on the grasping side, we inject task-level priors and risk penalties into grasp candidate scoring and optimization to suppress unstable or task-incompatible grasps; on the planning side, we target high-risk initial states through data collection and fine-tuning to address genuine planning bottlenecks. We evaluate the proposed framework in both simulation and real-robot experiments, and show that GTP-FA improves the corresponding base learners across RL, IL, diffusion-policy, and VLA-based settings, achieving substantially higher overall task success rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GTP-FA, a closed two-stage grasp-then-plan framework for robotic manipulation. It generates grasp candidates, performs motion planning conditioned on the selected grasp, and learns a failure attribution model from failed trajectories that generalizes to unseen grasps and outputs a distribution over failure modes. This attribution then drives targeted optimization: task-level priors and risk penalties on the grasp side, and data collection/fine-tuning on high-risk initial states for the planner. The central empirical claim is that GTP-FA improves base learners across RL, IL, diffusion-policy, and VLA settings, yielding substantially higher task success rates in both simulation and real-robot experiments.
Significance. If the failure attribution model reliably disentangles grasp-induced versus planning-induced failures, the framework offers a principled alternative to undifferentiated trial-and-error in long-horizon manipulation and could generalize across multiple learning paradigms. The closed-loop diagnosis-driven optimization is a conceptual strength, but its practical value hinges on the empirical demonstration that the attribution step produces stable, actionable distributions without introducing new failure modes.
major comments (2)
- [Abstract] Abstract: The central claim that the failure attribution model 'generalizes to unseen grasps and produces a stable distribution over failure modes for diagnosis-guided optimization' is load-bearing for the subsequent grasp-scoring penalties and planner fine-tuning. However, because grasp selection directly determines the initial configuration seen by the planner, grasp-induced instabilities can manifest as apparent planning failures (and vice versa), creating an identifiability risk that is not addressed in the provided description of the attribution model.
- [Abstract] The manuscript states that GTP-FA 'improves the corresponding base learners across RL, IL, diffusion-policy, and VLA-based settings, achieving substantially higher overall task success rates,' yet the abstract supplies no quantitative deltas, error bars, number of trials, or ablation controls that would allow verification of the data-to-claim link for this multi-learner improvement.
minor comments (1)
- [Abstract] The abstract would be strengthened by a single sentence reporting the magnitude of the reported success-rate gains (e.g., 'from X% to Y%') to give readers an immediate sense of effect size.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the failure attribution model 'generalizes to unseen grasps and produces a stable distribution over failure modes for diagnosis-guided optimization' is load-bearing for the subsequent grasp-scoring penalties and planner fine-tuning. However, because grasp selection directly determines the initial configuration seen by the planner, grasp-induced instabilities can manifest as apparent planning failures (and vice versa), creating an identifiability risk that is not addressed in the provided description of the attribution model.
Authors: We acknowledge the identifiability concern. The attribution model is trained using labeled trajectories that distinguish grasp failures (via pre-execution metrics such as grasp quality scores and force thresholds) from planning failures (via post-grasp execution deviations). The model's reported generalization to unseen grasps is intended to support this separation. We agree an explicit discussion of the disentanglement approach, its assumptions, and limitations is warranted and will add this to the revised manuscript. revision: yes
-
Referee: [Abstract] The manuscript states that GTP-FA 'improves the corresponding base learners across RL, IL, diffusion-policy, and VLA-based settings, achieving substantially higher overall task success rates,' yet the abstract supplies no quantitative deltas, error bars, number of trials, or ablation controls that would allow verification of the data-to-claim link for this multi-learner improvement.
Authors: We agree that quantitative support would strengthen the abstract. In the revision we will incorporate concise numerical results, including average success-rate improvements across the four learning paradigms, trial counts, and error-bar references, subject to abstract length limits. revision: yes
Circularity Check
No circularity detected; empirical framework with independent evaluation
full rationale
The paper describes an empirical two-stage robotic manipulation framework (GTP-FA) that learns a failure attribution model from failed trajectories and uses its outputs for diagnosis-guided optimization of grasp scoring and planner fine-tuning. No equations, parameter fits, or derivation steps are presented that reduce any claimed result to its own inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. Improvements are demonstrated via simulation and real-robot experiments across RL, IL, diffusion, and VLA baselines, rendering the central claims externally falsifiable and self-contained against benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[10]
Efficient online reinforcement learning with offline data
Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. In International Conference on Machine Learning, pages 1577--1594. PMLR, 2023
2023
-
[15]
Graspnet-1billion: A large-scale benchmark for general object grasping
Hao-Shu Fang, Chenxi Wang, Minghao Gou, and Cewu Lu. Graspnet-1billion: A large-scale benchmark for general object grasping. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11444--11453, 2020
2020
-
[17]
Copa: General robotic manipulation through spatial constraints of parts with foundation models
Haoxu Huang, Fanqi Lin, Yingdong Hu, Shengjie Wang, and Yang Gao. Copa: General robotic manipulation through spatial constraints of parts with foundation models. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9488--9495. IEEE, 2024
2024
-
[20]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al. ^ * _ 0.6 : A VLA that learns from experience. arXiv preprint arXiv:2511.14759, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. _ 0.5 : A vision--language--action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Generalizing 6-dof grasp detection via domain prior knowledge
Haoxiang Ma, Modi Shi, Boyang Gao, and Di Huang. Generalizing 6-dof grasp detection via domain prior knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18102--18111, 2024
2024
-
[28]
Liv: Language-image representations and rewards for robotic control
Yecheng Jason Ma, Vikash Kumar, Amy Zhang, Osbert Bastani, and Dinesh Jayaraman. Liv: Language-image representations and rewards for robotic control. In International Conference on Machine Learning, pages 23301--23320. PMLR, 2023
2023
-
[30]
6-dof graspnet: Variational grasp generation for object manipulation
Arsalan Mousavian, Clemens Eppner, and Dieter Fox. 6-dof graspnet: Variational grasp generation for object manipulation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2901--2910, 2019
2019
-
[33]
Roboclip: One demonstration is enough to learn robot policies
Sumedh Sontakke, Jesse Zhang, S \'e b Arnold, Karl Pertsch, Erdem B y k, Dorsa Sadigh, Chelsea Finn, and Laurent Itti. Roboclip: One demonstration is enough to learn robot policies. Advances in Neural Information Processing Systems, 36: 0 55681--55693, 2023
2023
-
[34]
Task-oriented grasp prediction with visual-language inputs
Chao Tang, Dehao Huang, Lingxiao Meng, Weiyu Liu, and Hong Zhang. Task-oriented grasp prediction with visual-language inputs. In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4881--4888. IEEE, 2023
2023
-
[35]
Foundationgrasp: Generalizable task-oriented grasping with foundation models
Chao Tang, Dehao Huang, Wenlong Dong, Ruinian Xu, and Hong Zhang. Foundationgrasp: Generalizable task-oriented grasping with foundation models. IEEE Transactions on Automation Science and Engineering, 2025
2025
-
[38]
Grasp as you say: Language-guided dexterous grasp generation
Yi-Lin Wei, Jian-Jian Jiang, Chengyi Xing, Xian-Tuo Tan, Xiao-Ming Wu, Hao Li, Mark Cutkosky, and Wei-Shi Zheng. Grasp as you say: Language-guided dexterous grasp generation. Advances in Neural Information Processing Systems, 37: 0 46881--46907, 2024
2024
-
[39]
Catgrasp: Learning category-level task-relevant grasping in clutter from simulation
Bowen Wen, Wenzhao Lian, Kostas Bekris, and Stefan Schaal. Catgrasp: Learning category-level task-relevant grasping in clutter from simulation. In 2022 International Conference on Robotics and Automation (ICRA), pages 6401--6408. IEEE, 2022
2022
-
[44]
arXiv preprint arXiv:2512.13380 , year=
Universal Dexterous Functional Grasping via Demonstration-Editing Reinforcement Learning , author=. arXiv preprint arXiv:2512.13380 , year=
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Generalizing 6-dof grasp detection via domain prior knowledge , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[46]
IEEE Transactions on Automation Science and Engineering , year=
Foundationgrasp: Generalizable task-oriented grasping with foundation models , author=. IEEE Transactions on Automation Science and Engineering , year=
-
[47]
Advances in Neural Information Processing Systems , volume=
Grasp as you say: Language-guided dexterous grasp generation , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Task-oriented grasp prediction with visual-language inputs , author=. 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2023 , organization=
2023
-
[49]
arXiv preprint arXiv:2509.01746 , year=
Fail2Progress: Learning from Real-World Robot Failures with Stein Variational Inference , author=. arXiv preprint arXiv:2509.01746 , year=
-
[50]
Aha: A vision-language-model for detecting and reasoning over failures in robotic manipulation , author=. arXiv preprint arXiv:2410.00371 , year=
-
[51]
FailSafe: Reasoning and Recovery from Failures in Vision-Language-Action Models
Failsafe: Reasoning and recovery from failures in vision-language-action models , author=. arXiv preprint arXiv:2510.01642 , year=
work page internal anchor Pith review arXiv
-
[52]
2022 International Conference on Robotics and Automation (ICRA) , pages=
Catgrasp: Learning category-level task-relevant grasping in clutter from simulation , author=. 2022 International Conference on Robotics and Automation (ICRA) , pages=. 2022 , organization=
2022
-
[53]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
6-dof graspnet: Variational grasp generation for object manipulation , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[54]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Graspnet-1billion: A large-scale benchmark for general object grasping , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[55]
arXiv preprint arXiv:2211.02647 , year=
Neural grasp distance fields for robot manipulation , author=. arXiv preprint arXiv:2211.02647 , year=
-
[56]
arXiv preprint arXiv:2510.25889 , year=
RL: Online rl fine-tuning for flow-based visionlanguage-action models , author=. arXiv preprint arXiv:2510.25889 , year=
-
[57]
arXiv preprint arXiv:2512.05107 , year=
STARE-VLA: Progressive Stage-Aware Reinforcement for Fine-Tuning Vision-Language-Action Models , author=. arXiv preprint arXiv:2512.05107 , year=
-
[58]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. arXiv preprint arXiv:2410.24164 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Data Scaling Laws in Imitation Learning for Robotic Manipulation
Data scaling laws in imitation learning for robotic manipulation , author=. arXiv preprint arXiv:2410.18647 , year=
work page internal anchor Pith review arXiv
-
[60]
arXiv preprint arXiv:2503.01837 , year=
Multi-Stage Manipulation with Demonstration-Augmented Reward, Policy, and World Model Learning , author=. arXiv preprint arXiv:2503.01837 , year=
-
[61]
Intelligence, Physical and Amin, Ali and Aniceto, Raichelle and Balakrishna, Ashwin and Black, Kevin and Conley, Ken and Connors, Grace and Darpinian, James and Dhabalia, Karan and DiCarlo, Jared and others , journal=. ^
-
[62]
Intelligence, Physical and Black, Kevin and Brown, Noah and Darpinian, James and Dhabalia, Karan and Driess, Danny and Esmail, Adnan and Equi, Michael and Finn, Chelsea and Fusai, Niccolo and others , journal=. _
-
[63]
arXiv preprint arXiv:2405.03379 , year=
Reverse forward curriculum learning for extreme sample and demonstration efficiency in reinforcement learning , author=. arXiv preprint arXiv:2405.03379 , year=
-
[64]
International Conference on Machine Learning , pages=
Efficient online reinforcement learning with offline data , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[65]
IEEE Robotics and Automation Letters , volume=
Centergrasp: Object-aware implicit representation learning for simultaneous shape reconstruction and 6-dof grasp estimation , author=. IEEE Robotics and Automation Letters , volume=. 2024 , publisher=
2024
-
[66]
2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Copa: General robotic manipulation through spatial constraints of parts with foundation models , author=. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2024 , organization=
2024
-
[67]
arXiv preprint arXiv:2503.15035 , year=
GraspCorrect: Robotic Grasp Correction via Vision-Language Model-Guided Feedback , author=. arXiv preprint arXiv:2503.15035 , year=
-
[68]
arXiv preprint arXiv:2305.04639 , year=
Multimodal Detection and Identification of Robot Manipulation Failures , author=. arXiv preprint arXiv:2305.04639 , year=
-
[69]
RoboMD: Uncovering Robot Vulnerabilities through Semantic Potential Fields
From Mystery to Mastery: Failure Diagnosis for Improving Manipulation Policies , author=. arXiv preprint arXiv:2412.02818 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Unpacking Failure Modes of Generative Policies: Runtime Monitoring of Consistency and Progress, 2024
Unpacking failure modes of generative policies: Runtime monitoring of consistency and progress , author=. arXiv preprint arXiv:2410.04640 , year=
-
[71]
arXiv preprint arXiv:2209.03855 , year=
Se (3)-diffusionfields: Learning smooth cost functions for joint grasp and motion optimization through diffusion , author=. arXiv preprint arXiv:2209.03855 , year=
-
[72]
Advances in Neural Information Processing Systems , volume=
Roboclip: One demonstration is enough to learn robot policies , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
arXiv preprint arXiv:2502.20630 , year=
Subtask-Aware Visual Reward Learning from Segmented Demonstrations , author=. arXiv preprint arXiv:2502.20630 , year=
-
[74]
International Conference on Machine Learning , pages=
Liv: Language-image representations and rewards for robotic control , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[75]
arXiv preprint arXiv:2406.11815 , year=
Llarva: Vision-action instruction tuning enhances robot learning , author=. arXiv preprint arXiv:2406.11815 , year=
-
[76]
arXiv preprint arXiv:2503.01616 , year=
Robodexvlm: Visual language model-enabled task planning and motion control for dexterous robot manipulation , author=. arXiv preprint arXiv:2503.01616 , year=
-
[77]
arXiv preprint arXiv:2412.13630 , year=
Policy decorator: Model-agnostic online refinement for large policy model , author=. arXiv preprint arXiv:2412.13630 , year=
-
[78]
arXiv preprint arXiv:2408.02912 , year=
Koi: Accelerating online imitation learning via hybrid key-state guidance , author=. arXiv preprint arXiv:2408.02912 , year=
-
[79]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v , author=. arXiv preprint arXiv:2310.11441 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.